

flink 1.11.2 学习笔记(3)-统计窗口window
接上节继续,通常在做数据分析时需要指定时间范围,比如:"每天凌晨1点统计前一天的订单量" 或者 "每个整点统计前24小时的总发货量"。这个统计时间段,就称为统计窗口。Flink中支持多种Window统计,今天介绍二种常见的窗口:TumbingWindow及SlidingWindow。
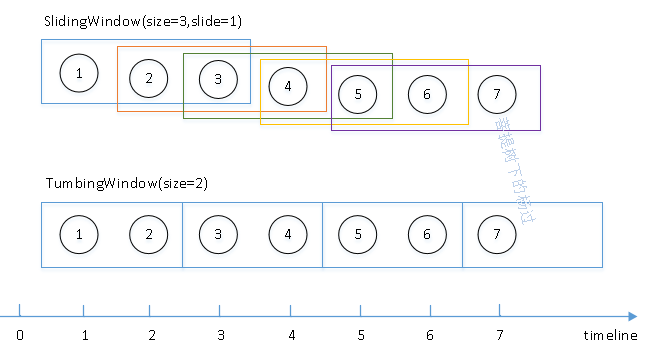
如上图,最下面是时间线,假设每1分钟上游系统产生1条数据,分别对应序号1~7。如果每隔1分钟,需要统计前3分钟的数据,这种就是SlidingWindow。如果每2分钟的数据做1次统计(注:2次相邻的统计之间,没有数据重叠部分),这种就是TumbingWindow。
在开始写示例代码前,再来说一个概念:时间语义。
通常每条业务数据都有自己的"业务发生时间"(比如:订单数据有“下单时间”,IM聊天消息有"消息发送时间"),由于网络延时等原因,数据到达flink时,flink有一个"数据接收时间"。那么在数据分析时,前面提到的各种窗口统计应该以哪个时间为依据呢?这就是时间语义。 flink允许开发者自行指定用哪个时间来做为处理依据,大多数业务系统通常会采用业务发生时间(即:所谓的事件时间)。
下面还是以WordCount这个经典示例来演示一番:(flink版本:1.11.2)
1、准备数据源
仍以kafka作为数据源,准备向其发送以下格式的数据:
{
"event_datetime": "2020-12-19 14:10:21.209",
"event_timestamp": "1608358221209",
"word": "hello"
}
注意:这里event_timestamp相当于业务时间(即:事件时间)对应的时间戳,word为每次要统计的单词。event_datetime不参与处理,只是为了肉眼看日志更方便。
写一个java类,不停发送数据:(每10秒生成一条随机数据,1分钟共6条)
package com.cnblogs.yjmyzz.flink.demo;
import com.google.gson.Gson;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.text.SimpleDateFormat;
import java.util.*;
/**
* @author 菩提树下的杨过
*/
public class KafkaProducerSample {
private static String topic = "test3";
private static Gson gson = new Gson();
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
public static void main(String[] args) throws InterruptedException {
Properties p = new Properties();
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(p);
String[] words = new String[]{"hello", "world", "flink"};
Random rnd = new Random();
try {
while (true) {
Map<String, String> map = new HashMap<>();
map.put("word", words[rnd.nextInt(words.length)]);
long timestamp = System.currentTimeMillis();
map.put("event_timestamp", timestamp + "");
map.put("event_datetime", sdf.format(new Date(timestamp)));
String msg = gson.toJson(map);
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, msg);
kafkaProducer.send(record);
System.out.println(msg);
Thread.sleep(10000);
}
} finally {
kafkaProducer.close();
}
}
}
2. TumbingWindow示例
package com.cnblogs.yjmyzz.flink.demo;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
import java.util.Properties;
/**
* @author 菩提树下的杨过(http : / / yjmyzz.cnblogs.com /)
*/
public class KafkaStreamTumblingWindowCount {
private final static Gson gson = new Gson();
private final static String SOURCE_TOPIC = "test3";
private final static String SINK_TOPIC = "test4";
private final static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm");
public static void main(String[] args) throws Exception {
// 1 设置环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//指定使用eventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 2. 定义数据
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "test-read-group-2");
props.put("deserializer.encoding", "GB2312");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
DataStreamSource<String> text = env.addSource(new FlinkKafkaConsumer011<>(
SOURCE_TOPIC,
new SimpleStringSchema(),
props));
// 3. 处理逻辑
DataStream<Tuple3<String, Integer, String>> counts = text.assignTimestampsAndWatermarks(new WatermarkStrategy<String>() {
@Override
public WatermarkGenerator<String> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new WatermarkGenerator<String>() {
private long maxTimestamp;
private long delay = 100;
@Override
public void onEvent(String s, long l, WatermarkOutput watermarkOutput) {
Map<String, String> map = gson.fromJson(s, new TypeToken<Map<String, String>>() {
}.getType());
String timestamp = map.getOrDefault("event_timestamp", l + "");
maxTimestamp = Math.max(maxTimestamp, Long.parseLong(timestamp));
}
@Override
public void onPeriodicEmit(WatermarkOutput watermarkOutput) {
watermarkOutput.emitWatermark(new Watermark(maxTimestamp - delay));
}
};
}
}).flatMap(new FlatMapFunction<String, Tuple3<String, Integer, String>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, Integer, String>> out) throws Exception {
//解析message中的json
Map<String, String> map = gson.fromJson(value, new TypeToken<Map<String, String>>() {
}.getType());
String word = map.getOrDefault("word", "");
String eventTimestamp = map.getOrDefault("event_timestamp", "0");
//获取每个统计窗口的时间(用于显示)
String windowTime = sdf.format(new Date(TimeWindow.getWindowStartWithOffset(Long.parseLong(eventTimestamp), 0, 60 * 1000)));
if (word != null && word.trim().length() > 0) {
//收集(类似:map-reduce思路)
out.collect(new Tuple3<>(word.trim(), 1, windowTime));
}
}
})
//按Tuple3里的第0项,即:word分组
.keyBy(value -> value.f0)
//按每1分整点开固定窗口计算
.timeWindow(Time.minutes(1))
//然后对Tuple3里的第1项求合
.sum(1);
// 4. 打印结果
counts.addSink(new FlinkKafkaProducer010<>("localhost:9092", SINK_TOPIC,
(SerializationSchema<Tuple3<String, Integer, String>>) element -> (element.f2 + " (" + element.f0 + "," + element.f1 + ")").getBytes()));
counts.print();
// execute program
env.execute("Kafka Streaming WordCount");
}
}
代码看着一大堆,但是并不复杂,解释 一下:
31-34 行是一些常量定义 ,从test3这个topic拿数据,处理好的结果,发送到test4这个topic
42行指定时间语义:使用事件时间做为依据。但是这还不够,不是空口白话,说用“事件时间”就用“事件时间”,flink怎么知道哪个字段代表事件时间? 62-77行,这里给出了细节,解析kafka消息中的json体,然后把event_timestamp提取出来,做为时间依据。另外65行,还指定了允许数据延时100ms(这个可以先不管,后面学习watermark时,再详细解释 )
89-90行,为了让wordCount的统计结果更友好,本次窗口对应的起始时间,使用静态方法TimeWindow.getWindowStartWithOffset计算后,直接放到结果里了。
102行, timeWindow(Time.munites(1)) 这里指定了使用tumblingWindow,每次统计1分钟的数据。(注:这里的1分钟是从0秒开始,到59秒结束,即类似: 2020-12-12 14:00:00.000 ~ 2020-12-12 14:00:59.999)
运行结果:
下面是数据源的kafka消息日志(截取了部分)
...
{"event_datetime":"2020-12-19 14:32:36.873","event_timestamp":"1608359556873","word":"hello"}
{"event_datetime":"2020-12-19 14:32:46.874","event_timestamp":"1608359566874","word":"world"}
{"event_datetime":"2020-12-19 14:32:56.874","event_timestamp":"1608359576874","word":"hello"}
{"event_datetime":"2020-12-19 14:33:06.875","event_timestamp":"1608359586875","word":"hello"}
{"event_datetime":"2020-12-19 14:33:16.876","event_timestamp":"1608359596876","word":"world"}
{"event_datetime":"2020-12-19 14:33:26.877","event_timestamp":"1608359606877","word":"hello"}
{"event_datetime":"2020-12-19 14:33:36.878","event_timestamp":"1608359616878","word":"world"}
{"event_datetime":"2020-12-19 14:33:46.879","event_timestamp":"1608359626879","word":"flink"}
{"event_datetime":"2020-12-19 14:33:56.879","event_timestamp":"1608359636879","word":"hello"}
{"event_datetime":"2020-12-19 14:34:06.880","event_timestamp":"1608359646880","word":"world"}
{"event_datetime":"2020-12-19 14:34:16.881","event_timestamp":"1608359656881","word":"world"}
{"event_datetime":"2020-12-19 14:34:26.883","event_timestamp":"1608359666883","word":"hello"}
{"event_datetime":"2020-12-19 14:34:36.883","event_timestamp":"1608359676883","word":"flink"}
{"event_datetime":"2020-12-19 14:34:46.885","event_timestamp":"1608359686885","word":"flink"}
{"event_datetime":"2020-12-19 14:34:56.885","event_timestamp":"1608359696885","word":"world"}
{"event_datetime":"2020-12-19 14:35:06.885","event_timestamp":"1608359706885","word":"flink"}
...
flink的处理结果:
... 3> (world,2,2020-12-19 14:33) 4> (flink,1,2020-12-19 14:33) 2> (hello,3,2020-12-19 14:33) 3> (world,3,2020-12-19 14:34) 2> (hello,1,2020-12-19 14:34) 4> (flink,2,2020-12-19 14:34) ...
3.SlidingWindow示例
package com.cnblogs.yjmyzz.flink.demo;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
import java.util.Properties;
/**
* @author 菩提树下的杨过(http : / / yjmyzz.cnblogs.com /)
*/
public class KafkaStreamSlidingWindowCount {
private final static Gson gson = new Gson();
private final static String SOURCE_TOPIC = "test3";
private final static String SINK_TOPIC = "test4";
private final static SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy-MM-dd HH:mm");
private final static SimpleDateFormat sdf2 = new SimpleDateFormat("HH:mm");
public static void main(String[] args) throws Exception {
// 1 设置环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//指定使用eventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 2. 定义数据
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "test-read-group-1");
props.put("deserializer.encoding", "GB2312");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
DataStreamSource<String> text = env.addSource(new FlinkKafkaConsumer011<>(
SOURCE_TOPIC,
new SimpleStringSchema(),
props));
// 3. 处理逻辑
DataStream<Tuple3<String, Integer, String>> counts = text.assignTimestampsAndWatermarks(new WatermarkStrategy<String>() {
@Override
public WatermarkGenerator<String> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new WatermarkGenerator<String>() {
private long maxTimestamp;
private long delay = 1000;
@Override
public void onEvent(String s, long l, WatermarkOutput watermarkOutput) {
Map<String, String> map = gson.fromJson(s, new TypeToken<Map<String, String>>() {
}.getType());
String timestamp = map.getOrDefault("event_timestamp", l + "");
maxTimestamp = Math.max(maxTimestamp, Long.parseLong(timestamp));
}
@Override
public void onPeriodicEmit(WatermarkOutput watermarkOutput) {
watermarkOutput.emitWatermark(new Watermark(maxTimestamp - delay));
}
};
}
}).flatMap(new FlatMapFunction<String, Tuple3<String, Integer, String>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, Integer, String>> out) throws Exception {
//解析message中的json
Map<String, String> map = gson.fromJson(value, new TypeToken<Map<String, String>>() {
}.getType());
String eventTimestamp = map.getOrDefault("event_timestamp", "0");
String windowTimeStart = sdf1.format(new Date(TimeWindow.getWindowStartWithOffset(Long.parseLong(eventTimestamp), 2 * 60 * 1000, 1 * 60 * 1000)));
String windowTimeEnd = sdf2.format(new Date(1 * 60 * 1000 + TimeWindow.getWindowStartWithOffset(Long.parseLong(eventTimestamp), 2 * 60 * 1000, 1 * 60 * 1000)));
String word = map.getOrDefault("word", "");
if (word != null && word.trim().length() > 0) {
out.collect(new Tuple3<>(word.trim(), 1, windowTimeStart + " ~ " + windowTimeEnd));
}
}
})
//按Tuple3里的第0项,即:word分组
.keyBy(value -> value.f0)
//每1分钟算1次,每次算过去2分钟内的数据
.timeWindow(Time.minutes(2), Time.minutes(1))
//然后对Tuple3里的第1项求合
.sum(1);
// 4. 打印结果
counts.addSink(new FlinkKafkaProducer010<>("localhost:9092", SINK_TOPIC,
(SerializationSchema<Tuple3<String, Integer, String>>) element -> (element.f2 + " (" + element.f0 + "," + element.f1 + ")").getBytes()));
counts.print();
// execute program
env.execute("Kafka Streaming WordCount");
}
}
与TumbingWindow最大的区别在于105行,除了指定窗口的size,还指定了slide值,有兴趣的同学可以研究下这个方法:
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size, Time slide) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(SlidingProcessingTimeWindows.of(size, slide));
} else {
return window(SlidingEventTimeWindows.of(size, slide));
}
}
输出结果:
发送到kafka的数据源片段:
...
{"event_datetime":"2020-12-19 14:32:36.873","event_timestamp":"1608359556873","word":"hello"}
{"event_datetime":"2020-12-19 14:32:46.874","event_timestamp":"1608359566874","word":"world"}
{"event_datetime":"2020-12-19 14:32:56.874","event_timestamp":"1608359576874","word":"hello"}
{"event_datetime":"2020-12-19 14:33:06.875","event_timestamp":"1608359586875","word":"hello"}
{"event_datetime":"2020-12-19 14:33:16.876","event_timestamp":"1608359596876","word":"world"}
{"event_datetime":"2020-12-19 14:33:26.877","event_timestamp":"1608359606877","word":"hello"}
{"event_datetime":"2020-12-19 14:33:36.878","event_timestamp":"1608359616878","word":"world"}
{"event_datetime":"2020-12-19 14:33:46.879","event_timestamp":"1608359626879","word":"flink"}
{"event_datetime":"2020-12-19 14:33:56.879","event_timestamp":"1608359636879","word":"hello"}
{"event_datetime":"2020-12-19 14:34:06.880","event_timestamp":"1608359646880","word":"world"}
{"event_datetime":"2020-12-19 14:34:16.881","event_timestamp":"1608359656881","word":"world"}
{"event_datetime":"2020-12-19 14:34:26.883","event_timestamp":"1608359666883","word":"hello"}
{"event_datetime":"2020-12-19 14:34:36.883","event_timestamp":"1608359676883","word":"flink"}
{"event_datetime":"2020-12-19 14:34:46.885","event_timestamp":"1608359686885","word":"flink"}
{"event_datetime":"2020-12-19 14:34:56.885","event_timestamp":"1608359696885","word":"world"}
{"event_datetime":"2020-12-19 14:35:06.885","event_timestamp":"1608359706885","word":"flink"}
...
处理后的结果:
... 3> (world,2,2020-12-19 14:33) 4> (flink,1,2020-12-19 14:33) 2> (hello,3,2020-12-19 14:33) 3> (world,3,2020-12-19 14:34) 2> (hello,1,2020-12-19 14:34) 4> (flink,2,2020-12-19 14:34) ...
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号