
flink 1.11.2 学习笔记(2)-Source/Transform/Sink
一、flink处理的主要过程
从上一节wordcount的示例可以看到,flink的处理过程分为下面3个步骤:
1.1 、添加数据源addSource,这里的数据源可以是文件,网络数据流,MQ,Mysql...
1.2、数据转换(或者称为数据处理),比如wordcount里的处理过程,就是把一行文本,按空格拆分成单词,并按单词计数
1.3、将处理好的结果,输出(或下沉)到目标系统,这里的目标系统,可以是控制台、MQ、Redis、Mysql、ElasticSearch...
可能有同学有疑问,上节wordcount里,最后的结果只是调用了1个print方法,好象并没有addSink的过程?
org.apache.flink.streaming.api.datastream.DataStream#print() 可以看下这个方法的源码:
/**
* Writes a DataStream to the standard output stream (stdout).
*
* <p>For each element of the DataStream the result of {@link Object#toString()} is written.
*
* <p>NOTE: This will print to stdout on the machine where the code is executed, i.e. the Flink
* worker.
*
* @return The closed DataStream.
*/
@PublicEvolving
public DataStreamSink<T> print() {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
return addSink(printFunction).name("Print to Std. Out");
}
其实最后1行,就已经调用了addSink
二、kafka基本操作
下面将把之前WordCount的流式处理版本,其中的Source与Sink改成常用的Kafka:
注:不熟悉kafka的同学,可以参考下面的步骤学习kafka的常用命令行(kafka老手可跳过)
到kafka官网下载最新的版本,并解压到本机。
2.1 启动zookeeper
.\zookeeper-server-start.bat ..\..\config\zookeeper.properties
2.2 启动kafka
.\kafka-server-start.bat ..\..\config\server.properties
2.3 查看topic list
.\kafka-topics.bat --list --zookeeper localhost:2181
2.4 启动procduer
.\kafka-console-producer.bat --broker-list localhost:9092 --topic test1
2.5 启动consumer
.\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test1
添加Source


1 <dependency> 2 <groupId>org.apache.flink</groupId> 3 <artifactId>flink-connector-kafka-0.11_2.12</artifactId> 4 <version>1.11.2</version> 5 </dependency>
代码:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "test-read-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
DataStreamSource<String> text = env.addSource(new FlinkKafkaConsumer011<>(
"test1",
new SimpleStringSchema(),
props));
添加Transform
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//将每行按word拆分
String[] tokens = value.toLowerCase().split("\\b+");
//收集(类似:map-reduce思路)
for (String token : tokens) {
if (token.trim().length() > 0) {
out.collect(new Tuple2<>(token.trim(), 1));
}
}
}
})
//按Tuple2里的第0项,即:word分组
.keyBy(value -> value.f0)
//然后对Tuple2里的第1项求合
.sum(1);
添加Sink
counts.addSink(new FlinkKafkaProducer010<>("localhost:9092", "test2",
(SerializationSchema<Tuple2<String, Integer>>) element -> ("(" + element.f0 + "," + element.f1 + ")").getBytes()));
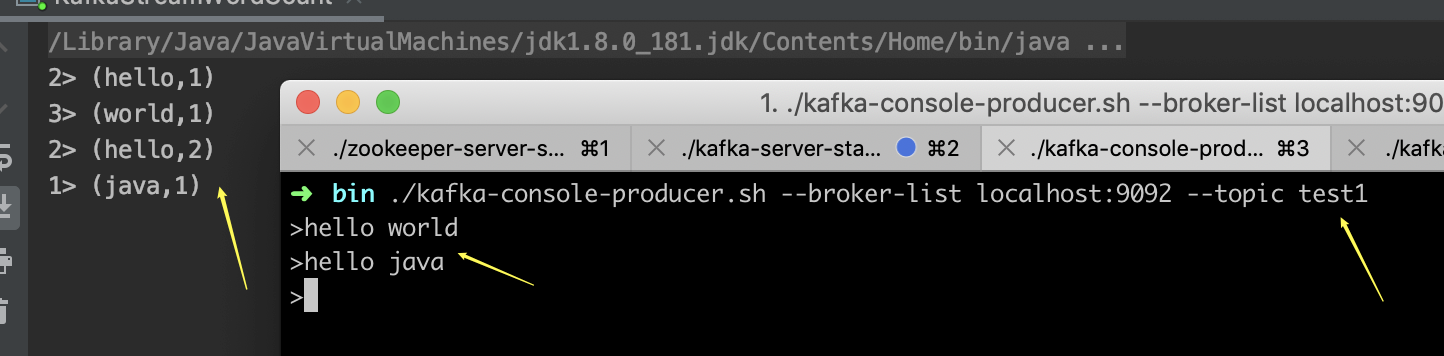
如上图,程序运行起来后,在kafka的proceduer终端,随便输入一些word,相当于发送消息给flink,然后idea的console控制台,输出的统计结果。
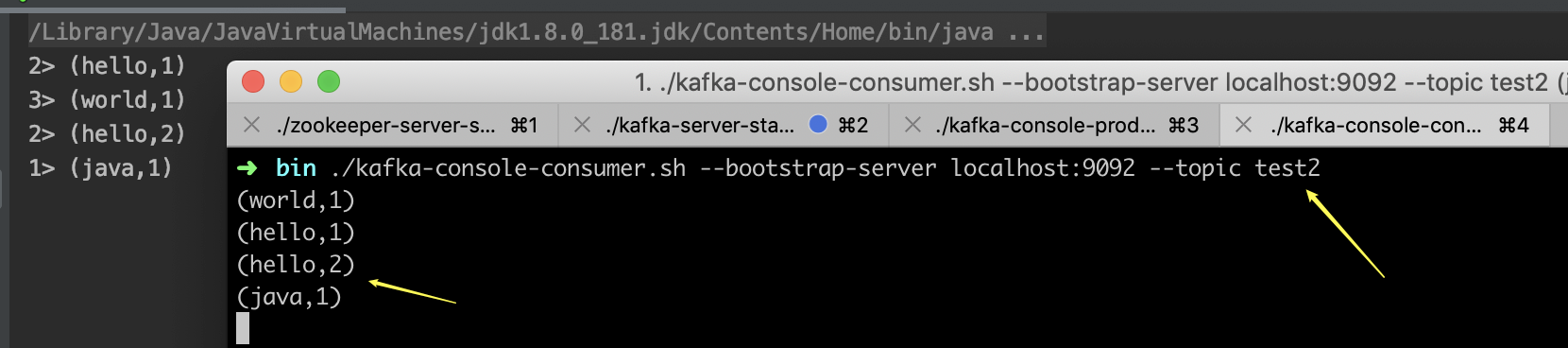
如果此时,再开一个kafka的consumer,可以看到统计结果,也同步发送到了test2这个topic,即实现了kafka的sink.
附:
完整pom文件
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 3 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> 4 <modelVersion>4.0.0</modelVersion> 5 6 <groupId>com.cnblogs.yjmyzz</groupId> 7 <artifactId>flink-demo</artifactId> 8 <version>0.0.1-SNAPSHOT</version> 9 10 <properties> 11 <java.version>1.8</java.version> 12 <flink.version>1.11.2</flink.version> 13 </properties> 14 15 <dependencies> 16 17 <!-- flink --> 18 <dependency> 19 <groupId>org.apache.flink</groupId> 20 <artifactId>flink-core</artifactId> 21 <version>${flink.version}</version> 22 </dependency> 23 24 <dependency> 25 <groupId>org.apache.flink</groupId> 26 <artifactId>flink-java</artifactId> 27 <version>${flink.version}</version> 28 </dependency> 29 30 <dependency> 31 <groupId>org.apache.flink</groupId> 32 <artifactId>flink-scala_2.12</artifactId> 33 <version>${flink.version}</version> 34 </dependency> 35 36 <dependency> 37 <groupId>org.apache.flink</groupId> 38 <artifactId>flink-clients_2.12</artifactId> 39 <version>${flink.version}</version> 40 </dependency> 41 42 <!--kafka--> 43 <dependency> 44 <groupId>org.apache.flink</groupId> 45 <artifactId>flink-connector-kafka-0.11_2.12</artifactId> 46 <version>1.11.2</version> 47 </dependency> 48 49 <dependency> 50 <groupId>org.apache.flink</groupId> 51 <artifactId>flink-test-utils-junit</artifactId> 52 <version>${flink.version}</version> 53 </dependency> 54 </dependencies> 55 56 <repositories> 57 <repository> 58 <id>central</id> 59 <layout>default</layout> 60 <url>https://repo1.maven.org/maven2</url> 61 </repository> 62 <repository> 63 <id>bintray-streamnative-maven</id> 64 <name>bintray</name> 65 <url>https://dl.bintray.com/streamnative/maven</url> 66 </repository> 67 </repositories> 68 69 <build> 70 <plugins> 71 <plugin> 72 <artifactId>maven-compiler-plugin</artifactId> 73 <version>3.1</version> 74 <configuration> 75 <source>1.8</source> 76 <target>1.8</target> 77 </configuration> 78 </plugin> 79 80 <!-- Scala Compiler --> 81 <plugin> 82 <groupId>net.alchim31.maven</groupId> 83 <artifactId>scala-maven-plugin</artifactId> 84 <version>4.4.0</version> 85 <executions> 86 <execution> 87 <id>scala-compile-first</id> 88 <phase>process-resources</phase> 89 <goals> 90 <goal>compile</goal> 91 </goals> 92 </execution> 93 </executions> 94 <configuration> 95 <jvmArgs> 96 <jvmArg>-Xms128m</jvmArg> 97 <jvmArg>-Xmx512m</jvmArg> 98 </jvmArgs> 99 </configuration> 100 </plugin> 101 102 </plugins> 103 </build> 104 105 </project>
完整java文件
package com.cnblogs.yjmyzz.flink.demo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import org.apache.flink.util.Collector;
import java.util.Properties;
/**
* @author 菩提树下的杨过(http://yjmyzz.cnblogs.com/)
*/
public class KafkaStreamWordCount {
public static void main(String[] args) throws Exception {
// 1 设置环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 定义数据
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "test-read-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
DataStreamSource<String> text = env.addSource(new FlinkKafkaConsumer011<>(
"test1",
new SimpleStringSchema(),
props));
// 3. 处理逻辑
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//将每行按word拆分
String[] tokens = value.toLowerCase().split("\\b+");
//收集(类似:map-reduce思路)
for (String token : tokens) {
if (token.trim().length() > 0) {
out.collect(new Tuple2<>(token.trim(), 1));
}
}
}
})
//按Tuple2里的第0项,即:word分组
.keyBy(value -> value.f0)
//然后对Tuple2里的第1项求合
.sum(1);
// 4. 打印结果
counts.addSink(new FlinkKafkaProducer010<>("localhost:9092", "test2",
(SerializationSchema<Tuple2<String, Integer>>) element -> ("(" + element.f0 + "," + element.f1 + ")").getBytes()));
counts.print();
// execute program
env.execute("Kafka Streaming WordCount");
}
}
作者:菩提树下的杨过
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号