
RHO-1: Not All Tokens Are What You Need 阅读笔记
论文背景
现有的大语言模型主要通过增加参数来提升性能,忽略了数据中的一些噪声tokens。
主要难题:去除tokens可能会导致语义产生偏差,关键在于如何能准确识别无效tokens。
主要贡献
先在高质量语料库对模型进行训练,根据期望分布对tokens进行评分,过滤掉不相关以及不干净的tokens(参考模型);SLM(Selective Language Modeling)利用参考模型中得到的tokens的loss来对该语料库中的tokens评分(训练模型);最后只选择在参考模型和训练模型中都表现出较高超额损失的标记进行语言模型训练。
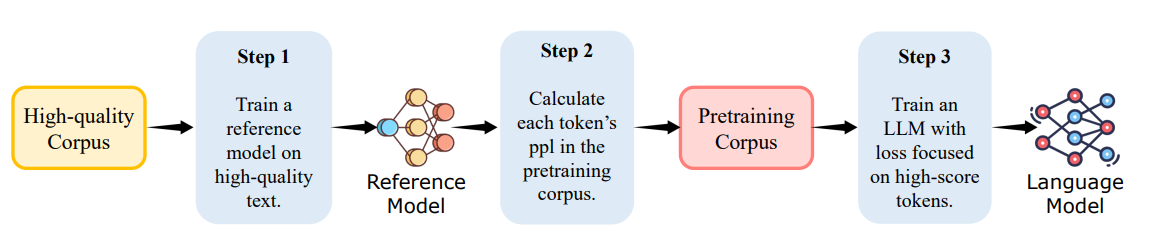
architecture解释:首先通过在高质量的语料集中训练一个参考模型;接着利用该参考模型计算token的ppl(perplexity);最后仅利用得分高的token训练LLM。
对于语料库的研究发现:噪声tokens的Loss不会随着训练时间而增大或者减小,但是单个噪声token在训练过程中却会产生较大的方差,影响结果的准确性。该发现同时也符合直觉判断。
计算过程
参考模型训练好之后,利用RM在更大的语料库中计算token的参考Loss:
\[\mathcal{L}_{\text{RM}}(x_i) = -\log P(x_i|x_{<i})
\]
在使用模型\(\theta\)时的真实Loss:
\[\mathcal{L}_{\text{CLM}}(\theta) = -\frac{1}{N} \sum_{i=1}^{N} \log P(x_i|x_{<i};\theta)
\]
计算差值:
\[\mathcal{L}_{\Delta}(x_i) = \mathcal{L}_{\theta}(x_i) - \mathcal{L}_{\text{RM}}(x_i)
\]
最终SLM的Loss:
\[\mathcal{L}_{\text{SLM}}(\theta) = -\frac{1}{N * k\%} \sum_{i=1}^{N} I_{k\%}(x_i) \cdot \log P(x_i|x_{<i};\theta)
\]
其中,\(I_{k\%}(x_i)\)即前k%的x选取(值为1),其余不选取(值为0)。
Datasets:
数学ML:0.5B,来自GPT以及人工编辑的数学相关tokens的高质量数据集。
一般ML:1.9B,融合多个数据集(Tulu-v2、OpenHermes-2.5)。
预训练数学模型:14B,来自OpenWebMath(OWM)。
与训练一般模型:80B,SlimPajama、StarCoderData、OpenWebMath的融合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号