


R语言 ggplot2包
R语言 ggplot2包的学习
分析数据要做的第一件事情,就是观察它。对于每个变量,哪些值是最常见的?值域是大是小?是否有异常观测?
ggplot2图形之基本语法:
ggplot2的核心理念是将绘图与数据分离,数据相关的绘图与数据无关的绘图分离
ggplot2是按图层作图
ggplot2保有命令式作图的调整函数,使其更具灵活性
ggplot2将常见的统计变换融入到了绘图中。
ggplot的绘图有以下几个特点:第一,有明确的起始(以ggplot函数开始)与终止(一句语句一幅图);其二,图层之间的叠加是靠“+”号实现的,越后面其图层越高。
ggplot图的元素可以主要可以概括如下:最大的是plot(指整张图,包括background和title),其次是axis(包括stick,text,title和stick)、legend(包括backgroud、text、title)、facet这是第二层次,其中facet可以分为外部strip部分(包括backgroud和text)和内部panel部分(包括backgroud、boder和网格线grid,其中粗的叫grid.major,细的叫grid.minor)。
ggplot2里的所有函数可以分为以下几类:
用于运算(我们在此不讲,如fortify_,mean_等)
初始化、展示绘图等命令(ggplot,plot,print等)
按变量组图(facet_等)
真正的绘图命令(stat_,geom_,annotate),这三类就是实现一个函数一个图层的核心函数。
微调图型:严格意义上说,这一类函数不是再实现图层,而是在做局部调整。
aes : 同样适用于修改geom_XXX() aes参数控制了对哪些变量进行图形映射,以及映射方式
图形属性(aes) 横纵坐标、点的大小、颜色,填充色等
完整公式总结:
ggplot(data = , aes(x = , y = )) +
geom_XXX(...) + ... + stat_XXX(...) + ... +
annotate(...) + ... + labs(...) +
scale_XXX(...) + coord_XXX(...) + guides(...) + theme(...) +
facet_XXX(...)
#完整ggplot2绘图示意:
library(ggplot2)
attach(iris)
p <- ggplot(data=iris,aes(x = Sepal.Length,y = Sepal.Width))
p + geom_point(aes(colour = Species)) + stat_smooth() +
labs(title = "Iris of Sepal.length \n According to the Sepal.Width") +
theme_classic() + theme_bw() +annotate("text",x=7,y=4,parse = T,label = "x[1]==x[2]",size=6, family="serif",fontface="italic", colour="darkred")
geom :表示几何对象,它是ggplot中重要的图层控制对象,因为它负责图形渲染的类型。
几何对象(geom_) 上面指定的图形属性需要呈现在一定的几何对象上才能被我们看到,这些承载图形属性的对象可能是点,可能是线,可能是bar
stat :统计变换 比如求均值,求方差等,当我们需要展示出某个变量的某种统计特征的时候,需要用到统计变换
annotate:添加注释 #由于设置的文本会覆盖原来的图中对应的位置,可以改变文本的透明度或者颜色 例: annotate(geom='text')会向图形添加一个单独的文本对象 annotate("text",x=23,y=200,parse=T,label = "x[1]==x[2]")
labs : labs(x = "这是 X 轴", y = "这是 Y 轴", title = "这是标题") ## 修改文字
scale_: 标度是一种函数,它控制了数学空间到图形元素空间的映射。一组连续数据可以映射到X轴坐标,也可以映射到一组连续的渐变色彩。一组分类数据可以映射成为不同的形状,也可以映射成为不同的大小,这就是与aes内的各种美学(shape、color、fill、alpha)调整有关的函数。
coord_:调整坐标,控制了图形的坐标轴并影响所有图形元素. 调整坐标 coord_flip()来翻转坐标轴。使用xlim()和ylim()来设置连续型坐标轴的最小值和最大值 coord_cartesian(xlim=c(0,100),ylim=c(0,100))
guides:调整所有的text。
theme:调整不与数据有关的图的元素的函数。theme函数采用了四个简单地函数来调整所有的主题特征:element_text调整字体,element_line调整主题内的所有线,element_rect调整所有的块,element_blank清空。theme(panel.grid =element_blank()) ## 删去网格线
facet :控制分组绘图的方法和排列形式
# 不指定数据集时,data = NULL
一个图形对象就是一个包含数据,映射,图层,标度,坐标和分面的列表,外加组件options
ggplot(数据, 映射) geom_xxx(映射, 数据) stat_xxx(映射, 数据)
# 通过“+”实现不同图层的相应累加,且越往后的图层表现在上方
点(point, text):往往只有x、y指定位置,有shape但没有fill
线(line,vline,abline,hline,stat_function等):一般是基于函数来处理位置
射(segment):特征是指定位置有xend和yend,表示射线方向
面(tile, rect):这类一般有xmax,xmin,ymax,ymin指定位置
棒(boxplot,bin,bar,histogram):往往是二维或一维变量,具有width属性
带(ribbon,smooth):透明是特征是透明的fill
补:包括rug图,误差棒(errorbar,errorbarh)
然后,就是按照你的需要一步步加图层了(使用“+”)。
*********************
基本语法:
数据(data):将要展示的数据;
映射(mapping):数据中的变量到图形成分的映射;
几何对象(geom):用来展示数据的几何对象,如geom_point,geom_bar,geom_abline;
图形属性(aes):图形属性决定了图形的外观,如字体大小、标签位置及刻度线;
标度(scale):决定了变量如何被映射到图形属性上;
坐标(coordinate):数据如何被映射到图中。如coord_cartesian:笛卡尔坐标、coord_polar:极坐标、coord_map:地理投影;
统计变换(stat):对数据进行汇总,如箱线图:stat_boxplot、线图:stat_abline、直方图:stat_bin
分面(facet):用来描述数据如何被拆分为子集,以及对不同子集是如何绘制的。
位置调整(position):对图形位置做精细控制。
创建ggplot对象:使用ggplot函数:
ggplot(data,mapping=aes(),...,environment=globalenv())
| 参数 | 描述 | 默认值 |
| data | 要绘图的数据框 | |
| mapping | 一系列图形属性的映射 | aes() |
| environment | 图形属性参数所在的环境 | globalenv() |
| ... |
几何对象:
为了指定图形类型,必须加入图层,可采用layer()函数。可以使用“point”等短名称来指定几何对象。layer函数允许将几何对象作为名称和值的配对,这样就不需要指出函数全名,而只需要geom_后面的部分。几何对象如下:
| 几何对象函数 | 描述 |
| geom_abline | 线图,由斜率和截距指定 |
| geom_area | 面积图(即连续的条形图) |
| geom_bar | 条形图 |
| geom_bin2d | 二维封箱的热图 |
| geom_blank | 空的几何对象,什么也不画 |
| geom_boxplot | 箱线图 |
| geom_contour | 等高线图 |
| geom_crossbar | crossbar图(类似于箱线图,但没有触须和极值点) |
| geom_density | 密度图 |
| geom_density2d | 二维密度图 |
| geom_errorbar | 误差线(通常添加到其他图形上,比如柱状图、点图、线图等) |
| geom_errorbarh | 水平误差线 |
| geom_freqpoly | 频率多边形(类似于直方图) |
| geom_hex | 六边形图(通常用于六边形封箱) |
| geom_histogram | 直方图 |
| geom_hline | 水平线 |
| geom_jitter | 点、自动添加了扰动 |
| geom_line | 线 |
| geom_linerange | 区间,用竖直线来表示 |
| geom_path | 几何路径,由一组点按顺序连接 |
| geom_point | 点 |
| geom_pointrange | 一条垂直线,线的中间有一个点(与Crossbar图和箱线图相关,可以用来表示线的范围) |
| geom_polygon | 多边形 |
| geom_quantile | 一组分位数线(来自分位数回归) |
| geom_rect | 二维的长方形 |
| geom_ribbon | 彩虹图(在连续的x值上表示y的范围,例如Tufte著名的拿破仑远征图) |
| geom_rug | 触须 |
| geom_segment | 线段 |
| geom_smooth | 平滑的条件均值 |
| geom_step | 阶梯图 |
| geom_text | 文本 |
| geom_tile | 瓦片(即一个个的小长方形或多边形) |
| geom_vline | 竖直线 |
统计变换
| 统计变换函数 | 描述 |
| stat_abline | 添加线条,用斜率和截距表示 |
| stat_bin | 分割数据,然后绘制直方图 |
| stat_bin2d | 二维密度图,用矩阵表示 |
| stat_binhex | 二维密度图,用六边形表示 |
| stat_boxplot | 绘制带触须的箱线图 |
| stat_contour | 绘制三维数据的等高线图 |
| stat_density | 绘制密度图 |
| stat_density2d | 绘制二维密度图 |
| stat_function | 添加函数曲线 |
| stat_hline | 添加水平线 |
| stat_identity | 绘制原始数据,不进行统计变换 |
| stat_qq | 绘制Q-Q图 |
| stat_quantile | 连续的分位线 |
| stat_smooth | 添加平滑曲线 |
| stat_spoke | 绘制有方向的数据点(由x和y指定位置,angle指定角度) |
| stat_sum | 绘制不重复的取值之和(通常用在三点图上) |
| stat_summary | 绘制汇总数据 |
| stat_unique | 绘制不同的数值,去掉重复的数值 |
| stat_vline | 绘制竖直线 |
标度函数
| 标度函数 | 描述 |
| scale_alpha | alpha通道值(灰度) |
| scale_brewer | 调色板,来自colorbrewer.org网站展示的颜色标度 |
| scale_continuous | 连续标度 |
| scale_data | 日期 |
| scale_datetime | 日期和时间 |
| scale_discrete | 离散值 |
| scale_gradient | 两种颜色构建的渐变色 |
| scale_gradient2 | 3中颜色构建的渐变色 |
| scale_gradientn | n种颜色构建的渐变色 |
| scale_grey | 灰度颜色 |
| scale_hue | 均匀色调 |
| scale_identity | 直接使用指定的取值,不进行标度转换 |
| scale_linetype | 用线条模式来展示不同 |
| scale_manual | 手动指定离散标度 |
| scale_shape | 用不同的形状来展示不同的数值 |
| scale_size | 用不同大小的对象来展示不同的数值 |
坐标系
| 坐标函数 | 描述 |
| coord_cartesian | 笛卡儿坐标 |
| coord_equal | 等尺度坐标(斜率为1) |
| coord_flip | 翻转笛卡儿坐标 |
| coord_map | 地图投影 |
| coord_polar | 极坐标投影 |
| coord_trans | 变换笛卡儿坐标 |
分面
| 分面函数 | 描述 |
| facet_grid | 将分面放置在二维网格中 |
| facet_wrap | 将一维的分面按二维排列 |
位置
| 定位函数 | 描述 |
| position_dodge | 并列 |
| position_fill | 填充 |
| position_identity | 不对位置进行处理 |
| position_jitter | 扰动处理 |
| position_stack | 堆叠处理 |
Chap1. R 基础
## 加载文件
- 默认情况下,数据集中的字符串(String)会被视为因子(Factor)处理,此时可以设置
stringAsFactors = FALSE,将文本变量视为字符串表示。 - 读取xlsx和xls文件:package
xlsx(Java)和gdata(Perl) foreign:read.spss;read.octave;read.systat;read.xport;read.dta
Chap2. 快速探索数据(略)
## 概述 qplot()函数的语法与基础绘图系统类似,简短易输入,通常用于探索性数据分析。qplot(x,y,data,geom=c(xx,xx))
条形图
barplot()第一个向量用来设定条形的高度,第二个向量用来设定每个条形对应的标签(可选)。变量值条形图: 两个输入变量,x为分类变量,y表示变量值频数条形图:一个输入变量,需要注意连续x轴和离散x轴的差异。
直方图
与条形图不同的地方在于,x为连续型变量
箱线图
- 需要传递两个向量:x和y
- 在x轴上引入两变量的交互:
interaction() - Question:基础绘图系统和ggplot2的箱线图略有不同。
绘制函数图像
ggplot(data.frame(x=c(0,20)), aes(x=x)) + stat_function(fun=myfun, geom = "line")
Chap3. 条形图
重要细节:条形图的高度表示的是数据集中变量的频数,还是表示变量取值本身
## 概述 条形图通常用来展示不同的分类下(x轴)某个数值型变量的取值(y轴),其条形高度既可以表示数据集中变量的频数,也可以表示变量取值本身。
参数
fill:改变条形图的填充色;colour:添加边框线;position:改变条形图的类型;linetype:线型scale_fill_brewer()和scale_fill_manual()设置颜色scale_fill_brewer(palette="Pastell")
条形图
- 频数条形图:只需要一个输入变量,当变量为连续型变量时,等价于直方图。
- 颜色映射在
aes()内部完成,而颜色的重新设定在aes()外部完成。 - 排序:
ggplot(upc, aes=(x=reorder(Abb, Change)), y =Change, fill = Region) - 正负条形图着色:首先,创建一个对取值正负情况进行标示的变量,然后参数设定为
position='identity',这可以避免系统因对负值绘制堆积条形而发出的警告信息。 guide=FALSE删除图例width调整条形图的条形宽度;position_dodge(0.7)调整条形间距(中心距离)- 堆积条形图:
geom_bar(stat='identity')默认情况 - 更改图例颜色顺序:
guides(fill = guide_legend(reverse=TRUE)) - 调用调色板
scale_fill_brewer(palette='Pastell')和手动:scale_fill_manual() - 百分比堆积图:首先利用plyr包种的ddply()转化数据,然后再绘图.
- 添加 数据标签:
geom_text(aes(y = label_y, label=Weight),vjust=xxx)其中y用来控制标签的位置 - 绘制Cleveland点图:通常都会设置成根据x轴对应的连续变量的大小取值对数据进行排序。
reorder(x,y):先将x转化为因子,然后根据y对其进行排序。- 主题系统(Theming System):
theme(panel.grid.major.x = element_blank(),panel.grid.minor.x = element_blank())
汇总好的数据集绘制条形图:
x <- c('A','B','C','D','E')y <- c(13,22,16,31,8)df <- data.frame(x= x, y = y)ggplot(data = df, mapping = aes(x = x, y = y)) + geom_bar(stat= 'identity')
对于条形图的y轴就是数据框中原本的数值时,必须将geom_bar()函数中stat(统计转换)参数设置为’identity’,即对原始数据集不作任何统计变换,而该参数的默认值为’count’,即观测数量。
使用明细数据集绘制条形图:
-
set.seed(1234)
x <- sample(c('A','B','C','D'), size = 1000, replace= TRUE, prob = c(0.2,0.3,0.3,0.2))
y <- rnorm(1000) * 1000
df = data.frame(x= x, y = y)
ggplot(data = x = x, mapping = aes(x = factor(x), y = ..count..))+ geom_bar(stat = 'count')
数据集本身是明细数据,而对于统计某个离散变量出现的频次时,geom_bar()函数中stat(统计转换)参数只能设置为默认,即’count’。
当然,如果需要对明细数据中的某个离散变量进行聚合(均值、求和、最大、最小、方差等)后再绘制条形图的话,建议先使用dplyr包中的group_by()函数和summarize()函数实现数据汇总,具体可参见:
从x轴的数据类型来看:有字符型的x值也有数值型的x值
上面的两幅图对应的x轴均为离散的字符型值,如果x值是数值型时,该如何正确绘制条形图?
set.seed(1234)x <- sample(c(1,2,4,6,7), size = 1000, replace = TRUE,prob = c(0.1,0.2,0.2,0.3,0.2))ggplot(data = data.frame(x = x), mapping= aes(x = x, y = ..count..)) + geom_bar(stat = 'count')
如果直接使用数值型变量作为条形图的x轴,我们会发现条形图之间产生空缺,这个空缺其实对应的是3和5两个值,这样的图形并不美观。为了能够使条形图之间不存在类似的空缺,需要将数值型的x转换为因子,即factor(x),如下图所示:
ggplot(data = data.frame(x = x), mapping = aes(x = factor(x), y = ..count..))+ geom_bar(stat = 'count')
上面几幅图的颜色均为灰色的,显得并不是那么亮眼,为了使颜色更加丰富多彩,可以在geom_bar()函数内通过fill参数可colour参数设置条形图的填充色和边框色,例如:
ggplot(data = data.frame(x = x), mapping = aes(x = factor(x), y = ..count..))+ geom_bar(stat = 'count', fill = 'steelblue', colour = 'darkred')
关于颜色的选择可以在R控制台中输入colours(),将返回657种颜色的字符。如果想查看所有含红色的颜色值,可以输入colours()[grep(‘red’,
colours())]返回27种红色。
绘制簇条形图
以上绘制的条形图均是基于一个离散变量作为x轴,如果想绘制两个离散变量的条形图即簇条形图该如何处理呢?具体见下方例子:
x <- rep(1:5, each = 3)y <- rep(c('A','B','C'),times = 5)set.seed(1234)z <- round(runif(min = 10, max = 20, n = 15)) df <- data.frame(x= x, y = y, z = z)ggplot(data = df, mapping = aes(x = factor(x), y = z,fill = y)) + geom_bar(stat = 'identity', position = 'dodge')
对于簇条形图只需在ggplot()函数的aes()参数中将其他离散变量赋给fill参数即可。这里的position参数表示条形图的摆放形式,默认为堆叠式(stack),还可以是百分比的堆叠式。下面分别设置这两种参数,查看一下条形图的摆放形式。
堆叠式:
ggplot(data = df, mapping = aes(x = factor(x), y = z, fill = y)) + geom_bar(stat= 'identity', position = 'stack')
发现一个问题,条形图的堆叠顺序(A,B,C)与图例顺序(C,B,A)恰好相反,这个问题该如何处理呢?很简单,只需再添加guides()函数进行设置即可,如下所示:
ggplot(data = df, mapping = aes(x = factor(x), y = z, fill = y)) + geom_bar(stat= 'identity', position = 'stack') + guides(fill = guide_legend(reverse= TRUE))
guides()函数将图例引到fill属性中,再使图例反转即可。
百分比堆叠式:
ggplot(data = df, mapping = aes(x = factor(x), y = z, fill = y)) + geom_bar(stat= 'identity', position = 'fill')
颜色配置:
同样,如果觉得R自动配置的填充色不好看,还可以根据自定义的形式更改条形图的填充色,具体使用scale_fill_brewer()和scale_fill_manual()函数进行颜色设置。
scale_fill_brewer()函数使用R自带的ColorBrewer画板
ggplot(data = df, mapping = aes(x = factor(x), y = z, fill = y)) + geom_bar(stat= 'identity', position = 'dodge') + scale_fill_brewer(palette = 'Accent')
具体的调色板颜色可以查看scale_fill_brewer()函数的帮助。
scale_fill_manual()函数允许用户给指定的分类水平设置响应的色彩,个人觉得这个比较方便
col <- c('darkred','skyblue','purple')ggplot(data = df, mapping =aes(x = factor(x), y = z, fill = y)) + geom_bar(stat = 'identity', colour= 'black', position = 'dodge') + scale_fill_manual(values = col, limits= c('B','C','A')) + xlab('x')
a <- ggplot(mpg, aes(x=hwy))
a + stat_bin(aes(fill=..count.., color=-1*..ndensity..), binwidth = 1)统计方法有输入,有输出。通常输入为x和y。输出值会以例的形式追加到当前操作的数据拷贝中。比如上例中的stat_bin函数,就会生成四列新数据,分别为count, density, ncount以及ndensity。在访问这些新列的时候,使用..name..的方式。
该如何绘制有序的条形图?
#不经排序的条形图,默认按x值的顺序产生条形图x <- c('A','B','C','D','E','F','G')y <-c('xx','yy','yy','xx','xx','xx','yy')z <- c(10,33,12,9,16,23,11)df<- data.frame(x = x, y = y, z = z)ggplot(data = df, mapping = aes(x= x, y = z, fill = y)) + geom_bar(stat = 'identity')
按z值的大小,重新排列条形图的顺序,只需将aes()中x的属性用reorder()函数更改即可。
ggplot(data = df, mapping = aes(x = reorder(x, z), y = z, fill = y)) +geom_bar(stat = 'identity') + xlab('x')
关于条形图的微调
如何y轴的正负值区分开来,并去除图例
-
set.seed(12)
x <- 1980 + 1:35
y <- round(100*rnorm(35))
df <- data.frame(x = x,y = y)
# 判断y是否为正值
df <- transform(df,judge = ifelse(y>0,"YES","NO"))
# 去除图例用theme()主题函数
ggplot(df,aes(x = x,y = y,fill = judge))+
geom_bar(stat = "identity")+
theme(legend.position= "")+
xlab("Year")+
scale_fill_manual(values = c("darkred","blue"))
stat参数和position参数均设置为identity,目的是图形绘制不要求对原始数据做任何的变换,包括统计变换和图形变换,排除图例可以通过scale_fill_manual()函数将参数guide设置为FALSE,同时该函数还可以自定义填充色,一举两得。
ggplot(data = df, mapping = aes(x = x, y = y, fill = judge))+
geom_bar(stat = 'identity', position = 'identity')+
scale_fill_manual(values = c('blue','red'), guide = FALSE)+
xlab('Year')
调整条形图的条形宽度和条形间距
geom_bar()函数可以非常灵活的将条形图的条形宽度进行变宽或变窄设置,具体通过函数的width参数实现,width的最大值为1,默认为0.9。
x <- c("A","B","C","D","E")
y <- c(10,20,15,22,18)
df <- data.frame(x = x,y = y)
# 不作任何条形宽度的调整
ggplot(df,aes(x = x,y = y))+
geom_bar(stat = "identity",fill = "steelblue",colour = "black")
# 使条形宽度变宽
ggplot(df,aes(x = x,y = y))+geom_bar(stat = "identity",fill = "steelblue",colour = "black",width = 1)
对于簇条形图来说,还可以调整条形之间的距离,默认情况下,条形图的组内条形间隔为0,具体可通过函数的position_dodge参数实现条形距离的调整,为了美观,一般将条形距离设置的比条形宽度大一点。
-
x <- rep(1:5,each = 3)
y <- rep(c("A","B","C"),times = 5)
set.seed(12)
z <- round(runif(min = 10,max = 20,n = 15))
df <- data.frame(x = x,y = y,z = z)
# 不做任何条形宽度和条形距离的调整
ggplot(df,aes(x = factor(x),y = z,fill = y))+
geom_bar(stat = "identity",position = "dodge")
调整条形宽度和条形距离
ggplot(data = df, mapping = aes(x = factor(x), y = z, fill = y)) + geom_bar(stat= 'identity', width = 0.5, position = position_dodge(0.7))
添加数据标签
geom_text()函数可以方便的在图形中添加数值标签,具体微调从几个案例开始:
-
# 添加标签
ggplot(df,aes(x = interaction(x,y),y = z,fill = y))+
geom_bar(stat = "identity")+
geom_text(aes(label = z))
除此之外,还可以调整标签的大小、颜色、位置等。
ggplot(data = df, mapping = aes(x = interaction(x,y), y = z, fill = y))+ geom_bar(stat = 'identity') + ylim(0,max(z)+1) + geom_text(mapping =aes(label = z), size = 8, colour = 'orange', vjust = 1)
ylim设置条形图中y轴的范围;size调整标签字体大小,默认值为5号;colour更换标签颜色;vjust调整标签位置,1为分界线,越大于1,标签越在条形图上界下方,反之则越在条形图上上界上方。
# vjust 调整标签竖直位置,越大,标签越在条形图的上界下方;0.5时,则在中间。
# hjust 调整标签水平位置,越大,标签越在条形图的上界左边;0.5时,则在中间。
对于水平交错的簇条形图,必须通过geom_text()函数中的position_dodge()参数来调整标签位置,hjust=0.5将标签水平居中放置。
ggplot(data = df, mapping = aes(x = x, y = z, fill = y)) + geom_bar(stat= 'identity', position = 'dodge') + geom_text(mapping = aes(label = z),size = 5, colour = 'black', vjust = 1, hjust = .5, position = position_dodge(0.9))
这里的图形位置与标签位置摆放必须一致,即图形位置geom_bar()函数中的position = 'dodge'参数,标签位置geom_text()函数中的position
= position_dodge(0.9)参数。
对于堆叠的簇条形图,必须通过geom_text()函数中的position_stack()参数来调整标签位置,hjust将标签水平居中放置。
ggplot(data = df, mapping = aes(x = x, y = z, fill = y)) + geom_bar(stat= 'identity', position = 'stack') + geom_text(mapping = aes(label = z),size = 5, colour = 'black', vjust = 3.5, hjust = .5, position = position_stack())
这里的图形位置与标签位置摆放必须一致,即图形位置geom_bar()函数中的position = 'stack'参数,标签位置geom_text()函数中的position
= position_stack()参数。
补充:统计变换
若x轴变量为连续的,则用sta = bin;
若离散型的,可用stat = “count”或stat = “identity”
参考资料
R数据可视化手册
R语言_ggplot2:数据分析与图形艺术
Chap4. 折线图
概述
折线图可以反映某种现象的趋势。通常折线图的横坐标是时间变量,纵坐标则是一般的数值型变量。当然,折线图也允许横纵坐标为离散型和数值型。
折线图通常用来对两个连续变量之间的相互依存关系进行可视化。其中x也可以是因子型变量。
简单折线图
geom_line()
- 对于因子型变量,必须使用
aes(group=1)以确保ggplot()知道这些数据点属于同一个分组,从而应该用一条折线连在一起。 - 数据标记相互重叠:需要相应地左移或者右移连接线以避免点线偏离。
geom_line(position=position_dodge(0.2)) - 参数:线型(linetype),线宽(size),颜色(colour):边框线
- 在
aes()函数外部设定颜色、线宽、线型和点型等参数会将所有目标对象设定为同样的参数值。 - 面积图:
geom_area(),alpha调节透明度 - 堆积面积图:
geom_area()基础上,映射一个因子型比那里给填充色(fill)即可 - 添加置信域:
geom_ribbon(),然后分贝映射一个变量给ymin和ymax。geom_ribbon(aes(ymin=xx,ymax=xx), alpha = 0.2)
一、绘制单条折线图
library(ggplot2)
library(lubridate) #处理日期时间相关的R包,非常有用,强烈推荐
Year <- year(seq(from = as.Date('2006-01-01'), to = as.Date('2015-01-01'), by = 'year'))
Weight <- c(23,35,43,57,60,62,63,66,61,62)
df <- data.frame(Year = Year, Weight = Weight)
ggplot(data = df, mapping = aes(x = factor(Year), y = Weight, group = 1)) + geom_line() + xlab('Year')
有关离散变量的折线图
type <- c('A','B','C','D','E')
quanlity <- c(1,1.1,2.1,1.5,1.7)
df <- data.frame(type = type, quanlity = quanlity)
ggplot(data = df, mapping = aes(x = type, y = quanlity, group = 1)) + geom_line()
有关连续变量的折线图
set.seed(1234)
times <- 1:15
value <- runif(15,min = 5,max = 15)
df <- data.frame(times = times, value = value)
ggplot(data = df, mapping = aes(x = times, y = value)) + geom_line()
善于发现的你,可能会注意到上面三段代码有一个重要的不同之处,那就是第一段和第二段代码中含有‘group = 1’的设置。这样做是因为横坐标的属性设置为了因子,即将连续型的年份和离散型的字符转换为因子,如果不添加‘group = 1’这样的条件,绘图将会报错。故务必需要记住这里的易犯错误的点!
往折线图中添加标记(点) 当数据点密度比较小或采集分布(间隔)不均匀时,为折线图做上标记将会产生非常好的效果。处理的方法非常简单,只需在折线图的基础上再加上geom_point()函数即可。
set.seed(1234)
year <- c(1990,1995,2000,2003,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015)
value <- runif(15, min = 10, max = 50)
df <- data.frame(year = year, value = vlaue)
ggplot(data = df, mapping = aes(x = year, y = value)) + geom_line() + geom_point()
从图中就可以非常明显的看出,刚开始采集的点分布非常散,而后面采集的点就比较密集,这也有助于对图的理解和应用。
二、绘制多条折线图 上面绘制的都是单条这折线图,对于两个或两个以上的折线图该如何绘制呢?也很简单,只需将其他离散变量赋给诸如colour(线条颜色)和linetype(线条形状)的属性即可,具体参见下文例子。
基于颜色的多条折线图
set.seed(1234)
year <- rep(1990:2015, times = 2)
type <- rep(c('A','B'),each = 26)
value <- c(runif(26),runif(26, min = 1,max = 1.5))
df <- data.frame(year = year, type = type, value = value)
ggplot(data = df, mapping = aes(x = year, y = value, colour = type)) + geom_line()
基于形状的多条折线图
ggplot(data = df, mapping = aes(x = year, y = value, linetype= type)) + geom_line()
同样需要注意的是,在绘制多条折线图时,如果横坐标为因子,必须还得加上‘group=分组变量’的参数,否则报错或绘制出错误的图形。
以上绘制的折线图,均采用默认格式,不论是颜色、形状、大小还是透明度,均没有给出自定义的格式。其实ggplot2包也是允许用户根据自己的想法设置这些属性的。
自定义线条或点的颜色—scale_color_manual()
自定义线条类型—scale_linetype_manual()
自定义点的形状—scale_shape__manual()
自定义点的大小或线条的宽度—scale_size__manual()
自定义透明度—scale_alpha__manual()
综合的例子:
ggplot(data = df, mapping = aes(x = year, y = value, linetype = type, colour = type, shape = type, fill = type))+ geom_line() + geom_point() #绘制线图和点图
+ scale_linetype_manual(values = c(1,2)) #自定义线条类型
+ scale_color_manual(values = c('steelblue','darkred')) #自定义颜色
+ scale_shape_manual(values = c(21,23)) #自定义点形状
+ scale_fill_manual(values = c('red','black')) #自定义点的填充色
虽然这幅图画的优点夸张,目的是想说明可以通过自定义的方式,想怎么改就可以怎么改。前提是aes()属性的内容与自定义的内容对应上。
三、绘制堆积面积图
绘制堆叠的面积图只需要geom_area()函数再加上一个离散变量映射到fill就可以轻松实现,先忙咱小试牛刀一下。
set.seed(1234)
year <- rep(1990:2015, times = 2)
type <- rep(c('A','B'),each = 26)
value <- c(runif(26),runif(26, min = 1,max = 1.5))
df <- data.frame(year = year, type = type, value = value)
ggplot(data = df, mapping = aes(x = year, y = value, fill = type)) + geom_area()
一幅堆叠的面积图就轻松绘制成功,但我们发现,堆叠的顺序与图例的顺序恰好相反,不用急,只需要加一句命令即可:
ggplot(data = df, mapping = aes(x = year, y = value, fill = type)) + geom_area() + guides(fill = guide_legend(reverse = TRUE))
如果需要为每一块面积图的顶部加上一条直线,可以通过如下两种方式:
ggplot(data = df, mapping = aes(x = year, y = value, fill = type)) + geom_area(colour = 'black', size =1, alpha = .7) + guides(fill = guide_legend(reverse = TRUE))
其中,colour设置面积图边框的颜色;size设置边框线的粗细;alpha设置面积图和边框线的透明度。
ggplot(data = df, mapping = aes(x = year, y = value, fill = type)) + geom_area(alpha = 0.6) + geom_line(colour = 'black', size = 1, position = 'stack', alpha = 0.6) + guides(fill = guide_legend(reverse = TRUE))
该方法是通过添加堆叠线条(必须设置geom_line()中position参数为‘stack’,否则只是添加了两条线,无法与面积图的顶部重合)。这两幅图的区别在于第二种方式没有绘制面积图左右边框和底边框。在实际应用中,建议不要在面积图中绘制边框线,因为边框的存在可能产生误导。
四、绘制百分比堆积面积图
在面积图中,也可以方便快捷的绘制出百分比堆积面积图,具体操作如下:
set.seed(1234)
year <- rep(1990:2015, times = 4)
type <- rep(c('A','B','C','D'),each = 26)
value <- c(runif(26),runif(26, min = 1,max = 1.5), runif(26, min = 1.5,max = 2), runif(26, min = 2,max = 2.5))
df <- data.frame(year = year, type = type, value = value)
ggplot(data = df, mapping = aes(x = year, y = value, fill = type)) + geom_area(position = 'fill', alpha = 0.6) + guides(fill = guide_legend(reverse = TRUE))
但通过这种方式(设置面积图的positon='fill')存在一点点小缺陷,即无法绘制出百分比堆积面积图顶部的线条,该如何实现呢?这里只需要对原始数据集做一步汇总工作,让后按部就班的绘制面积图即可。
library(dplyr)
df_by_type <- group_by(.data = df, year)
df_summarize <- mutate(.data = df_by_type, value2 = value/sum(value))
有关dplyr包的用法可参考:
强大的dplyr包实现数据预处理
ggplot(data = df_summarize, mapping = aes(x = year, y = value2, fill = type)) + geom_area(alpha = 0.6) + geom_line(colour = 'black', size = 1, position = 'stack', alpha = 0.6) + guides(fill = guide_legend(reverse = TRUE))
哈哈,大功告成,就这么简单。
Chap5. 散点图
概述
散点图通常用来刻画两个连续型变量之间的关系。
散点图
geom_point()
- 参数值:
shape(),size=2,colour() - 更改配色与点形:
scale_colour/shape_brewer/manual() - 尽量将不需要高精度的变量映射给图形的大小和颜色属性。
- 调用
scale_size_area()函数使数据点的面积正比于变量值。 - 处理图形重叠问题(overplotting):
- 使用半透明的点
- 将数据分箱(bin),并用矩形表示(适用于量化分析)
stat_bin2d() - 将数据分箱(bin),并用六边形表示
stat_binhex(packages:”hexbin”) - 使用箱线图
- 离散x:调用
geom_point(position_jitter())函数给数据点增加随机扰动。
- 添加回归模型拟合线:
stat_smooth(method=lm,level=0.95) - 添加自己构建的模型拟合线:
geom_line(data=predicted,size=1) dlply()和ldply()函数:切分数据,对各个部分执行某一函数,并对执行结果进行重组。- 散点图中添加模型系数:
+ annotate(parse = TRUE)函数添加文本。利用expression()检验输出结果 - 添加边际地毯(Marginal rugs):
geom_rug() - 添加标签:
geom_text(aes(label=xxx),size=xx,x=xx+0.1)vjust=1:标签文本的顶部与数据点对齐vjust=0:标签文本的底部与数据点对齐hjust=1/0:右对齐/左对齐- 通常先设定
hjust()和vjust()的值为0或1,然后再调整x或y的值来调整文本标签的位置. - 对数坐标轴:需令x或者y乘以一个数值才可以。
- 去掉不需要的标签:将不需要刻画出来的标签赋值为
NA
- 绘制气泡图:
geom_point()和scale_size_area(max_size=15) - 散点图矩阵:base基础绘图系统,
pairs()
散点图通常用来刻画两个连续型变量之间的关系,数据集中的每一条观测都由散点图中的一个点来表示。在散点图中也可以加入一些直线或曲线,用来表示基于统计模型的拟合。当数据集记录很多时,散点图可能会彼此重叠,这种情况往往需要一些预处理操作。
1 基本散点图
散点图可以用来描述两个连续变量之间的关系,一般在做数据探索分析时会使用到,通过散点图发现变量之间的相关性强度、是否线性关系等。
使用geom_point()绘制散点图,并分别映射一个变量到x和y。
|
1
2
|
library(gcookbook)
ggplot(heightweight, aes(x=ageYear, y=heightIn)) + geom_point()
|
可以使用shape和size分别指定点型和点的大小,如果点型包括填充和描边的话,可用fill和color分别指定填充色和描边色。
2 基于类别型变量分组
可将分组变量(因子或字符变量)赋值给颜色或形状属性,实现分组散点图的绘制
可以将因子和字符串等类别型变量映射到散点的颜色或形状。
|
1
2
|
library(gcookbook)
ggplot(heightweight, aes(x=ageYear, y=heightIn, shape=sex, color=sex)) + geom_point()
|
set.seed(112)
x <- rnorm(100,mean = 2,sd = 3)
y <- 1.5+2*x+rnorm(100)
z <- sample(c(0,1),size = 100,replace = TRUE)
df <- data.frame(x = x,y = y,z = z)
# 将数值型变量转换为因子型变量
df$z <- factor(df$z)
#分组变量赋值给颜色属性
ggplot(df,aes(x = x,y = y,colour = z))+
geom_point(size = 3)
#分组变量赋值给形状属性
ggplot(df,aes(x = x,y = y,shape = z))+
geom_point(size = 3)
# 分组变量同时赋给颜色属性和形状属性
ggplot(df,aes(x = x,y = y,shape = z,colour = z))+
geom_point(size = 3)+
scale_color_brewer(palette = "Accent")+
scale_shape_manual(values = c(2,16))

注意点的形状,21-25之间的点的形状,既可以赋值边框颜色,又可以赋值填充色。
将离散型变量或因子映射给颜色属性或形状属性
x <- c(10,13,11,15,18,20,21,22,24,26)
y <- c(76,60,70,58,55,48,44,40,26,18)
z <- c(100,120,300,180,80,210,30,95,145,420)
df <- data.frame(x = x,y = y,z = z)
# 将连续型变量映射给颜色属性
ggplot(df,aes(x = x,y = y,colour = z))+
geom_point(size = 3)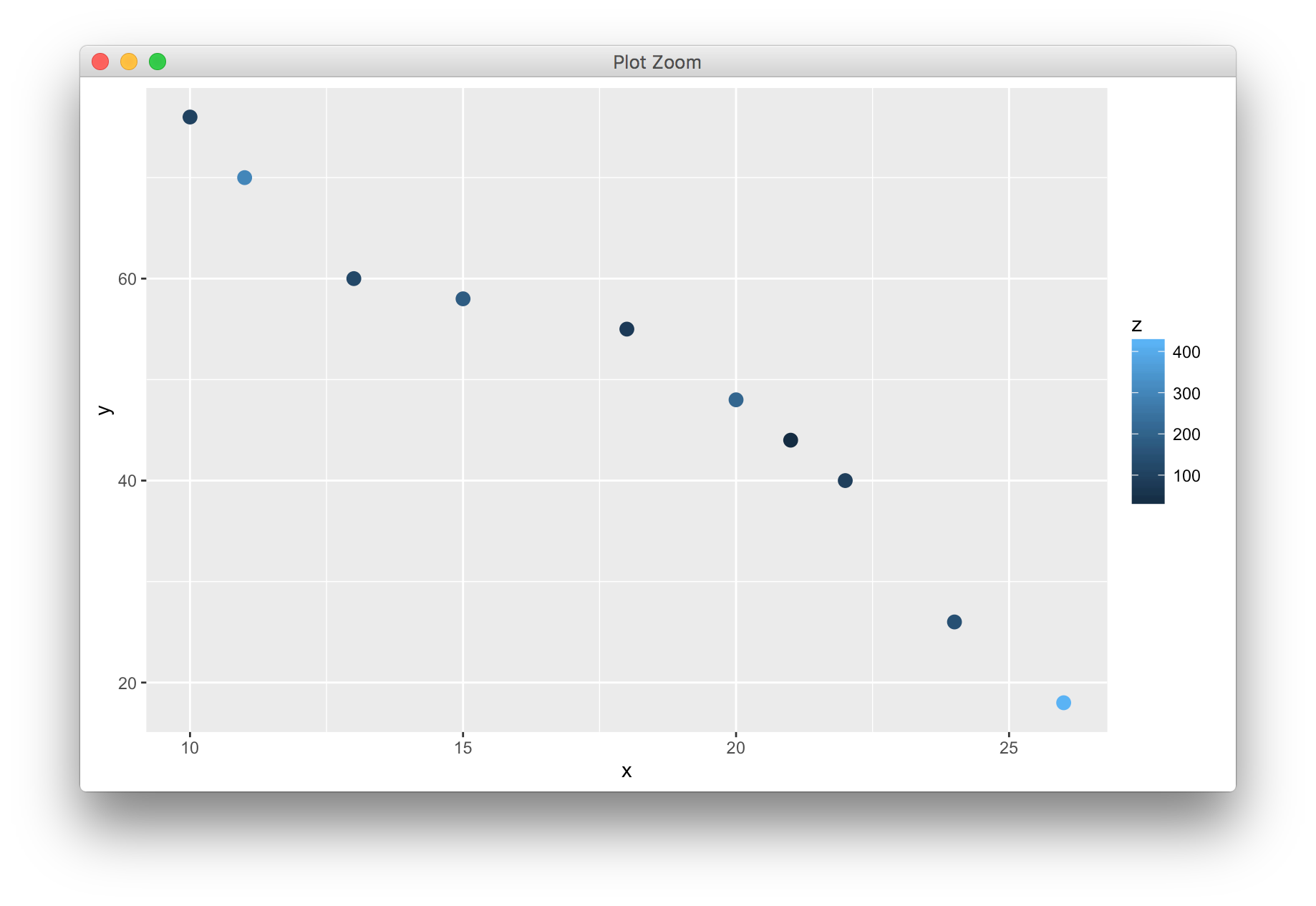
图例上,颜色越深而对应的值越小,如何将值的大小与颜色的深浅保持一致?只需要人为的设置色阶,从低到高设置不同的颜色即可
3 基于连续型变量映射
当然,还可以将连续型变量映射到散点的颜色或大小等存在渐变的属性上,从而呈现三个连续型变量之间的关系。其中人眼对于x轴和y轴所对应变量的变化更为敏感,而对颜色和大小的变化则不那么敏感。
|
1
2
|
library(gcookbook)
ggplot(heightweight, aes(x=ageYear, y=heightIn, size=weightLb, color=weightLb)) + geom_point()
|
同时映射类别型变量和连续型变量,并设置散点的面积正比于连续型变量的大小,默认为非线性映射。
|
1
2
|
library(gcookbook)
ggplot(heightweight, aes(x=ageYear, y=heightIn, size=weightLb, color=sex)) + geom_point(alpha=.5) + scale_size_area()
|
# 将连续型变量映射给颜色属性,同时设置双色梯度
ggplot(df,aes(x = x,y = y,colour = z))+geom_point(size = 3)+scale_colour_gradient(low = "lightblue",high = "darkblue")
# 将连续变量映射给大小属性
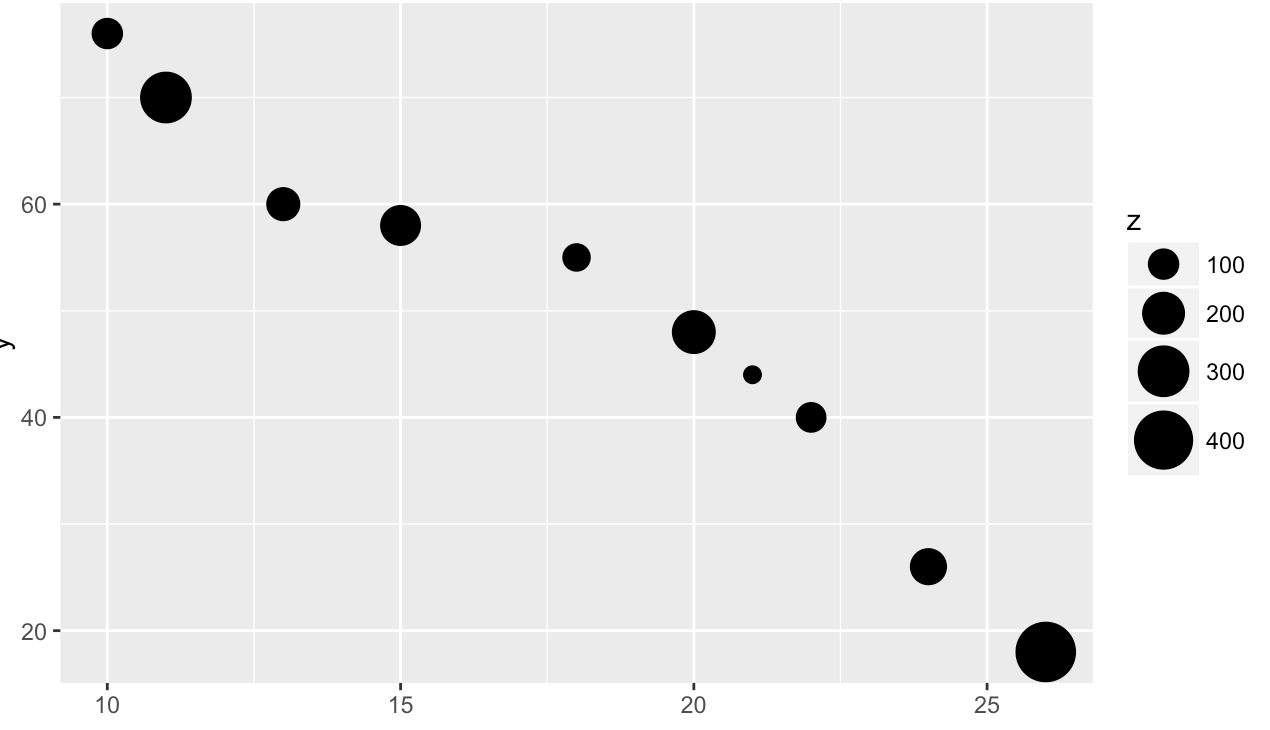
ggplot(df,aes(x = x,y = y,size = z))+ geom_point()
# 将连续型变量赋给颜色属性或大小属性,自定义双色梯度,色阶间隔顺序由低到高
ggplot(df,aes(x = x,y = y,fill = z))+ geom_point(shape = 21,size = 3)+
scale_fill_gradient(low = "lightblue",high = "darkblue",breaks = c(100,150,200,300,350,400))
# 自定义球大小的间隔
ggplot(df,aes(x = x,y = y,size = z))+geom_point()+
scale_size_continuous(breaks = c(100,150,200,250,300,350,400),guide = guide_legend())
# scale_size(breaks = c(100,150,200,250,300,350,400))结果一样
# 将连续变量值的大小与球的大小成比例
ggplot(df,aes(x = x,y = y,size = z))+geom_point()+scale_size_area(max_size = 10)
# scale_size_area()可以确保数值0映射为0,max_size保证映射最大的点的大小
4 处理散点重合
处理散点重合的基本思路包括:
当数据点非常多时,可能会导致数据点重叠严重,处理方法如下:
1)使用半透明的点
2)数据分箱,并用矩形表示{stat_bin2d()}
3)数据分箱,并用六边形表示{stat_binhex()}
4)使用二维密度估计,并将等高线添加到散点图中{stat_density2d()}
5)向散点图中添加边际地毯
set.seed(112)
x <- rnorm(10000)
y <- rnorm(10000,0,2)
df <- data.frame(x = x,y = y)
# 不作任何处理
ggplot(df,aes(x = x,y = y))+
geom_point()
# 使用透明度处理点的重叠问题
ggplot(df,aes(x = x,y = y))+geom_point(alpha = 0.1)
# 分箱,并用矩阵表示
ggplot(df,aes(x = x,y = y))+stat_bin2d()
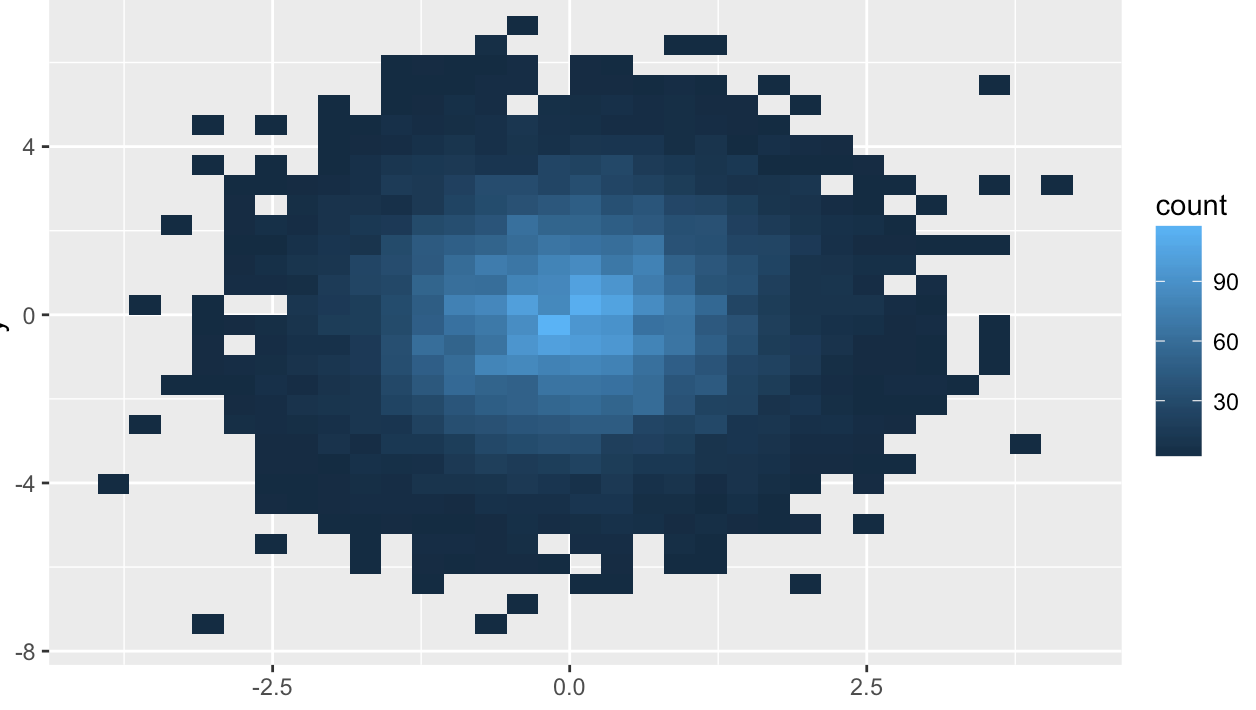
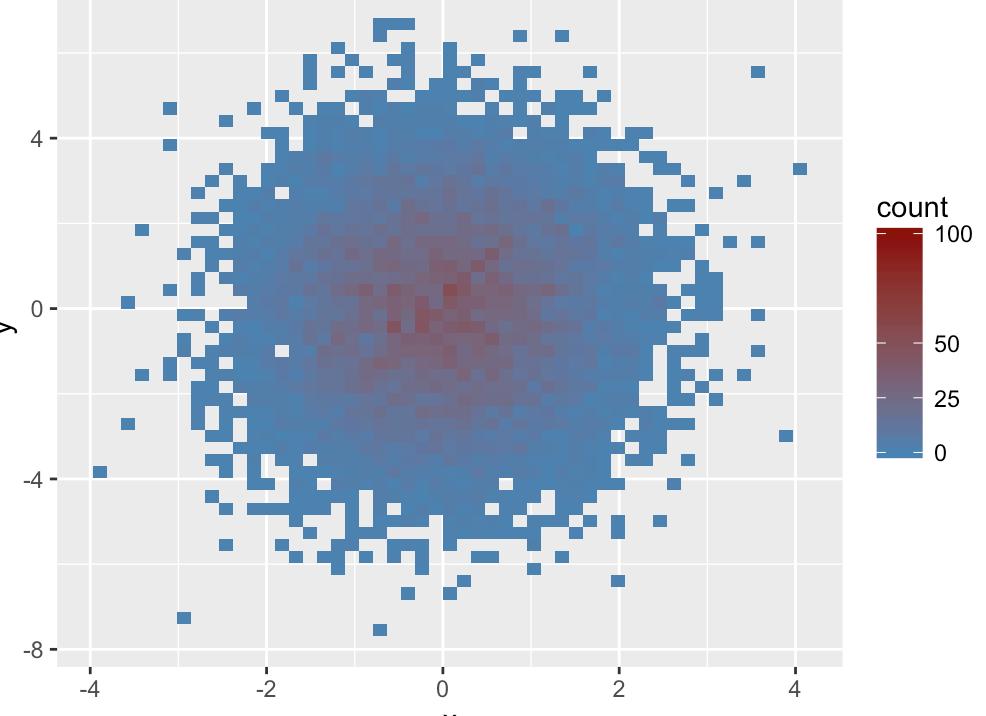
默认情况下,stat_bin2d()函数将x轴和y轴的数据点各分位30段,即参数900个箱子;用户还可以自定义分段个数,以及箱子在垂直和水平方向上的宽度。
# 设置bins为50,
ggplot(df,aes(x = x,y = y))+stat_bin2d(bins = 50)+scale_fill_gradient(low = "steelblue",high = "darkred",limits = c(0,100),breaks = c(0,25,50,100))
分箱的具体做法是,将点分箱,并统计每个箱中点的个数,然后通过某种方法可视化这个数量。
# 分箱,用六边形表示,箱子水平和竖直方向的宽度各为0.2,0.3;
# 图例标度范围0-100,显示在图例上的值(0,25,50,100)
ggplot(df,aes(x = x,y = y))+stat_bin_hex(binwidth = c(0.2,0.3))+
scale_fill_gradient(low = "lightgreen",high = "darkred",limits=c(0,100),breaks = c(0,25,50,100))

# 使用stat_density2d作二维密度估计,并将等高线添加到散点图中
ggplot(df,aes(x = x,y = y))+geom_point()+stat_density2d()
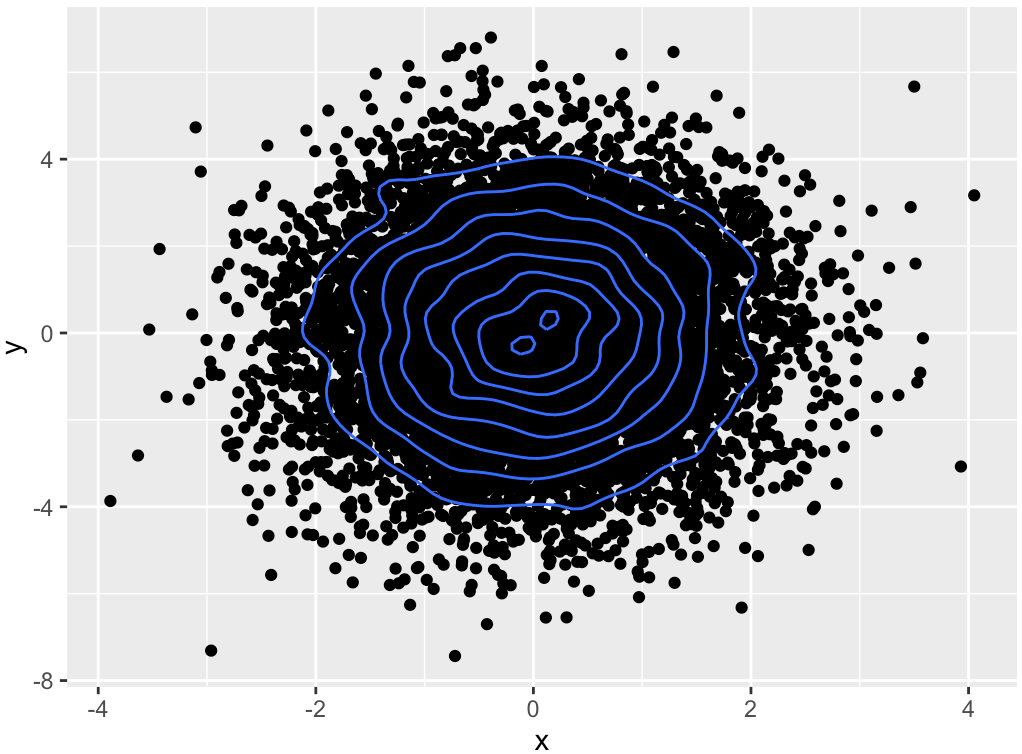
#使用大小与分布密度成正比例的点,不添加等高线
ggplot(df,aes(x = x, y = y)) +stat_density2d(geom = 'point', aes(size = ..density..),contour = FALSE) + scale_size_area()

#使用瓦片图展示数据分布密度情况
ggplot(df,aes(x = x, y = y)) + stat_density2d(geom = 'tile',aes(fill = ..density..),contour = FALSE)

#向散点图中添加边际地毯(轴须线)
ggplot(faithful,aes(x = eruptions, y = waiting)) + geom_point() + geom_rug()

#通过边际地毯,可以快速查看每个坐标轴上数据的分布密疏情况。还可以通过向边际地毯线的位置坐标添加扰动并设定size减少线宽,从而减轻边际地毯线的重叠程度。
ggplot(faithful, aes(x = eruptions, y = waiting)) +geom_point() +geom_rug(position = 'jitter', size = 0.1)
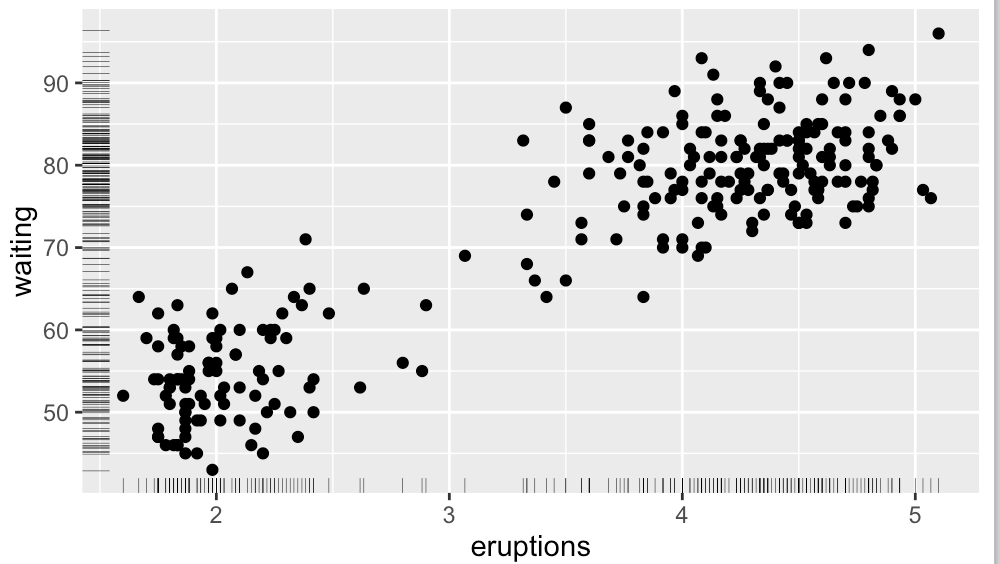
- 设置透明度;
- 使用矩形和六边形等分箱,并且用颜色表示密度。
|
1
2
3
4
5
6
7
8
9
10
11
|
sp <- ggplot(diamonds, aes(x=carat, y=price))
# 未处理
sp + geom_point()
# 设置透明度
sp + geom_point(alpha=.1)
sp + geom_point(alpha=.01)
# 矩形分箱并设置渐变颜色
sp + stat_bin2d(bins=50) + scale_fill_gradient(low="lightblue", high="red")
# 六边形分箱并设置渐变颜色
install.packages("hexbin")
sp + stat_binhex() + scale_fill_gradient(low="lightblue", high="red")
|
以下为六边形分箱的结果。
当x轴和y轴对应一个或两个离散型变量时,例如虽然对应数值,但是数值仅取某些离散点,可以给散点图添加扰动,使得散点分离开来。
|
1
2
3
4
5
6
7
|
sp <- ggplot(ChickWeight, aes(x=Time, y=weight))
# 未处理
sp + geom_point()
# 添加扰动
sp + geom_point(position="jitter")
# 仅添加水平方向上的扰动
sp + geom_point(position=position_jitter(width=.5, height=0))
|
5 添加拟合线
使用stat_smooth()或geom_smooth()添加拟合线和置信域。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
library(gcookbook)
sp <- ggplot(heightweight, aes(x=ageYear, y=heightIn))
# 默认,loess局部加权多项式拟合
sp + geom_point() + stat_smooth()
# 线性拟合,95%置信域
sp + geom_point() + stat_smooth(method=lm)
# 99%置信域
sp + geom_point() + stat_smooth(method=lm, level=0.99)
# 不加置信域
sp + geom_point() + stat_smooth(method=lm, se=FALSE)
# 修改配色
sp + geom_point(color="grey60") + stat_smooth(method=lm, se=FALSE, color="black")
|
以下使用Logistic回归拟合一个二分类的样本,可以看出V1和classn具有二分类关系,Logistic回归曲线也说明了这一点。
|
1
2
3
4
5
6
|
library(MASS)
b <- biopsy
b$classn[b$class=="benign"] <- 0
b$classn[b$class=="malignant"] <- 1
head(b)
ggplot(b, aes(x=V1, y=classn)) + geom_point(position=position_jitter(width=.3, height=.06), alpha=.4, shape=21, size=1.5) + geom_smooth(method="glm", method.args=list(family="binomial"))
|
如果已经将类别型变量映射到散点的颜色或形状,则在添加拟合线时会分别为每一组添加一条拟合线。可以看到身高随着年龄增长而增加,到一定年龄后停止增长,且男性比女性平均身高更高。
|
1
|
ggplot(heightweight, aes(x=ageYear, y=heightIn, color=sex)) + geom_point() + scale_color_brewer(palette="Set1") + geom_smooth()
|
散点图矩阵
散点图矩阵用于展示多幅散点图,pairs()函数可以创建基础的散点图矩阵,以下代码包含mpg、disp、drat和wt中任意两者的散点图。
|
1
|
pairs(~ mpg + disp + drat + wt, data=mtcars, main="Basic Scatter Plot Matrix")
|
car包的scatterplotMatrix()函数也可以生成散点图矩阵,并支持以下操作:
- 以某个因子为条件绘制散点图矩阵;
- 包含线型和平滑拟合曲线;
- 在主对角线放置箱线图、密度图或者直方图;
- 在各单元格的边界添加轴须图。
|
1
2
|
library(car)
scatterplotMatrix(~ mpg + disp + drat + wt, data=mtcars, spread=FALSE, lty.smooth=2, main="Scatter Plot Matrix via car Package")
|
spread=FALSE选项表示不添加展示分散度和对称信息的直线。
再来一个scatterplotMatrix()函数的使用例子,主对角线的核密度曲线改为了直方图,并且直方图以汽车气缸数为条件绘制。
|
1
2
|
library(car)
scatterplotMatrix(~ mpg + disp + drat + wt|cyl, data=mtcars, spread=FALSE, diagonal="histogram", main="Scatter Plot Matrix via car Package")
|
gclus包中的cpairs()函数提供了一个有趣的散点图矩阵变种,支持重排矩阵中变量的位置,让相关性更高的变量更靠近主对角线,还可以对各单元格进行颜色编码来展示变量间的相关性大小。
首先查看各个变量之间相关性的大小:
|
1
|
cor(mtcars[c("mpg", "wt", "disp", "drat")])
|
可以发现相关性最高(0.89)的是车重(wt)和排量(disp),以及车重(wt)和每加仑英里数(mpg)。相关性最低(0.68)的是每加仑英里数(mpg)和后轴比(drat)。以下代码根据相关性大小,对散点图矩阵中的这些变量重新排序并着色。
|
1
2
3
4
5
6
|
library(gclus)
mydata <- mtcars[c(1,3,5,6)]
mydata.corr <- abs(cor(mydata))
mycolors <- dmat.color(mydata.corr)
myorder <- order.single(mydata.corr)
cpairs(mydata, myorder, panel.colors=mycolors, gap=.5, main="Variables Ordered and Colored by Correlation")
|
高密度散点图
当散点图中点数量过大时,数据点的重叠将会导致绘图效果显著变差。对于这种情况,可以使用封箱、颜色和透明度等来指定图中任意点上重叠点的数目。
smoothScatter()函数可利用核密度估计生成用颜色密度来表示点分布的散点图。
|
1
2
3
4
5
6
7
8
|
set.seed(1234)
n <- 10000
c1 <- matrix(rnorm(n ,mean=0, sd=.5), ncol=2)
c2 <- matrix(rnorm(n, mean=3, sd=2), ncol=2)
mydata <- rbind(c1, c2)
mydata <- as.data.frame(mydata)
names(mydata) <- c("x", "y")
smoothScatter(mydata$x, mydata$y, main="Scatterplot Colored by Smoothed Densities")
|
hexbin包中的hexbin()函数将二元变量的封箱放到六边形单元格中。
|
1
2
3
|
library(hexbin)
bin <- hexbin(mydata$x, mydata$y, xbins=50)
plot(bin, main="Hexagonal Binning with 10000 Observations")
|
IDPmisc包中的iplot()函数也可以通过颜色来展示点的密度。
|
1
2
|
library(IDPmisc)
iplot(mydata$x, mydata$y, main="Image Scatter Plot with Color Indicating Density")
|
三维散点图
如果想一次性对三个定量变量的交互进行可视化,那么可以使用scatterplot3d中的scatterplot3d()函数进行绘制。
|
1
2
3
4
|
library(scatterplot3d)
attach(mtcars)
scatterplot3d(wt, disp, mpg, main="Basic 3D Scatter Plot")
detach(mtcars)
|
scatterplot3d()函数提供了许多选项,包括设置图形符号、轴、颜色、线条、网格线、突出显示和角度等功能。例如以下代码生成一幅突出显示效果的三维散点图,增强了纵深感并添加了连接点与水平面的垂直线。
|
1
2
3
4
|
library(scatterplot3d)
attach(mtcars)
scatterplot3d(wt, disp, mpg, pch=16, highlight.3d=TRUE, type="h", main="3D Scatter Plot with Vertical Lines")
detach(mtcars)
|
还可以再加上一个回归面。
|
1
2
3
4
5
6
|
library(scatterplot3d)
attach(mtcars)
s3d <- scatterplot3d(wt, disp, mpg, pch=16, highlight.3d=TRUE, type="h", main="3D Scatter Plot with Vertical Lines and Regression Plane")
fit <- lm(mpg ~ wt + disp)
s3d$plane3d(fit)
detach(mtcars)
|
使用rgl包中的plot3d()函数可创建交互式的三维散点图,通过鼠标即可对图形进行旋转。
|
1
2
3
4
|
library(rgl)
attach(mtcars)
plot3d(wt, disp, mpg, col="red", size=5)
detach(mtcars)
|
Rcmdr包中的scatter3d()函数可以实现类似功能。
|
1
2
3
4
|
library(Rcmdr)
attach(mtcars)
scatter3d(wt, disp, mpg)
detach(mtcars)
|
7 添加文本标注
使用geom_text()为散点图添加标注,vjust为0时表示竖直方向上基线对齐,为1时表示顶部对齐,hjust为0时表示水平方向上左对齐,为1时表示右对齐,以下设置对齐方式并适当添加偏移,以改善显示效果。
|
1
|
ggplot(subset(countries, Year==2009 & healthexp>2000), aes(x=healthexp, y=infmortality)) + geom_point() + geom_text(aes(y=infmortality+.1, label=Name), size=4, vjust=0)
|
8 使用气泡图绘制二维统计
以下使用散点图绘制气泡图,对两个类别型变量进行统计。
|
1
2
3
4
|
hec <- HairEyeColor[,,"Male"] + HairEyeColor[,,"Female"]
library(reshape2)
hec <- melt(hec, value.name="count")
ggplot(hec, aes(x=Eye, y=Hair)) + geom_point(aes(size=count), shape=21, color="black", fill="cornsilk") + scale_size_area(max_size=20, guide=FALSE) + geom_text(aes(y=as.numeric(Hair)-sqrt(count)/22, label=count), vjust=1, color="grey60", size=4)
|
value1 <- rep(c('高价值','中价值','低价值'), each = 3)
value2 <- rep(c('高价值','中价值','低价值'), times = 3)
nums <- c(500,287,123,156,720,390,80,468,1200)
df <- data.frame(value1 = value1, value2 = value2, nums = nums)
df$value1 <- factor(df$value1, levels = c('高价值','中价值','低价值'), order = TRUE)
df$value2 <- factor(df$value2, levels = c('低价值','中价值','高价值'), order = TRUE)
ggplot(df,aes(x = value1, y = value2, size = nums)) +geom_point(colour = 'steelblue') +
scale_size_area(max_size = 30, guide = FALSE) +geom_text(aes(label = nums), vjust = 0, colour = 'black', size = 5) + theme(text = element_text(family = 'SimSun'))
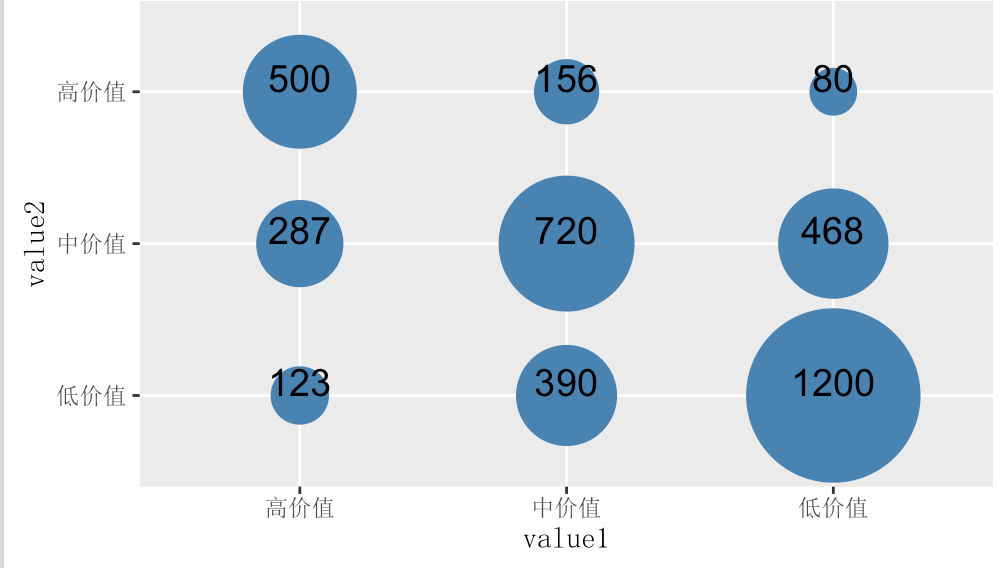
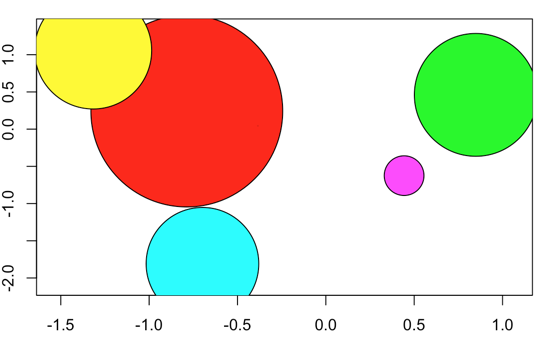
绘制气泡图也可使用函数symbols(x,y,circle=r).当中x、y是坐标轴,r是每一个点的半径。
x<-rnorm(6)
y<-rnorm(6)
r<-abs(rnorm(6))
symbols(x,y,circle = r, bg=rainbow(6))
###############气泡图例子2
attach(mtcars) # 激活或挂接数据集
#attach( )函数是将数据框添加到R的搜索路径中 # mtcars为R语言内置数据集
r<-sqrt(disp/pi)
symbols(wt,mpg,circle=r, inches=0.3, bg="lightblue")
text(wt,mpg,row.names(mtcars), cex=0.5) #给每一个气泡加上文字。
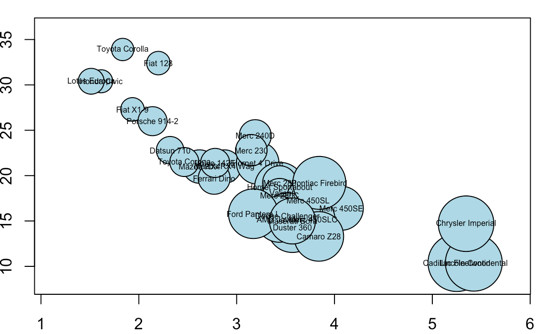
Chap6. 描述数据分布
数据分布可视化方法
直方图
geom_histogram()binwidth设置组距;origin设置分组原点- 各分组区间左闭右开
- 分面:
facet_grid(x ~.)- 修改分类标签:
revalue(x, c("0"="No smoke","1"="smoke")) - 参数
scales = free可以单独设定各个分面的Y轴标度。
- 修改分类标签:
我们经常想观察一批数据的分布形态,直方图、密度图、箱线图、小提琴图和点图等都是很好的实现形式。在此,我们简略介绍直方图、密度图和箱线图,这种三种图形对我们来说更为常用。
直方图
很多人没搞清楚条形图和直方图之间的区别。条形图主要用于展示分类数据,即名义数据,各组分开而立。而直方图多用于展示数值型数据,各组相依。
单组直方图
最基本的语句就是在ggplot语句后再加geom_histogram()即可。
library(gcookbook) library(ggplot2) ggplot(faithful, aes(x=waiting)) + geom_histogram(bins=10)
直方图默认最大为30组,我们可以使用*binwidth来改变。
ggplot(faithful, aes(x=waiting)) +geom_histogram(binwidth=8, bins=10,fill="white", colour="black")#改为8组
分组直方图
分组直方图做法与其他图形一样,我们用到facet_grid(var ~ .),该方法是以var变量进行分类,做多个图形,非一个图形中做多个直方图。如果变量为数字,应当因子化。
library(MASS) #取binwidth数据 ggplot(birthwt, aes(x=bwt))+geom_histogram(fill="white",bins=10, colour="black")+facet_grid(smoke ~ .)
核密度曲线
geom_line(stat='identity')或者geom_density()
如果你想要做密度曲线,则用geom_density映射一连续变量。
ggplot(faithful, aes(x=waiting)) + geom_density() #你也可以将包住的部分给填充颜色 ggplot(faithful, aes(x=waiting)) + geom_density(fill="blue", alpha=.2) + xlim(35, 105) #如果你不喜欢线与下方相连,可以使用另外一种方式 ggplot(faithful, aes(x=waiting)) + geom_line(stat="density") + expand_limits(y=0)#expand_limits使y轴范围包含0值。 #密度曲线与直方图共戏 ggplot(faithful, aes(x=waiting, y=..density..)) + geom_histogram(fill="cornsilk", colour="grey60", size=.2) + geom_density() + xlim(35, 105)
分组密度曲线
library(MASS) #取binwidth数据 ggplot(birthwt, aes(x=bwt))+geom_histogram(fill="white", colour="black")+facet_grid(smoke ~ .)
birthwt1 <- birthwt
birthwt1$smoke <- factor(birthwt1$smoke)
ggplot(birthwt1, aes(x=bwt, fill=smoke)) + geom_density(alpha=.3)
频数多边形
geom_freqpoly()
频数多边形描述了数据本身的信息,而核密度曲线只是一个估计,需要认为输入带宽参数。
箱线图
geom_boxplot()
- 参数:
width,outlier.size,outlier.shape - 添加槽口(notch):用来帮助查看不同分布的中位数是否有差异。
- 添加均值:
geom_summary(fun.y="mean",geom="point"...)
library(MASS) #取binwidth数据
ggplot(birthwt, aes(x=bwt))+geom_histogram(fill="white", colour="black")+facet_grid(smoke ~ .)
ggplot(birthwt, aes(x=factor(race), y=bwt)) + geom_boxplot() #如果存在多个多个离群点,可用outlier.size 和outlier.shape进行大小和形状设置 ggplot(birthwt, aes(x=factor(race), y=bwt)) + geom_boxplot(outlier.size=1.5, outlier.shape=21) #为了看数据分布是否有偏,我们还可以增加均值与中值进行比较,主要用stat_summary把均值以菱形相展示。 ggplot(birthwt, aes(x=factor(race), y=bwt)) + geom_boxplot() + stat_summary(fun.y="mean", geom="point", shape=23, size=3, fill="white")
小提琴图
geom_violin()
- 小提琴图用来比较多组数据分布情况的方法,其也是核密度估计。
- 坐标范围:从最小值到最大值,与箱线图不同。
- 参数:
adjust调整平滑程度,scale="count"使得图的面积与每组观测值数目成正比。
p = ggplot(data=mpg, mapping=aes(x=class, y=hwy, fill=class))
p + geom_boxplot() + geom_jitter(shape=21)
p + geom_violin(alpha=0.5, width=0.9) + geom_jitter(shape=21)

Wilkinson点图
geom_dotplot()
- Wilkinson点图:沿着x轴方向对数据进行分组,并在y轴上对点进行堆积。图形上Y轴的刻度线没有明确的含义。
- 备注:移除刻度线
scale_y_continuous(break=NULL),移除坐标轴标签theme(axis.title.y=element_blank()) - 参数
binaxis=”y”,将数据点沿着Y轴进行堆叠,并沿着x轴分组。stackdir="center":中心堆叠
p = ggplot(data=mpg, mapping=aes(x=class, y=hwy, fill=class))
p +geom_dotplot()
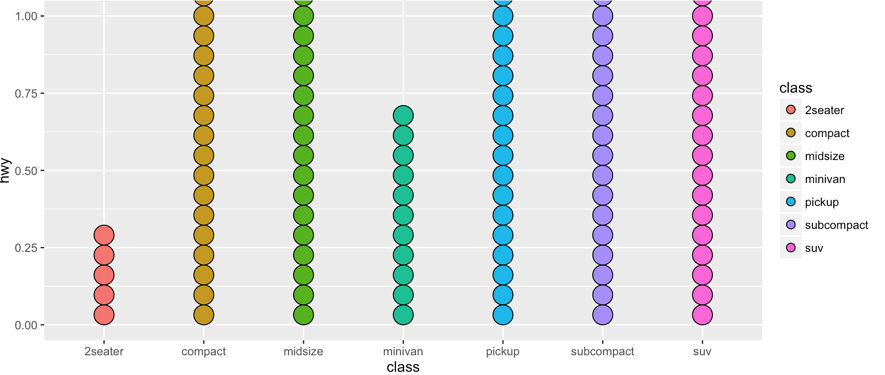
颜色图和等高图
par(mar = rep(1, 4))
x = 10 * (1:nrow(volcano))
y = 10 * (1:ncol(volcano))
image(x, y, volcano, col = terrain.colors(100), axes = FALSE)
contour(x, y, volcano, levels = seq(90, 200, by = 5),add = TRUE, col = "peru")
box()
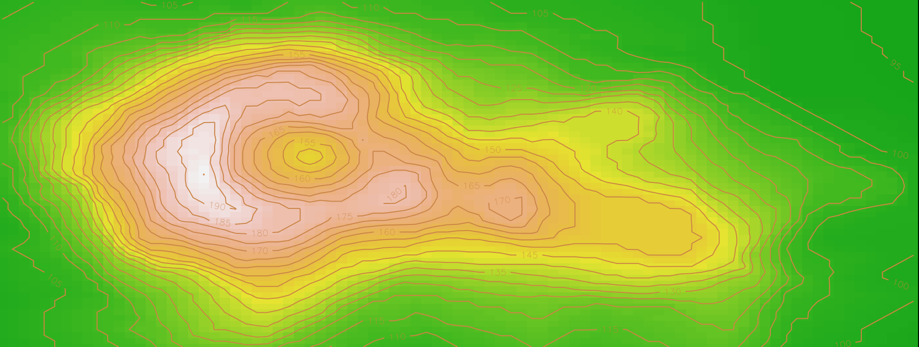
极坐标 (玫瑰图)
dt = data.frame(A = c(2, 7, 4, 10, 1,5), B = c('B','A','C','D','E','B'))
windowsFonts(myFont = windowsFont("楷体")) ## 绑定字体
p = ggplot(dt, aes(x = B, y = A, fill = B)) + geom_bar(stat = "identity", alpha = 0.7) + coord_polar()
p

Chap7. 注解
文本注解
geom_text()annotate():可以添加任意类型的几何对象。annotate("text",x=,y=,label=,...)
数学表达式
annotate("text",...,parse=TRUE,...)- 引入常规文本:在双引号内使用单引号标出纯文本的部分即可。
- 不能简单地把一个变量之间放到另一个变量旁边却不在中间添加任何记号。
?plotmath和?demo(plotmath)
添加直线
- 横线和竖线:
geom_hline(yintercept=)&geom_vline() - 有角度的直线:
geom_abline(intercept=,slope=)
添加线段和箭头
- 线段:
annotate("segment",x=,xend=,y=,yend=) - 利用grid包中的
arrow()函数向线段两端添加箭头或平头。
添加矩形阴影
annotate("rect",xmin=,xmax=,ymin=,ymax=,alpha=,fill=)
添加误差线
geom_errorbar(aes(ymin=,ymax=),width=,position=)
向独立分面添加注解
# 基本图形
p <- ggplot(mpg, aes(x=displ,y=hwy)) +
geom_point() + facet_grid(.~drv)
#存有每个分面所需标签的数据框
f_labels <- data.frame(drv=c("4","f","r"),
label=c("4wd","Front","Rear"))
p + geom_text(x=6,y=40,aes(label=label), data= f_labels) 1. `sprintf()`:returns a character vector containing a formatted combination of text and variable values. 2. `sprintf("italic(y) == %.2f %+.2f * italic(x)",round(coef(mod)[1],2),round(coef(mod)[2],2))`
1 添加文本注解
使用annotate()生成一条文本注解,通过x和y指定文本位置,可以是具体数值或者Inf和-Inf,表示图形的边缘,使用hjust和vjust进行水平方向和竖直方向上的微调,使用family、color、size分别指定字体、颜色、大小。
|
1
|
ggplot(faithful, aes(x=eruptions, y=waiting)) + geom_point() + annotate("text", x=3, y=48, label="Group 1", family="serif", color="darkred", size=5) + annotate("text", x=mean(range(faithful$eruptions)), y=-Inf, label="Group 2", vjust=-1)
|
2 添加数学表达式
还是使用annotate(),不过需要制定parse为TRUE,表示对文本进行公式解析。
|
1
|
ggplot(data.frame(x=c(-3, 3)), aes(x=x)) + stat_function(fun=dnorm) + annotate("text", x=0, y=0.05, parse=TRUE, size=4, label="'Function: ' * y==frac(1, sqrt(2*pi)) * e^{-x^2/2}")
|
更多和公式语法有关的内容可参考?plotmath,更多数学表达式的图示可参考?demo(plotmath)。
3 添加直线
使用geom_hline()、geom_vline()、geom_abline()分别绘制水平线、竖直线和有角度的线。如果x轴或y轴为类别型变量,则第一个水平为数值1,第二个水平为数值2,依此类推。
|
1
2
|
library(gcookbook)
ggplot(heightweight, aes(x=ageYear, y=heightIn, color=sex)) + geom_point() + geom_hline(yintercept=60) + geom_vline(xintercept=14) + geom_abline(intercept=37.4, slope=1.75)
|
同样可以通过指定类别型变量绘制多条直线。
|
1
2
3
|
library(plyr)
hw_means <- ddply(heightweight, "sex", summarise, heightIn=mean(heightIn))
ggplot(heightweight, aes(x=ageYear, y=heightIn, color=sex)) + geom_point() + geom_hline(aes(yintercept=heightIn, color=sex), data=hw_means, linetype="dashed", size=1)
|
4 添加线段和箭头
在annotate()中指定segment可以添加线段,还可以为线段添加箭头,箭头默认角度angle为30度,默认长度length为0.2英寸,使用x、xend、y、yend指定线段的起始位置。如果x轴或y轴为类别型变量,则相应地第一个水平使用数值1,第二个水平使用数值2,依次类推。
|
1
2
|
library(grid)
ggplot(subset(climate, Source=="Berkeley"), aes(x=Year, y=Anomaly10y)) + geom_line() + annotate("segment", x=1850, xend=1820, y=-.8, yend=-.95, color="blue", size=2, arrow=arrow()) + annotate("segment", x=1950, xend=1980, y=-.25, yend=-.25, arrow=arrow(ends="both", angle=90, length=unit(.2, "cm")))
|
5 添加矩形阴影
在annotate()中指定rect可以添加矩形,其实只要传递了合适的参数,任意几何对象都可以配合annotate()使用。
|
1
2
|
library(gcookbook)
ggplot(subset(climate, Source=="Berkeley"), aes(x=Year, y=Anomaly10y)) + geom_line() + annotate("rect", xmin=1950, xmax=1980, ymin=-1, ymax=1, alpha=.1, fill="blue")
|
6 向独立分面添加注解
使用分面变量生成一个新的数据框,并设定每个分面要绘制的值,然后配合新数据框使用geom_text()。
|
1
2
3
|
p <- ggplot(mpg, aes(x=displ, y=hwy)) + geom_point() + facet_grid(.~drv)
f_labels <- data.frame(drv=c("4", "f", "r"), label=c("4wd", "Front", "Rear"))
p + geom_text(x=6, y=40, aes(label=label), data=f_labels)
|
再来一个为每个分面添加拟合直线公式的例子。
|
1
2
3
4
5
6
7
8
9
10
|
lm_labels <- function(dat) {
mod <- lm(hwy ~ displ, data=dat)
formula <- sprintf("italic(y) == %.2f%+.2f * italic(x)", round(coef(mod)[1], 2), round(coef(mod)[2], 2))
r <- cor(dat$displ, dat$hwy)
r2 <- sprintf("italic(R^2) == %.2f", r^2)
data.frame(formula=formula, r2=r2, sringAsFactors=FALSE)
}
library(plyr)
labels <- ddply(mpg, "drv", lm_labels)
ggplot(mpg, aes(x=displ, y=hwy)) + geom_point() + facet_grid(.~drv) + geom_smooth(method=lm, se=FALSE) + geom_text(x=3, y=40, aes(label=formula), data=labels, parse=TRUE, hjust=0) + geom_text(x=3, y=35, aes(label=r2), data=labels, parse=TRUE, hjust=0)
|
Chap8. 坐标轴
交换x轴和y轴
coord_filp()
# x是因子型变量
+ scale_x_discrete(limits=rev(levels(..)))
坐标轴的值域
ylim()或者xlim()- 全称:
scale_y_continuous(limits=c(,),breaks=c(.,.,.)) - 注意区分
scale_y_continuous()和coord_cartesian();其中前者表示使用标度限制y到更小的范围,范围外的数据被丢弃,而后者则是利用坐标变换放大或缩小了数据。 expand_limits():只能用来扩展数据,而不能用来缩减值域。
反转一条连续型坐标轴
scale_y_reverse()
scale_x_reverse()
修改类别型坐标轴上项目的顺序
scale_x_discrete(limits=c(.,.,.))
# 反转坐标轴
scale_x_discrete(limits=rev(levels(...)))
设置x轴和y轴的缩放比例
coord_fixed(ratio=1)
默认情况下,ggplot2使两轴的总长宽比例为1:1,从而形成正方形的绘图区域,而本节中所提到的比例为:坐标轴单位长度表示的数值范围
设置刻度线的位置
参数breaks
离散型变量的坐标轴:设置limits以重排序或移除项目,而设置breaks来控制哪些项目拥有标签。
移除刻度线和标签
# 移除刻度标签
theme(axis.text.y = element_blank())
# 移除刻度线
theme(axis.ticks = element_blank())
# 同时移除连续型变量的刻度线、刻度标签和网格线
scale_y_continuous(breaks= NULL) 刻度标签可以单独控制,但是刻度线和网格线必须同时控制。
修改刻度标签的文本
参数:breaks & labels
package:scales自带了一些内置的格式化函数,比如comma(),dollar(),percent(),scientific()
修改刻度标签的外观
# 文本旋转
theme(axis.text.x = element_text(angle=90,hjust=,vjust=))
# 其他文本属性
theme(axis.text.x = element_text(family=,face=,colour=,size=rel()))
rel(0.9):表示为当前主题基础字体大小的0.9倍
修改坐标轴标签的文本
# 简便法
xlab() & ylab()
# 完整法
scale_x_continuous(name="") 文本中可包含`\n,\t`等文本符号
移除坐标轴标签
theme(axis.title.x = element_blank())
对数坐标轴
scale_x_log10() & scale_y_log10()
# 刻度标签转而使用指数计数法
library(scales)
scale_x_log10(breaks=10^(-1:5), labels=trans_format("log10",math_format(10^.x)))
# 自然对数
trans=log_trans()
# 以2为底的对数
trans = log2_trans()
对数坐标轴添加刻度
annotation_logticks()
坐标轴上使用日期
library(scales)
# Date 对象
p + scale_x_time(breaks = datebreaks, date_format("%Y-%m"))
# POSIXt对象
p + scale_x_datetime(breaks = datebreaks,date_format())
+ theme(axis.text.x = element_text(angle=90, hjust=1))1 交换X轴和Y轴使用coord_flip()来翻转坐标轴。
|
1
|
ggplot(PlantGrowth, aes(x=group, y=weight)) + geom_boxplot() + coord_flip()
|
2 设置连续型坐标轴的值域
可以使用xlim()和ylim()来设置连续型坐标轴的最小值和最大值。
|
1
|
ggplot(PlantGrowth, aes(x=group, y=weight)) + geom_boxplot() + ylim(0, max(PlantGrowth$weight))
|
ylim()是scale_y_continuous()的简化写法,后者还可以使用breaks设置刻度线的位置。
|
1
2
|
ylim(0, 10)
scale_y_continuous(limits=c(0, 10), breaks=c(0, 5, 10))
|
3 反转连续型坐标轴
使用scale_y_reverse()和scale_x_reverse()反转连续型坐标轴。
4 修改类别型坐标轴上项目的顺序
通过scale_x_discrete()和scale_y_discrete()并将一个依所需顺序排列的水平向量传递给limits即可。如果在limits中省略某一类别对应的值,则该类别在绘图中将不显示。
|
1
|
ggplot(PlantGrowth, aes(x=group, y=weight)) + geom_boxplot() + scale_x_discrete(limits=c("trt1", "ctrl", "trt2"))
|
以下代码反转类别型坐标轴的项目顺序。
|
1
|
ggplot(PlantGrowth, aes(x=group, y=weight)) + geom_boxplot() + scale_x_discrete(limits=rev(levels(PlantGrowth$group)))
|
5 设置X轴和Y轴的缩放比例
当x轴和y轴所对应的连续型变量具有相同的尺度和量级时,可以通过coord_fixed()使得x轴和y轴之间保持1:1的缩放结果。
|
1
2
|
library(gcookbook)
ggplot(marathon, aes(x=Half, y=Full)) + geom_point() + coord_fixed()
|
如果希望使用其他缩放比例时,在coord_fixed()中指定ratio即可。
|
1
|
ggplot(marathon, aes(x=Half, y=Full)) + geom_point() + coord_fixed(ratio=1/2)
|
6 修改刻度标签的文本
在需要设置刻度标签的地方同时为breaks和labels赋值即可。
|
1
2
|
library(gcookbook)
ggplot(heightweight, aes(x=ageYear, y=heightIn)) + geom_point() + scale_y_continuous(breaks=c(50, 56, 60, 66, 72), labels=c("Tiny", "Really\nshort","Short", "Medium", "Tallish"))
|
也可以定义一个格式化函数,将原始的值自动地转换为相应的标签。
|
1
2
3
4
5
6
7
|
# 将英寸转换为英尺加英寸
footinch_formatter <- function(x) {
foot <- floor(x/12)
inch <- x %% 12
return(paste(foot, "'", inch, "\"", sep=""))
}
ggplot(heightweight, aes(x=ageYear, y=heightIn)) + geom_point() + scale_y_continuous(labels=footinch_formatter)
|
scales包提供了一些常用的格式化函数:
- comma(),在千、百万、十亿等位置向数字添加逗号;
- dollar(),添加一个美元符号并舍入到最接近的美分;
- percent(),乘以100,舍入到最接近的整数值,并添加一个百分号;
- scientific(),对大数字和小数字给出科学计数法表示。
除此之外,通过ggplot2提供的theme()可以对刻度标签文本设置字体、样式、大小和颜色,进行旋转和平移等操作,当然还包括对坐标轴标签文本、标题、图例等全部元素的样式自定义,详情请参考?theme。
7 修改标题和坐标轴标签文本
使用labs()可以同时设置x轴标签、y轴标签和标题,如果使用到了中文,还需要用theme()设置全局字体,参考这里。
|
1
|
labs(x="x轴标签", y="y轴标签", title="绘图标题")
|
8 使用对数坐标轴
使用scale_x_log10()和scale_y_log10()可以将线性坐标轴转换为对数坐标轴,在某些情况下,使用对数坐标轴更有意义。
|
1
2
|
library(MASS)
ggplot(Animals, aes(x=body, y=brain, label=rownames(Animals))) + geom_text(size=3) + scale_x_log10() + scale_y_log10()
|
9 绘制极坐标
使用coord_polar()即可绘制极坐标。
|
1
2
|
library(gcookbook)
ggplot(wind, aes(x=DirCat, fill=SpeedCat)) + geom_histogram(binwidth=15, boundary=-7.5) + coord_polar() + scale_x_continuous(limits=c(0, 360))
|
然而,由于极坐标的原因,扇形大小并不能直观反映出实际的观测数量,而且多种颜色混杂难以让人对风力有直观的感受,因此我们需要改变一下样式。
|
1
|
ggplot(wind, aes(x=DirCat, fill=SpeedCat)) + geom_histogram(binwidth=15, boundary=-7.5, color="black", size=.2) +guides(fill=guide_legend(reverse=TRUE)) + coord_polar() + scale_x_continuous(limits=c(0, 360), breaks=seq(0, 360, by=45), minor_breaks=seq(0, 360,by=15)) + scale_fill_brewer()
|
Chap9.控制图形的整体外观
设置图形标题
# 图形标题,"\n"换行
ggtitle()
labs(title="")
# 将标题移到内部
annotate("text",x=mean(range(x)),y=Inf,label="Age",vjust=1.5,size=6)
修改文本外观
文本项目分为两类:主题元素和文本几何对象。主题元素包括图形中的所有非数据元素:如标题、图例和坐标轴。文本几何对象则属于图形本身的一部分。
- family: Helvatica、Times、Courier
- face: plain、bold、italic、bold.italic
- lineheight: 行间距倍数
- angle: 旋转角度(逆时针)
- size: 字体大小(主题为磅,几何对象为毫米)
- strip.text: 双向分面标签的外观
使用主题
# 预制的主题:
theme_bw()
theme_grey()
# 设置默认主题
theme_set(theme_bw())
## 修改主题元素的外观
要修改一套主题,配合相应的element_xx对象添加theme()函数即可。element_xx对象包括element_line、element_rect和element_text。
创建自定义主题
mytheme = theme_bw() +
theme(text = element_text(colour="red"),axis.title=element_text(size=rel(1.25)))
p + mytheme
隐藏网格线
- 主网格线:panel.grid.major
- 次网格线:panel.grid.minor
Chap10. 图例
像x轴和y轴一样,图例也是一种引导元素:它可以向人们展示如何从视觉上的图形属性映射回数据本身。
# 移除图例(指明图例属性)
guides(fill=FALSE)
# 修改图例的位置
theme(legend.position="bottom")
# 将图例置于图像中
theme(legend.position=c(1,0)) +
theme(legend.bakground=element_rect(fill="white",colour="black"))
# 修改图例项目的顺序
scale_fill_discrete(limits=c("a","b","c"))
# 反转图例顺序(属性fill)
guides(fill=guide_legend(reverse=TRUE))
# 设置图例标题(属性fill)
labs(fill="Condition")
guides(fill=guide.legend(title="Condition"))
# 修改图例文本
theme(legend.title=element_text(face="italic",family="Times",colour="red",size=14))
# 修改图例标签
scale_fill_discrete(limits=c("a","b","c"),labels=c("A","B","C"))
# 修改图例标签的外观
theme(legend.text=element_text(xx))
# 使用含多行文本的标签
library(grid)
## 增加图例说明的高度并减小各行的间距
theme(legend.text=element_text(lineheight=0.8),legend.key.height=unit(1,"cm"))
Chap11. 分面
数据可视化中最实用的技术之一就是将分组数据并列呈现,这样使得组间的比较变得轻而易举。
# 分面函数
facet_grid(. ~ cyl,scale="free")
facet_wrap(~class, nrow=2)
# 修改分面标签和标题的外观
theme(strip.text=element_text(face="bold",size=rel(1.5)),strip.background=element_rect(fill="lightblue",colour="black",size=1))即在一个页面上自动摆放多幅图形, 这一过程先将数据划分为多个子集, 然后将每个子集依次绘制到页面的不同面板中。ggplot2提供两种分面类型:网格型(facet_grid)和封面型(facet_wrap)。网格分面生成的是一个2维的面板网格, 面板的行与列通过变量来定义, 本质是2维的; 封装分面则先生成一个1维的面板条块, 然后再分装到2维中, 本质是1维的。
在很多情况下, 我们可能需要绘制有两个y轴的坐标系, 而在ggplot2中, 这种做法特别不提倡(stackover的讨论), 可解决的方法要么是把变量归一化, 要么便是采用分面方法。
p <- ggplot(mtcars, aes(mpg, wt, colour = cyl)) +geom_point() #geom_point()为通过”+”以图层的方式加入点的几何对象
p <- ggplot(mtcars, aes(mpg, wt)) + geom_point()
p + facet_grid(. ~ cyl) #以cyl为分类变量
p + facet_wrap( ~ cyl, nrow = 3) #wrap与grid的区别
p + facet_grid(cyl ~ .) #以cyl为分类变量
p + facet_wrap( ~ cyl, ncol = 3) #wrap与grid的区别
p + facet_grid(vs ~ am) #以vs和am为分类变量
p + facet_wrap(vs ~ am, ncol = 2) #wrap与grid 的区别
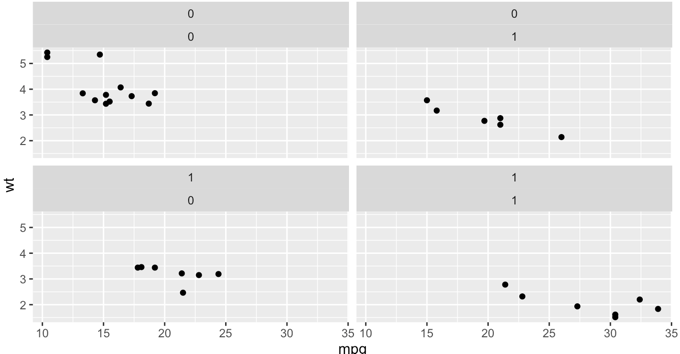
Chap12. 配色
离散型变量调色板
- 等距色:scale_fill_discrete()
- 色轮等距色:scale_fill_hue()
- 灰度调色板:scale_fill_grey()
- 调色板颜色:scale_fill_brewer()
- 自定义颜色:scale_fill_manual()
# 设置亮度参数(Default:l=65)
scale_fill_hue(l=45)
# 调用调色板
library(RColorBrewer)
display.brewer.all()
# 使用自定义调色板
scale_fill_manual(values=mycol)
对类别型数据中的点而言,最好选择调色板Set1和Dark2;对面积而言,Set2、Pastel1、Pastel2和Accent都是不错的选择方案。
RGB颜色
RGB颜色是由六个数字组成(十六进制数),形式如“#RRGGBB”。在十六进制中,数字先从0到9,然后紧接着是A到F。每一个颜色都由两个数字表示,范围从00到FF。比如颜色“#FF0099”中,255表示红色,0表示绿色,153表示蓝色,整体表示品红色。十六进制数中每个颜色通道常常重复同样的数字,因子这样更容易阅读并且第二个数字的精确值对外观的影响并不是很明显。
RGB经验法则
- 一般情况下,较大的数字更明亮,较小的数字更暗淡。
- 如果要得到灰色,将三个颜色通道设置为相同的值。
- CMY(印刷三原色):青(cyan)、品红(magenta)、黄(yellow)。
- RGB颜色
色盲友好式调色板
cb_col = c("#000000","#E69F00","#56B4E9","#009E73","#F0E442","#0072B2","#D55E00","#CC79A7")
scale_fill_manual(values=cb_col)
# 调用dichromat包
连续型变量调色板
- 两色渐变:scale_fill_gradient()
- 三色渐变:scale_fill_gradient2()
- 等间隔n色渐变:scale_fill_gradientn()
Chap15. 其他图形
相关矩阵图
library(corrplot)
corrplot(cor(x),method="shade",shade.col=NA,tl.col="black",tl.srt=45,col=col(200),addCoef.col="black",cl.pos="no",order="AOE")
绘制函数曲线
# 函数曲线
stat_function(fun=myfun, n=200)
# 函数曲线下添加阴影
## 定义一个新函数,把x范围外的值替换为NA
p + stat_function(fun=myfun, geom="area", fill="blue",alpha=0.2) +
stat_function(fun=myfun)
# 绘制经验累积分布函数图
stat_ecdf()
绘制热图
使用geom_tile()或者geom_raster(),并将一个连续变量映射到fill上。
p + geom_tile() +
scale_x_continuous(breaks = seq(1940,1976,by=4)) +
scale_y_reverse() +
scale_fill_gradient2(midpoint=50,mid="grey70",limits=c(0,100))
三维散点图
library(rgl)
# 绘制点
plot3d(x,y,z,type="s",size=0.75,lit=FALSE)
# 添加线段
interleave = function(v1,v2) as.vector(rbind(v1,v2))
segment3d(interleave(x,x),
interleave(y,y),interleave(z,min(z)),alpha=0.4,col="blue")
# 绘制盒子
rgl.bbox(color="grey50", emission="grey50",xlen=0,ylen=0,zlen=0)
# 保存图像
rgl.snapshot("3dplot.png", fmt="png")
rgl.postscript("3dplot.pdf",fmt="pdf")
# 三维图动画
plot3d(x,y,z,type="s",size=0.75,lit=FALSE)
play3d(spin3d())
movie3d(spin3d(axis=c(1,0,0),rpm=4),duration=15,fps=50)
绘制谱系图
hc = hclust(scale(x))
plot(hc, hang=-1)
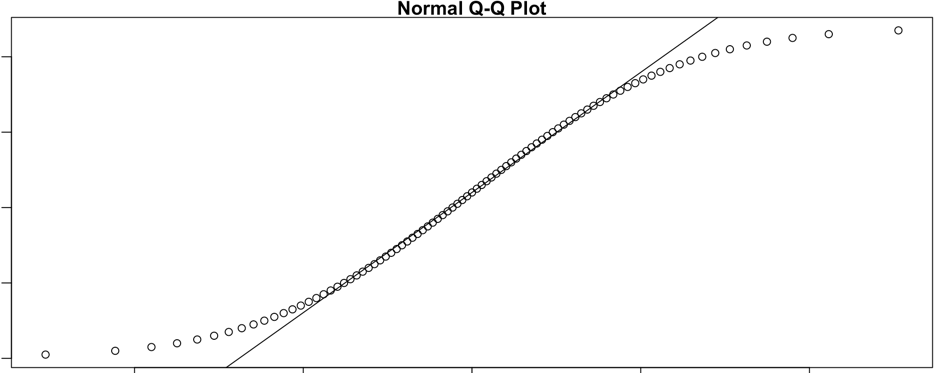
绘制QQ图
# base画图
qqnorm(x)
qqline(x)
# ggplot2画图
predicted <- data.frame(i = 1:length(VALUE), x=1:length(VALUE), y=1:length(VALUE))
predicted$x <- qnorm((predicted$i-0.375)/(nrow(predicted+0.25)))
predicted$y <- sd(VALUE)*predicted$x+mean(VALUE)
ggplot(data.frame(VALUE), aes(sample = VALUE)) +
stat_qq() +
geom_line(data=predicted[,-1],aes(x=x,y=y),size=1,colour="red")
绘制脸型图
#可以利用函数cbind() 和rbind() 把向量和矩阵拼成一个新的矩阵
library(TeachingDemos)
data <- rbind(c(80394, 32903, 13.2),
c(82560, 36230, 13.8),
c(85213, 26921, 10.8))
faces2(data, which = c(3, 14, 12), labels = c("北京", "上海", "天津"), ncols = 3)

绘制马赛克图
# 主要用来可视化列联表
library(vcd)
mosaic(~x+y+z, data, highlighting="x",highlighting_fill=c(lightblue","pink"),direction=c("v","h","v"))
绘制饼图
fold = table(survey$Fold)
pie(fold,labels=c("x","y","z"))
绘制地图
Chap14. 保存图形
Web浏览器更支持SVG文件,而LaTeX则更支持PDF文件。
输出为PDF矢量文件
#width和height的单位为英寸
pdf("myplot.pdf",width=4,height=4,useaDingbats=FALSE)
plot(x,y)
print(ggplot(data,aes(x=x,y=y))+geom_point())
dev.off()
# 如果图形多于一幅,则每一幅将在PDF输出中列于独立的一页。
# ggsave()不能用于创建多页图形
ggsave("myplot.pdf",width=8,height=8,units="cm",useaDingbats=FALSE)
输出为SVG矢量文件
svg("myplot.svg",width=4,height=4)
plot()
dev.off()
输出为WMF矢量文件
Windows图元文件(WMF),即只能在Windows上创建。
win.metafile("myplot.wmf",width=4,height=4)
plot()
dev.off()
# ggsave()
ggsave("myplot.wmf",width=8,height=8,units="cm")
输出为点阵(PNG/TIFF)文件
png("myplot.png",width=400,height=400)
plot(x,y)
dev.off()
# 多幅图形
png("myplot-%d.png",width=400,height=400)
plot()
print(ggplot())
dev.off()
# ggsave函数
ggsave("myplot.png",width=8,height=8,unit="cm",dpi=300)
# CairoPNG():支持抗锯齿和alpha通道的特性
install.packages("Cairo")
CairoPNG("myplot.png")
plot()
dev.off()
在图中显示中文
# MAC用户
plot(x, main="散点图",xlab="数",ylab="值",family="SimSun")
ggplot(data, aes(x=x,y=y))+
geom_point()+
annotate("text",x=10,y=30,size=10,label="我就是我!",family="SimSun")+
xlab("数")+
ylab("值")+
theme(title=element_text(family="SimSun"))
一页多图
视图窗口(viewport):显示设备的一个矩阵子区域。grid.layout()设置了一个任意高和宽的视图窗口布局。
pdf("myplot.pdf",width=8,height=6)
grid.newpage()
pushViewport(viewport(layout=grid.layout(2,2)))
vplayout = function(x,y){
viewport(layout.pos.row=x, layout.pos.col=y)
}
print(a, vp = vplayout(1, 1:2))
print(b, vp = vplayout(2, 1))
print(c, vp = vplayout(2, 2))
dev.off()
默认的grid.layout()中,每个单元格的大小都相同,可以设置widths和heights参数使得它们具有不同的大小。
时间序列
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
#用excel导入数据, 格式为csvori.data <- read.csv("lesson8.csv", header = F)#以矩阵的方式读入数据, 按行排列, 每三列换一行data <- matrix(as.matrix(ori.data), nrow(ori.data) / 3, 3, byrow = TRUE)#关闭区域特定的时间编码方式Sys.setlocale("LC_TIME", "C")#用as.POSIXlt()读入字符串数据并转化为date数据, 赋值给date, 或as.Date()date <- as.POSIXlt(data[, 1], tz = "", "%a %b %d %H:%M:%S HKT %Y")#对ip和pv所在的列转化为数值型IP <- as.numeric(data[, 2])PV <- as.numeric(data[, 3])head(data)#恢复区域特地的时间编码方式Sys.setlocale("LC_TIME", "")#用ggplot2绘图require(ggplot2)#用reshape包中的melt函数分解数据require(reshape2)p.data <- data.frame(date, IP, PV)meltdata <- melt(p.data, id = (c("date")))#用对IP和PV做分页处理, y轴刻度自由变化graphic <- ggplot(data = meltdata, aes(x = date, y = value, color = variable)) + geom_line() + geom_point()graphic <- graphic + facet_grid(variable ~ ., scales = "free_y")#美化, 添加标题, 坐标, 更改图例graphic<- graphic + labs(x = "日期", y = "人次", title = "某网站7月至10月IP/PV统计") + theme(plot.title = element_text(size = 20, face = "bold")) + scale_colour_discrete(name = "",labels = c("IP","PV")) + theme(strip.text.y = element_text(angle = 0)) |
地图
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
require(maps)require(ggplot2)#用直方图看下pop整体的分布#可以发现数据分布较变化较大, 所以对pop做log转化qplot(pop, data = us.cities, binwidth = 0000, geom = "histogram")qplot(log(pop), data = us.cities, binwidth = 0.03, geom = "histogram")#绘制背景地图USA.POP <- ggplot(us.cities, aes(x = long, y = lat)) + xlim(-130, -65) + borders("state", size=0.5)+ geom_point(aes(size = log(pop), color = factor(capital), alpha = 1/50))+ #对size标度的调整参考http://docs.ggplot2.org/0.9.3.1/scale_size.html scale_size(range=c(0, 7), name = "log(City population)")+ #对离散型颜色变量的标度调整参考http://docs.ggplot2.org/0.9.3.1/scale_manual.html #对连续型颜色标量的标度调整参考http://docs.ggplot2.org/0.9.3.1/scale_brewer.html #和http://docs.ggplot2.org/0.9.3.1/scale_gradient2.html scale_color_manual(values = c("black", "red"), labels = c("state capital", "city"))+ #调整图例 guides(color = guide_legend(title=NULL)) + scale_alpha(guide = FALSE)+ #绘制标题和坐标轴 labs(x = "longtitude", y = "latitude", title = "City Population in the United States")+ theme(plot.title = element_text(size=20)) #输出图像 并用cairo包进行抗锯齿处理ggsave(USA.POP, file = "USA_POP.png", type = "cairo", width = 10, height = 6.75) |
当然, 这只是简单的地图绘制方法,统计之都上也有很多大牛来用R绘制各种各样精美的地图(1, 2)。
剂量-效应曲线
R中的drc包很容易对各种剂量-效应曲线进行绘图, 此处采用较为常用的log-logistic四参数方程拟合了剂量-效应曲线。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
ori.data <- read.csv("D-R curve.csv")require(drc)require(reshape2)#把数据融合melt.data <- melt(ori.data, id = c("dose"), value.name = "response")[, -2]#用drc包中的log-logistic四参数方程进行拟合建模model <- drm(response ~ dose, data = melt.data, fct = LL.4(names = c("Slope", "Lower Limit", "Upper Limit", "EC50")))#确定x轴范围并构建数据集min <- range(ori.data$dose)[1]max <- range(ori.data$dose)[2]line.data <- data.frame(d.predict = seq(min, max, length.out = 1000))#用模型预测数据构建数据集line.data$p.predict <- predict(model, newdata = line.data)#构建绘图数据, 能够计算误差棒require(plyr)p.data <- ddply(melt.data, .(dose), colwise(mean))p.data$sd <- ddply(melt.data, .(dose), colwise(sd))[,2]require(ggplot2)p <- ggplot() + geom_errorbar(data = p.data, width = 0.1, size = 1, aes(ymax = response + sd, ymin = response - sd, x = dose)) + geom_point(data = p.data, aes(x = dose, y = response), color = "red", alpha = 0.5, size = 5) + geom_line(data = line.data, aes(x = d.predict, y = p.predict), size = 1, color = "blue") + #改变坐标轴间隔 scale_x_log10(name = "Dose", breaks=c(0.05, 0.1, 0.5, 1, 5, 10, 50, 100)) + scale_y_continuous(name = "Response") + theme_bw()#查看拟合模型参数summary(model) |
现代线条艺术欣赏
1 羽毛图
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
x1 = c(seq(0, pi, length = 50), seq(pi, 2*pi, length = 50))
y1 = cos(x1) / sin(x1)
x2 = seq(1.02 * 2 * pi + pi/2, 4*pi + pi/2, length = 50)
y2 = tan(x2)
op = par(bg="black", mar=rep(.5,4))
plot(c(x1, x2), c(y1, y2), type = "n", ylim = c(-11, 11))
for (i in seq(-10, 10, length = 100))
{
lines(x1, y1 + i, col = hsv(runif(1,.65,.7), 1, 1, runif(1,.7)),
lwd = 4 * runif(1, 0.3))
lines(x2, y2 + i, col = hsv(runif(1,.65,.7), 1, 1, runif(1,.7)),
lwd = 4 * runif(1, 0.3))
}
|
2 心形图
|
1
2
3
4
5
6
7
8
9
10
|
theta = seq(-2 * pi, 2 * pi, length = 300)
x = cos(theta)
y = x + sin(theta)
op = par(bg = "black", mar = rep(0.1, 4))
plot(x, y, type = "n", xlim = c(-8, 8), ylim = c(-1.5, 1.5))
for (i in seq(-2*pi, 2*pi, length = 100))
{
lines(i*x, y, col = hsv(runif(1, 0.85, 0.95), 1, 1, runif(1, 0.2, 0.5)),
lwd = sample(seq(.5, 3, length = 10), 1))
}
|
3 幻圈图
|
1
2
3
4
5
6
7
8
9
10
|
theta = 1:100
x = sin(theta)
y = cos(theta)
op = par(bg = 'black', mar = rep(0.5, 4))
plot.new()
plot.window(xlim = c(-1, 1), ylim = c(-1, 1), asp = 1)
lines(x, y, col = hsv(0.65, 1, 1))
lines(0.8 * x, 0.8 * y, col = hsv(0.8, 1, 1))
lines(0.6 * x, 0.6 * y, col = hsv(0.9, 1, 1))
lines(0.4 * x, 0.4 * y, col = hsv(0.95, 1, 1))
|
4 土星环
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
x = seq(-50, 50, by = 1)
y = -(x^2)
op = par(bg = 'black', mar = rep(0.5, 4))
plot(y, x, type = 'n')
lines(y, x, lwd = 2*runif(1), col = hsv(0.08, 1, 1, alpha = runif(1, 0.5, 0.9)))
for (i in seq(10, 2500, 10))
{
lines(y-i, x, lwd = 2*runif(1), col = hsv(0.08, 1, 1, alpha = runif(1, 0.5,
0.9)))
}
for (i in seq(500, 600, 10))
{
lines(y - i, x, lwd = 2*runif(1), col = hsv(0, 1, 1, alpha = runif(1, 0.5, 0.9)))
}
for (i in seq(2000, 2300, 10))
{
lines(y - i, x, lwd = 2*runif(1), col = hsv(0, 1, 1, alpha = runif(1, 0.5,
0.9)))
}
for (i in seq(100, 150, 10))
{
lines(y - i, x, lwd = 2*runif(1), col = hsv(0, 1, 1, alpha = runif(1, 0.5, 0.9)))
}
|
5 字母印象
|
1
2
3
4
5
6
7
8
9
10
11
12
|
nx = 100
ny = 80
x = sample(x = 1:nx, size = 90, replace = TRUE)
y = seq(-1, -ny, length = 90)
op = par(bg = "black", mar = c(0, 0.2, 0, 0.2))
plot(1:nx, seq(-1, -nx), type = "n", xlim = c(1, nx), ylim = c(-ny+10, 1))
for (i in seq_along(x))
{
aux = sample(1:ny, 1)
points(rep(x[i], aux), y[1:aux], pch = sample(letters, aux, replace = TRUE),
col = hsv(0.35, 1, 1, runif(aux, 0.3)), cex = runif(aux, 0.3))
}
|
6 绚丽霞光
|
1
2
3
4
5
6
7
8
9
|
theta = seq(0, pi, length = 300)
x = cos(theta)
y = sin(theta)
op = par(bg = "black", mar = rep(0.5, 4))
plot(x, y, type = 'n')
segments(rep(0, 299), rep(0, 299), x[1:299] * runif(299, 0.7),
y[1:299] * runif(299, 0.7),
col = hsv(runif(299, 0.45, 0.55), 1, 1, runif(299, 0.5)),
lwd = 5*runif(299))
|
作者:Hycf_yjd
链接:http://www.cnblogs.com/yjd_hycf_space
参考资料:
R语言_ggplot2:数据分析与图形艺术
R数据可视化手册
ggplot2绘制饼图
ggplot2绘制散点图
ggplot2实现多图合并
基于ggplot2图形的微调
https://my.oschina.net/935572630/blog/625401
http://www.itdadao.com/articles/c15a507013p0.html
https://zhuanlan.zhihu.com/p/23414691?refer=EasyCharts-R
http://www.cnblogs.com/yjd_hycf_space/p/6702590.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}