


评分卡模型
一、评分卡模型
PS:核心点在于我们需要一个判别指标来对数据进行打标签分类
1、项目简介:
信用评分技术是一种应用统计模型,其作用是对贷款申请人做风险评估分值的方法。在互金公司等各种贷款业务机构中,普遍使用信用评分,对客户实行打分制,以期对客户有一个优质与否的评判。评分卡主要分为三类A卡(申请评分卡)、B卡(行为评分卡)、C卡(贷后评分卡)。我们主要讨论的是A卡即申请评分卡,用于贷前审批阶段对借款申请人的量化评估;
2、评分卡原理:
申请评分卡是一种统计模型,它可基于对当前申请人的各项资料进行评估并给出一个分数,该评分能定量对申请人的偿债能力作出预判。
客户申请评分卡由一系列特征项组成,每个特征项相当于申请表上的一个问题(例如,年龄、银行流水、收入等)。每一个特征项都有一系列可能的属性,相当于每一个问题的一系列可能答案(例如,对于年龄这个问题,答案可能就有30岁以下、30到45等)。在开发评分卡系统模型中,先确定属性与申请人未来信用表现之间的相互关系,然后给属性分配适当的分数权重,分配的分数权重要反映这种相互关系。分数权重越大,说明该属性表示的信用表现越好。一个申请的得分是其属性分值的简单求和。如果申请人的信用评分大于等于金融放款机构所设定的界限分数,此申请处于可接受的风险水平并将被批准;低于界限分数的申请人将被拒绝或给予标示以便进一步审查。
3、开发流程:
导入数据集 → 数据预处理 → 数据探索 → 特征工程 → 建立模型 → 建立评分卡
4、流程demo:
4.1、数据集导入


4.2、数据预处理
1) 查看数据信息
了解数据信息状态,包括数据量、数据维度、数据特征类型等等
2) 缺失值处理
对于缺失值较少的‘家属数量’我们可以直接删除缺失值。及对数据集进行去重处理。
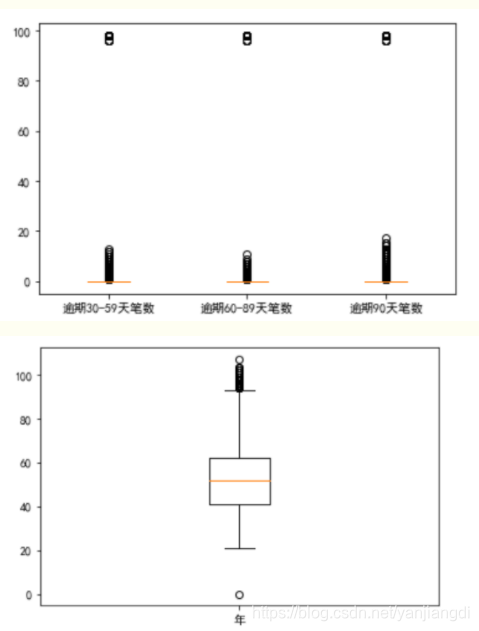
3) 异常值检测及处理
利用箱型图对特征进行可视化来检测异常数据。
![]()
通过以上特征可视化我们可以对明显偏离的样本,比如年龄为0,或是逾期次数过高进行盖帽或者是删除操作
4.3、数据可视化分析
1) 单变量可视化

![]()
可以看出:
(1) 客户主体集中在月收入10000以下的人群,月收入在15000之前的坏客率和月收入呈负相关收入越高坏客率越低,后进入一段平稳
(2) 当收入超过20000后,坏客率又在上升。
结论:这表明收入在15000以下的人群收入比较稳定,随着收入越高坏账率也就越高。而收入大于20000的人群可能从事炒股,创业等风险较大的工作,所以坏账率增大。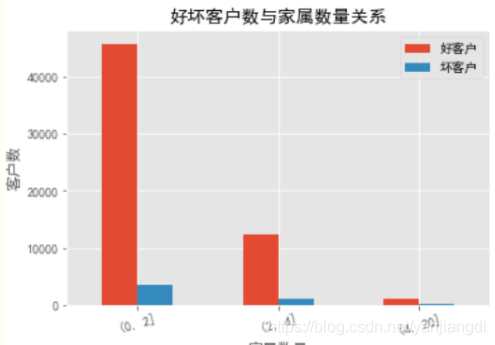
![]()
![]()
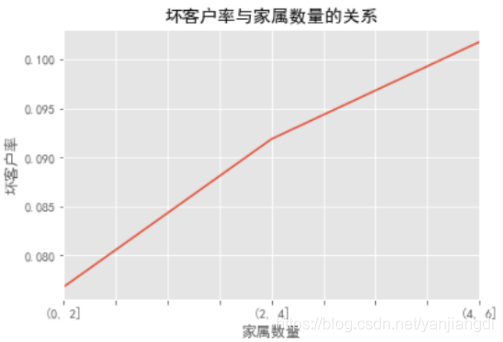
可以看出
(1) 客户的家属数量的主要集中在0-2之间,家属数量和坏客率呈线性相关,也就是说随着家属数量提升,坏客率也在显著提升。
(2) 可能是由于家属数量大,家庭的支出也就增大,所以更容易出现坏账的情况。
2) 多变量可视化
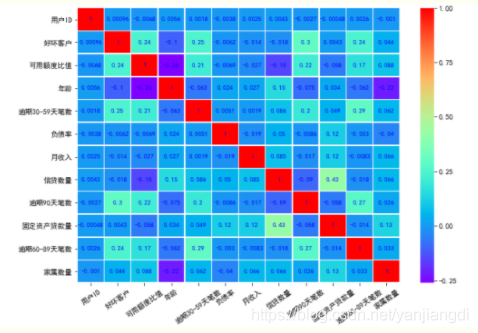
通过变量直接的相关性系数,建立相关性矩阵,观察变量之间的关系,可以进行初步的多重共线性筛选。
![]()
热力图的颜色表示变量之间的相关性程度,可以看出变量之间没有相关性过高的情况,所以暂时不需要考虑多重共线性的问题。
5、特征工程
1) 特征分箱
在建立风控评分卡中,一般会对特征进行分箱,以提高模型的稳定性和健壮性,消除了异常波动对评分结果的影响。
2) woe 转换
接下来给分箱后的数据计算woe值,woe算是一种编码形式,但是和普通的编码它实际代表了响应客户和未响应客户之间的差异情况。
公式如下:
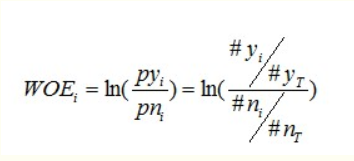
![]()
![]()
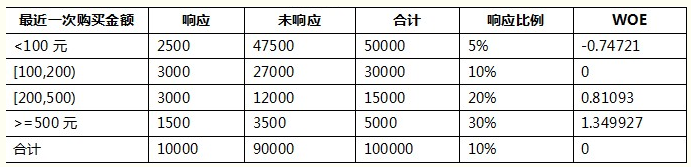
可以看出
1) 当前分组中,响应的比例越大,WOE值越大
2) 当前分组WOE的正负,由当前分组响应和未响应的比例,与样本整体响应和未响应的比例的大小关系决定
3) 当前分组的比例小于样本整体比例时,WOE为负,当前分组的比例大于整体比例时,WOE为正,当前分组的比例和整体比例相等时,WOE为0。
注意:一般认为woe关于分箱是单调的,我们会认为分箱比较好,可解释性强。
WOE其实描述了变量当前这个分组,对判断个体是否会响应(或者说属于哪个类)所起到影响方向和大小
当WOE为正时,变量当前取值对判断个体是否会响应起到的正向的影响
当WOE为负时,起到了负向影响。而WOE值的大小,则是这个影响的大小的体现
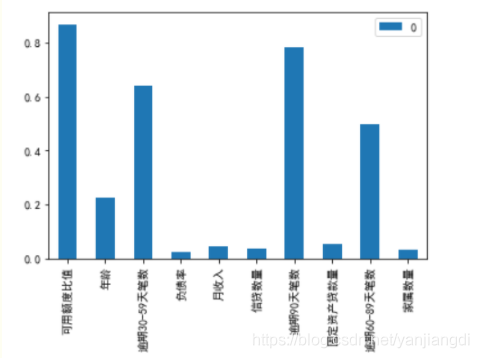
3) IV值计算
IV的全称是Information Value,中文意思是信息价值,或者信息量。它的作用其实和gini和信息熵类似,都是用来衡量变量的预测能力,可以通过IV值来达到特征筛选的目的。

![]()
![]()
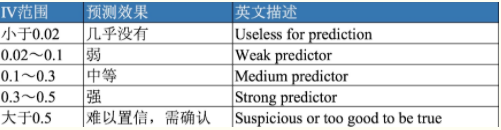
通过特征IV的可视化,可以很直观的观察特征之间的差异,我们选择IV较高的特征代入模型。r如下是IV值范围说明的情况:
![]()
4) 为啥用IV不用WOE进行特征选择
第一个原因:当衡量一个变量的预测能力时,所使用的指标值不应该是负数,否则,说一个变量的预测能力的指标是-2.3,听起来很别扭。从这个角度讲,乘以pyn这个系数,保证了变量每个分组的结果都是非负数。可以验证的是,当一个分组的WOE是正数时,pyn也是正数,当一个分组的WOE是负数时,pyn也是负数,而当一个分组的WOE=0时,pyn也是0。
第二个原因:乘以pyn后,体现出了变量当前分组中个体的数量占整体个体数量的比例,对变量预测能力的影响。
6、建立模型
建立logistics模型,logistics回归是广义线性回归,它的在建立后和线性回归一样会赋值给特征不同的权重,很符合建立评分卡的概念。
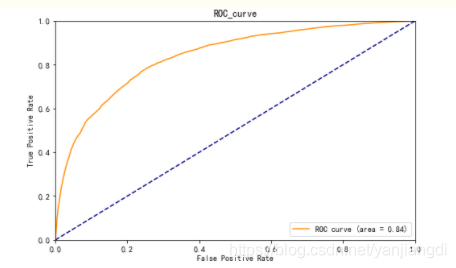
模型测试效果的准确率并不能反映模型的真实效果,我们需要利用下面ROC曲线来评估模型。
![]()
模型在ROC曲线上大致表现不错,AUC也达到了0.84。
7、建立评分卡

![]()
![]()
![]()
1) 根据资料查得评分卡创建公式。
2) 将数据集代入到自定义函数,计算评分标准。
3) 计算每个变量得分,每个特征对应的分数如下:

![]()
将用户数据代入到评分标准后求和,就可以得到该用户的总分。得分越高代表其越有可能成为坏的客户。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号