

深入解析:刘聪NLP | 等了大半年的Qwen3-VL终于也开源了!附模型细节&实测!
本文来源公众号“刘聪NLP”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/h25IJMUH5yFIjATaAi8dqA
刘聪NLP。就是大家好,我
抓着云栖大会,猛开源是吧,两天时间,开源了Qwen3-Omni系列模型、Qwen-Image-Edit-2509模型、Qwen3-VL模型、Qwen3Guard-Gen系列模型,共计12个。
还有一些没开源的API,比如Qwen-TTS、Qwen3-Coder-Plus、Qwen3-Max、Qwen3-LiveTranslate等等等
PS:我恨俊旸呀!天天凌晨开源~
说实话,根本测不完,都知道我一直在等Qwen3的VL模型,其他模型先放一放,今天先来测试一波VL模型。
先来看看模型相关内容,Qwen3-VL相较于Qwen2.5-VL有以下方面改进,
vision encoder部分,Qwen3-VL沿用之前的VisionPatchEmbed,采用Conv3d,不过patch_size从14扩到了16,激活函数从silu变成gelu_pytorch_tanh
projector部分,从之前的MLP-based Projector,额外增加DeepStack,把vision encoder中,8、16、24三层的特征,插入到LLM中
MoE模型,位置编码MRoPE-Interleave,t,h,w 交错分布的形式,对长视频理解效果更好。就是llm decoder部分,采用Qwen3模型,能够是Dense模型,也可以是MoE模型,暂时开的Qwen3-VL-235B-A22B
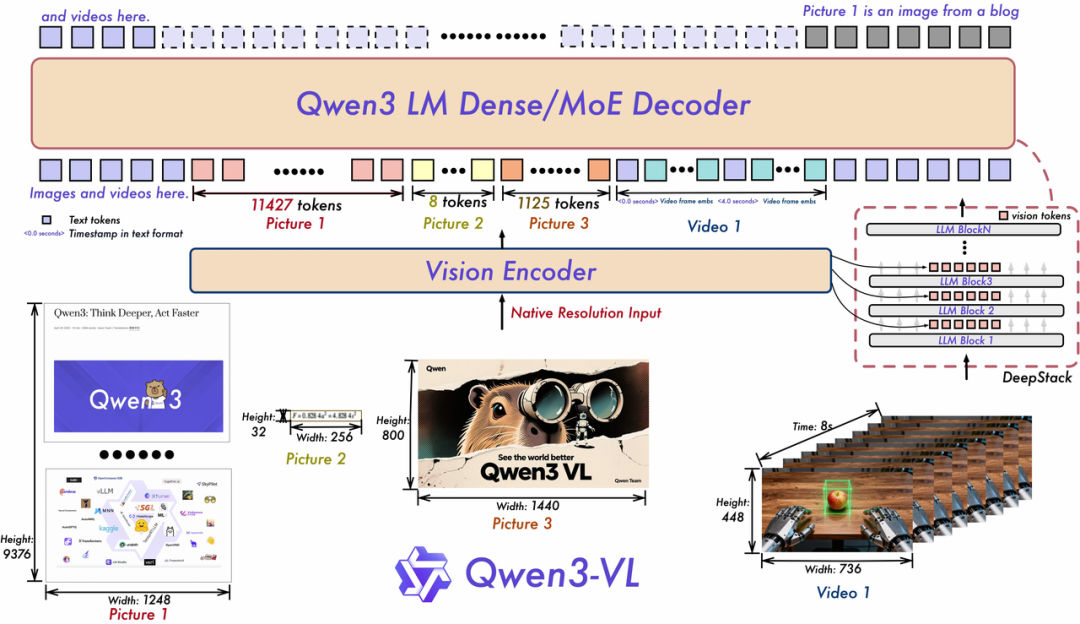
Qwen2.5-VL的相关细节就不多说了,感兴趣的可以去看Paper,
https://arxiv.org/abs/2502.13923
Qwen3-VL的纯文本能力与Qwen3-235B-A22B-2507媲美,相关榜单,
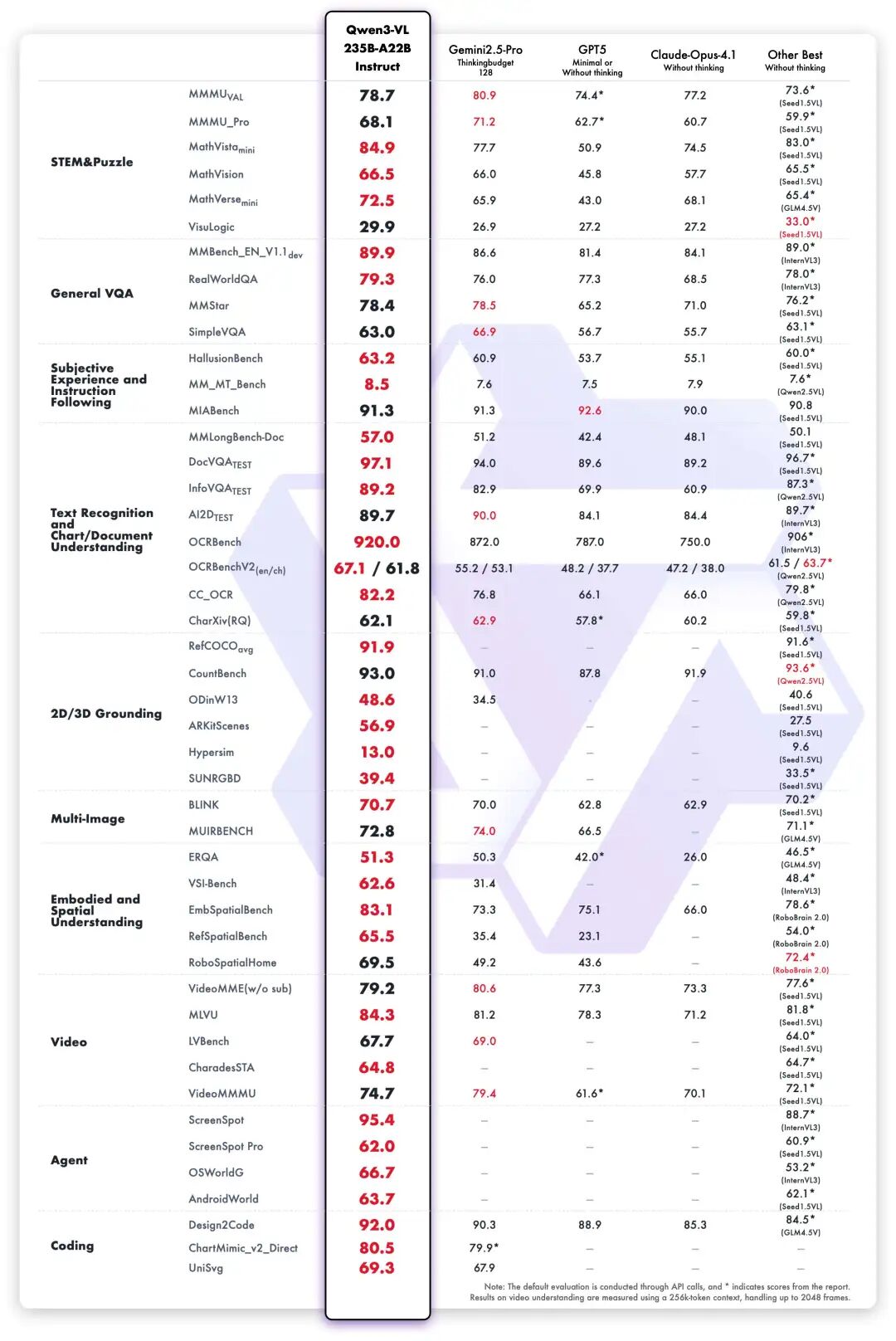
HF:https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
下面带来实测,懒人速览版:
表格识别,Qwen3-VL依旧牛逼,本来Qwen2.5-VL就很强
对色彩的把握程度变高,之前色盲测试一堆问题,现在多次实验,结果均正确
图片排序任务,雪糕对了,菌子错了,但也解释比较合理,相较于Qwen2.5提高很多,并且比主流开源VL模型效果要好
网页复刻任务效果比较差,该跟榜单coding提高有点不同,但我测试了几个复刻,效果都一般
不行就是空间变换能力较之前有提高,可以正确识别出主视图,但其他较复杂变换,还
资料、推理计算很强,尤其是是推理计算,比主流开源VL模型都要好
目标对比不好,但可以经过grouding正确识别,感觉还是图片编码切割的问题,现在VL模型都一样
世界知识跟训练集相关,上海金茂大厦依然识别成上海中心大厦
我发现,think版本相较于instruct版本会过度思考,而导致回答错误
在屏幕理解并找到正确内容位置,因为grouding不错,GUI能力也不错就是当然GUI本质
有的结果差不多,instruct和think我就放一个了
整体提高很多,应该是现在开源VL的Top了
OCR识别
考察内容提取能力,为了增加难度,上手写体。
Prompt:请识别图中的文本内容,言简意赅。

Qwen3-VL-235B-A22B-Instruct:回答正确

Qwen3-VL-235B-A22B-Thinking:回答正确

表格识别
考察内容提取和指令跟随能力,需将表格图片用HTML进行还原。
Prompt:
## Role
你是一位有多年经验的OCR表格识别专家。
## Goals
需要通过给定的图片,识别表格里的内容,并以html表格结果格式输出结果。
## Constrains
- 需要认识识别图片中的内容,将每个表格单元格中的内容完整的识别出来,并填入html表格结构中;
- 图片中的表格单元格中可能存在一些占位符需要识别出来,例如"-"、"—"、"/"等;
- 输出表格结构一定遵循图片中的结构,表格结构完全一致;
- 特别注意图片中存在合并单元格的情况,结构不要出错;
- 对于内容较多的图片,一定要输出完整的结果,不要断章取义,更不要随意编造;
- 图片内容需要完整识别,不要遗漏,同时注意合并单元;
- 最终输出结果需要是html格式的表格内容。
## Initialization
请仔细思考后,输出html表格结果。
Qwen3-VL-235B-A22B:回答正确
再来一个,字多的
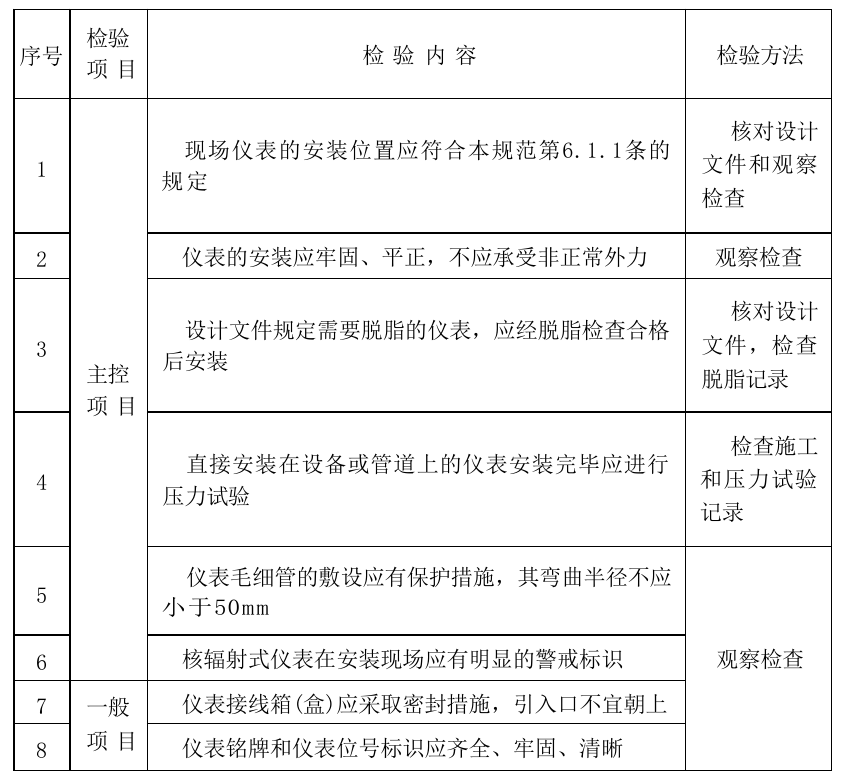
Qwen3-VL-235B-A22B:回答正确
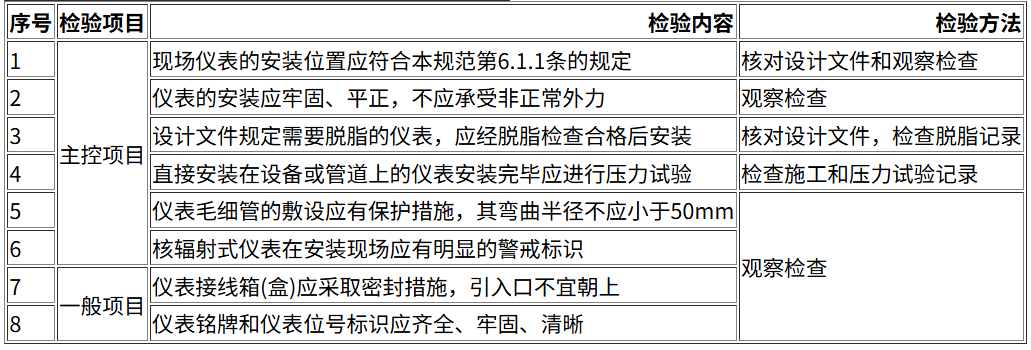
网页复刻
上传一个截图,让多模态大模型进行还原,考察审美和代码能力。
Prompt:请帮我1:1还原这个网页内容,用HTML呈现。
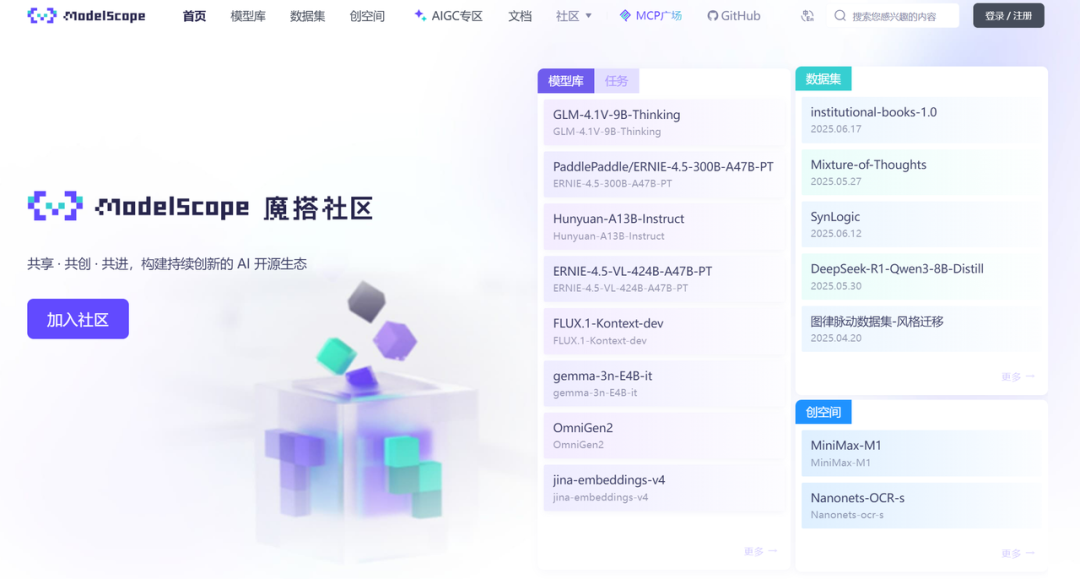
Qwen3-VL-235B-A22B:有点奇怪,不好看
报告分析
考察内容理解能力、知识储备的能力,上传一个体检报告,看看能不能分析出来问题,以及相关的注意事项。
Prompt:请帮我解读一下报告内容。
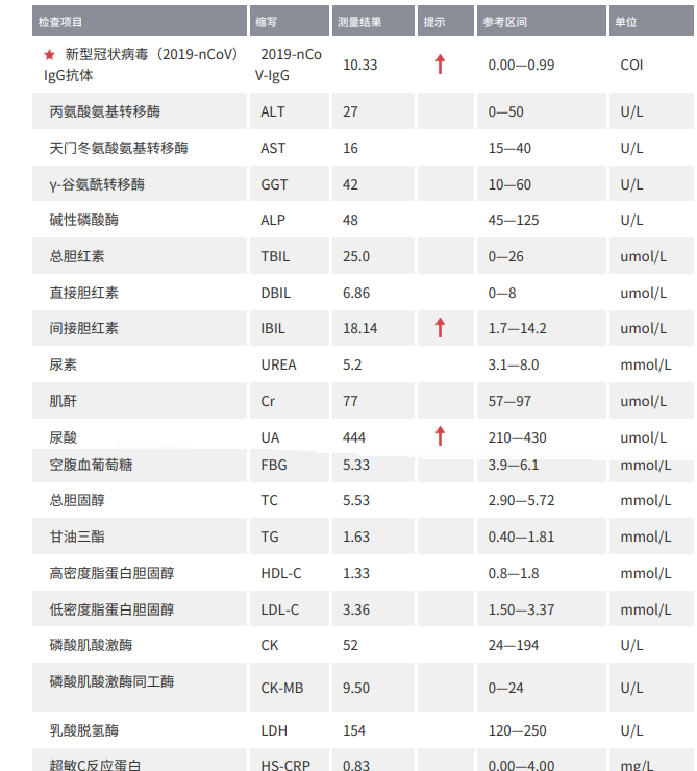
Qwen3-VL-235B-A22B:解读正确

理解计算
考察内容理解能力、计算能力,上传一个GDP表格,找到最大值并计算占比。
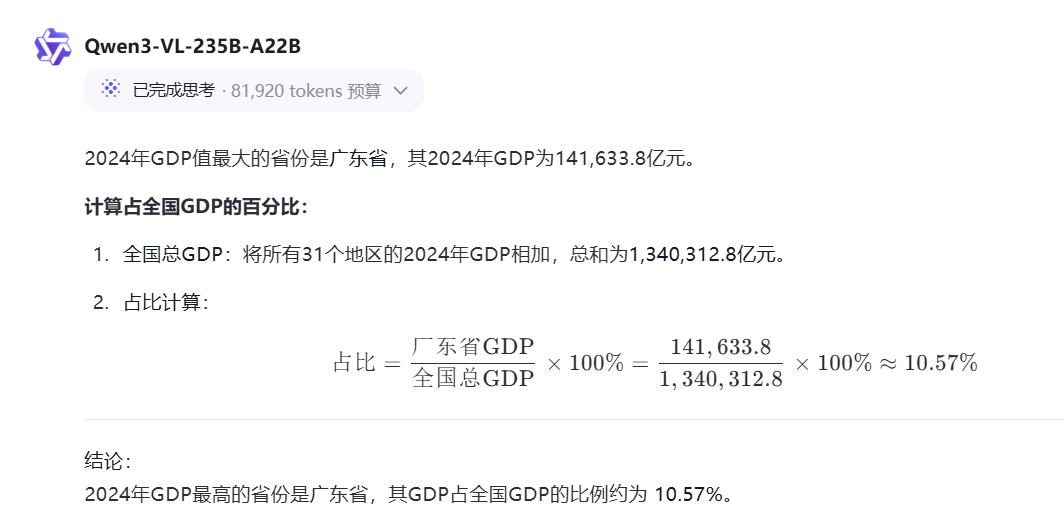
Prompt:找到2024年GDP值最大的省份,并且计算占全国GDP的百分之多少?
2024年总和=1340312.8
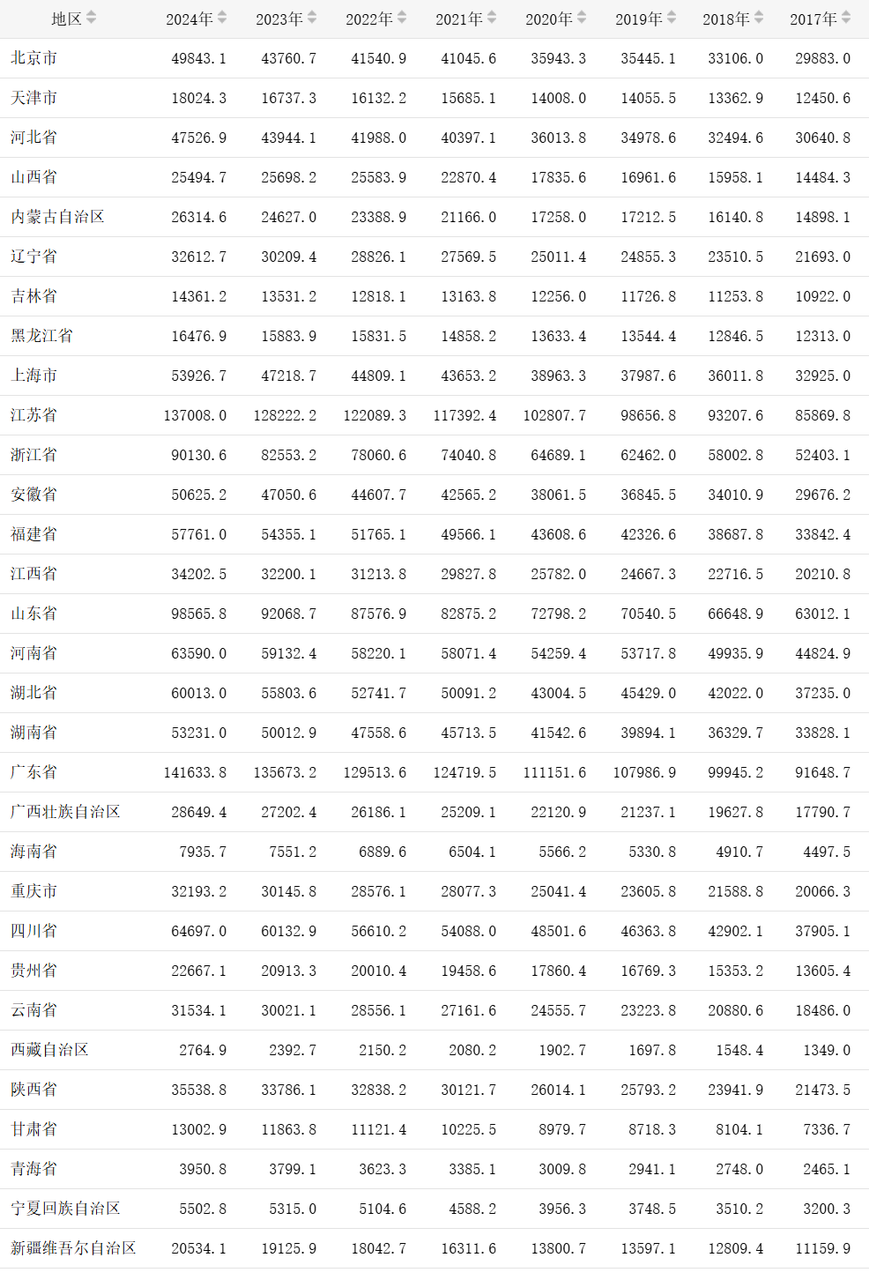
Qwen3-VL-235B-A22B-Instruct:计算正确,很强,之前模型都很难对

Qwen3-VL-235B-A22B-Thinking:计算正确
目标识别
主要考察多模态模型对事物的识别能力,让模型判断事物是否准确、或者查东西的个数。
Prompt:图片上是两只狗对吗?

Qwen3-VL-235B-A22B:回答正确

Prompt:告诉我桌子上菇娘儿的个数。

Qwen3-VL-235B-A22B:回答错误,应该是10个

目标对比
主要考察多模态模型对图片细致内容解析及分析的能力,还有多图对比的能力。
Prompt:找到图片中奔跑的人,并返回行列序号,比如:几行几列。
正确答案是6行10列

Qwen3-VL-235B-A22B-Instruct:回答错误

Qwen3-VL-235B-A22B-Thinking:回答错误
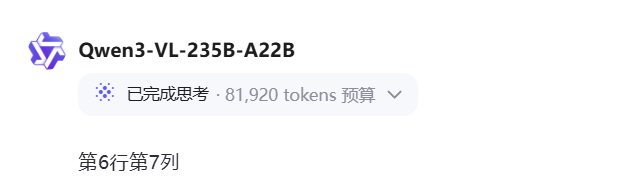
Prompt:找到不开心的小恐龙,并返回行列序号,比如:几行几列。
正确答案是11行1列,11行6列

Qwen3-VL-235B-A22B-Instruct:回答错误
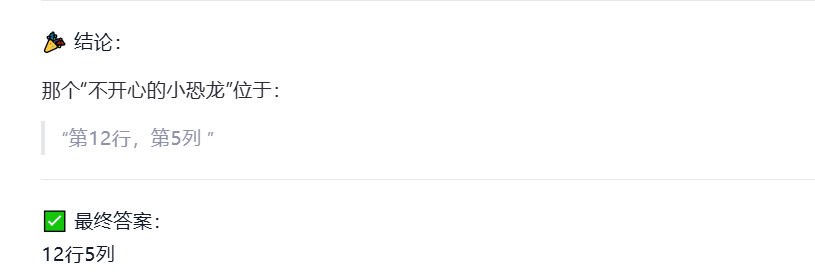
Qwen3-VL-235B-A22B-Thinking:回答错误

Grouding
查看模型定位能力,之前纯文本输出找不到的内容,grouding是能够找到的
Qwen3-VL-235B-A22B-Instruct:

Qwen3-VL-235B-A22B-Thinking:


数学做题
数学题看模型的数学能力,测试2025年高考题。
Prompt:解题

Qwen3-VL-235B-A22B:回答正确,NB之前文本模型最后一问回答有问题,VL竟然对了
图片排序
考察模型能否理清多张图片之间逻辑关系的,能否理解世界事件发展的规律。
Prompt:根据图中展示的多个场景,将最有可能发生的事件按顺序排列。 正确答案CADB,走到商店,买雪糕,滑倒,打到脸上
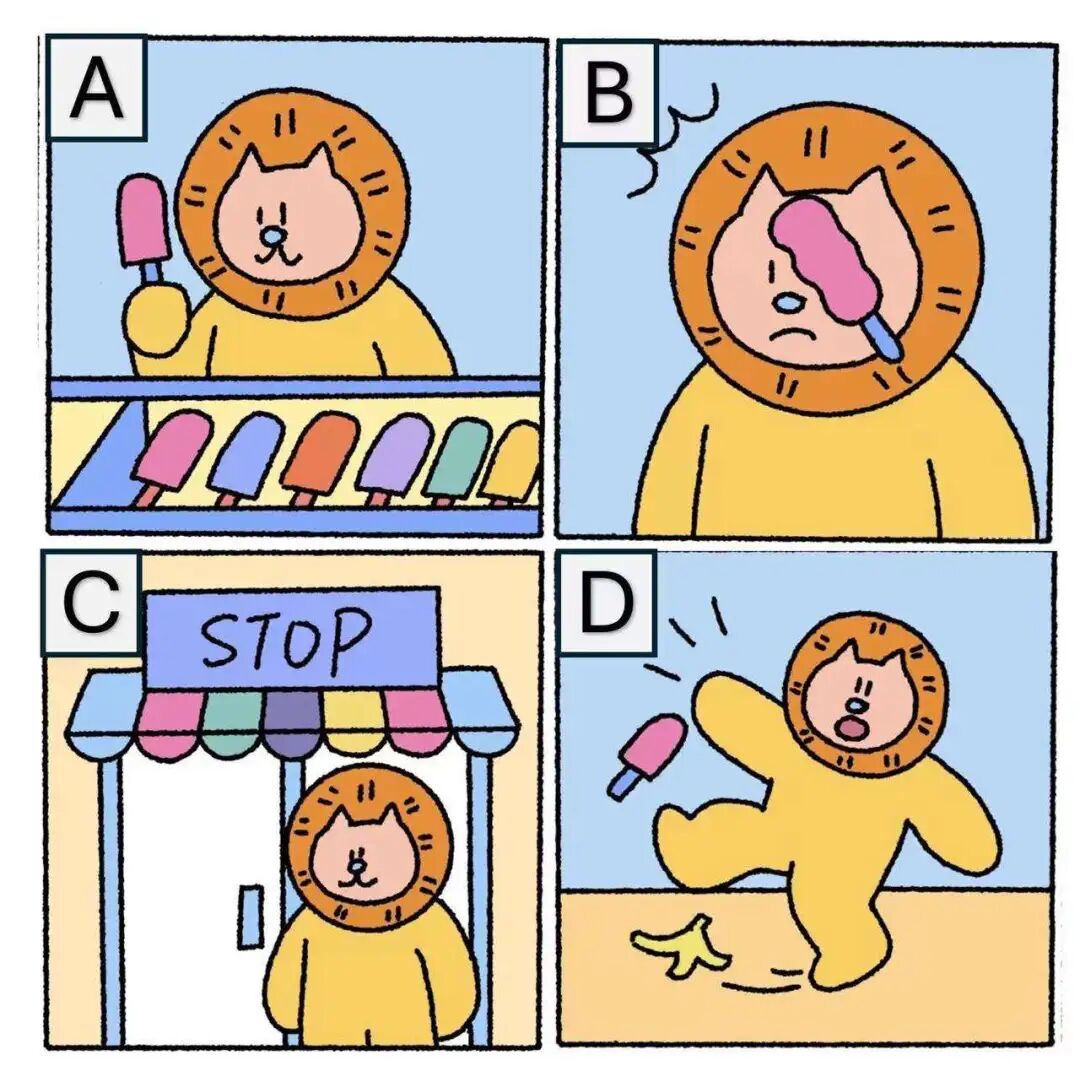
Qwen3-VL-235B-A22B:回答正确,牛逼,完美理解
Prompt:根据图中显示的多个场景,将最有可能发生的事件按顺序排列。 正确答案CDAB,有蘑菇,采摘并吃掉,有点晕,产生了幻觉蘑菇会走了

B-A就是Qwen3-VL-235B-A22B:回答不太对,但是也对,解释的也合理,核心是A-B,还

空间逻辑
考察模型在理解图片的基础上进行深度的逻辑分析,直接考公逻辑题。
Prompt:请回答。
正确答案为A。

Qwen3-VL-235B-A22B:回答错误,该回答很长,很长,到最后会出现中英文夹杂的现象,应该是本身Qwen3-235B-A22B的问题。

空间变换
考察模型对图像的空间转换能力。
Prompt:请回答。
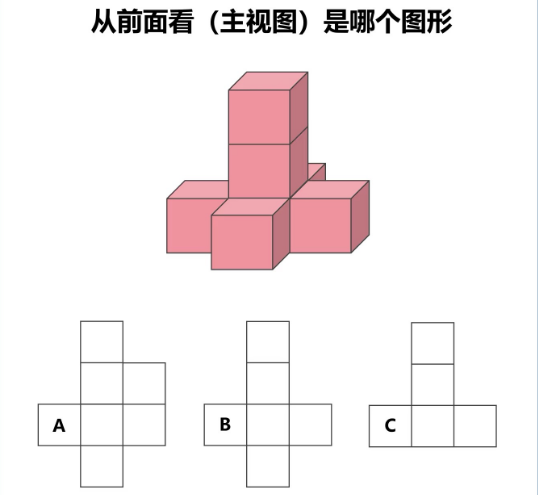
Qwen3-VL-235B-A22B:回答正确,行正确识别主视图

Prompt:请回答,哪个选项的六面体展开结果是上面的展开图。
正确答案为D
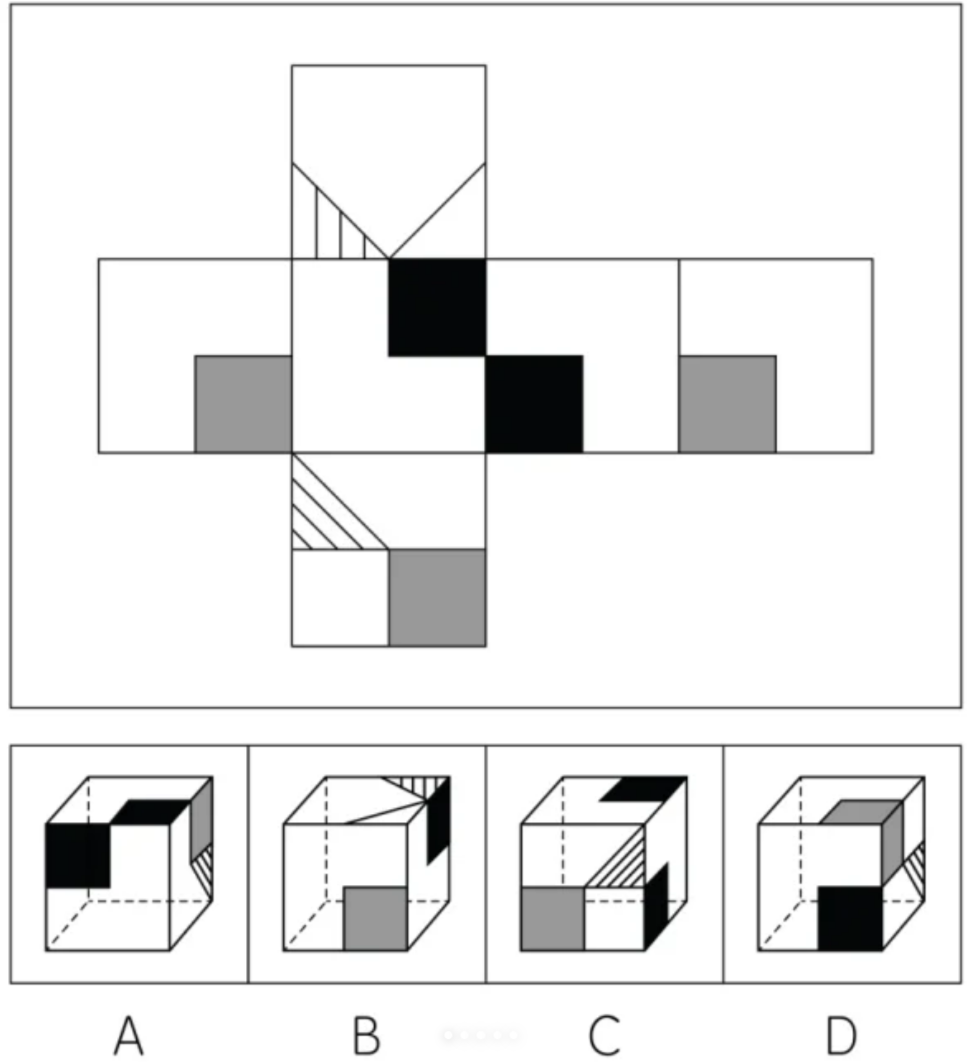
Qwen3-VL-235B-A22B:回答错误

色盲测试
考察大模型对颜色的识别能力。
Prompt:图片里有数字吗?如果有的话是什么?
正常者能读出6,红绿色盲者及红绿色弱者读成 5,而全色弱者则全然读不出上述的两个字。

Qwen3-VL-235B-A22B:回答正确

Prompt:图片里有数字吗?如果有的话是什么?
色觉正常的人能清楚地从图中看出数字74,红绿色盲者会看到21,而全色盲者可能看不出数字。
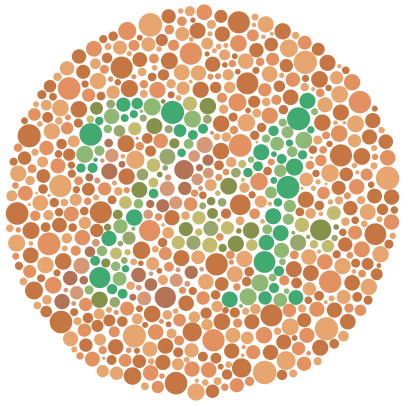
Qwen3-VL-235B-A22B:回答正确

世界知识
通过考察模型的世界知识能力,看到标志性建筑,是否能够判断具体地点。
Prompt:朋友拍了一张图片,可以告诉我他是在中国哪个城市拍的吗?

通过Qwen3-VL-235B-A22B:回答正确,能够认出盘锦红海滩

Prompt:朋友拍了一张图片,允许告诉我他是在中国哪个城市拍的吗?
上海金茂大厦,算是标志性建筑了。

Qwen3-VL-235B-A22B:回答错误,上海金茂大厦依然识别不对,识别成上海中心大厦,大概率是上海中心大厦资料较多的疑问。

最终想说,等了半年,Qwen3-VL终于出来了,整体效果我还是比较满意的,
相较于之前有很大提高,同时应该也是现在VL模型的Top级别,
有点大了,期望出个贫民版吧,来个30B-A3B的就很舒服了,就是不过235B-A22B还
都肝到云栖大会发布,真是肝麻了,一下子更新这么多模型,omni、tts、max我都还没来得及测,
后面测完在更~
THE END !
我继续更新的动力。就是文章结束,感谢阅读。您的点赞,收藏,评论大家有推荐的公众号许可评论区留言,共同学习,一起进步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号