实用指南:Linux coredump原理 图文详解
目录
(代码:linux5.16.8,架构:arm64)
One look is worth a thousand words. —— Tess Flanders
在阅读本文内容之前,我们不妨先思考以下几个问题:
1)coredump文件,是谁生成的 ?
2)coredump文件中,都保存了哪些内容?
3)多线程的程序发生coredump时,会发生什么?
4)若应用中,有多个线程在同一时刻触发Segment Fault,又会发生什么?
一、coredump 文件内容
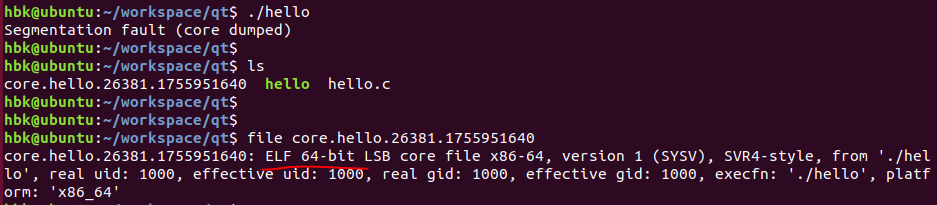
coredump档案,本质上与一般的可执行文件一样,也是一个ELF格式的文件,当程序触发异常,且异常无法被内核处理时,程序在内核中会触发crash流程,并生成coredump文件,保存应用异常时的上下文信息。它就像是脚本世界的"黑匣子",记录了崩溃瞬间的完整现场。
纵然coredump同样是ELF格式的记录,但与一般的可执行文件还是有一些区别:
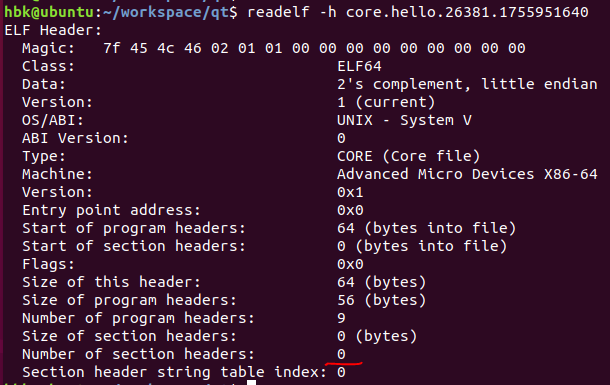
1)coredump文件只关注程序运行时的状态,因此coredump文档没有Section信息,只有Segment信息,经过readelf工具可以看到coredump文件的“Number of section headers” 为0:
2)coredump文件中,对于可执行('E')类型的segment,其filesz字段为0,也就是说可执行的代码段内容,不会实际保存到coreudmp文件中,这些内容是应该在调试阶段gdb去加载原始ELF软件到对应的虚拟地址后,进行分析的:
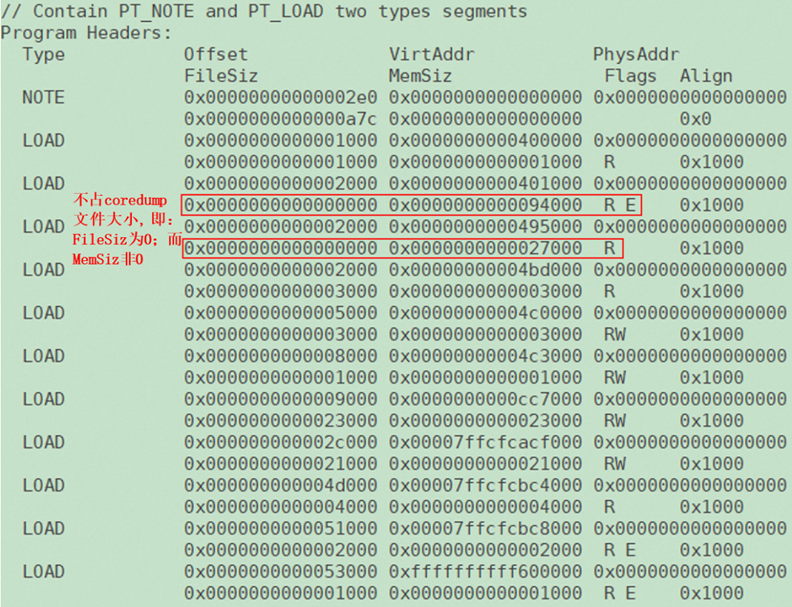
【Coredump文件内容】
从上图中,也可以直观的看出:coredump文件由两类Segment构成,分别是 PT_NOTE类型的、以及 PT_LOAD类型的segment。
- PT_NOTE
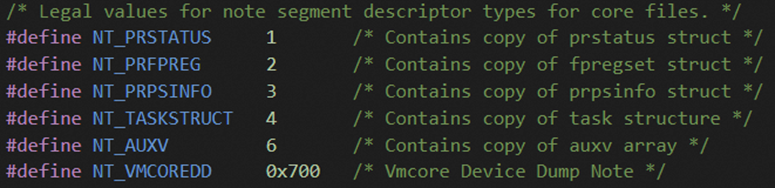
PT_NOTE,是 elf core文件 中新增的segment,记录解析memory区域的关键信息。PT_NOTE segment 被分成了多个elf_note结构,其中NT_PRSTATUS类型的记录了复位前CPU的寄存器信息,NT_TASKSTRUCT记录了进程的task_struct信息,还有一个最关键类型的自定义VMCOREINFO结构记录了内核的一些关键信息;
该segment包含coredump文件创建时的进程状态信息,如导致crash的signal,pending & held signals,进程/父进程UID,nice,寄存器值(包括当前pc)等
- PT_LOAD
在coredump文件中,每个segment用来记录一段memory区域,还记录了这段memory对应的物理地址、虚拟地址和长度、flag(读、写、执行等)。这些PT_LOAD类型的segment的设置,是利用遍历进程中每个vma进行设置的,并且将vma的内容写到coredump记录中,elf core文件的大部分内容用PT_LOAD segment来记录memory信息。
PT_LOAD主要包含以下内容:p_type、p_offset、p_vaddr、p_paddr、p_filesz、p_memsz、p_flags、p_align;
以上介绍了coredump文件的组成内容都有哪些,可能看上去还是有些抽象,那么我们用一张图,直观的给出coredump文件的内容布局,究竟是怎样的:
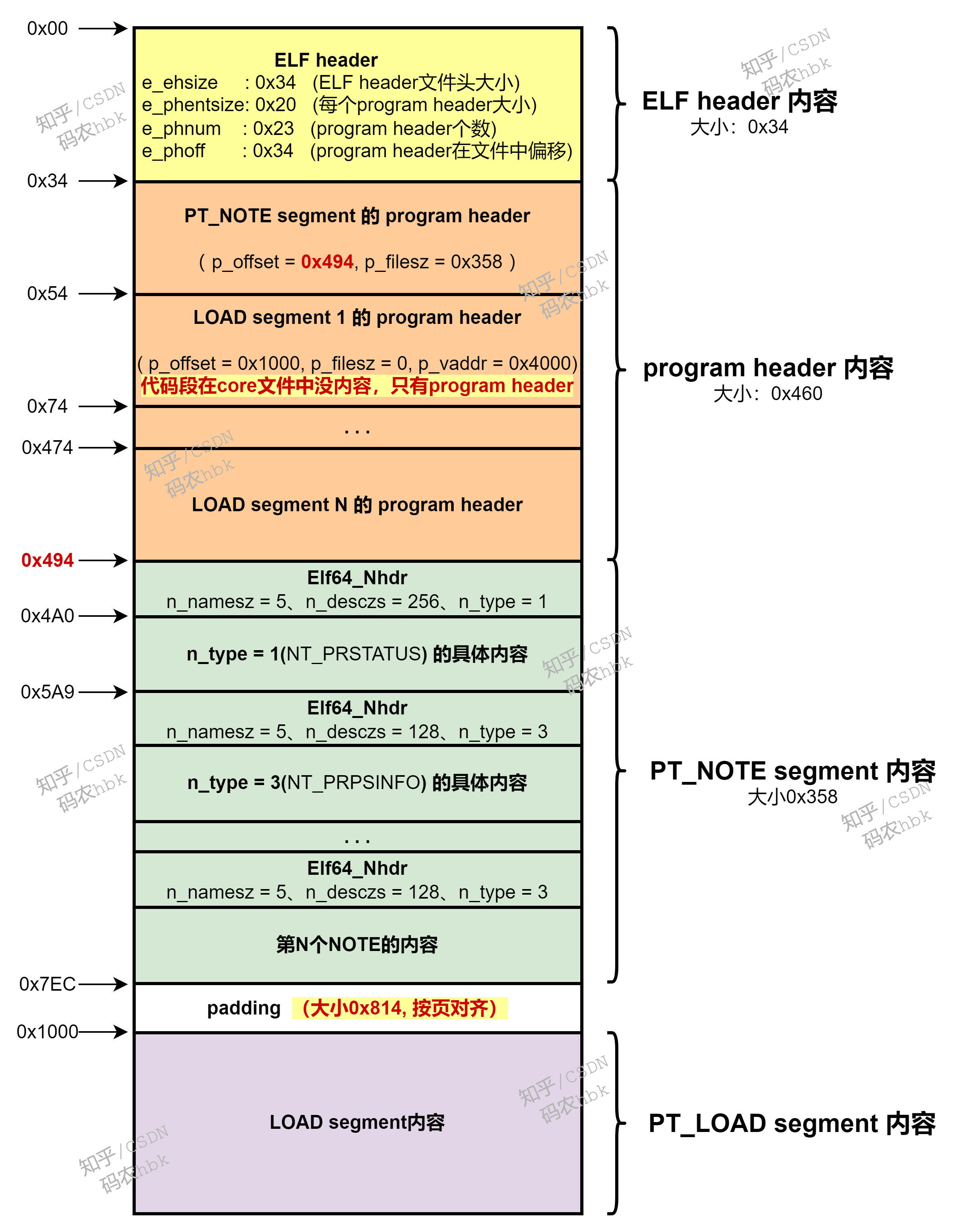
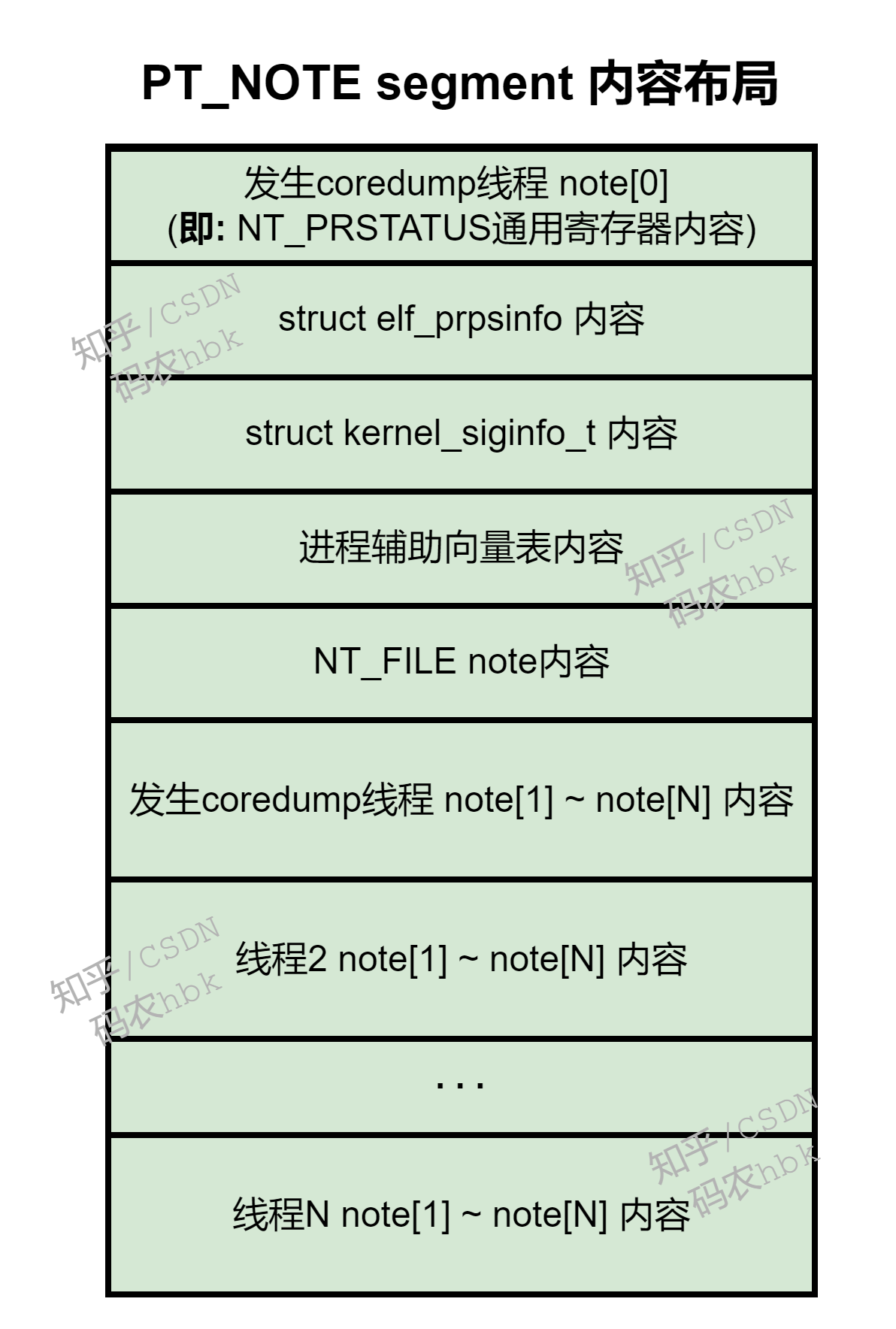
其中,PT_NOTE segment 的内容布局如下:
以上coreudmp文件的内容,都是在APP程序发生异常crash后,在内核中,由软件中某个线程去负责填写生成的,具体完成代码在内核elf_core_dump函数中。
以上介绍了coreudmp文件的内容,以下的篇幅,会着重分析:一个程序从发生segment fault的那一刻起,到最终生成coreudmp材料完毕的完整流程是怎样进行的,以及各种corner case的处理。
二、coredump 构建原理

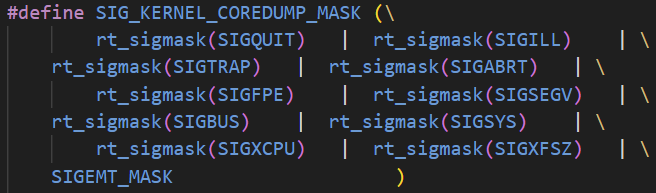
不论是哪种原因造成的程序crash,在task陷入内核的异常处理函数中,都会给当前任务设置一个pending的信号(SIG_KERNEL_COREDUMP_MASK中的某一个信号,大部分情况下会设置SIGSEGV):
随后在同步异常处理完毕后,返回用户态前夕,会检查信号,若发现当前任务有带处理的信号,则会走信号处理流程(signal_get),这里面就会去真正执行coredump相关的流程了!
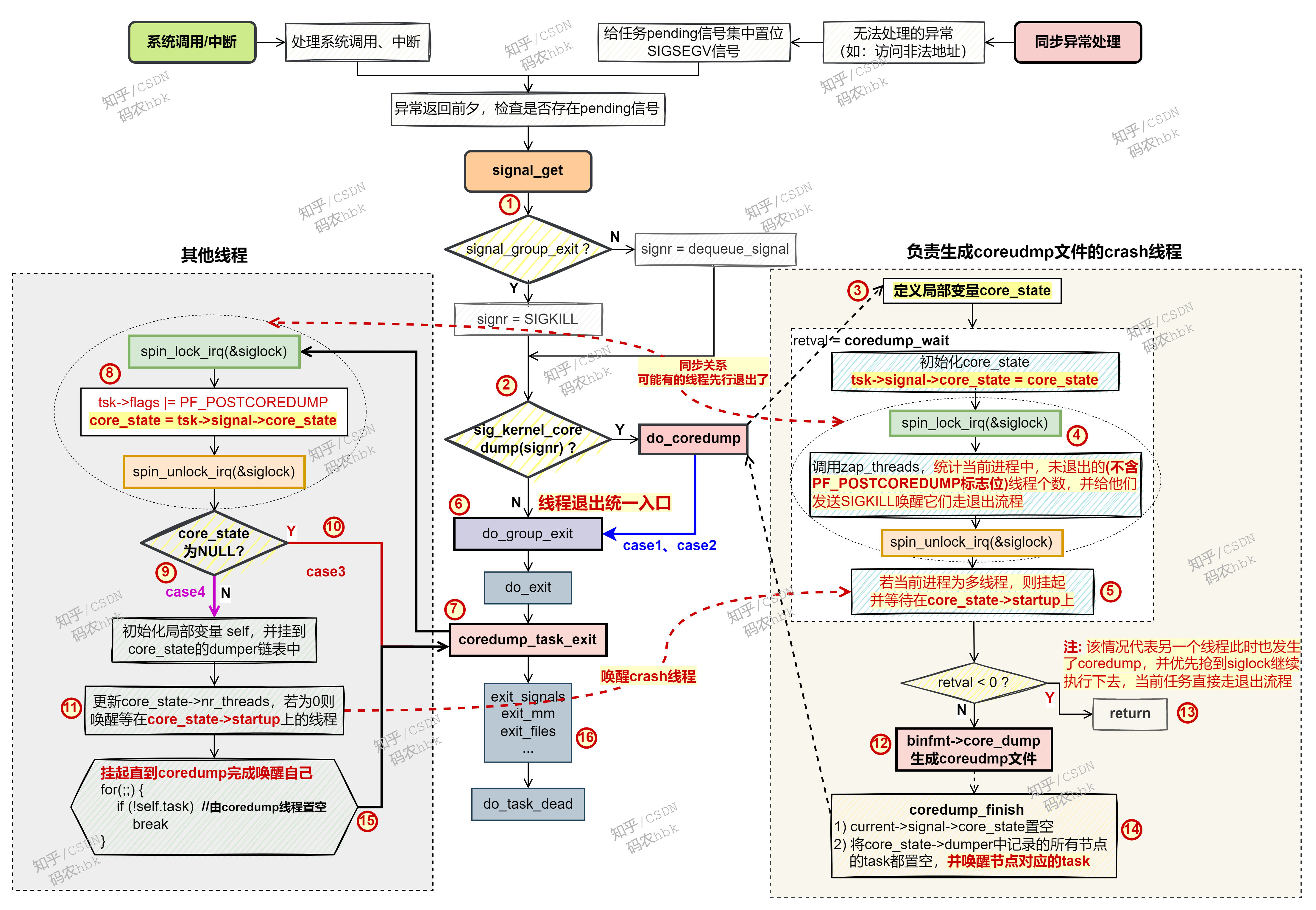
接下来,简单描述下图中当一个脚本发生crash时,各个线程做的事情:
【触发segment fault的线程】
1)触发crash的任务,在异常返回前夕,检查当前任务是否有pending的信号;
2)发现存在需要执行coredump动作的pending信号,于是执行do_coredump,做一些前期准备工作;
3)定义一个局部变量core_state,并将其赋值给当前进程的字段(task->signal_core_state)中,用于表示当前进程应该执行coredump流程;
4)统计当前进程中未退出的线程数量,并依次给它们置位SIGKILL信号,并唤醒所有其他线程,让其去执行信号处理流程,这些线程最终都会在执行SIGKILL的退出流程中挂起;
5)当前触发crash的线程主动挂起,直到进程中其他所有线程都挂起后,会唤醒自己继续运行;
12)调用 binfmt->core_dump函数(即:elf_core_dump),去生成coredump的内容;
14)当coredump文件创建完毕后,唤醒进程中的其他线程,继续走退出流程;
6)当前触发crash的线程,从do_coredump函数返回,同样继续走线程退出流程;
【其他线程】
1)其他正常运行的线程,由于接收到SIGKILL信号,在内核返回用户态前夕,同样会走信号处理流程,调用signal_get 获取待处理的信号;
2)由于接收到的是SIGKILL信号,于是直接走do_group_exit流程;
7)在do_exit流程中,会调用coredump_task_exit函数,检查当前进程是否需要执行coredump流程;
否需要走coredump流程;就是8)凭借读取当前进程中的字段(task->signal_core_state)是否置位,来判断当前进程
10)若该字段为NULL,说明无需coredump,则直接从coredump_task_exit函数返回,并继续走常规的退出流程;
9)若发现core_state字段非NULL,则说明当前进程中某个线程发生了segment fault,需要走coredump流程;
最后一个挂起的线程,则通过complete操作,唤醒等待在core_state->startup变量上的“发生crash的线程”;就是11)更新core_state中的信息,为发现当前线程
15)将当前线程挂起,直到触发crash的线程完成coredump文件生成工作后,会将自己唤醒;
16)当coredump完成后,当前线程被唤醒,从coredump_task_exit函数返回,并继续执行常规的tuich
三、发生coredump时的一些corner case
1)程序中,同一时刻有多个线程同时发生segment fault触发coredump,最终会由哪个线程真正去执行coreudmp文件生成的工作?
结论:当有多个线程同时crash时,最终只会有一个线程去执行真正的coredump文件生成工作,其余所有线程(包括同样发生crash的线程)都需要挂起,等待coredump文档生成完毕。
代码分析:在linux5.16.8的实现中,发生coredump的多个thread首先会进入do_coredump, 接着竞争拿tsk->sighand->siglock锁, 判断(sig->flags & SIGNAL_GROUP_EXIT) 和(sig->group_exit_task != NULL) 这2个条件是否有一个为True。若都不为true, 就把tsk->signal->group_exit_task设为current,随后给所有其他任务发送SIGKILL并唤醒,走信号退出流程(在do_exit中发现是coredump就会把自己挂起)。
若同时发生coredump的多个线程中, 有一个先把sig->group_exit_task置为current, 其余发生coredump的线程在zap_threads中就会因为(sig->group_exit_task != NULL)为True, 而返回-EAGAIN, 最终do_coredump直接返回, 再次进入do_group_exit流程, 随后在do_exit中执行coredump_task_exit, 发现处于coredump, 就把自己挂起。
2)当一个线程发生 segment fault 时,若另一个线程执行了pthread_exit,正在内核中执行do_exit退出流程,那么这个线程的信息会被收集到coredump文件中么?
结论:若发生crash的那一刻,正好有其他线程在执行do_exit退出流程,那么它会判断一下当前进程是否处于coredump状态(即上图中的第10步,检查core_state是否为NULL),若处于coredump状态的话就将自己挂起;否则,就会更新当前任务的状态或者整个进程的线程个数,然后继续走退出流程,这种情况下该线程就不会被统计到coredump信息中。
代码分析:是linux 5.16.8中,线程的退出在内核中会走到do_exit, 继而调用coredump_task_exit 将线程的 tsk->flags 置位PF_POSTCOREDUMP,然后去检查是否处于coredump状态, 若处于就将自己挂起并更新core_state->nr_threads; 否则的话就继续执行do_exit退出流程。
在首次发生coredump时, 函数zap_process统计当前进程的线程个数时, 会跳过置位PF_POSTCOREDUMP的线程, 有这个位的任务代表它已经在退出流程后期了。
发生coredump时,线程个数统计依据: 统计那些task->flags没有置位PF_POSTCOREDUMP的任务,那些已经置位PF_POSTCOREDUMP的线程不会被统计到core_state->nr_threads中。
四、代码实现
get_signal {
struct signal_struct *signal = current->signal
int signr
### 当前线程需要执行退出流程, 在do_exit中会检查是否存在coredump需要挂起
if (signal_group_exit(signal)) {
ksig->info.si_signo = signr = SIGKILL
sigdelset(¤t->pending.signal, SIGKILL)
goto fatal
}
signr = dequeue_synchronous_signal(&ksig->info)
fatal:
spin_unlock_irq(&sighand->siglock)
current->flags |= PF_SIGNALED
if (sig_kernel_coredump(signr)) {
/*
* If it was able to dump core, this kills all
* other threads in the group and synchronizes with
* their demise. If we lost the race with another
* thread getting here, it set group_exit_code
* first and our do_group_exit call below will use
* that value and ignore the one we pass it.
*/
do_coredump {
struct core_state core_state
struct coredump_params cprm = {
.siginfo = siginfo,
.regs = signal_pt_regs(),
.limit = rlimit(RLIMIT_CORE),
.mm_flags = mm->flags,
};
binfmt = mm->binfmt
### coredump_wait主要用于统计当前进程中未退出的(不含PF_POSTCOREDUMP标志位)线程个数, 并给他们发送SIGKILL
### 唤醒它们走退出流程. 然后本线程等在core_state->startup上, 直到最后一个线程停下来通知唤醒本线程.
###
### 注: 这个函数里有一个多线程竞争点! 在zap_threads中, 同时只能有一个发生coredump的线程成功抢到siglock
### 并设置相应状态. 那些后抢到锁的coredump线程会直接返回到get_signal中, 继续执行退出流程, 并且会再次
### 发现处于coredump状态并把自己停下.
retval = coredump_wait(siginfo->si_signo, &core_state) {
struct task_struct *tsk = current
int core_waiters = -EBUSY
init_completion(&core_state->startup)
core_state->dumper.task = tsk
core_state->dumper.next = NULL
core_waiters = zap_threads(tsk, core_state, exit_code) {
int nr = -EAGAIN
spin_lock_irq(&tsk->sighand->siglock) // 加锁siglock, 多个线程coredump的话, 只要一个线程能抢到锁, 去做真正的coredump
if (!signal_group_exit(tsk->signal)) {
tsk->signal->core_state = core_state
tsk->signal->group_exit_task = tsk // 第一个拿到锁的coredump线程, 成功将group_exit_task置为自己, 其他coredump线程之后拿到锁, 会发现上面的条件fail直接返回
### 统计不带PF_POSTCOREDUMP标志位的线程个数, 并给他们发送SIGKILL信号并唤醒他们走退出流程
nr = zap_process(tsk, exit_code, 0) {
int nr = 0
for_each_thread(start, t) {
### 若任务t已经置上PF_POSTCOREDUMP位, 就代表该任务已经走到退出流程了
if (t != current && !(t->flags & PF_POSTCOREDUMP)) {
sigaddset(&t->pending.signal, SIGKILL)
signal_wake_up(t, 1)
nr++
}
}
return nr
}
atomic_set(&core_state->nr_threads, nr)
}
spin_unlock_irq(&tsk->sighand->siglock)
### case1: 未抢到siglock的coredump线程返回负数, 直接返回到get_signal, 接着走退出流程do_group_exit,
### 并且会在do_exit中发现存在coredump而将自己停下来.
### case2: 抢到siglock的coredump返回进程中不带PF_POSTCOREDUMP标志位的线程数, 若没有其他线程则返回0
return nr //
}
### 多线程情况下, 等待其他所有线程都走到coredump_task_exit, 并将自己挂起
if (core_waiters > 0) {
wait_for_completion(&core_state->startup)
ptr = core_state->dumper.next
while (ptr != NULL) {
wait_task_inactive(ptr->task, 0)
ptr = ptr->next
}
}
return core_waiters
}//coredump_wait
/*
* 若retval小于0, 就代表此时另外一个线程也在做do_coredump, 且它率先拿到了siglock给其他任务发送SIGKILL信号,
* 并等待其他任务都停下来通知自己.
*/
if (retval core_dump(&cprm)
A.K.A
elf_core_dump
### coredump执行完毕
### 1) 给group_exit_code置位0x80, 用于wait的status
### 2) 清空current->signal->core_state
### 3) 将core_state->dumper上记录的线程节点的task置NULL并唤醒该task
coredump_finish {
spin_lock_irq(¤t->sighand->siglock)
if (core_dumped && !__fatal_signal_pending(current))
current->signal->group_exit_code |= 0x80
current->signal->group_exit_task = NULL
current->signal->flags = SIGNAL_GROUP_EXIT
next = current->signal->core_state->dumper.next
current->signal->core_state = NULL
spin_unlock_irq(¤t->sighand->siglock)
while ((curr = next) != NULL) {
next = curr->next
task = curr->task
curr->task = NULL
wake_up_process(task)
}
}//coredump_finish
fail_creds:
return
}//do_coredump
}//if (sig_kernel_coredump(signr))
do_group_exit {
do_exit {
/* 拿着siglock锁, 置上PF_POSTCOREDUMP flag(用于coredump刚开始还没统计好线程个数时, 有子线程退出的情况), 获取core_state
* 若core_state不为空, 代表发生coredump了, 更新core_state->nr_threads.
* 若nr_threads为0, 则代表所有子线程都停下来了, 则唤醒发生coredump的那个线程继续执行;
* 若nr_threads不为0, 则将自己挂到core_state->dumper.next中, 并将自己设为不可打断方式的挂起.
* 当coredump收集信息执行完毕后, 发生coredump的那个线程会将core_state->dumper链表中所有core_thread节点的task成员置NULL,
* 并唤醒core_state->dumper链表中成员对应的task. 其余停下来的线程被唤醒后, 会检查self.task, 若为空就从coredump_task_exit
* 返回, 继续走退出流程
*/
coredump_task_exit {
spin_lock_irq(&tsk->sighand->siglock) // 拿锁
tsk->flags |= PF_POSTCOREDUMP
core_state = tsk->signal->core_state // 获取core_state成员
spin_unlock_irq(&tsk->sighand->siglock) // 解锁
if (core_state) {
struct core_thread self
self.task = current
if (self.task->flags & PF_SIGNALED)
self.next = xchg(&core_state->dumper.next, &self)
if (atomic_dec_and_test(&core_state->nr_threads))
complete(&core_state->startup) // 若是最后一个停下来的线程, 则唤醒coredump线程
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE)
if (!self.task)
break; // coredump finish, continue do_exit flow
freezable_schedule()
}
}
### 若core_state为空, 有两种情况: 1)当前任务所在进程没有发生coredump; 2)其他线程发生coredump但还没走到coredump_wait里设置tsk->signal->core_state的地方
}
exit_signals
exit_mm
exit_files
...
do_task_dead {
set_special_state(TASK_DEAD)
__schedule(SM_NONE)
}
}
}
}五、总结
本文介绍了coreudmp档案的组成内容,以及一个程序发生crash后的完整处理流程。用户态程序crash后,主要借助内核的信号机制,做完所有线程的同步、以及各种corner case的处理,最终由触发crash的线程,在内核态中完成coredump文件的生成工作,完成后所有线程都会走常规的退出流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号