
完整教程:python爬虫之网页解析技术
前置技术栈,HTML基础语法、标签的使用,了解即可
1. 爬取原理
网页解析就是解析当前URL的html文件,打开任意一个站点都可以看到当前的index.html。可以看到页面上非常多的文本信息,而这些文本信息,正式我们要抓取的。
所有的标签都有<p>这是你要抓的文本</p>,用代码(如 requests)向网站发送请求,拿到整个 HTML 文本。从源码中定位并提取目标文本,用解析工具(如 BeautifulSoup 或 XPath):找到特定标签(比如 class=“title” 的 <div>),取出里面的文字内容,取出来的文本可以存到文件、数据库,或做进一步分析。
2. 简单示例
01 从字符中提取
代码示例,这里我使用一个文字替换做简单演示
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, "lxml")
# print(soup.prettify())
print("类型: ", type(soup))
print("标题: ", soup.title) # 获取title标签
print("标题名: ", soup.title.name) # 获取title标签的名称
print("标题内容: ", soup.title.string) # 获取title标签的内容
print("标题的父标签: ", soup.title.parent.name) # 获取title标签的父标签
print("p标签: ", soup.p) # 获取第一个p标签运行结果:
C:\Code\python\pacon\venv\Scripts\python.exe C:\Code\python\pacon\01-静态页面抓取\01-bs4\01-base.py
类型:
标题: The Dormouse's story
标题名: title
标题内容: The Dormouse's story
标题的父标签: head
p标签: The Dormouse's story02 从html文件中提取
html文件内容
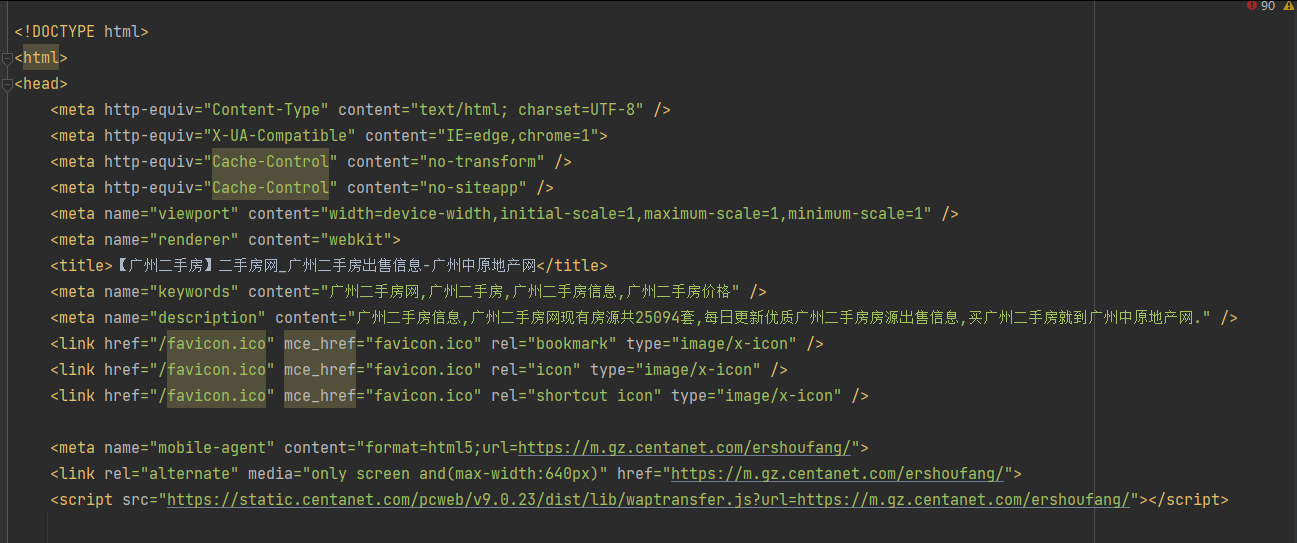
python代码提取
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("../素材/广州二手房.html", encoding="utf-8"), "lxml")
house_list = soup.find_all("div", class_="house-item house-itemB clearfix")
for d in house_list:
# print(d)
# print(list(d.stripped_strings))
# 房子描述
# print(d.h4.a["title"])
# print(d.select(".house-name")[0].text)
# 房子名称 东风东路散盘| 3室1厅 | 70平
# 通过 CSS 选择器定位 class="house-name" 的 <p> 标签,取第一个匹配项([0]),并输出其 .text(所有子标签文本的合并字符串)
print(d.select(".house-name")[0].text.strip(), "\n")运行结果: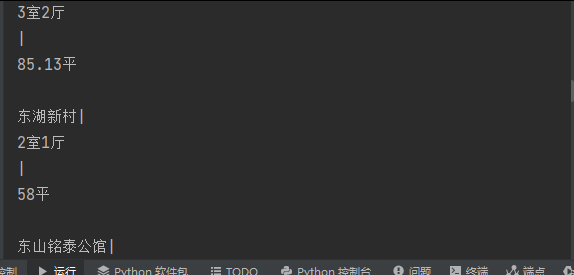
## 三国演义标题
from bs4 import BeautifulSoup
import xml
soup = BeautifulSoup(open("../素材/02-三国演义.html", encoding="utf-8"), "lxml")
chapter_list = soup.select(".book-mulu>ul>li>a")
for i in chapter_list:
print(i.string)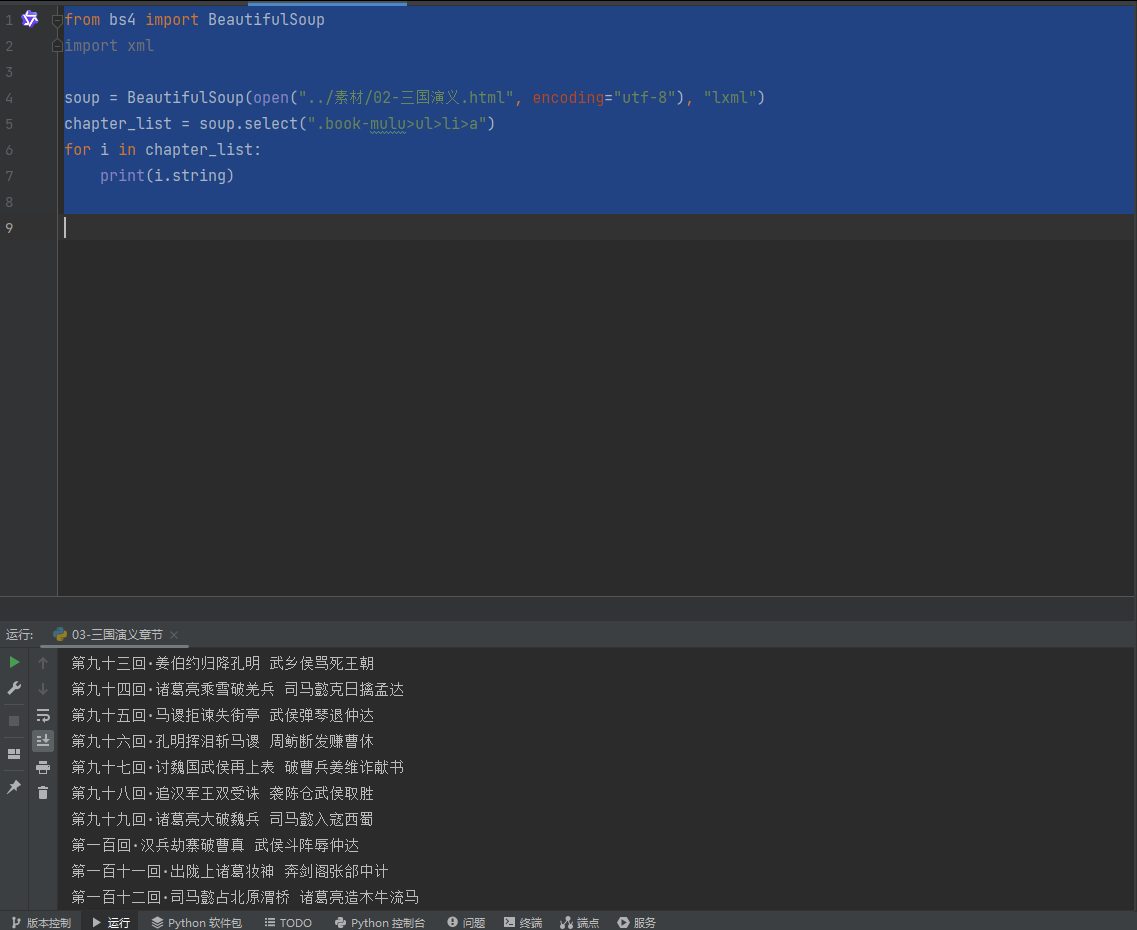

 浙公网安备 33010602011771号
浙公网安备 33010602011771号