
模型蒸馏中loss曲线的原理与应用 - 详解
目录
模型蒸馏中loss曲线的原理与应用
引言
在机器学习领域,模型蒸馏是一种将大型模型(教师模型)的知识迁移到小型模型(学生模型)的技术,旨在提升小模型的性能和泛化能力。在这一过程中,loss曲线作为关键监控指标,不仅反映了训练进度,还揭示了模型学习中的深层信息。本文将深入探讨loss曲线的原理、如何读取loss曲线、其与模型参数的关系,并独特聚焦于**LoRA(Low-Rank Adaptation)**微调工艺在模型蒸馏中的应用。
一、loss曲线的原理
Loss曲线是模型训练过程中损失函数值的可视化表示。损失函数衡量模型预测与真实标签之间的差异,通常随着训练的进行逐渐减小。在模型蒸馏中,loss曲线不仅仅反映学生模型在训练数据上的表现,还包含与教师模型知识迁移相关的部分。
模型蒸馏的损失函数通常由以下两部分组成:
- 交叉熵损失(Cross-Entropy Loss)
学生模型在训练数据上的标准损失,用于衡量学生模型预测与真实标签之间的差异。就是这 - 蒸馏损失(Distillation Loss)
这是学生模型预测与教师模型预测之间的差异,通常采用**KL散度(Kullback-Leibler Divergence)**来计算,目的是让学生模型学习教师模型的输出分布。
总损失函数可以表示为: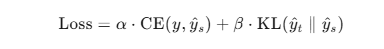

二、如何读取loss曲线
Loss曲线通常以训练步数(或epoch)为横轴,损失值为纵轴绘制。以下是读取loss曲线时需要关注的几个关键点:
- 下降趋势
一个健康的loss曲线应呈现逐渐下降的趋势,表明模型在学习并优化参数。 - 震荡情况
如果loss曲线出现大幅震荡,可能意味着学习率过高,或者训练数据分布不均匀。 - 平稳状态
当loss曲线趋于平稳时,模型可能已经收敛,或者陷入了局部最小值。 - 过拟合迹象
如果训练loss持续下降,而验证loss开始上升,则可能是过拟合的表现。
在模型蒸馏中,除了关注总损失外,还需单独分析蒸馏损失的变化,以确保学生模型有效学习教师模型的知识。
三、loss曲线与参数的关系
模型参数直接影响loss曲线的形态和行为。以下是几个关键参数及其作用:
- 学习率(Learning Rate)
- 学习率过高:loss曲线可能剧烈震荡,甚至发散。
- 学习率过低:loss下降缓慢,收敛时间延长。
- 批量大小(Batch Size)
较大的批量大小供应更稳定的梯度估计,使loss曲线更平滑;较小的批量大小可能导致曲线波动。 - 模型架构
学生模型的复杂度和容量决定了其学习能力,影响loss曲线的下降速度和最终收敛值。 - 蒸馏温度(Temperature)
在计算蒸馏损失时,温度参数控制教师模型输出的平滑度。高温度使输出更平滑,有助于学生模型学习更广泛的知识,但可能降低精度。
四、LoRA在模型蒸馏中的应用
**LoRA(Low-Rank Adaptation)是一种高效的微调技术,特别适合大型预训练模型。它通过冻结大部分模型参数,仅训练一小组低秩矩阵来适应新任务,从而显著降低计算和内存需求。在模型蒸馏中,LoRA的应用使得学生模型的训练更加高效,而loss曲线的监控则成为评估其效果的关键手段。
1. LoRA与loss曲线的关系
- 参数效率
LoRA仅更新少量参数,因此loss曲线的下降速度和稳定性允许反映LoRA配置(如秩的大小)的有效性。 - 过拟合风险
由于训练参数少,LoRA通常比全参数微调更不容易过拟合,但仍需通过对比训练和验证loss曲线来确认。 - 收敛行为
LoRA的loss曲线可能比全参数微调更快趋于平稳,这反映了其高效性,但也可能意味着学习能力受限。
2. LoRA在蒸馏中的优势
- 计算资源节省
LoRA大幅减少训练参数,使其在资源受限场景下仍能做完模型蒸馏。 - 与全参数微调的对比
经过比较LoRA和全参数微调的loss曲线,可以发现LoRA在保持性能的同时显著降低了计算成本。例如,LoRA的loss曲线可能在早期快速下降并稳定,而全参数微调可能需要更多步数才能达到相似效果。
3. 实际应用中的注意点
- 超参数调整
LoRA的秩(rank)和学习率需要根据任务调整,loss曲线是验证这些超参数效果的直接依据。 - 蒸馏损失监控
否有效吸收教师模型知识。就是在LoRA微调的蒸馏中,确保蒸馏损失随训练下降,以验证学生模型
五、结论
Loss曲线是模型蒸馏中不可或缺的分析工具,它不仅帮忙我们监控训练进度,还揭示了模型学习行为和参数配备的深层信息。在LoRA微调技术的应用中,loss曲线的分析尤为重要,能够帮助我们优化模型性能,同时高效利用计算资源。通过合理读取和调整loss曲线,我们能够在模型蒸馏任务中取得更好的效果,为实际应用献出有力支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号