
java8+springboot2.5.4环境Markdwon转word - 详解
Markdwon转word
实现步骤
- 环境:java8+Springboot2.5.4
- Markdown转HTML:commonmark-java 及扩展实现
- 使用docx4j实现html转word
功能实现java代码
引入依赖类
org.commonmark
commonmark
0.21.0
org.commonmark
commonmark-ext-gfm-tables
0.21.0
org.commonmark
commonmark-ext-task-list-items
0.21.0
org.docx4j
docx4j-JAXB-Internal
8.3.13
org.docx4j
docx4j-JAXB-ReferenceImpl
8.3.13
org.docx4j
docx4j-ImportXHTML
8.3.11
commons-io
commons-io
2.11.0
org.jsoup
jsoup
1.15.3
de.klg.utils.jbarcode
jbarcode
1.0.0java代码实现类
MarkdownToHtmlUtils.java
import org.commonmark.Extension;
import org.commonmark.parser.Parser;
import org.commonmark.renderer.html.HtmlRenderer;
import org.commonmark.ext.gfm.tables.TablesExtension;
import org.commonmark.ext.task.list.items.TaskListItemsExtension;
import java.util.Arrays;
import java.util.List;
public class MarkdownToHtmlUtils {
// 支持表格、任务列表扩展
private static final List EXTENSIONS = Arrays.asList(
TablesExtension.create(),
TaskListItemsExtension.create()
);
private static final Parser PARSER = Parser.builder()
.extensions(EXTENSIONS)
.build();
private static final HtmlRenderer RENDERER = HtmlRenderer.builder()
.extensions(EXTENSIONS)
// 为代码块添加语言标识(方便后续转Word时保留样式)
.attributeProviderFactory(context -> (node, tagName, attributes) -> {
if ("code".equals(tagName)) {
attributes.put("class", "language-java"); // 示例:默认Java代码块
}
})
.build();
/**
* Markdown转HTML
*/
public static String convert(String markdown) {
if (markdown == null || markdown.trim().isEmpty()) {
return "";
}
return RENDERER.render(PARSER.parse(markdown));
}
}WordUtils.java
package com.bridge.utils;
import org.docx4j.Docx4J;
import org.docx4j.convert.in.xhtml.XHTMLImporterImpl;
import org.docx4j.jaxb.Context;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.wml.*;
import org.springframework.stereotype.Component;
import java.io.*;
import java.math.BigInteger;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
@Component
public class WordUtils {
private final ObjectFactory factory;
public WordUtils() {
this.factory = Context.getWmlObjectFactory();
}
public void htmlToWord(String htmlContent, String outputPath) throws Exception {
// 创建Word文档包
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.createPackage();
// 设置XHTML导入器
XHTMLImporterImpl xhtmlImporter = new XHTMLImporterImpl(wordMLPackage);
// 导入HTML内容
wordMLPackage.getMainDocumentPart().getContent().addAll(
xhtmlImporter.convert(htmlContent, null));
// 保存文档
File file = new File(outputPath);
Docx4J.save(wordMLPackage, file, Docx4J.FLAG_NONE);
}
public static void main(String[] args) throws Exception {
// 读取文件内容(UTF-8编码,避免中文乱码)
byte[] bytes = Files.readAllBytes(Paths.get("D:\\myFile\\typora\\java-note\\数据库\\mysql\\1-MySQL 三万字精华总结.md"));
String html = MarkdownToHtmlUtils.convert(new String(bytes, StandardCharsets.UTF_8));
String fullHtml = "\n" +
"\n" +
"\n" +
" \n" +
" Markdown转换结果\n" +
"\n" +
"\n" +
html + "\n" +
"\n" +
"";
WordUtils wordUtils = new WordUtils();
String outPath = "C:\\Users\\Administrator\\Desktop\\tmp\\"+System.currentTimeMillis()+".docx";
System.out.println("outPath==>"+outPath);
wordUtils.htmlToWord(fullHtml,outPath);
}
}测试markdown
### 第一范式(1NF)列不可再分
1.每一列属性都是不可再分的属性值,确保每一列的原子性
2.两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据
### 第二范式(2NF)属性完全依赖于主键
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主键
### 第三范式(3NF)属性不依赖于其它非主属性 属性直接依赖于主键
数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号--> 所在院校 --> (院校地址,院校电话)
# MySQL 三万字精华总结 + 面试100 问,和面试官扯皮绰绰有余(收藏系列)
写在之前:不建议那种上来就是各种面试题罗列,然后背书式的去记忆,对技术的提升帮助很小,对正经面试也没什么帮助,有点东西的面试官深挖下就懵逼了。
个人建议把面试题看作是费曼学习法中的回顾、简化的环节,准备面试的时候,跟着题目先自己讲给自己听,看看自己会满意吗,不满意就继续学习这个点,如此反复,好的offer离你不远的,奥利给
写在之前:不建议那种上来就是各种面试题罗列,然后背书式的去记忆,对技术的提升帮助很小,对正经面试也没什么帮助,有点东西的面试官深挖下就懵逼了。个人建议把面试题看作是费曼学习法中的回顾、简化的环节,准备面试的时候,跟着题目先自己讲给自己听,看看自己会满意吗,不满意就继续学习这个点,如此反复,好的offer离你不远的,奥利给
## **一、MySQL架构**
和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,**插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离**。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
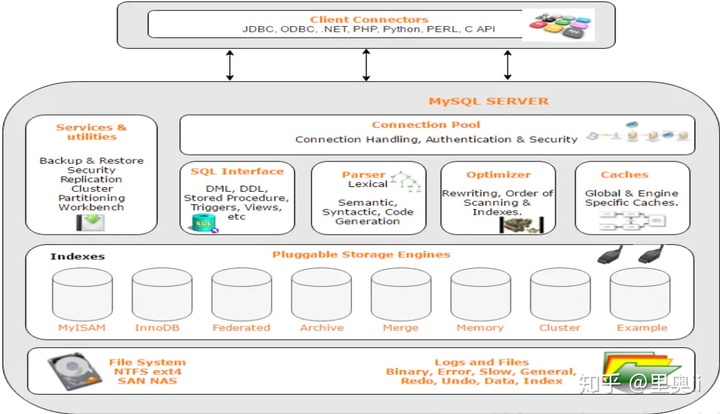
1. **连接层**:最上层是一些客户端和连接服务。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
1. **服务层**:第二层服务层,主要完成大部分的核心服务功能, 包括查询解析、分析、优化、缓存、以及所有的内置函数,所有跨存储引擎的功能也都在这一层实现,包括触发器、存储过程、视图等。
1. **引擎层**:第三层存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取
1. **存储层**:第四层为数据存储层,主要是将数据存储在运行于该设备的文件系统之上,并完成与存储引擎的交互。
画出 MySQL 架构图,这种变态问题都能问的出来 MySQL 的查询流程具体是?or 一条SQL语句在MySQL中如何执行的?
客户端请求 ---> 连接器(验证用户身份,给予权限) ---> 查询缓存(存在缓存则直接返回,不存在则执行后续操作) ---> 分析器(对SQL进行词法分析和语法分析操作) ---> 优化器(主要对执行的sql优化选择最优的执行方案方法) ---> 执行器(执行时会先看用户是否有执行权限,有才去使用这个引擎提供的接口) ---> 去引擎层获取数据返回(如果开启查询缓存则会缓存查询结果)

说说MySQL有哪些存储引擎?都有哪些区别?
 浙公网安备 33010602011771号
浙公网安备 33010602011771号