
2019大学排名
目的网站:http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html

import requests import bs4
requests用于得到目的网站源代码
bs4用于解析request得到的源码
r = requests.get('http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html')
r.encoding = 'utf-8'
soup = bs4.BeautifulSoup(r.text,"html.parser")
向目的网站发送请求,并将请求结果保存到对象 r ,将 r 的编码指定为utf-8,然后开始解析源码,解析结果保存到soup中
查看网页源代码,如图:

tbody 和 tbody 中的 td 即位所需要的标签
for i in soup.find('tbody').children:
#内容是否为标签,避免遇到空行符或其他
if isinstance(i,bs4.element.Tag):
#将结果根据td分开,存在td中
j= i('td')
#只需列表前三个值
t = [j[0].string,j[1].string,j[2].string]
if t[1]=='湖北师范大学':
print('----------------------------------------------------------------')
#打印结果,若找到湖北师范大学,用-----隔开
print(t)
if t[1]=='湖北师范大学':
print('----------------------------------------------------------------')
运行结果:
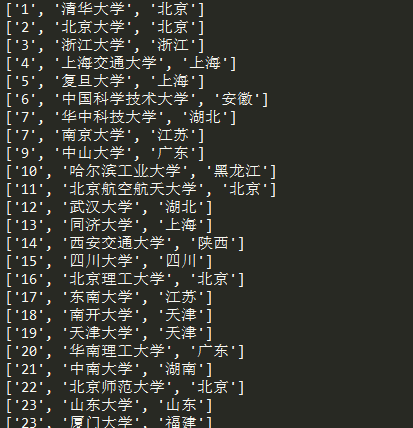
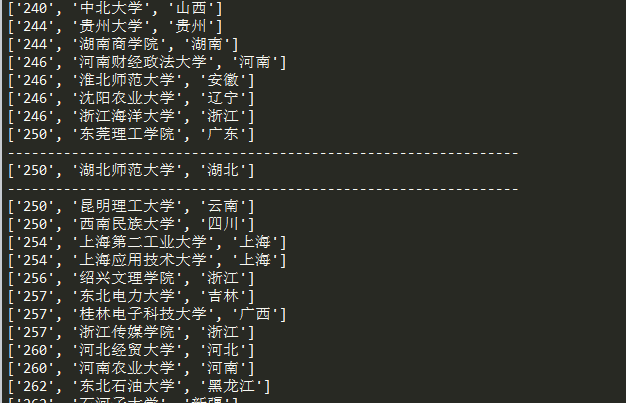
完整代码:
import requests
import bs4
r = requests.get('http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html')
r.encoding = 'utf-8'
soup = bs4.BeautifulSoup(r.text,"html.parser")
a = []
for i in soup.find('tbody').children:
#内容是否为标签,避免遇到空行符或其他
if isinstance(i,bs4.element.Tag):
#将结果根据td分开,存在td中
j= i('td')
#只需列表前三个值
t = [j[0].string,j[1].string,j[2].string]
if t[1]=='湖北师范大学':
print('----------------------------------------------------------------')
#打印结果,若找到湖北师范大学,用-----隔开
print(t)
if t[1]=='湖北师范大学':
print('----------------------------------------------------------------')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号