

80万商城运营大数据分析
80万商城运营大数据分析
- 用户行为分析:日访问量、小时访问量、不同行为类型访问量
- 获客分析
- 用户留存分析
- 复购分析
- 转化漏斗分析
- 商品竞争力分析:性别、城市、用户浏览、购买、收藏、商品类目分析
一:导入数据
# 导入常用的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import datetime
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# columns = ['user_id','goods_id','cat','behavior','time']
df = pd.read_table("E:/yizhiamumu/behavior.txt")
df.info()
打印结果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 757565 entries, 0 to 757564
Data columns (total 10 columns):
user_id 757565 non-null int64
goods_id 757565 non-null int64
cat 757565 non-null int64
behavior 757565 non-null object
time 757565 non-null int64
sex 757565 non-null int64
addr 757565 non-null object
device 757565 non-null object
price 757565 non-null float64
amount 757565 non-null int64
dtypes: float64(1), int64(6), object(3)
memory usage: 57.8+ MB
观察数据
df.head()
打印结果
user_id goods_id cat behavior time sex addr device price amount
0 1 5002615 2520377 pv 1574911385 0 成都 Redmi Note8Pro 0.0 0
1 1 2734026 4145813 pv 1574914184 0 成都 Redmi Note8Pro 0.0 0
2 1 5002615 2520377 pv 1574916273 0 成都 Redmi Note8Pro 0.0 0
3 1 3239041 2355072 pv 1574927664 0 成都 Redmi Note8Pro 0.0 0
4 1 4615417 4145813 pv 1574942864 0 成都 Redmi Note8Pro 0.0 0
二:数据清洗
# 数据清廷
df.drop_duplicates(inplace=True)
# 时间戳处理
df['time1'] = df['time'].apply(lambda x:datetime.datetime.fromtimestamp(x))
df['month'] = df['time'].apply(lambda x:int(datetime.datetime.fromtimestamp(x).strftime("%Y%m")))
df['date'] = df['time'].apply(lambda x:datetime.datetime.fromtimestamp(x).strftime("%Y%m%d"))
df['hour'] = df['time1'].apply(lambda x:x.hour)
# 销售金额计算
df['money'] = df['price'] * df['amount']
# 缺失值处理
df.isnull().sum()
df.describe()
打印结果
user_id goods_id cat time sex price amount month hour money
count 757565.000000 7.575650e+05 7.575650e+05 7.575650e+05 757565.000000 757565.000000 757565.000000 757565.000000 757565.000000 757565.000000
mean 5583.487645 2.582329e+06 2.716578e+06 1.575162e+09 0.432664 0.955333 0.047983 201911.560921 14.953452 2.383729
std 3184.742636 1.487073e+06 1.465113e+06 1.494278e+05 0.495445 7.915329 0.376215 0.496275 6.063847 21.677706
min 1.000000 2.900000e+01 2.171000e+03 1.574870e+09 0.000000 0.000000 0.000000 201911.000000 0.000000 0.000000
25% 2824.000000 1.304276e+06 1.354236e+06 1.575031e+09 0.000000 0.000000 0.000000 201911.000000 11.000000 0.000000
50% 5671.000000 2.582878e+06 2.735466e+06 1.575181e+09 0.000000 0.000000 0.000000 201912.000000 16.000000 0.000000
75% 8310.000000 3.861863e+06 4.145813e+06 1.575291e+09 1.000000 0.000000 0.000000 201912.000000 20.000000 0.000000
max 11079.000000 5.163006e+06 5.161669e+06 1.575389e+09 1.000000 99.900000 4.000000 201912.000000 23.000000 399.600000
三:数据可视化
1 每天PV UV 走势分析
# 数据可视化
# 1 每天PV UV 走势分析
all_puv = pd.pivot_table(df, index=['date'],values='user_id',aggfunc='count')
uv = df[['user_id','date']].drop_duplicates()['date'].value_counts()
all_puv = all_puv.join(uv)
all_puv.columns = ['pv','uv']
all_puv['avg_pv'] = all_puv['pv']/all_puv['uv']
all_puv
打印结果
pv uv avg_pv
date
20191128 106877 7610 14.044284
20191129 111426 7811 14.265267
20191130 114328 7874 14.519685
20191201 121457 8097 15.000247
20191202 153545 10552 14.551270
20191203 149932 10530 14.238557
x=all_puv.index
fig,axes = plt.subplots(1,3,figsize=(18,3))
axes[0].plot(x,all_puv['pv'], color='r', marker='o')
axes[1].plot(x,all_puv['uv'], color='g', marker='s')
axes[2].plot(x,all_puv['avg_pv'], color='b', marker='d')
axes[0].set_title('pv')
axes[1].set_title('uv')
axes[2].set_title('avg_pv')
plt.show()
打印结果 
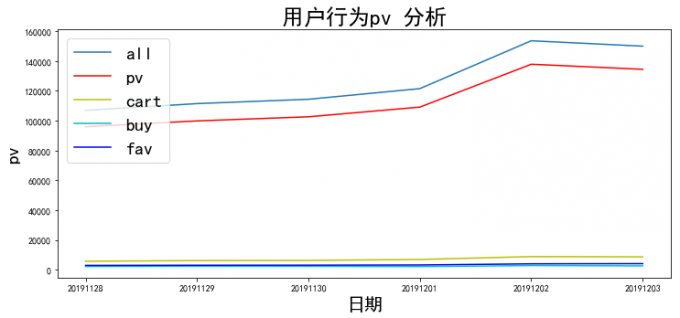
2 用户行为 pv 分析
# 2 用户行为 pv 分析
pv = pd.pivot_table(df, index=['date'], columns=['behavior'], values='user_id', aggfunc='count')
pv['all'] = pv.sum(axis=1)
plt.figure(figsize=(12,5))
plt.plot(pv.index, pv['all'])
plt.plot(pv.index, pv['pv'],color='r')
plt.plot(pv.index, pv['cart'],color='y')
plt.plot(pv.index, pv['buy'], color='c')
plt.plot(pv.index, pv['fav'], color='b')
plt.xlabel("日期", fontsize=20)
plt.ylabel('pv', fontsize=20)
plt.title("用户行为pv 分析", fontsize=24)
plt.legend(["all","pv","cart","buy","fav"], loc = 'upper left', fontsize=20)
plt.show()
打印结果
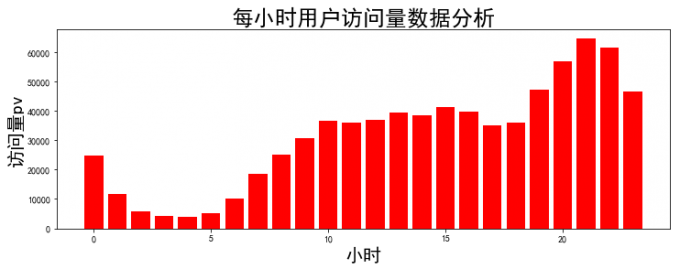
3 访问高峰分析
# 3 访问高峰分析
hour_pv = df['hour'].value_counts().reset_index().rename(columns={'index':'hour', 'hour':'pv'})
plt.figure(figsize=(12,4))
plt.bar(hour_pv['hour'], hour_pv['pv'],color='r')
plt.xlabel("小时", fontsize=20)
plt.ylabel("访问量pv", fontsize=20)
plt.title("每小时用户访问量数据分析", fontsize = 24)
plt.show()
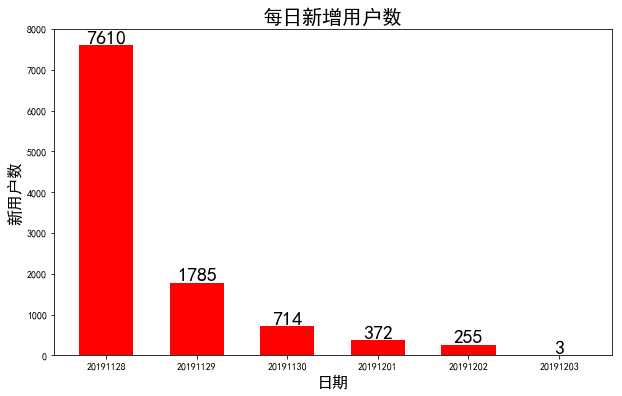
4 新用户分析
# 4 新用户分析
new_user= df[['user_id','date']].groupby('user_id').min()['date'].value_counts().reset_index()
new_user.columns = ['date', 'new_user']
plt.figure(figsize=(10,6))
x,y = new_user['date'], new_user['new_user']
plt.bar(x,y,width=0.6,color='r')
for a, b in zip(x,y):
plt.text(a,b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=20)
plt.xlabel("日期", fontsize=16)
plt.ylabel("新用户数", fontsize=16)
plt.title("每日新增用户数", fontsize=20)
plt.show()
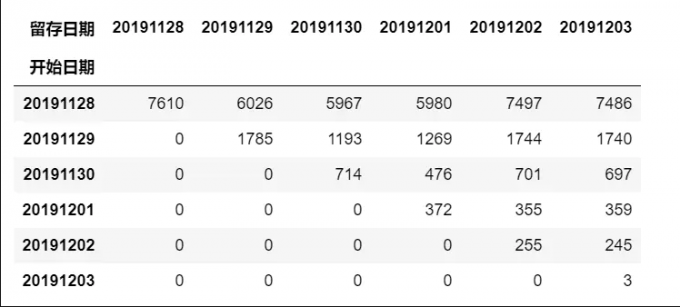
5 用户留存分析
# 5 用户留存分析
# 建立 n 日留存率计算模型,数据传入用户id 和登录日期
# n 为n 日留存, 不传入start_date 和 n 时,则计算所有留存
def cal_retention(df, start_date='20190101',n=0):
if n>0:
new_user = df[['user_id','date']].groupby('user_id').min().reset_index()
date2 = datetime.datetime.strptime(start_date, '%Y%m%d')+datetime.timedelta(n)
end_date = datetime.datetime.strftime(date2,'%Y%m%d')
start_user = set(new_user[new_user.date==start_date].user_id)
end_user = set(df[df.date==end_date].user_id)
user = start_user&end_user
return [start_date, end_date, len(start_user),len(user),round(len(user)/len(start_user),4)]
else:
new_user = df[['user_id',"date"]].groupby('user_id').min().reset_index()
date_source = new_user.date.unique()
date_source.sort()
result1 = []
flag =0
for start_date in date_source:
start_user = set(new_user[new_user.date == start_date].user_id)
for end_date in date_source[flag:]:
end_user = set(df[df.date==end_date].user_id)
user = start_user&end_user
result1.append([start_date,end_date,len(start_user),len(user),round(len(user)/len(start_user),4)])
flag = flag+1
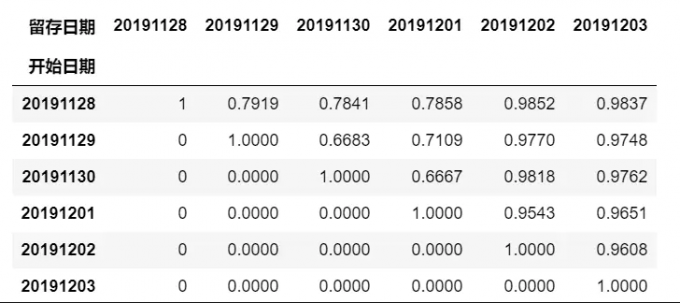
return pd.DataFrame(result1, columns=['开始日期','留存日期','新用户数','留存人数','留存率'])
# 调用cal_retention 函数计算留存
# cal_retention(df[['user_id','date']],'20191128',3)
retention = cal_retention(df[['user_id','date']])
# 留存人数展示
pd.pivot_table(retention, index=['开始日期'],columns=['留存日期'],values='留存人数',aggfunc='sum',fill_value=0)
# 留存率展示
pd.pivot_table(retention, index=['开始日期'],columns=['留存日期'],values='留存率',aggfunc='sum',fill_value=0)
6 复购率计算
# 6 复购率计算
data_buy = df[df.behavior=='buy'][['user_id','date']].drop_duplicates()['user_id'].value_counts().reset_index()
data_buy.columns = ['user_id','num']
re_buy_rate = round(len(data_buy[data_buy.num>=2])/len(data_buy),4)
print("复购率为:",round(re_buy_rate*100,2),"%")
# 购买总人数
buy_user = len(data_buy)
# 网联次数的人数分布
buy_freq = data_buy.num.value_counts().reset_index()
buy_freq.columns = [['购买次数','人数']]
buy_freq['人数占比'] = round(buy_freq['人数']/buy_user,4)
buy_freq
打印结果
复购率为: 42.06 %
购买次数 人数 人数占比
0 1 3540 0.5794
1 2 1714 0.2805
2 3 575 0.0941
3 4 210 0.0344
4 5 57 0.0093
5 6 14 0.0023
7 商品TOP 分析
7.1 商品销售TOP
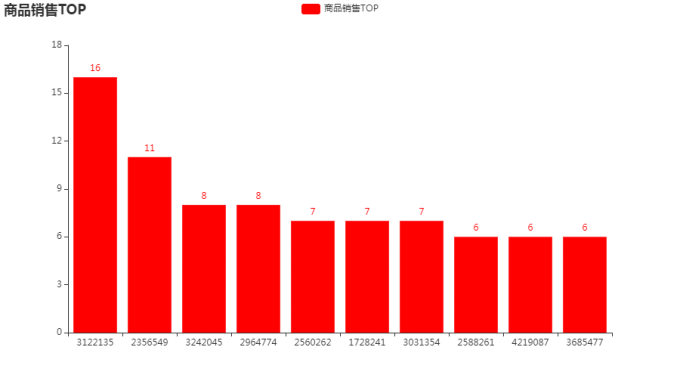
# 7.1 商品销售TOP
buy_top = df[df.behavior=='buy']['goods_id'].value_counts().head(10)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(buy_top.index.tolist())
bar.add_yaxis("商品销售TOP",buy_top.values.tolist(),color='red')
bar.set_global_opts(title_opts=opts.TitleOpts(title="商品销售TOP"))
bar.render_notebook()
7.2商品浏览TOP
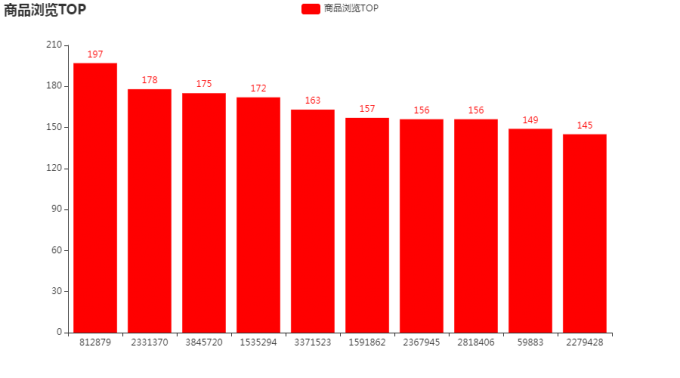
# 7.2商品浏览TOP
pv_top = df[df.behavior=='pv']['goods_id'].value_counts().head(10)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(pv_top.index.tolist())
bar.add_yaxis("商品浏览TOP",pv_top.values.tolist(),color='red')
bar.set_global_opts(title_opts=opts.TitleOpts(title="商品浏览TOP"))
bar.render_notebook()
7.3商品收藏 TOP
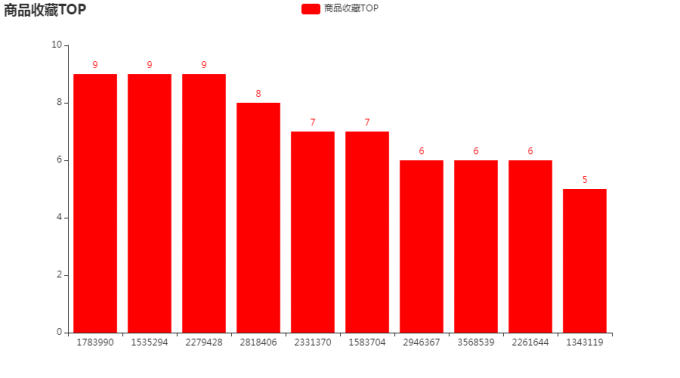
# 7.3商品收藏 TOP
fav_top = df[df.behavior=='fav']['goods_id'].value_counts().head(10)
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(fav_top.index.tolist())
bar.add_yaxis("商品收藏TOP",fav_top.values.tolist(),color='red')
bar.set_global_opts(title_opts=opts.TitleOpts(title="商品收藏TOP"))
bar.render_notebook()
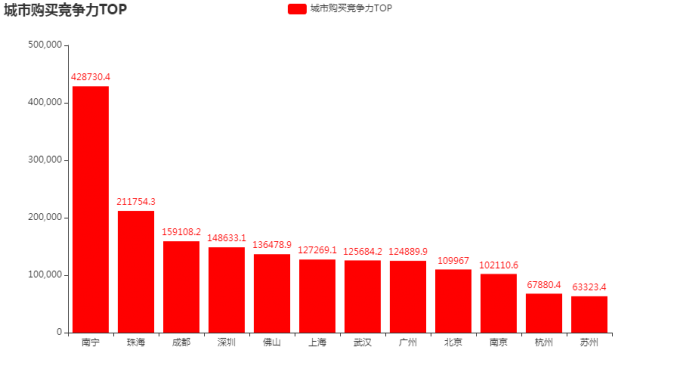
8 城市购买竞争力TOP
# 8 城市购买竞争力TOP
city_top = df[df.behavior=='buy'][['addr','money']].groupby('addr').sum().sort_values('money',ascending=False)
bar = Bar()
bar.add_xaxis(city_top.index.tolist())
bar.add_yaxis("城市购买竞争力TOP",[round(a,2) for a in city_top.money], color='red')
bar.set_global_opts(title_opts=opts.TitleOpts(title="城市购买竞争力TOP"))
bar.render_notebook()
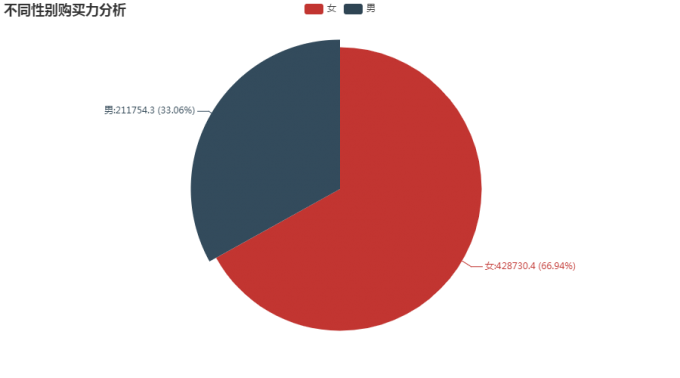
9 不同性别购买力分析
# 9 不同性别购买力情况 0-女,1-男
sex_top = df[df.behavior=='buy'][['sex','money']].groupby('sex').sum()
from pyecharts.charts import Pie
pie = Pie()
pie.add("",[list(z) for z in zip(['女','男'], [round(a,2) for a in city_top.money])])
pie.set_global_opts(title_opts=opts.TitleOpts(title="不同性别购买力分析"))
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c} ({d}%)"))
pie.render_notebook()
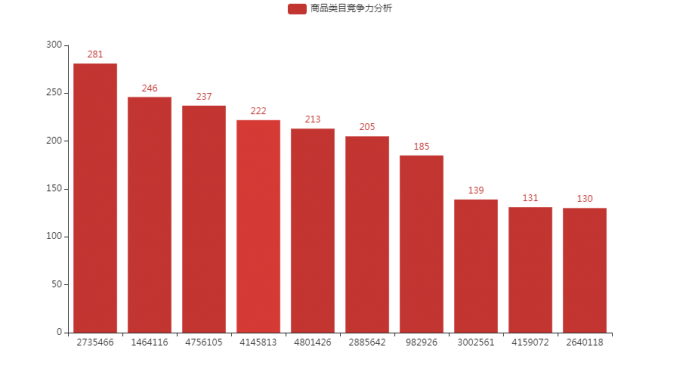
10商品类目竞争力分析
# 10商品类目竞争力分析
cat_top = df[df.behavior=='buy']['cat'].value_counts().head(10)
bar = Bar()
bar.add_xaxis(cat_top.index.tolist())
bar.add_yaxis("商品类目竞争力分析",cat_top.values.tolist())
bar.render_notebook()
11 总体转化漏斗分析
# 11 总体转化漏斗分析
from pyecharts.charts import Funnel
from pyecharts import options as opts
data_behavior = df[df.behavior!="fav"]['behavior'].value_counts().reset_index().rename(columns={"index":"环节","behavior":"人数"})
# 单一环节的转化率
t1 = np.array(data_behavior['人数'][1:])
t2 = np.array(data_behavior['人数'][0:-1])
single_convs = t1/t2
single_convs = list(single_convs)
single_convs.insert(0,1)
# 总体转化率
flag = data_behavior['人数'][0]
data_behavior['总体转化率'] = data_behavior['人数']/flag
attrs = [a+": "+str(round(b,2))+"%" for a,b in zip(data_behavior['环节'],data_behavior['总体转化率']*100)]
attr_value = [round(a,2) for a in data_behavior['总体转化率'] * 100]
funnel = Funnel()
funnel.add("商品",[list(z) for z in zip(attrs, attr_value)], label_opts = opts.LabelOpts(position="inside"))
funnel.set_global_opts(title_opts=opts.TitleOpts(title="总体转化漏斗数据分析"))
funnel.render_notebook()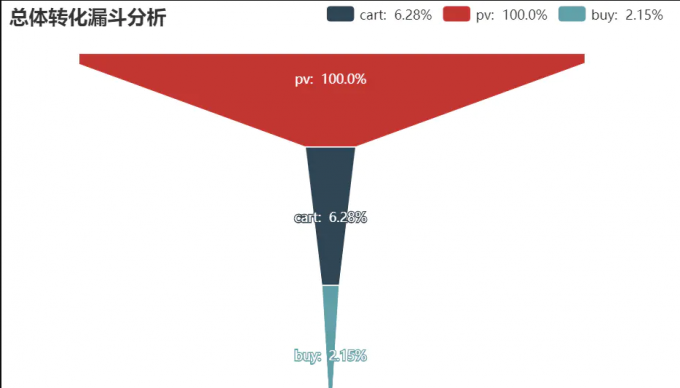
12 RFM 用户分层模型
# RFM 模型打分规则
def recency(x):
if x<=2:
return 5
elif x==3:
return 4
elif x==4:
return 3
elif x==5:
return 2
elif x>=6:
return 1
def frequency(x):
if x>=8:
return 5
elif (x>=6)&(x<8):
return 4
elif (x>=4)&(x<6):
return 3
elif (x>=2)&(x<4):
return 2
elif (x>=0)&(x<2):
return 1
def monetary(x):
if x>=300:
return 5
elif (x>=200)&(x<300):
return 4
elif (x>100)&(x<200):
return 3
elif (x>50)&(x<100):
return 2
elif (x>=0)&(x<50):
return 1
# RFM 用户分层
RFM_date = df[df.behavior == 'buy'][['user_id','date']].groupby("user_id").max()
RFM_F = df[df.behavior == 'buy'][['user_id','behavior']].groupby('user_id').count()
RFM_M = df[df.behavior == 'buy'][['user_id','money']].groupby('user_id').mean()
RFM = RFM_date.join(RFM_F).join(RFM_M)
# 用户价值分层
end_date = datetime.datetime.strptime('20191205',"%Y%m%d")
# 时间间隔天数计算
RFM['days'] = RFM['date'].apply(lambda x:(end_date-datetime.datetime.strptime(x,"%Y%m%d")).days)
RFM = RFM[['days','behavior','money']]
RFM.columns = ['间隔天数','消费频次','消费金额']
RFM.head()
打印结果:
间隔天数 消费频次 消费金额
user_id
2 3 7 186.742857
4 5 4 142.600000
16 4 2 84.650000
17 4 1 62.700000
20 4 1 37.900000
RFM数据建模:
# RFM 数据处理
RFM['R_S'] = RFM['间隔天数'].apply(recency)
RFM['F_S'] = RFM['消费频次'].apply(frequency)
RFM['M_S'] = RFM['消费金额'].apply(monetary)
RFM['RFM'] = RFM.apply(lambda x:int(x.R_S * 100 + x.F_S * 10 + x.M_S),axis=1)
RFM.head()
打印结果
间隔天数 消费频次 消费金额 R_S F_S M_S RFM
user_id
2 3 7 186.742857 4 4 3.0 443
4 5 4 142.600000 2 3 3.0 233
16 4 2 84.650000 3 2 2.0 322
17 4 1 62.700000 3 1 2.0 312
20 4 1 37.900000 3 1 1.0 311
欢迎关注:一只阿木木

 浙公网安备 33010602011771号
浙公网安备 33010602011771号