

NumPy的一种主要数据类型是N维数组(ndarray,简称数组)。N维数组是 SciPy 中很多高级数据处理技术的基础。
为什么要使用NumPy数组
在 Python 中表格数据的一种表示方法是使用列表的列表。
gene0 = [100, 200]
gene1 = [50, 0]
gene2 = [350, 100]
expression_data = [gene0, gene1, gene2]
在以上代码中,每种基因在不同细胞类型上的表达被保存在一个 Python 整型列表中。然后将这些列表保存在一个列表(可以称其为元列表,meta-list)中。可以用两级列表索引提取出单个数据点。
expression_data[2][0]
350
这样保存多维数组是效率非常低的一种方法:
1.上面的 gene2 列表不是整数列表,而是一个指向整数的指针列表,会占用更多的内存。
2.列表和整数被随机地保存在计算机 RAM 中完全不同的区域。但是现代处理器更喜欢按块读取内存中的内容,因此,将数据分散保存在 RAM 中是非常低效的。
这些正是 NumPy 数组要解决的问题。
3.N维数组比Python列表处理速度要快得多,这是因为NumPy内置向量化操作。存储上列表中的每个元素都是一个对象,占用对应的内存;而N维数组每个元素只占用必要内存,空间远小于列表。同时N维数组可以使用切片操作在不复制基础数据的情况下取数组的子集。
NumPy数组的相关操作
shape方法
import numpy as np
array1 = np.array([1, 2, 3, 4])
print(array1)
print(type(array1))
[1 2 3 4]
<class 'numpy.ndarray'>
以上代码说明一维数组与Python列表极为相似,而NumPy数组的类型是 “numpy.ndarray”。
我们可以使用print(array1.shape)来得到N维数组的形状,即“(4,)”。
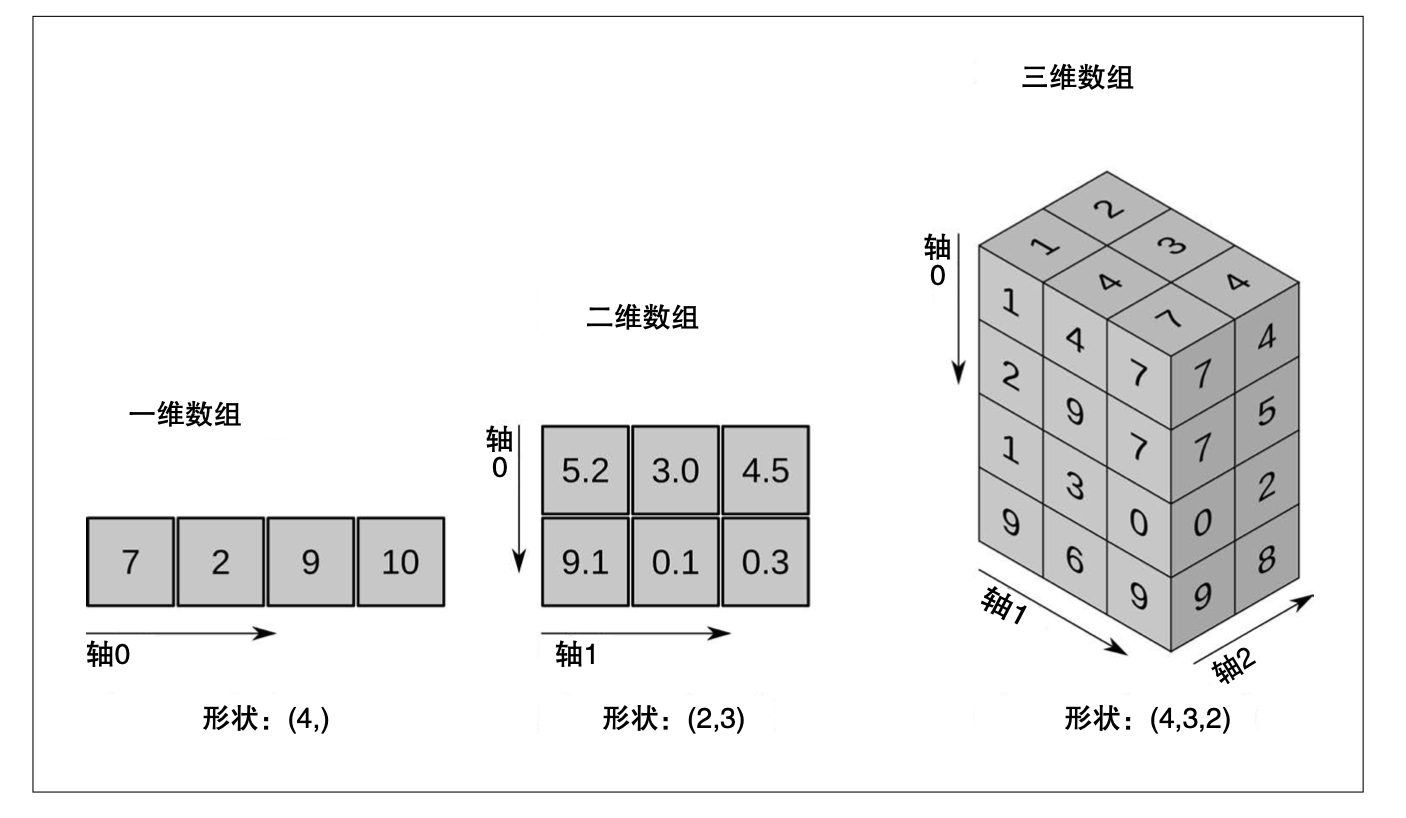
向量化
向量化无须使用 for 循环就可以对数组中的每个元素进行计算。既能提高数组操作的速度, 还可以使代码更简单。
e.g.
x = np.array([1, 2, 3, 5])
print(x * 2)
[2 4 6 10]
y = np.array([0, 1, 2, 1])
print(x + y)
[1 3 5 11]
广播
广播是在两个数组间执行隐式操作的一种方法,允许在形状兼容的两个数组间执行操作,如重塑两个向量,可以计算出它们的外积。
e.g.
x = np.array([1, 2, 3, 4])
x = np.reshape(x, (len(x), 1))
print(x)
[[1]
[2]
[3]
[4]]
这里使用了reshape方法来重塑数组。
y = np.array([0, 1, 2, 1])
outer = x * y
print(outer)
[[0 1 2 1]
[0 2 4 2]
[0 3 6 3]
[0 4 8 4]]
两个数组都有两个维度,而且内侧维度都等于 1,因此这两个数组的形状是兼容的,可以得到一个4*4的数组。】
pandas读取数据
pandas 是一个专门用于数据处理和分析的库。
我们将用它读取混合类型的表格数据。pandas 使用的是 DataFrame 类型,这是一种非常灵活的表格形式,基于 R 语言中的数据框对象开发而成。
因此可以读取一列数据为字符串,多列整数的混合类型列表。
e.g.
import numpy as np
import pandas as pd
# 导入TCGA黑色素瘤数据
filename = 'data/counts.txt'
with open(filename, 'rt') as f:
data_table = pd.read_csv(f, index_col=0) # 用pandas解析文件 print(data_table.iloc[:5, :5])

pandas 专门提取出了标题行,并用它对各列进行了命名。第一列给出了每种 基因的名称,其余各列表示独立的样本。
如果想要详细学习 pandas,可以阅读 pandas 创建者 Wes McKinney 的著作《利用 Python 进行数据分析》。
科学计算
NumPy 和 SciPy 共同组成了 Python 科学应用生态系统的核心。SciPy 软件库实现了很多用
于科学数据处理的函数,比如用于统计学、信号处理、图像处理和函数优化。SciPy 是建立在 NumPy 之上的,NumPy 是 Python 中用于数值型数组计算的库。
在过去的几年中,基于 NumPy 和 SciPy,一个包括应用和库文件的完整生态系统迅速发展起来,
并在天文学、 生物学、气象学和气候科学,以及材料科学等多个学科得到了广泛应用。
NumPy 是 Python 科学计算的基础。它提供了高效的数值数组,并广泛支持数值计算, 其中包括线性代数、随机数和傅里叶变换。
- NumPy 的杀手级特性是“N 维数组”,又称 ndarray。这些数据结构可以高效地存储数值型数据,并能定义任何维度的网格。
- SciPy 库是一个高效的数值算法集合,用于信号处理、集成、优化和统计学等领域。其 中的程序都使用了用户友好型界面进行包装。
-
Matplotlib 是一个功能强大的二维(和基本的三维)绘图包。它的名称来自于受 Matlab 启发而发明的语法。
-
IPython 是一个交互式的 Python 界面,它允许你快速地与数据和测试方案交互。
-
Jupyter 笔记本在浏览器中运行,可以构建样式丰富的文档,将代码、文本、数学表达 式和可交互部件组合在一起。2 实际上,为了生成本书,需要将文本转换为 Jupyter 笔记 本并运行(这样我们就可以知道所有示例都能够正确运行)。Jupyter 最初是作为 IPython
的扩展而开发的,但现在可以支持多种语言,其中包括 Cython、Julia、R、Octave、
Bash、Perl 和 Ruby。
-
pandas 通过一个便于使用的软件包提供了快速、列式的数据结构。它特别适合处理有
标记的数据集,如表格和关系数据库,还适合管理时间序列数据和滑动窗口。pandas 中
还有很多便利的数据分析工具,可以解析、清洗、聚合和绘制数据。
-
scikit-learn 为机器学习算法提供了统一的接口。
-
scikit-image 提供了能与 SciPy 生态系统其他部分完美集成的图像分析工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号