

redis 的高并发的理解
redis 的特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
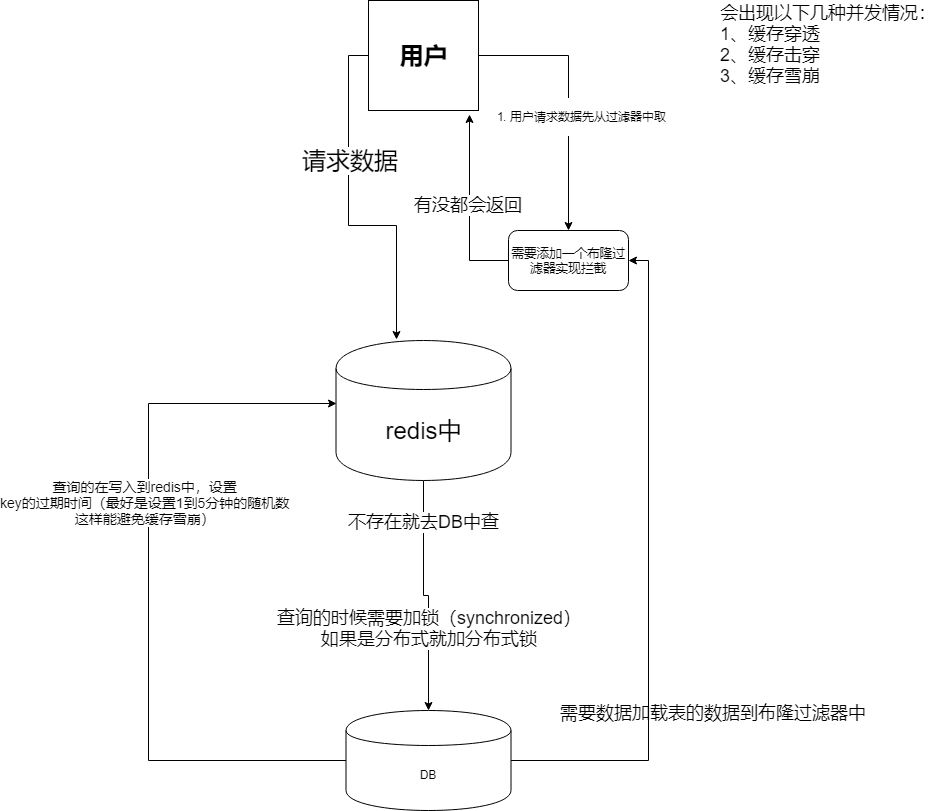
redis 在并发下出现的情况:
缓存穿透:
用户发送数据(一条数据库中存在、redis中不存在的) 到redis中没有就去DB中查,如果DB中没有查询到,就返回给用户;若黑客使用这个漏洞 进行对数据库的攻击就会给数据库击垮。
解决的办法:
1、添加过期时间
2、添加一个布隆过滤器
布隆过滤器( 加载120万的数据需要 9秒,)是数据哈希到一个足够大额 bigMap 中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力,但是布隆过滤器有个一误判率是大约是3%。
DB查询到数据为空的时候, 把数据写入到redis中 key对应的value就是空值, 并设置key 的过期时间,设置过期时间最好使用1-5的随机数,
缓存击穿:
用户发送请数据到redis中 发现redis的数据过期了。这个时候就会去查询数据库, 如果有大量的并发请求,发现有大量的数据在redis中过期了。这个时候就会给DB造成巨大的压力。
解决的方法:
1、设置redis中的key 为过期时间为随机数最大不超过5,
2、 在访问DB的时候加上锁, 如果是分布式就使用分布式锁。 使用互斥锁 (setNx )
缓存雪崩:
当redis中数据在某一个时间段存在大量的过期时间,就会去请求DB 这样会给数据库带来巨大的压力或者是击垮数据库。
解决方法:
在访问数据库的时候加锁
设置队列关系
缓存预热:
就系统上线的时候需要把数据库中的数据缓存到redis中,这个样就可以避免用户在查询的数据时候在从数据库中查了。
解决的方法:
1,系统上线后 实现都写好的执行缓存的刷新的页面进行操作。2,也可以手动的更新,3、定时刷新缓存
如果缓存的数据不多的话 设置项目启动就可以启动缓存更新。
缓存更新:
Redis默认的有6中策略可供选择
比较常用有两种方案:
1、定时去清理过期的缓存,
2、 用户请求过来的时候,发现缓存中的数据过期了,在去数据库查在去根性·更新redis。
缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低
redis 的命令 使用 :
与String相关的常用命令:
-
SET:为一个key设置value,可以配合EX/PX参数指定key的有效期,通过NX/XX参数针对key是否存在的情况进行区别操作,时间复杂度O(1)
-
GET:获取某个key对应的value,时间复杂度O(1)
-
GETSET:为一个key设置value,并返回该key的原value,时间复杂度O(1)
-
MSET:为多个key设置value,时间复杂度O(N)
-
MSETNX:同MSET,如果指定的key中有任意一个已存在,则不进行任何操作,时间复杂度O(N)
-
MGET:获取多个key对应的value,时间复杂度O(N)
与List相关的常用命令:
-
LPUSH:向指定List的左侧(即头部)插入1个或多个元素,返回插入后的List长度。时间复杂度O(N),N为插入元素的数量
-
RPUSH:同LPUSH,向指定List的右侧(即尾部)插入1或多个元素
-
LPOP:从指定List的左侧(即头部)移除一个元素并返回,时间复杂度O(1)
-
RPOP:同LPOP,从指定List的右侧(即尾部)移除1个元素并返回
-
LPUSHX/RPUSHX:与LPUSH/RPUSH类似,区别在于,LPUSHX/RPUSHX操作的key如果不存在,则不会进行任何操作
-
LLEN:返回指定List的长度,时间复杂度O(1)
-
LRANGE:返回指定List中指定范围的元素(双端包含,即LRANGE key 0 10会返回11个元素),时间复杂度O(N)。应尽可能控制一次获取的元素数量,一次获取过大范围的List元素会导致延迟,同时对长度不可预知的List,避免使用LRANGE key 0 -1这样的完整遍历操作。
应谨慎使用的List相关命令:
-
LINDEX:返回指定List指定index上的元素,如果index越界,返回nil。index数值是回环的,即-1代表List最后一个位置,-2代表List倒数第二个位置。时间复杂度O(N)
-
LSET:将指定List指定index上的元素设置为value,如果index越界则返回错误,时间复杂度O(N),如果操作的是头/尾部的元素,则时间复杂度为O(1)
-
LINSERT:向指定List中指定元素之前/之后插入一个新元素,并返回操作后的List长度。如果指定的元素不存在,返回-1。如果指定key不存在,不会进行任何操作,时间复杂度O(N)
由于Redis的List是链表结构的,上述的三个命令的算法效率较低,需要对List进行遍历,命令的耗时无法预估,在List长度大的情况下耗时会明显增加,应谨慎使用。
与Hash相关的常用命令:
-
HSET:将key对应的Hash中的field设置为value。如果该Hash不存在,会自动创建一个。时间复杂度O(1)
-
HGET:返回指定Hash中field字段的值,时间复杂度O(1)
-
HMSET/HMGET:同HSET和HGET,可以批量操作同一个key下的多个field,时间复杂度:O(N),N为一次操作的field数量
-
HSETNX:同HSET,但如field已经存在,HSETNX不会进行任何操作,时间复杂度O(1)
-
HEXISTS:判断指定Hash中field是否存在,存在返回1,不存在返回0,时间复杂度O(1)
-
HDEL:删除指定Hash中的field(1个或多个),时间复杂度:O(N),N为操作的field数量
-
HINCRBY:同INCRBY命令,对指定Hash中的一个field进行INCRBY,时间复杂度O(1)
应谨慎使用的Hash相关命令:
-
HGETALL:返回指定Hash中所有的field-value对。返回结果为数组,数组中field和value交替出现。时间复杂度O(N)
-
HKEYS/HVALS:返回指定Hash中所有的field/value,时间复杂度O(N)
上述三个命令都会对Hash进行完整遍历,Hash中的field数量与命令的耗时线性相关,对于尺寸不可预知的Hash,应严格避免使用上面三个命令,而改为使用HSCAN命令进行游标式的遍历,具体请见
https://redis.io/commands/scan
--
为什么redis是单线程模型也能效率也很高?
1 纯内存操作
2 核心是基于非阻塞的 io 多路复用机制
3 单线程 反而避免了多线程上下文切换的问题。
redis分布式锁:
设置分布式锁 set my:lock 随机值 NX PX 30000
(my 可以用 用户id或者是订单id等,随机值不能重复。NX:存在设置失败,反之就成功,px 设置过期时间)
释放锁。 就是删除key 是根据随机值, 是根据redis中的随机值和key对应的随机值一致就删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号