

中文分词演示
主要功能
Jieba分词器:
分词核心:定义了 segment函数,根据用户选择的模式调用不同的分词引擎:
精确模式:使用 jieba.lcut,力求最准确地将文本切分,适合文本分析。
全模式:使用 jieba.lcut(text, cut_all=True),扫描文本中所有可能成词的情况,速度快但可能存在冗余。
搜索引擎模式:使用 jieba.lcut_for_search,在精确模式基础上对长词再次切分,提高召回率,适用于搜索引擎场景。
THULAC分词器:
THULAC模式:调用 thu1.cut(text, text=True),使用清华大学开发的 THULAC 工具进行分词和词性标注(结果会显示词性)。
| 分词器名称 | 主要语言支持 | 核心特点 | 适用场景 |
|---|---|---|---|
| Jieba | 中文 | 支持精确、全、搜索引擎三种分词模式;可自定义词典;新词识别能力强 | 中文文本分析、搜索引擎索引 |
| NLTK | 英文 | 功能全面,提供分词、词性标注、命名实体识别等丰富工具 | 学术研究、教学、英文文本处理 |
| spaCy | 多语言(英文为主) | 工业化强度高,处理速度快;提供词性标注、依存句法分析等一体化管道 | 大规模英文文本处理、生产环境 |
| THULAC | 中文 | 由清华大学开发,分词准确性高,同时支持词性标注 | 对中文分词准确率要求高的专业文本处理 |
| HanLP | 多语言(中文为主) | 功能丰富,集成分词、词性标注、命名实体识别、依存句法分析等多种功能 | 需要综合NLP功能的复杂中文处理任务 |
| FoolNLTK | 中文 | 基于深度学习,分词准确率较高 | 对中文分词准确度有严苛要求的场景 |
| PKUSEG | 中文 | 由北京大学开发,支持多领域分词模型 | 特定领域(如新闻、医药)的中文分词 |
词性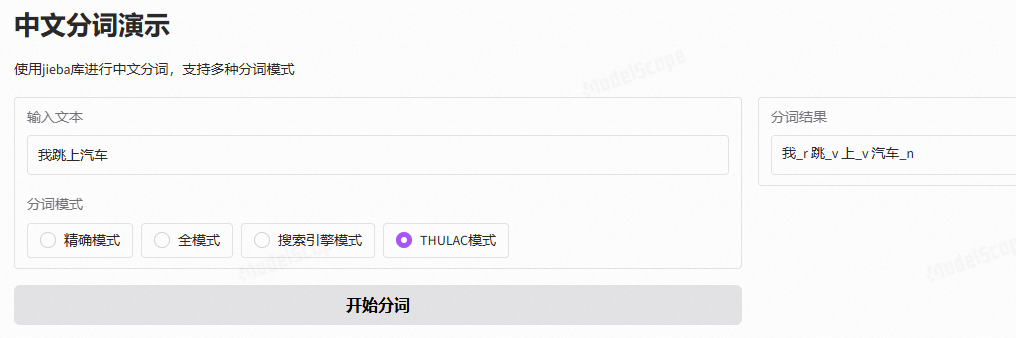
清华大学开发的 THULAC 工具,词性标注中的字母代码代表不同的词性类别,以下是完整的词性标注集及其含义:
主要词性类别
名词类:
n:名词
np:人名
ns:地名
ni:机构名
nz:其它专名
数词量词类:
m:数词
q:量词
mq:数量词
时间方位类:
t:时间词
f:方位词
s:处所词
动词形容词类:
v:动词
a:形容词
其他词类:
d:副词
h:前接成分
k:后接成分
i:习语
j:简称
r:代词
c:连词
p:介词
u:助词
y:语气助词
e:叹词
o:拟声词
g:语素
w:标点
x:其它
import gradio as gr import jieba import thulac # 初始化THULAC thu1 = thulac.thulac() # 定义分词函数 def segment(text, mode): if mode == "精确模式": seg_list = jieba.lcut(text) return "/ ".join(seg_list) elif mode == "全模式": seg_list = jieba.lcut(text, cut_all=True) return "/ ".join(seg_list) elif mode == "搜索引擎模式": seg_list = jieba.lcut_for_search(text) return "/ ".join(seg_list) elif mode == "THULAC模式": # 使用THULAC进行分词 thu_result = thu1.cut(text, text=True) return thu_result else: return "请选择有效的分词模式" # 创建Gradio界面 with gr.Blocks(title="中文分词演示") as demo: gr.Markdown("# 中文分词演示") gr.Markdown("使用jieba库进行中文分词,支持多种分词模式") with gr.Row(): with gr.Column(): input_text = gr.Textbox(label="输入文本", placeholder="请输入要分词的中文文本...") mode = gr.Radio(["精确模式", "全模式", "搜索引擎模式", "THULAC模式"], label="分词模式", value="精确模式") btn = gr.Button("开始分词") with gr.Column(): output_text = gr.Textbox(label="分词结果", interactive=False) # 示例 gr.Markdown("## 使用示例") gr.Examples( examples=[ ["今天天气真好", "精确模式"], ["今天天气真好", "全模式"], ["今天天气真好", "搜索引擎模式"], ["今天天气真好", "THULAC模式"], ["人工智能是人类发展的方向", "精确模式"], ["人工智能是人类发展的方向", "全模式"], ["人工智能是人类发展的方向", "搜索引擎模式"], ["人工智能是人类发展的方向", "THULAC模式"], ["自然语言处理技术很重要", "精确模式"], ["自然语言处理技术很重要", "全模式"], ["自然语言处理技术很重要", "搜索引擎模式"], ["自然语言处理技术很重要", "THULAC模式"] ], inputs=[input_text, mode], outputs=output_text, fn=segment, cache_examples=True ) btn.click(fn=segment, inputs=[input_text, mode], outputs=output_text) if __name__ == "__main__": demo.launch()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号