

四步构建最小可行系统(MVP)
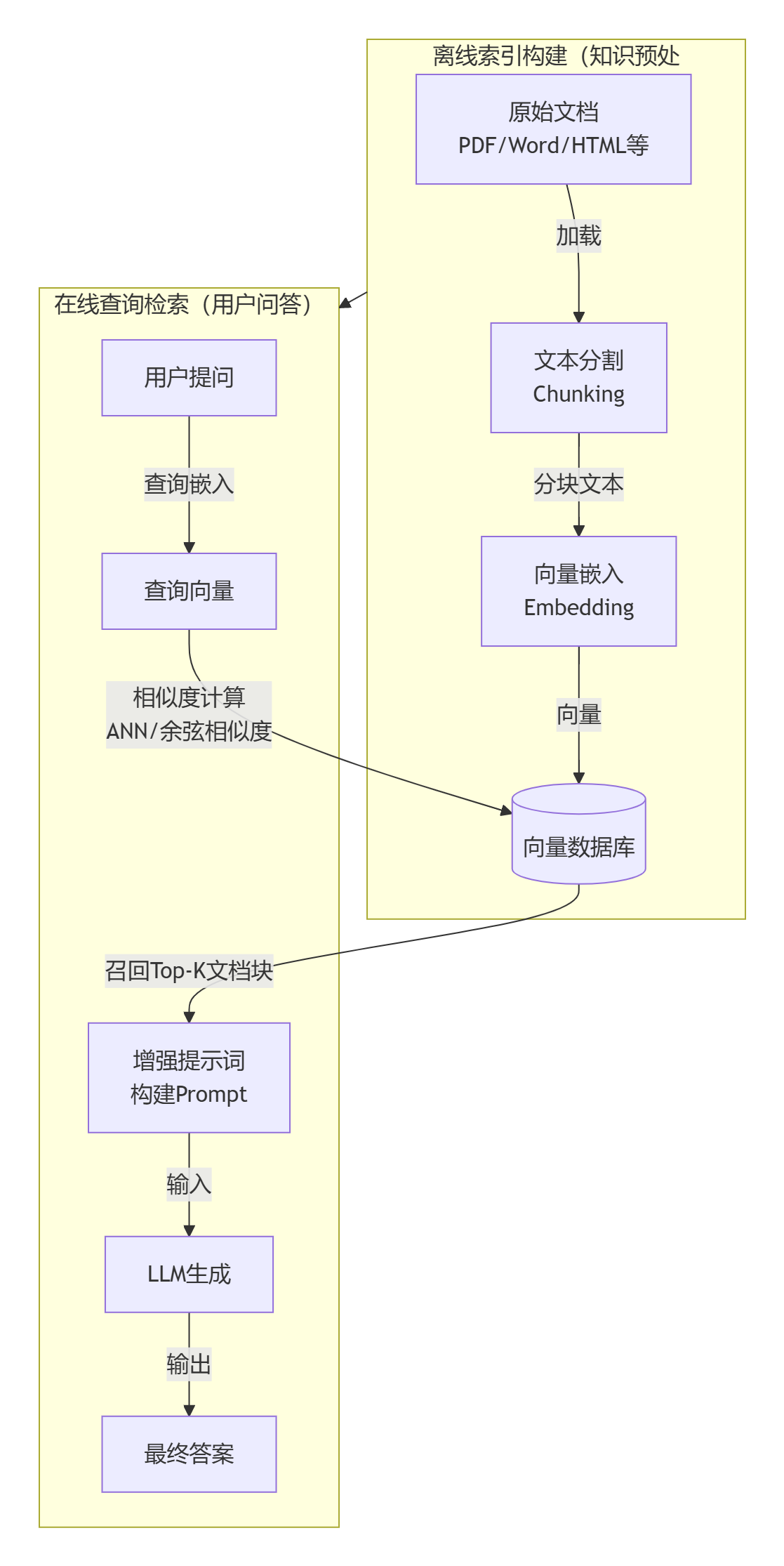
1,数据准备与清洗 这是系统的地基。我们需要将 PDF、Word 等多源异构数据标准化,并采用合理的分块策略(如按语义段落切分而非固定字符数),避免信息在切割中支离破碎。
2,索引构建 将切分好的文本通过嵌入模型转化为向量,并存入数据库。可以在此阶段关联元数据(如来源、页码),这对后续的精确引用很有帮助。
3,检索策略优化 不要依赖单一的向量搜索。可以采用混合检索(向量+关键词)等方式来提升召回率,并引入重排序模型对检索结果进行二次精选,确保 LLM 看到的都是精华。
4,生成与提示工程 最后,设计一套清晰的 Prompt 模板,引导 LLM 基于检索到的上下文回答用户问题,并明确要求模型“不知道就说不知道”,防止幻觉。
新手上手RAG 友好方案
如果你希望快速验证想法而非深耕代码,可以尝试 FastGPT 或 Dify 这样的可视化知识库平台,它们封装了复杂的 RAG 流程,仅需上传文档即可使用。对于开发者,利用 LangChain4j Easy RAG 或 GitHub 上的 TinyRAG 6等开源模板,也是高效的起手方式。
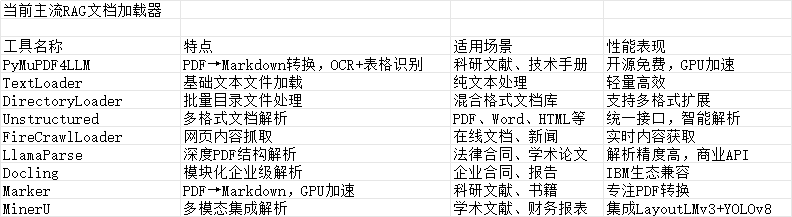
传统的数据库(如 MySQL)擅长处理结构化数据的精确匹配查询(例如,WHERE age = 25),但它们并非为处理高维向量的相似性搜索而设计的。
在庞大的向量集合中进行暴力、线性的相似度计算,其计算成本和时间延迟无法接受。
向量数据库 (Vector Database) 很好的解决了这一问题,它是一种专门设计用于高效存储、管理和查询高维向量的数据库系统。
在 RAG 流程中,它扮演着“知识库”的角色,是连接数据与大语言模型的关键桥梁。
向量数据库和传统数据库并非相互替代的关系,而是互补关系。在构建现代 AI 应用时,通常会将两者结合使用:利用传统数据库存储业务元数据和结构化信息,而向量数据库则专门负责处理和检索由 AI 模型产生的海量向量数据。
| 维度 | 向量数据库 | 传统数据库 (RDBMS) |
|---|---|---|
| 核心数据类型 | 高维向量 (Embeddings) | 结构化数据 (文本、数字、日期) |
| 查询方式 | 相似性搜索 (ANN) | 精确匹配 |
| 索引机制 | HNSW, IVF, LSH 等 ANN 索引 | B-Tree, Hash Index |
| 主要应用场景 | AI 应用、RAG、推荐系统、图像/语音识别 | 业务系统 (ERP, CRM)、金融交易、数据报表 |
| 数据规模 | 轻松应对千亿级向量 | 通常在千万到亿级行数据,更大规模需复杂分库分表 |
| 性能特点 | 高维数据检索性能极高,计算密集型 | 结构化数据查询快,高维数据查询性能呈指数级下降 |
| 一致性 | 通常为最终一致性 | 强一致性 (ACID 事务) |
Pinecone 是一款完全托管的向量数据库服务,采用Serverless架构设计。它提供存储计算分离、自动扩展和负载均衡等企业级特性,并保证99.95%的SLA。Pinecone支持多种语言SDK,提供极高可用性和低延迟搜索(<100ms),特别适合企业级生产环境、高并发场景和大规模部署。
Milvus 是一款开源的分布式向量数据库,采用分布式架构设计,支持GPU加速和多种索引算法。它能够处理亿级向量检索,提供高性能GPU加速和完善的生态系统。Milvus特别适合大规模部署、高性能要求的场景,以及需要自定义开发的开源项目。
Qdrant 是一款高性能的开源向量数据库,采用Rust开发,支持二进制量化技术。它提供多种索引策略和向量混合搜索功能,能够实现极高的性能(RPS>4000)和低延迟搜索。Qdrant特别适合性能敏感应用、高并发场景以及中小规模部署。
Weaviate 是一款支持GraphQL的AI集成向量数据库,提供20+AI模块和多模态支持。它采用GraphQL API设计,支持RAG优化,特别适合AI开发、多模态处理和快速开发场景。Weaviate具有活跃的社区支持和易于集成的特点。
Chroma 是一款轻量级的开源向量数据库,采用本地优先设计,无依赖。它提供零配置安装、本地运行和低资源消耗等特性,特别适合原型开发、教育培训和小规模应用。Chroma的部署简单,适合快速原型开发。
国产向量数据库:Milvus、腾讯云VectorDB、数智引航科技VexDB(Vector+X+Database)、九章云极DingoDB、京东云Vearch、火山引擎VikingDB、百度智能云VectorDB、爱可生TensorDB、星环科技Transwarp Hippo、零一万物Descartes、枫清科技ArcVector。
选择建议:
新手入门/小型项目:从 ChromaDB 或 FAISS 开始是最佳选择。它们与 LangChain/LlamaIndex 紧密集成,几行代码就能运行,且能满足基本的存储和检索需求。
生产环境/大规模应用:当数据量超过百万级,或需要高并发、实时更新、复杂元数据过滤时,应考虑更专业的解决方案,如 Milvus、Weaviate 或云服务 Pinecone。
其它:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号