

一,#本机环境检查
执行nvidia-smi,查看右上角。验证显卡驱动已安装最高支持的版本。
nvidia-smi
#在调试时,为了实时观察GPU利用率,一般新开一个命令窗口,执行以下命令,一秒刷新一次。
watch -n 1 nvidia-smi
执行nvcc -V验证cuda
nvcc -V
执行conda --version验证conda版本
conda --version
#列出所有已创建的Conda 环境:
conda env list 或 conda info --envs
#若存在,先删除已存在环境
conda env remove -n conda_qwen_image
#创建新环境
conda create -n conda_qwen_image python=3.10
#激活环境
conda activate conda_qwen_image
二,依赖库安装
根据CUDA版本安装PyTorch:
CUDA 12.1:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
CUDA 12.2:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu122
#验证PyTorch是否能正确识别GPU
python3 -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('GPU设备:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None'); print('GPU数量:', torch.cuda.device_count());"
#魔搭modelscope库安装
pip3 install modelscope
#相关库
pip3 install --upgrade transformers peft diffusers fastapi uvicorn
#新建man.py文件,加入代码
from modelscope import DiffusionPipeline, FlowMatchEulerDiscreteScheduler, snapshot_download
import torch
import math
import os
from pathlib import Path
from datetime import datetime
import base64
from io import BytesIO
from typing import Optional, List, Union
import time
import uuid
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
# 设置HF_ENDPOINT使用国内镜像加速模型下载
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# 减少显存碎片化
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# 启用推理模式,减少显存占用
torch.inference_mode()
# 定义请求和响应模型
class ImageGenerationRequest(BaseModel):
prompt: str
negative_prompt: Optional[str] = ""
width: Optional[int] = 1024
height: Optional[int] = 1024
num_inference_steps: Optional[int] = 8
seed: Optional[int] = 0
class ImageData(BaseModel):
b64_json: str
revised_prompt: str
class ImageGenerationResponse(BaseModel):
created: int
data: List[ImageData]
# 初始化模型
def initialize_model():
print("=" * 50)
print("开始初始化模型...")
print("=" * 50)
scheduler_config = {
'base_image_seq_len': 256,
'base_shift': math.log(3),
'invert_sigmas': False,
'max_image_seq_len': 8192,
'max_shift': math.log(3),
'num_train_timesteps': 1000,
'shift': 1.0,
'shift_terminal': None,
'stochastic_sampling': False,
'time_shift_type': 'exponential',
'use_beta_sigmas': False,
'use_dynamic_shifting': True,
'use_exponential_sigmas': False,
'use_karras_sigmas': False,
}
print("正在配置调度器...")
scheduler = FlowMatchEulerDiscreteScheduler.from_config(scheduler_config)
print("调度器配置完成")
# 检测可用GPU数量
num_gpus = torch.cuda.device_count()
print(f"检测到 {num_gpus} 个GPU设备")
# 根据项目规范,对于DiffusionPipeline模型,我们使用max_memory参数进行显存分配
# 而不是手动指定每层的设备映射
if num_gpus > 1:
print("检测到多个GPU,正在进行显存分配...")
# 获取每个GPU的显存信息并计算可分配的显存量
max_memory = {}
for i in range(num_gpus):
free_mem, total_mem = torch.cuda.mem_get_info(i)
# 按70%的空闲显存计算分配量,同时确保不超过22GB
allocated_mem = min(int(free_mem * 0.7), 22 * 1024**3, free_mem)
max_memory[i] = allocated_mem
print(f"GPU {i}: 分配 {(allocated_mem / 1024**3):.2f} GB 显存")
# 加载模型并指定显存分配
print("正在加载模型到多个GPU...")
pipe = DiffusionPipeline.from_pretrained(
'Qwen/Qwen-Image',
scheduler=scheduler,
torch_dtype=torch.bfloat16,
max_memory=max_memory, # 为每个GPU分配显存
)
print("多GPU模型加载完成")
else:
# 单GPU情况
print("检测到单个GPU,正在加载模型...")
pipe = DiffusionPipeline.from_pretrained(
'Qwen/Qwen-Image',
scheduler=scheduler,
torch_dtype=torch.bfloat16,
)
pipe = pipe.to("cuda")
print("单GPU模型加载完成")
print(f"模型已分配到{num_gpus}个GPU设备上")
print("=" * 50)
print("模型初始化完成")
print("=" * 50)
return pipe
# 提前下载LoRA权重
def download_lora_weights():
print("=" * 50)
print("开始下载LoRA权重...")
print("=" * 50)
# 使用ModelScope的snapshot_download下载LoRA权重
model_dir = snapshot_download('lightx2v/Qwen-Image-Lightning')
print(f"LoRA权重已下载到: {model_dir}")
# 查找.pt或.safetensors文件
lora_files = list(Path(model_dir).glob("*.safetensors")) + list(Path(model_dir).glob("*.pt"))
if not lora_files:
raise FileNotFoundError("在下载的LoRA权重目录中未找到.safetensors或.pt文件")
lora_file_path = lora_files[0] # 使用找到的第一个文件
print(f"使用LoRA文件: {lora_file_path}")
print("=" * 50)
print("LoRA权重下载完成")
print("=" * 50)
return str(lora_file_path)
# 图像生成函数
def generate_image(request: ImageGenerationRequest, pipe):
"""生成图像"""
print("=" * 50)
print("开始生成图像...")
print("=" * 50)
print(f"输入参数:")
print(f" - 提示词: {request.prompt}")
print(f" - 负面提示词: {request.negative_prompt}")
print(f" - 图像尺寸: {request.width}x{request.height}")
print(f" - 推理步数: {request.num_inference_steps}")
print(f" - 随机种子: {request.seed}")
start_time = time.time()
print("开始图像生成过程...")
print("正在调用模型生成图像...")
image = pipe(
prompt=request.prompt,
negative_prompt=request.negative_prompt,
width=request.width,
height=request.height,
num_inference_steps=request.num_inference_steps,
true_cfg_scale=1.0,
generator=torch.manual_seed(request.seed)
).images[0]
generation_time = time.time() - start_time
print(f"图像生成完成,耗时: {generation_time:.2f} 秒")
print("正在将图像转换为base64编码...")
# 将图像转换为base64编码
buffered = BytesIO()
image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
print("图像转换完成")
print("=" * 50)
print("图像生成流程结束")
print("=" * 50)
return img_str
# 初始化FastAPI应用
app = FastAPI(
title="Qwen-Image API",
description="基于Qwen-Image模型的OpenAI兼容图像生成API",
version="1.0.0"
)
# 全局模型实例
pipe = None
@app.on_event("startup")
async def startup_event():
global pipe
# 初始化模型
pipe = initialize_model()
# 下载LoRA权重
lora_file_path = download_lora_weights()
print("正在加载LoRA权重...")
pipe.load_lora_weights(lora_file_path)
print("LoRA权重加载完成")
@app.post("/v1/images/generations", response_model=ImageGenerationResponse)
async def create_image(request: ImageGenerationRequest):
try:
# 生成图像
image_data = generate_image(request, pipe)
# 构造响应
response = ImageGenerationResponse(
created=int(time.time()),
data=[
ImageData(
b64_json=image_data,
revised_prompt=request.prompt
)
]
)
return response
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8800)
运行服务端API。 CUDA_VISIBLE_DEVICES 指定显卡编号
CUDA_VISIBLE_DEVICES=0,1 python3 main.py
测试调用
curl -X POST http://localhost:8800/v1/images/generations -H "Content-Type: application/json" -d '{"prompt": "a lovely cat"}' | grep -q '"data"' && echo "API 工作正常" || echo "API 出现问题"
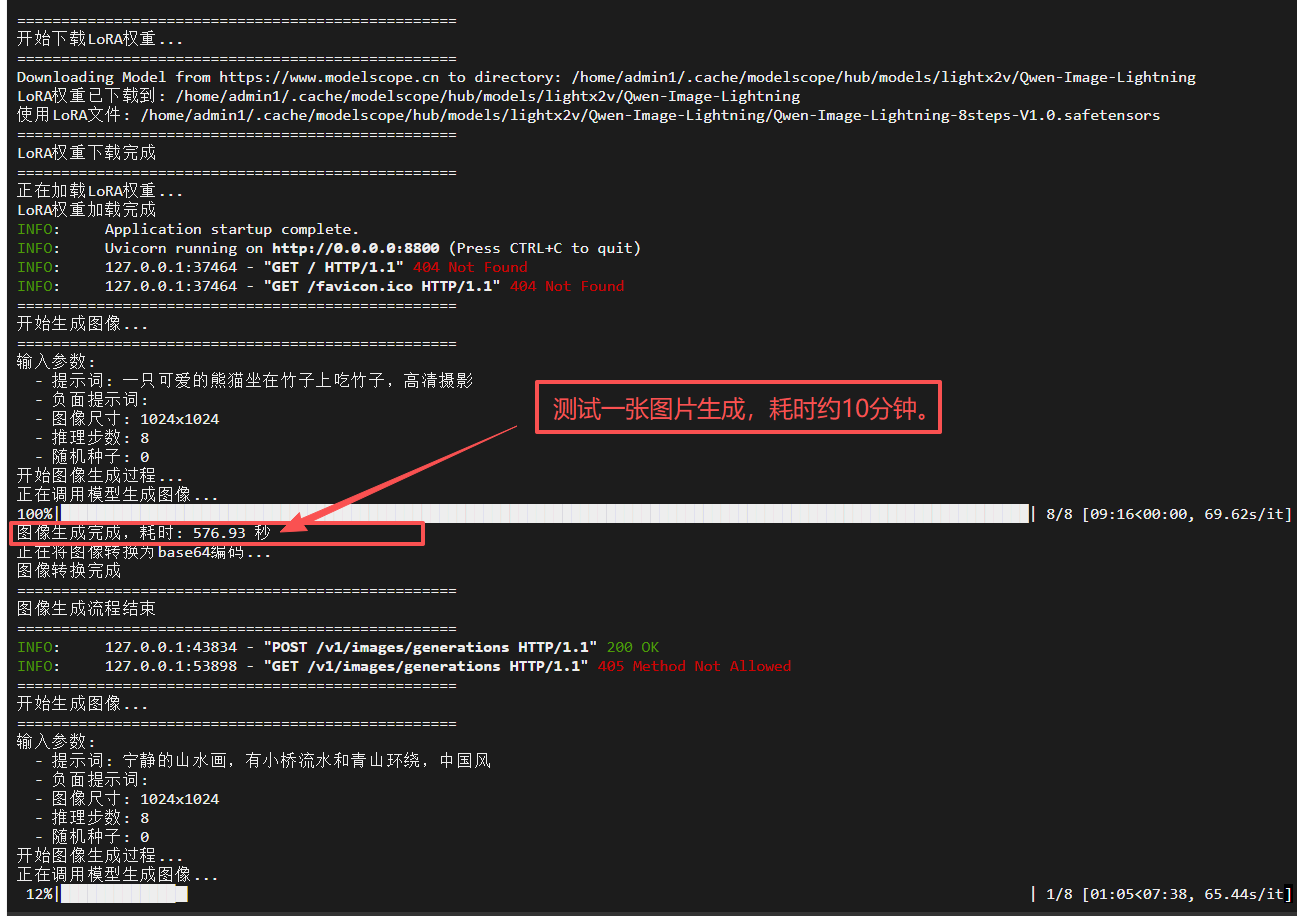
调用时控制台截图:
#安装低代码gradio库
pip3 install gradio
#新建app.py 使用低代码,创建文生图用户端。
import gradio as gr import requests import json import base64 from io import BytesIO from PIL import Image import traceback # 本地API配置 API_URL = "http://localhost:8800/v1/images/generations" # 示例提示词 EXAMPLE_PROMPTS = [ "一只可爱的熊猫坐在竹子上吃竹子,高清摄影", "未来城市的夜景,有飞行汽车和霓虹灯,赛博朋克风格", "宁静的山水画,有小桥流水和青山环绕,中国风" ] def generate_image(prompt, negative_prompt="", width=1024, height=1024, steps=8, seed=0): """ 调用本地API生成图片 Args: prompt (str): 正向提示词 negative_prompt (str): 负向提示词 width (int): 图片宽度 height (int): 图片高度 steps (int): 推理步数 seed (int): 随机种子 Returns: tuple: (生成的图片, 状态信息) """ if not prompt or prompt.strip() == "": return None, "请输入提示词" try: # 准备请求数据 payload = { "prompt": prompt, "negative_prompt": negative_prompt, "width": width, "height": height, "num_inference_steps": steps, "seed": seed } # 调用本地API print(f"正在调用本地API: {API_URL}") response = requests.post(API_URL, json=payload, timeout=1800) # 30分钟超时 if response.status_code == 200: result = response.json() # 解析返回的base64图片数据 if "data" in result and len(result["data"]) > 0: image_data = result["data"][0]["b64_json"] # 解码base64图片数据 image_bytes = base64.b64decode(image_data) image = Image.open(BytesIO(image_bytes)) return image, "图片生成成功" else: return None, "API返回数据格式错误" else: return None, f"API调用失败,状态码: {response.status_code},响应: {response.text}" except requests.exceptions.ConnectionError: return None, "连接API失败,请确保本地API服务已启动" except requests.exceptions.Timeout: return None, "API调用超时,请稍后重试" except Exception as e: error_msg = f"生成图片时出错: {str(e)}" print(error_msg) traceback.print_exc() return None, error_msg # 创建Gradio界面 with gr.Blocks(title="文生图应用") as demo: gr.Markdown("# 文生图应用") gr.Markdown("输入提示词,调用本地API生成对应的图片") with gr.Row(): with gr.Column(): prompt_input = gr.Textbox( label="提示词", placeholder="请输入图片描述...", lines=3 ) negative_prompt_input = gr.Textbox( label="负向提示词", placeholder="请输入不希望出现在图片中的内容(可选)...", lines=2 ) with gr.Accordion("高级参数", open=False): width_input = gr.Slider( minimum=256, maximum=2048, value=1024, step=64, label="图片宽度" ) height_input = gr.Slider( minimum=256, maximum=2048, value=1024, step=64, label="图片高度" ) steps_input = gr.Slider( minimum=1, maximum=50, value=8, step=1, label="推理步数" ) seed_input = gr.Number( label="随机种子 (0表示随机)", value=0, precision=0 ) # 添加示例提示词按钮 gr.Markdown("### 示例提示词") for i, example in enumerate(EXAMPLE_PROMPTS, 1): btn = gr.Button(f"示例 {i}: {example[:30]}..." if len(example) > 30 else f"示例 {i}: {example}") btn.click( fn=lambda ex=example: ex, outputs=prompt_input ) generate_btn = gr.Button("生成图片", variant="primary") with gr.Column(): image_output = gr.Image(label="生成的图片") status_output = gr.Textbox(label="状态信息", max_lines=3) # 绑定生成按钮事件 generate_btn.click( fn=generate_image, inputs=[ prompt_input, negative_prompt_input, width_input, height_input, steps_input, seed_input ], outputs=[image_output, status_output] ) if __name__ == "__main__": print("启动文生图Gradio界面...") print(f"请确保本地API服务已在 {API_URL} 启动") demo.launch(server_name="0.0.0.0", server_port=7860, share=False)
#运行应用
python3 app.py
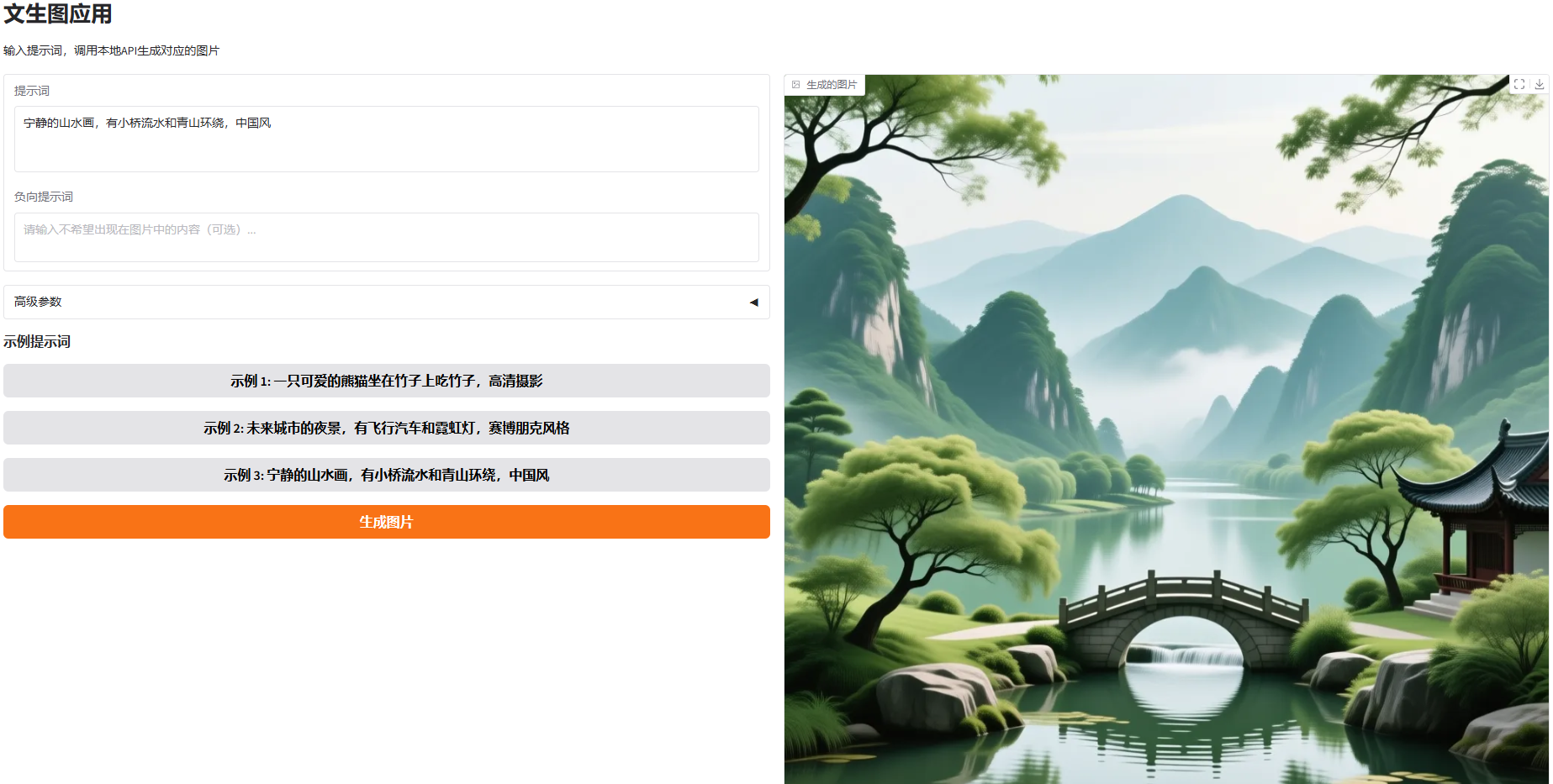
#使用效果图




 浙公网安备 33010602011771号
浙公网安备 33010602011771号