

本地布署Diffusers库实现文生图
本次随笔,记录开源Python库Diffusers库的使用。
Diffusers库由Hugging Face维护,拥有活跃的社区和丰富的文档。
Diffusers库是专注于扩散模型(Diffusion Models)的开源Python库。
Diffusers库多任务支持:支持无条件图像生成、文本到图像、图像到图像、超分辨率、图像修复、音频生成等多种任务
一,#本机环境检查
执行nvidia-smi,查看右上角。验证显卡驱动已安装最高支持的版本。
nvidia-smi
执行nvcc -V验证cuda
nvcc -V
执行conda --version验证conda版本
conda --version
#列出所有已创建的Conda 环境:
conda env list
或
conda info --envs
#若存在,先删除已存在环境
conda env remove -n diffusers_qwen_image
#创建新环境
conda create -n diffusers_qwen_image python=3.10
#激活环境
conda activate diffusers_qwen_image
二,库和依赖包安装
#安装最新版本的 diffusers
pip install git+https://github.com/huggingface/diffusers
#安装最新版本的 diffusers,临时清华镜像源下载
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple diffusers[torch]
#验证 diffusers库是否安装成功
python3 -c "import diffusers; print('diffusers 导入成功,版本:', diffusers.__version__)"
#安装 transformers库和依赖。 Stable Diffusion 所需的其他常见依赖也一并安装。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade transformers diffusers accelerate scipy ftfy
#验证transformers库是否安装成功
python3 -c "import transformers; print('transformers 版本:', transformers.__version__)"
根据CUDA版本安装PyTorch:
CUDA 12.1:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
CUDA 12.2:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu122
#验证PyTorch是否能正确识别GPU
python3 -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('GPU设备:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None'); print('GPU数量:', torch.cuda.device_count());"
三,设置环境变量,运行轻量级模型
首次运行 DiffusionPipeline.from_pretrained时,程序会从 Hugging Face Hub下载预训练模型。如果网络连接不稳定,下载可能会非常慢或失败,导致程序卡在下载阶段
解决方法:配置国内镜像加速。在运行你的Python命令之前,先在终端执行以下命令:
#设置环境变量,使用Hugging Face国内镜像站:
export HF_ENDPOINT=https://hf-mirror.com
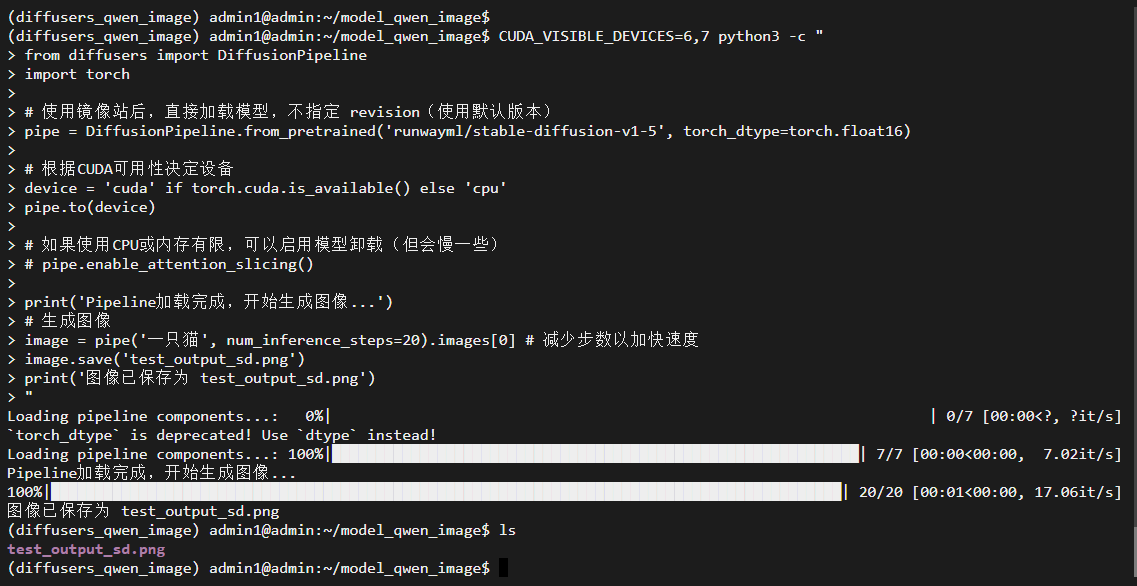
#使用轻量级模型: "runwayml/stable-diffusion-v1-5",用于验证流程。本次我本机指定第7张和第8张显卡运行
CUDA_VISIBLE_DEVICES=6,7 python3 -c " from diffusers import DiffusionPipeline import torch # 使用镜像站后,直接加载模型,不指定 revision(使用默认版本) pipe = DiffusionPipeline.from_pretrained('runwayml/stable-diffusion-v1-5', torch_dtype=torch.float16) # 根据CUDA可用性决定设备 device = 'cuda' if torch.cuda.is_available() else 'cpu' pipe.to(device) # 如果使用CPU或内存有限,可以启用模型卸载(但会慢一些) # pipe.enable_attention_slicing() print('Pipeline加载完成,开始生成图像...') # 生成图像 image = pipe('一只猫', num_inference_steps=20).images[0] # 减少步数以加快速度 image.save('test_output_sd.png') print('图像已保存为 test_output_sd.png') "
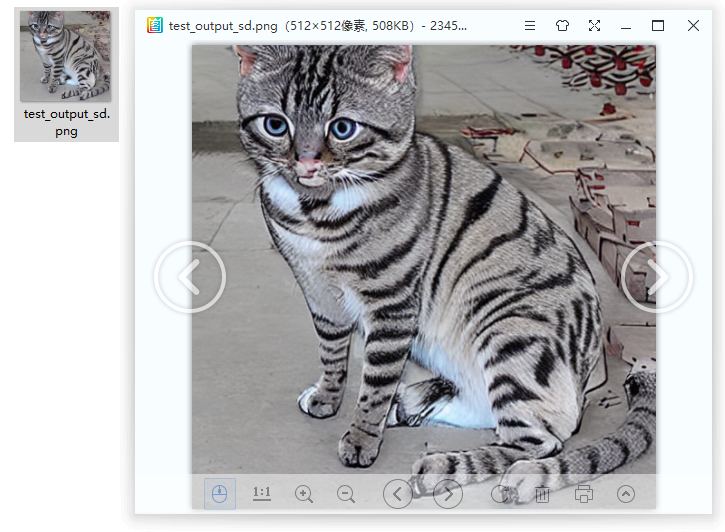
效果图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号