

以百度为例,介绍Page Object设计
前言
Page Object 是 UI 自动化测试项目开发实践的最佳设计模式之一,它的主要特点体现在对界面交互细节的封装上,使测试用例更专注于业务的操作,从而提高测试用例的可维护性。
认识 Page Object
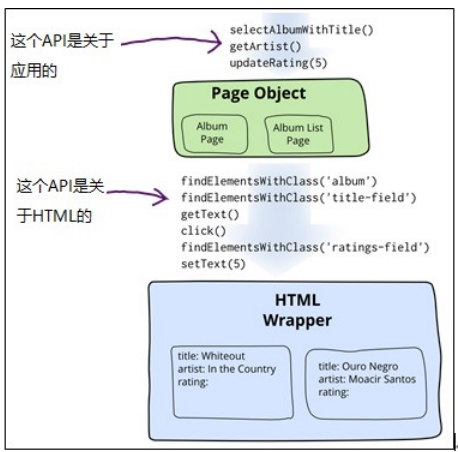
实现 Paget Object
1、创建 base.py 文件,内容如下:
创建 BasePage 类作为所有 Page 类的基类,在 BasePage 类中封装一些方法,这些方法是我们在做自动化时经常用到的。
-
open()方法用于打开网页,它接收一个 url 参数,默认为 None。如果 url 参数为None,则默认打开子类中定义的 url。稍后会在子类中定义 url 变量。
-
by_id()和 by_name()方法。我们知道,Selenium 提供的元素定位方法很长,这里做了简化,只是为了在子类中使用更加简便。
-
get_title()和 get_text()方法。这些方法是在写自动化测试时经常用到的方法,也可以定义在 BasePage 类中。需要注意的是,get_text()方法需要接收元素定位,这里默认为 XPath 定位。
当然,我们还可以根据自己的需求封装更多的方法到 BasePage 类中。
1 # -*-coding:utf-8-*- 2 class BasePage(): 3 """ 4 基础page层,封装一些常用方法 5 """ 6 7 def __init__(self, driver): 8 self.driver = driver 9 10 # 打开页面 11 def open(self, url=None): 12 if url is None: 13 self.driver.get(self.url) 14 else: 15 self.driver.get(url) 16 17 # id 定位 18 def by_id(self, id_): 19 return self.driver.find_element_by_id(id_) 20 21 # name 定位 22 def by_name(self, name): 23 return self.driver.find_element_by_name(name) 24 25 # class 定位 26 def by_class(self, class_name): 27 return self.driver.find_element_by_class_name(class_name) 28 29 # xpath 定位 30 def by_xpath(self, xpath): 31 return self.driver.find_element_by_xpath(xpath) 32 33 # css 定位 34 def by_css(self, css): 35 return self.driver.find_element_by_css_selector(css) 36 37 # 获取title 38 def get_title(self): 39 return self.driver.title 40 41 # 获取页面text 42 def get_text(self, xpath): 43 return self.by_xpath(xpath).text 44 45 # 执行JavaScript脚本 46 def js(self, script): 47 self.driver.execute_script(script)
2、创建baidu_page.py 文件
创建 BaiduPage.py 类继承 BasePage 类,定义 url 变量,供父类中的 open()方法使用。这里可能会有点绕,所以举个例子:小明的父亲有一辆电动玩具汽车,电动玩具汽车需要电池才能跑起来,但小明的父亲并没有为电动玩具汽车安装电池。小明继承了父亲的这辆电动玩具汽车,为了让电动玩具汽车跑起来,小明购买了电池。在这个例子中,open()方法就是“电动玩具汽车”,open()方法中使用的 self.url 就是“电池”,子类中定义的 url 是为了给父类中的 open()方法使用的。
在 search_input()和 search_button()方法中使用了父类的 self.by_id()方法来定位元素,比原生的 Selenium 方法简短了不少。
在测试用例中,使用 BaiduPage 类及它所继承的父类中的方法。
1 from base import BasePage 2 3 4 class BaiduPage(BasePage): 5 """百度 Page 层,百度页面封装操作到的元素""" 6 7 url = "https://www.baidu.com" 8 9 def search_input(self, search_key): 10 self.by_id("kw").send_keys(search_key) 11 12 def search_button(self): 13 self.by_id("su").click()
3、创建测试用例test_baidu.py
因为前面封装了元素的定位,所以在编写测试用例时会方便不少,当需要用到哪个 Page类时,只需将它传入浏览器驱动,就可以使用该类中提供的方法了。
1 import unittest 2 from time import sleep 3 from selenium import webdriver 4 from baidu_page import BaiduPage 5 6 7 class TestBaidu(unittest.TestCase): 8 9 @classmethod 10 def setUpClass(cls): 11 cls.driver = webdriver.Firefox() 12 13 def test_baidu_search_case(self): 14 page = BaiduPage(self.driver) 15 page.open() 16 page.search_input("selenium") 17 page.search_button() 18 sleep(5) 19 self.assertEqual(page.get_title(), "selenium_百度搜索") 20 21 @classmethod 22 def tearDownClass(cls): 23 cls.driver.quit() 24 25 26 if __name__ == "__main__": 27 unittest.main(verbosity=2)
本博客所有文章仅用于学习、研究和交流目的,欢迎非商业性质转载。
本文来自博客园,作者:hello_殷,转载请注明原文链接:https://www.cnblogs.com/yinzuopu/articles/15466588.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号