
Hadoop数据序列化
Hadoop数据序列化
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.数据序列化概述
1>.什么是数据序列化
Q1:什么数据序列化?
是将内存对象转换为字节流的过程,它直接决定了数据解析效率以及模式演化能力(数据格式发生变化时,比如增加或删除字段,是否仍能够保持兼容性)。
话句话说,就是把内存中的对象,转换成字节序列(或其它数据传输协议)以便于存储到磁盘(持久化)和网络传输。
Q2:什么是反序列化?
就是将收到字节序列(或其它数据传输协议)或者是磁盘持久化数据,转换成内存中的对象。
Q3:为什么要序列化?
答:一般来说,对象只生成在内存中里,关机断电就没有了,而且对象只能由本地进程使用,不能被发送到网络的另外一台计算机。然而序列化可以存储对象,将对象发送到远程计算机,当然也可以本地存储,当你的计算机断电下次可以读取磁盘数据以还原内存对象的数据结构。
2>.数据序列化的意义
当需要将数据存入文件或者通过网络发送出去时,需将数据对象转换为字节流,即对数据序列化。
考虑到性能,占用空间以及兼容性等因素,我们通常会经历以下几个阶段的技术演化,最终找到解决该问题的最优方案。
阶段一:
不考虑任何复杂的序列化方案,直接将数据转化成字符串,以文本形式保存或传输,如果有一条数据存在多个字段,则使用分隔符(比如",")进行分割。
该方案存储简单数据绰绰有余,但对于复杂数据传输,且数据模型经常变动时,将变化非常烦琐,通常会面临以下问题:
1>.难以表达嵌套数据
如果每条数据是嵌套式的,比如存在类似于map,list数据结构时,以文本方式存储时非常困难的。
2>.无法表达二进制数据
图片,视频等二进制数据无法表达,因为这类数据无法表示成简单的文本字符串。
3>.难以应对数据模式变化
在实际应用过程中,由于用户考虑不周全或需求发生变化,数据模式可能会经常发生变化。而每次发生变化,之前所有写入和读取(解析)模块均不可用,所有解析均需要修改,非常烦琐。
阶段二:
采用编程语言内置的序列化机制,比如Java Serialization,Python pickle等。
这种方式解决了阶段1面临的大部分问题,但随着使用逐步深入,我们发现这种方式将数据表示方式跟某种特定语言绑定在一起,很难左到跨语言数据的写入和读取。
阶段三:
为了解决阶段2面临的问题,我们决定使用应用范围广,跨语言的数据表示格式,比如JSON和XML。
但使用一段时间后,你会发现这种方式存在严重的性能问题:解析速度太慢,同时数据冗余较大,比如JSON会重复存储每个属性的名称等。
阶段四:
到这一阶段,我们期望出现一种带有schema描述的数据表示格式,通过统一化的schema描述,可约束每个字段的类型,进而为存储和解析数据带来优化的可能。
此外,统一schema的引入,可减少属性名称重复带来的开销,同时,也有利于数据共享。这就是我们通常所说的序列化框架。
常用的序列化框架有Thrift,Protocol Buffers和Avro,它们被称为"Language Of Data"。它们通过引入schema,使得数据跨语言序列化变得非常搞笑,同时提供了代码生成工具,为用户自动生成各种语言的代码。
总结起来,"Language Of Data"具备了以下基本特征:
1>.提供IDL(Interface Description Language)用以描述数据schema,能够很容易地描述任意结构化数据和非结构化数据。
2>.支持跨语言读写,至少支持C++,Java和Python三种主流语言。
3>.数据编码存储(整数可采用变长编码,字符串可采用压缩编码等),以尽可能避免不必要的存储浪费。
4>.支持schema演化,即允许按照一定规则修改数据的schema,仍可保证独写模块向前向后的兼容性(比如序列化前时指定了5个字段,我们在反序列化时可以只序列化3个字段)。
3>.Hadoop序列化特点
为什么不用Java的序列化
Java的序列化时一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息,比如各种校验信息,Header,继承体系等。不便于在网络中高效传输。所以,Hadoop字节开发了一套序列化机制(Writable)
Hadoop序列化特点:
1>.紧凑:
高效使用存储空间。
2>.快速:
读写数据的额外开销小。
3>.可扩展性:
随着通信协议的升级而可升级。
4>.互操作:
支持多语言的交互。比如主流的C++,Java,Python等编程语言。
二.数据序列化方案概述
目前存在很多开源序列化方案,其中比较著名的有Facebook Thrift,Google Protocol Buffers(简称"Protobuf")以及Apache Avro,这些序列化方案大同小异,彼此之间不存在压倒性优势,在实际应用中,需结合具体应用场景做出选择。
1>.序列化框架Thrift
Thrift时Facebook开源的RPC(Remote Procedure Call Protocol)框架,同时具有序列化和RPC两个功能,它几乎支持所有编程语言,包括C++,Java,Python,PHP,Ruby,Erlang,Perl,Haskel等。 Thrift提供了一套IDL语法用以定义和描述数据类型和服务。IDL文件由专门的代码生成器生成对应的目标语言代码,以供用户在应用程序总使用。Thrift IDL语法类似于C语言。 相比于其它序列化框架,Thrift最强大支出在于提供了RPC实现,如果有感兴趣的小伙伴可自行阅读Thrift官方文档。 博主推荐阅读: http://thrift.apache.org/docs/
2>.序列化框架Protobuf
Protocol Buffers是Google公司开源的序列化框架,主要支持Java,C++,Python三种语言,语法和使用方式与Thrift非常类似,但不包含RPC实现。 由于采用了更加紧凑的数据编码方式,大部分情况下,对于相同数据 集,Protobuf比Thrift占用存储空间更小,且解析速度更快。 博主推荐阅读: https://developers.google.com/protocol-buffers/
3>.序列化框架Avro
Avro是Hadoop生态系统中序列化及RPC框架,设计之初的意图是为Hadoop提供一个搞笑,灵活且易于演化的序列化及RPC基础库,目前已经发展成一个独立的项目。 相比Thrift和Protobuf,Avro具有以下几个特点: 1>.动态类型: Avro不需要生成代码,它将数据和schema存放在一起,这样数据处理过程并不需要生成代码,方便构建通用的数据处理系统和语言。 2>.未标记的数据 读取Avro数据时schema是已知的,这使得编码到数据中的类型信息表少,进而使得序列化后的数据变少。 3>.不需要显示指定域编号 处理数据时新旧schema都是已知的,因此通过使用字段名称即可解决兼容性问题。 Avro IDL语法与Thrift,Protobuf非常类似,只不过无需为每个域显示指定编号。Avro最初只支持JSON方式定义数据,后来增加了IDL支持。 博主推荐阅读: http://avro.apache.org/
三.自定义数据序列化实操案例
1>.需求分析
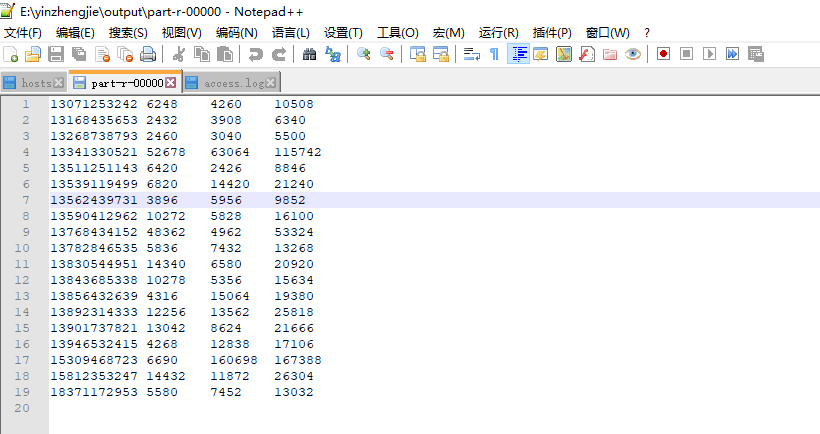
统计access.log文件中每一个手机号耗费的总上传流量,下载流量和总流量。 数据格式如下所示,默认以"\t"进行分割,各字段分别表示:id,手机号,网络IP,上传流量,下载流量,网络访问状态码。 1 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 7441 4386 200 期望输出格式如下所示,默认以"\t"进行分割,各字段分别表示:手机号,上传流量,下载流量和总流量。 13341330521 52678 63064 115742


1 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 7441 4386 200 2 13946532415 172.200.100.21 thrift.apache.org/docs/ 2134 6419 200 3 13856432639 172.200.30.101 www.cnblogs.com/yinzhengjie2020 2158 7532 200 4 13511251143 172.200.100.13 developers.google.com 3210 1213 404 5 18371172953 172.200.30.101 2790 3726 200 6 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 3712 5923 200 7 13590412962 172.200.30.2 avro.apache.org 5136 2914 200 8 15812353247 172.200.100.91 www.hao123.com 7216 5936 200 9 13539119499 172.200.100.61 thrift.apache.org/docs/ 3410 7210 200 10 13830544951 172.200.100.39 www.shouhu.com 7170 3290 403 11 13843685338 172.200.100.181 5139 2678 200 12 13341330521 172.200.100.29 www.cnblogs.com/yinzhengjie/ 3128 2980 500 13 13562439731 172.202.100.110 avro.apache.org 1948 2978 200 14 13071253242 172.200.100.210 thrift.apache.org/docs/ 3124 2130 200 15 13782846535 172.200.100.120 www.qq.com 2918 3716 200 16 13892314333 172.200.30.101 www.cnblogs.com/yinzhengjie2020 6128 6781 200 17 15309468723 172.200.100.34 www.qinghua.com 3345 80349 404 18 13901737821 172.200.100.95 www.sogou.com 6521 4312 200 19 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie2020 12058 18243 200 20 13268738793 172.200.100.217 avro.apache.org 1230 1520 200 21 13768434152 172.200.100.118 www.alibaba.com 24181 2481 200 22 13168435653 172.200.30.101 1216 1954 200 23 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 7441 4386 200 24 13946532415 172.200.100.21 thrift.apache.org/docs/ 2134 6419 200 25 13856432639 172.200.30.101 www.cnblogs.com/yinzhengjie2020 2158 7532 200 26 13511251143 172.200.100.13 developers.google.com 3210 1213 404 27 18371172953 172.200.30.101 2790 3726 200 28 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie/ 3712 5923 200 29 13590412962 172.200.30.2 avro.apache.org 5136 2914 200 30 15812353247 172.200.100.91 www.hao123.com 7216 5936 200 31 13539119499 172.200.100.61 thrift.apache.org/docs/ 3410 7210 200 32 13830544951 172.200.100.39 www.shouhu.com 7170 3290 403 33 13843685338 172.200.100.181 5139 2678 200 34 13341330521 172.200.100.29 www.cnblogs.com/yinzhengjie/ 3128 2980 500 35 13562439731 172.202.100.110 avro.apache.org 1948 2978 200 36 13071253242 172.200.100.210 thrift.apache.org/docs/ 3124 2130 200 37 13782846535 172.200.100.120 www.qq.com 2918 3716 200 38 13892314333 172.200.30.101 www.cnblogs.com/yinzhengjie2020 6128 6781 200 39 15309468723 172.200.100.34 www.qinghua.com 3345 80349 404 40 13901737821 172.200.100.95 www.sogou.com 6521 4312 200 41 13341330521 172.200.30.101 www.cnblogs.com/yinzhengjie2020 12058 18243 200 42 13268738793 172.200.100.217 avro.apache.org 1230 1520 200 43 13768434152 172.200.100.118 www.alibaba.com 24181 2481 200 44 13168435653 172.200.30.101 1216 1954 200
2>.编写流量统计的Bean对象
package cn.org.yinzhengjie.flow; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class FlowBean implements Writable { private long upFlow; private long downFlow; private long sumFlow; //定义一个空参构造器,反射时会用到 public FlowBean() { } public void set(long upFlow,long downFlow){ this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } /* 定义序列化方法 dataOutput: 框架给我们提供的数据出口,我们通过该对象进行数据序列化操作。 温馨提示: 注意输出时的数据类型顺序。我们写入的顺序为upFlow,downFlow,sumFlow. */ public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(upFlow); dataOutput.writeLong(downFlow); dataOutput.writeLong(sumFlow); } /* 定义反序列化方法 dataInput: 框架给我们提供的数据来源,我们通过该对象进行数据反序列化操作。 温馨提示: 注意输入的数据类型顺序要和输出时的数据类型要一一对应,即upFlow,downFlow,sumFlow。如果你不对应可能会导致最终的结果不正确哟~ */ public void readFields(DataInput dataInput) throws IOException { upFlow = dataInput.readLong(); downFlow = dataInput.readLong(); sumFlow = dataInput.readLong(); } }
3>.编写Mapper类
package cn.org.yinzhengjie.flow; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class FlowMapper extends Mapper<LongWritable,Text,Text,FlowBean> { private Text phone = new Text(); private FlowBean flow = new FlowBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到行数据并按照行进行切割 String[] fields = value.toString().split("\t"); //获取电话号码 phone.set(fields[1]); //获取上传流量 long upFlow = Long.parseLong(fields[fields.length - 3]); //获取下载流量 long downFlow = Long.parseLong(fields[fields.length - 2]); //将上传和下载流量传给flow对象 flow.set(upFlow,downFlow); //最后将map的处理结果交给mapreduce框架 context.write(phone,flow); } }
4>.编写Reducer类
package cn.org.yinzhengjie.flow; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> { private FlowBean sumFlow = new FlowBean(); @Override protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { long sumUpFlow = 0; long sumDownFlow = 0; for (FlowBean value : values){ sumUpFlow += value.getUpFlow(); sumDownFlow += value.getDownFlow(); } sumFlow.set(sumUpFlow,sumDownFlow); context.write(key,sumFlow); } }
5>.编写Driver类
package cn.org.yinzhengjie.flow; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class FlowDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取Job实例 Job job = Job.getInstance(new Configuration()); //设置类路径 job.setJarByClass(FlowDriver.class); //设置Mapper和Reducer job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); //设置输入输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置输入输出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
6>.配置参数并允许Driver
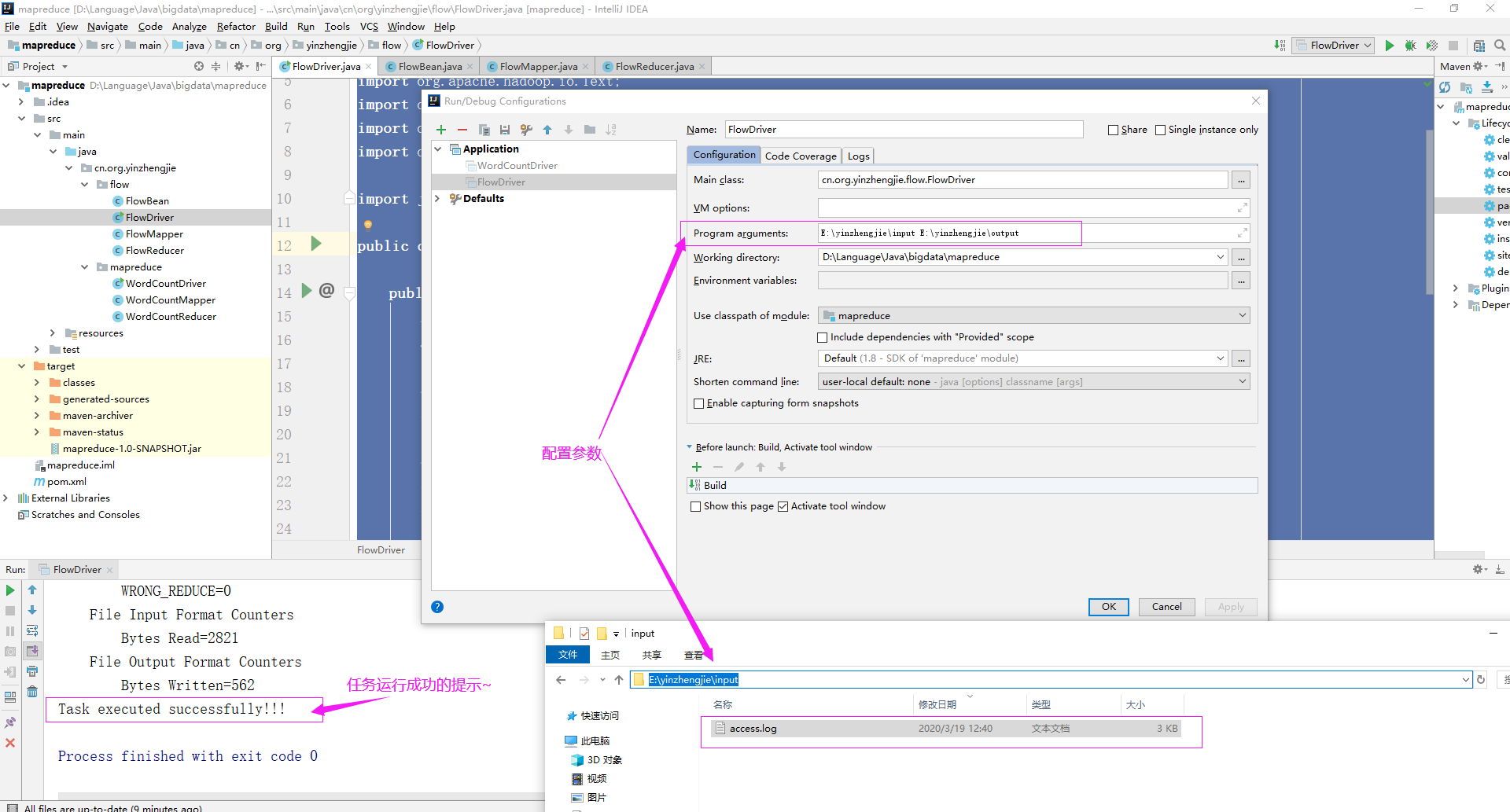
7>.查看运行结果
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。 欢迎加入基础架构自动化运维:598432640,大数据SRE进阶之路:959042252,DevOps进阶之路:526991186

 浙公网安备 33010602011771号
浙公网安备 33010602011771号