

clickhouse概述及单机部署
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Clickhouse概述
1.什么是clickhouse
Clickhouse是一个用于联机分析(Online Analytical Processing,OLAP)的列式数据库管理系统(DBMS)。
clickhouse由俄罗斯的搜索公司yandex在2016年6月15日开源。
官网地址:
https://clickhouse.com/docs/zh
参考链接:
https://clickhouse.com/docs/zh/concepts/olap
https://yandex.com
2.列式与行式数据库性能对比
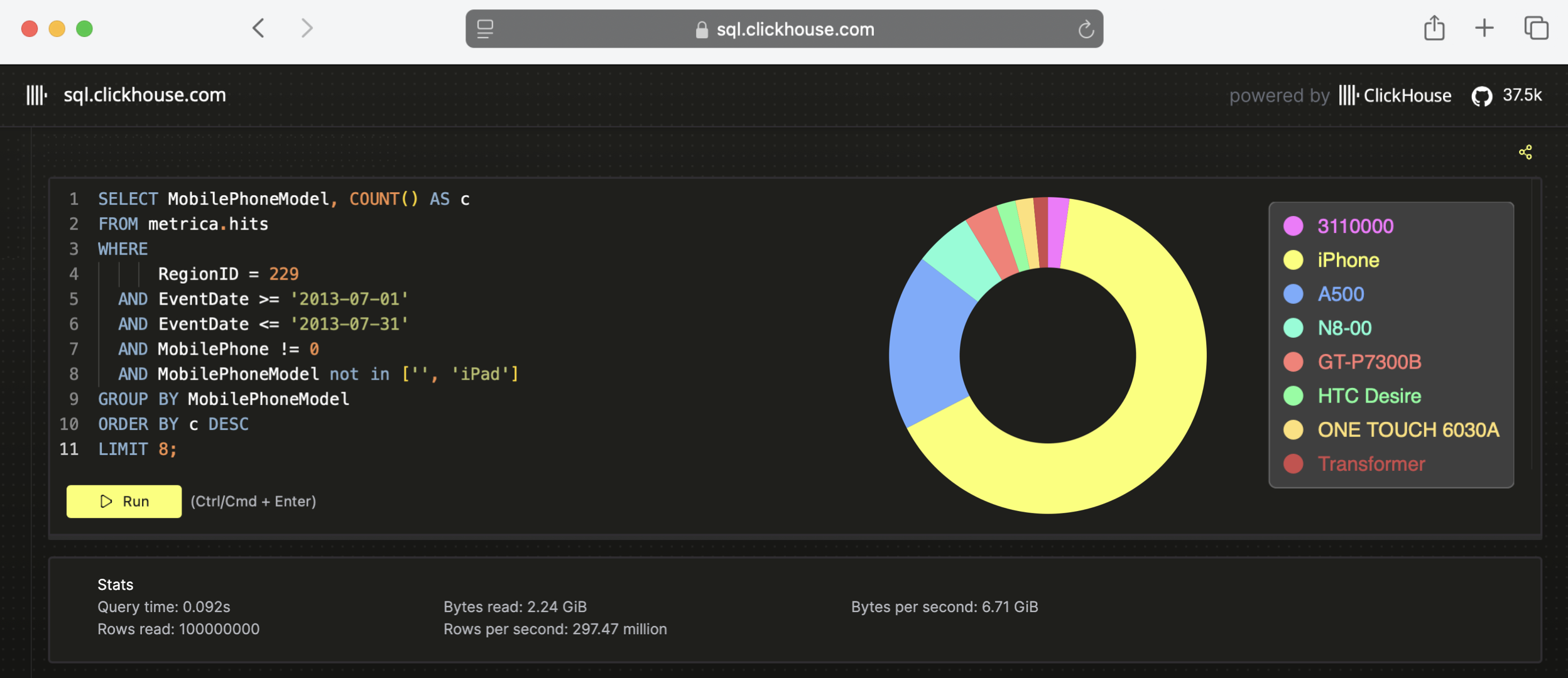
clickhouse性能超过了市面上大部分的数据库,相比传统的数据库,clickhouse要快100~1000倍。
- 1亿条数据clickhouse比Vertica约快5倍,比Hive快279倍,比MySQL快801倍。
- 10亿条数据clickhouse比Vertica约快5倍,MySQL和Hive已经无法完成任务了。
面向行的数据库是典型的事务型,能够处理大量事务,而面向列的数据库通常事务比较少,数据量较大。
正如您在上图的统计部分所看到的,该查询在92毫秒内处理了1亿行,吞吐量约为3亿行,或者不到每秒7GB。
参考链接:
https://clickhouse.com/docs/zh/intro
2.1 行式DBMS
在行式数据库中,即使上面的查询仅处理现有列中的几个,系统仍然需要从磁盘加载其他现有列的数据到内存中。
这是因为数据存储在称为 块 的块中(通常是固定大小,例如 4 KB 或 8 KB)。块是从磁盘读取到内存的最小数据单元。当应用程序或数据库请求数据时,操作系统的磁盘 I/O 子系统从磁盘读取所需的块。
如上图所示,即使只需要块的一部分,整个块也会被读入内存(这是由于磁盘和文件系统的设计)。
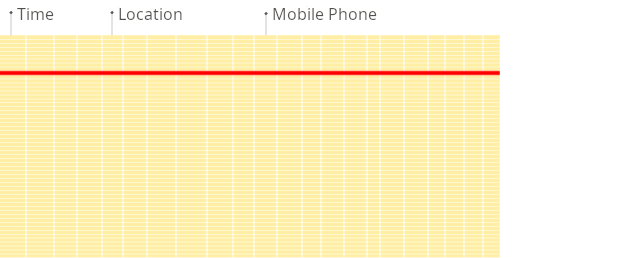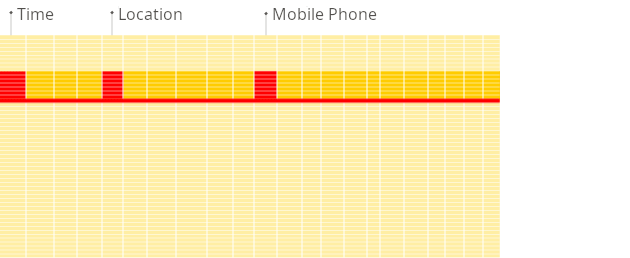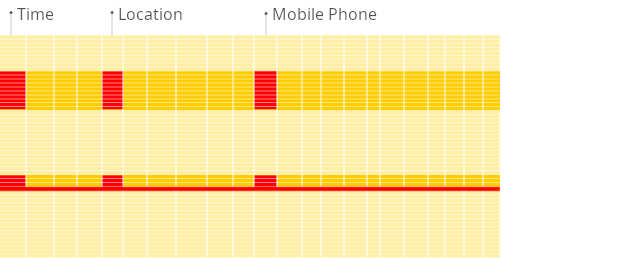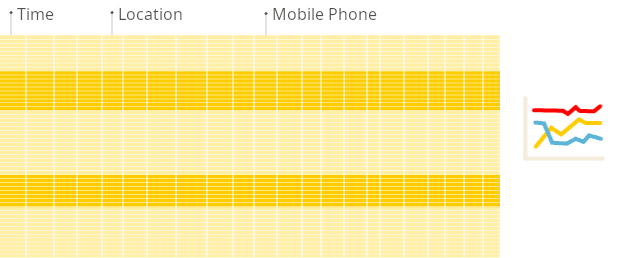
2.2 列式DBMS
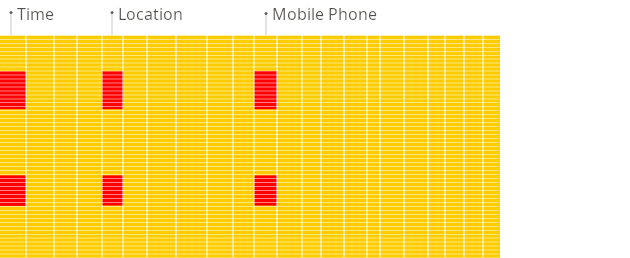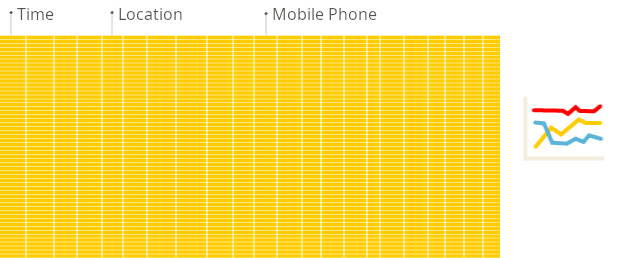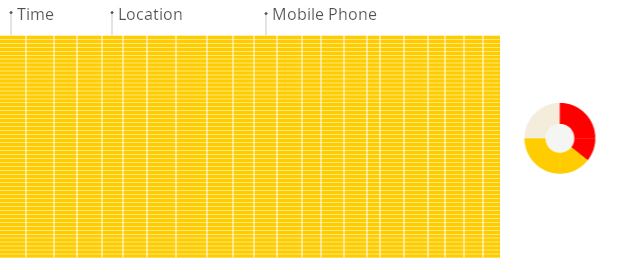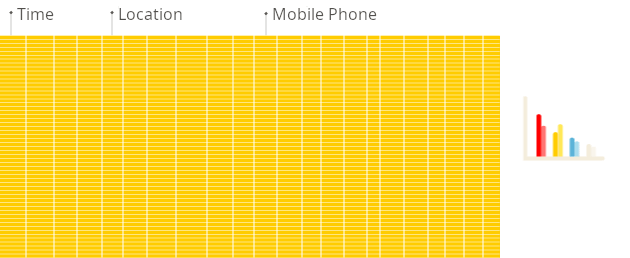
由于每列的值在磁盘上是顺序存储的,因此在运行上述查询时不会加载不必要的数据。
由于块级存储和从磁盘到内存的传输与分析查询的数据访问模式对齐,因此仅读取查询所需的列数据,从而避免了对未使用数据的不必要 I/O。这与行式存储相比,速度快得多,因为整行(包括不相关的列)都被读取。
3.clickhouse特性
clickhouse典型的特性:
- 1.真正的列式数据库管理系统;
- 2.数据压缩比例高,比如"7.4GB"的数据压缩后能到达"1.7GB"左右,压缩率近乎23%。
- 3.对存储无依赖,即使在HDD也能实现良好的性能,但如果由SSD或者内存,也会被充分利用资源;
- 4.多核心CPU的并行处理提高性能;
- 5.多服务器的分布式处理,支持集群模式,将数据分片存储且可以进行查询;
- 6.SQL支持,这意味着可以使用和MySQL近似的查询;
- 7.向量计算引擎,数据不仅按列存储,还通过向量(列的部分)进行处理,这使得CPU效率高;
- 8.实时数据插入;
- 9.主索引,数据物理按主键排序使得可以根据特定值或值范围以低延迟提取数据,低于几十毫秒;
- 10.次级索引;
- 11.适合在线查询;
- 12.支持近似计算;
- 13.自适应连接算法;
- 14.数据复制和数据完整性支持;
- 15.基于角色的访问控制;
- 16.可视为缺点的特性;
参考链接:
https://clickhouse.com/docs/zh/about-us/distinctive-features
https://clickhouse.com/docs/zh/sql-reference
4.clickhouse使用场景
- 1.绝大多数客户端请求都是用于读请求;
- 2.数据需要以大批次(大于1000行)进行更新,而不是单行更新,或者根本没有更新操作;
- 3.数据只是添加到数据库,没有必要修改;
- 4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列(一次性读取角度的数据);
- 5.表很"宽",即表中包含大量的列,也就是表的数据量比较大;
- 6.查询频率相对较低的非高并发场景(通常每台CH服务器每秒查询数百次);
- 7.对于简单查询,允许大约50ms的延迟;
- 8.列的值是比较小的数值和短字符串;
- 9.在处理单个客户端查询时需要高吞吐量(每台服务器每秒高达数十亿行);
- 10.不需要事务的场景(不支持事务);
- 11.数据一致性要求较低(副本同步有延迟);
- 12.每次查询中只会查询一个大表,除了一个大表,其余都是小表(较少跨表查询);
- 13.查询结果显著小于数据源,即数据有过滤或聚合,返回结果不超过单个服务器内存大小;
5.clickhouse缺点
- 1.没有完整的事务支持;
- 2.缺少高频率,低延迟的修改或删除已存在数据的能力,仅能用于批量删除或修改数据;
- 3.稀疏索引导致clickhouse不擅长细粒度或者key-value类型的数据查询需求,稀疏索引是一种优化空间使用的索引方式,它只为非空值建立索引,如果表中的某些字段有很多空值,使用稀疏索引可以节省很多空间;
- 4.不擅长join操作,且语法特殊;
- 5.由于采用并行处理机制,即使一个客户端的大量查询也会使用较多的CPU资源,所以不支持高并发;
6.国内大厂开始拥抱clickhouse
clickhouse非常适用于商业智能领域,也就是我们所说的BI领域。除此之外,它也能够被广泛应有与广告流量,web,APP流量,电信,金融,电子商务,信息安全,网络游戏,物联网等众多其他领域。
clickhouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域,目前国内社区火热,各大厂商纷纷跟进大规模使用。
甚至国内有的公司已经在用clickhouse集群来替代ElasticSearch集群了。
大厂使用案例:
- 1.今日头条内部使用clickhouse来做用户分析,内部一共几千个clickhouse节点,但集群最大1200节点,数据量几十PB,日增原始数据300TB左右。
- 2.腾讯内部用clickhouse做游戏数据分析,并且为之建立了一套监控运维体系;
- 3.携程内部从2018年7月开始接入试用,目前80%的业务都跑在clickhouse上,每天数据增量十多亿,近百万次查询请求;
- 4.快手内部也在使用clickhouse,存储总量大约10PB,每天新增200TB,90%查询小于3s;
- 5.京东clickhouse在物流,大数据,大模型等场景使用clickhouse实现;
温馨提示:
clickhouse官网推出了很多样例数据,大家可以参考。
参考链接:
https://clickhouse.com/docs/zh/getting-started/example-datasets
二.Ubuntu单机部署ClickHouse
1.clickhouse版本及软件包说明
1.1 clickhouse版本说明

clickhouse的版本遵循"Year(年).Major(主版本).Minor(此版本).patchset(补丁集)"的命名风格,例如: "25.4.6.67"。
通常每年会发布两个LTS版本,每个LTS版本会提供一年的支持,而普通的Stable版本(每个月发布一个版本)一般只会提供4个月左右的支持,而且支持的频率也要低一些。
由于clickhouse发布版本的节奏非常之快,几乎每月一个大版本,并且每个大版本都有Stable版本和LTS版本,因此如果企业中选择满足功能需求且稳定的版本非常重要。
Github地址:
https://github.com/ClickHouse/ClickHouse
官网下载地址:
https://packages.clickhouse.com/rpm/stable/
https://packages.clickhouse.com/deb/pool/main/c/
1.2 clickhouse软件包说明
| 包 | 描述 |
|---|---|
clickhouse-common-static |
安装 ClickHouse 编译的二进制文件。 |
clickhouse-server |
创建 clickhouse-server 的符号链接并安装默认服务器配置。 |
clickhouse-client |
创建 clickhouse-client 的符号链接和其他与客户端相关的工具,并安装客户端配置文件。 |
clickhouse-common-static-dbg |
安装带调试信息的 ClickHouse 编译的二进制文件。 |
clickhouse-keeper |
用于在专用 ClickHouse Keeper 节点上安装 ClickHouse Keeper。如果您在与 ClickHouse 服务器相同的服务器上运行 ClickHouse Keeper,则无需安装此软件包。安装 ClickHouse Keeper 及默认的 ClickHouse Keeper 配置文件。 |
如上表所示,是clickhouse常用的各种deb软件包。
参考链接:
https://clickhouse.com/docs/zh/install/debian_ubuntu#packages
1.3 clickhouse硬件环境选择
参考链接:
https://clickhouse.com/docs/zh/guides/sizing-and-hardware-recommendations
https://clickhouse.com/docs/zh/operations/overview
2.Ubuntu部署clickhouse
2.1 安装必备软件包
apt-get update && apt-get -y install apt-transport-https ca-certificates curl gnupg
2.2 下载ClickHouse GPG密钥并将其存储在密钥环中
curl -fsSL 'https://packages.clickhouse.com/rpm/lts/repodata/repomd.xml.key' | sudo gpg --dearmor -o /usr/share/keyrings/clickhouse-keyring.gpg
2.3 将ClickHouse存储库添加到apt源代码中
1.定义架构及安装版本的变量
ARCH=$(dpkg --print-architecture)
VERSION=lts
2.配置apt源
echo "deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg arch=${ARCH}] https://packages.clickhouse.com/deb ${VERSION} main" > /etc/apt/sources.list.d/clickhouse.list
3.查看信息
cat /etc/apt/sources.list.d/clickhouse.list
2.4 安装clickhouse服务器和客户端
1.更新apt包列表
apt-get update
2.安装clickhouse
[root@node-exporter42 ~]# apt-get -y install clickhouse-server clickhouse-client
...
Set up the password for the default user: # 这里需要输入自定义密码,我设置为: yinzhengjie
Password for the default user is saved in file /etc/clickhouse-server/users.d/default-password.xml.
Setting capabilities for clickhouse binary. This is optional.
chown -R clickhouse:clickhouse '/etc/clickhouse-server'
ClickHouse has been successfully installed.
Start clickhouse-server with:
sudo clickhouse start
Start clickhouse-client with:
clickhouse-client --password
Synchronizing state of clickhouse-server.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable clickhouse-server
Created symlink /etc/systemd/system/multi-user.target.wants/clickhouse-server.service → /lib/systemd/system/clickhouse-server.service.
Setting up clickhouse-client (25.3.3.42) ...
[root@node-exporter42 ~]#
2.5 启动clickhouse并连接测试
1.启动clickhouse
[root@node-exporter42 ~]# systemctl enable --now clickhouse-server
[root@node-exporter42 ~]# systemctl status clickhouse-server
2.客户端链接测试
[root@node-exporter42 ~]# clickhouse-client --password yinzhengjie
ClickHouse client version 25.3.3.42 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 25.3.3.
Warnings:
* Delay accounting is not enabled, OSIOWaitMicroseconds will not be gathered. You can enable it using `echo 1 > /proc/sys/kernel/task_delayacct` or by using sysctl.
* Maximum number of threads is lower than 30000. There could be problems with handling a lot of simultaneous queries.
node-exporter42 :) SHOW DATABASES;
SHOW DATABASES
Query id: 7ff9a5db-034a-4515-8bc1-a05b66c46e07
┌─name───────────────┐
1. │ INFORMATION_SCHEMA │
2. │ default │
3. │ information_schema │
4. │ system │
└────────────────────┘
4 rows in set. Elapsed: 0.002 sec.
node-exporter42 :)
三.clickhouse初体验
1.创建表
CREATE TABLE yinzhengjie_clickhouse
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32
)
ENGINE = MergeTree
PRIMARY KEY (user_id, timestamp)
2.插入数据
INSERT INTO yinzhengjie_clickhouse (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 ),
(103, 'https://www.cnblogs.com/yinzhengjie', now() + 5, 3.14159 )
3.查询数据
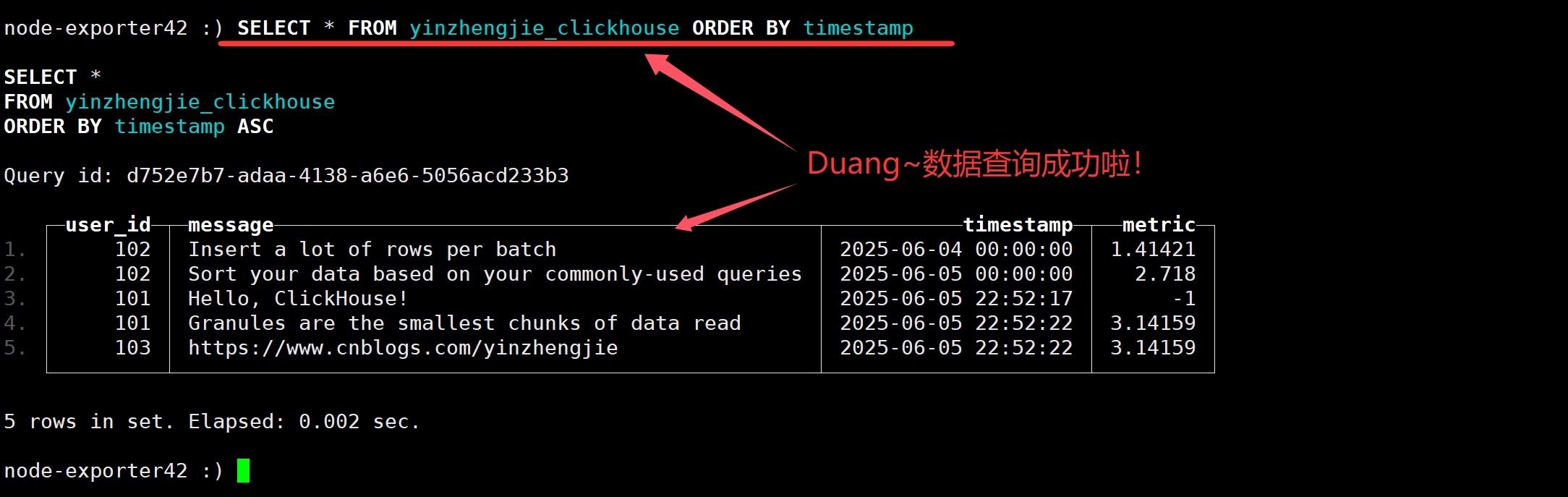
SELECT * FROM yinzhengjie_clickhouse ORDER BY timestamp
4.在线查询clickhouse测试数据

如上图所示,在线查询速度较慢,建议大家手动导入官方数据查询速度会更快。
具体SQL如下:
SELECT
passenger_count,
avg(toFloat32(total_amount))
FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_0.gz',
'TabSeparatedWithNames'
)
GROUP BY passenger_count
ORDER BY passenger_count;
参考链接:
https://clickhouse.com/docs/zh/getting-started/quick-start
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/18913325,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号