

Prometheus语言PromQL快速入门
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.PromQL的二元运算符
1.二元运算符概述
| 运算符类型 | 举例说明 |
|---|---|
| 算数运算符 | +(addition,加法) -(subtraction,减法) *(multiplication,乘法) /(division,除法) %(modulo,取余) ^(power/exponentiation,幂运算) |
| 比较运算符 | ==(equal,相等) !=(not-equl,不等于) >(greater-than,大于) <(less-than,小于) >=(greater-or-equal,大于等于) <=(less-or-equal,小于等于) |
| 逻辑运算符 | and(与) or(或) unless(非) |
二元运算符是Prometheus进行数据可视化或者数据操作的时候,应用非常多的一种功能。
对于二元运算符,它主要包含三类:算数运算符,比较运算符和逻辑运算符。
参考链接:
https://prometheus.io/docs/prometheus/latest/querying/operators/
2.运算符优先级
| 运算符优先级(由高到低) | 描述 |
|---|---|
| () | 可以使用'()'来改变运算次序。 |
| ^ | 幂运算,右结合机制 |
| *,/,% | 运算符满足结合律(左结合)机制 |
| +,- | 运算符满足结合律(左结合)机制 |
| ==,!=,<=,<,>=,> | 运算符满足结合律(左结合)机制 |
| and,unless | 运算符满足结合律(左结合)机制 |
| or | 运算符满足结合律(左结合)机制 |
如上表所示,为运算符的优先级。
如果你记不清楚优先级的顺序,可以使用"()"改变运算次序。
3.算数运算符示例
3.1 取GC的平均值
go_gc_duration_seconds_sum{instance="localhost:9090",job="prometheus"} / go_gc_duration_seconds_count{instance="localhost:9090",job="prometheus"}
3.2 正则表达式
node_memory_MemAvailable_bytes{instance=~"10.0.0.42:9100"}
node_memory_MemAvailable_bytes{instance=~"10.0.0.4[13]:9100"}
node_memory_MemAvailable_bytes{instance=~"10.0.0.4[1-3]:9100"}
node_memory_MemAvailable_bytes{instance=~"10.0.0.*:9100"}
node_memory_MemAvailable_bytes{instance=~"10.0.0.4[^2]:9100"}
node_memory_MemAvailable_bytes{instance!~"10.0.0.42:9100"}
3.3 单位换算可用内存GB
node_memory_MemFree_bytes / (1024 * 1024 * 1024)
3.4 可用内存占用率
node_memory_MemFree_bytes / node_memory_MemTotal_bytes * 100
3.5 内存使用率
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes) / node_memory_MemTotal_bytes * 100
3.6 磁盘使用率
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
3.7 取消metrics输出
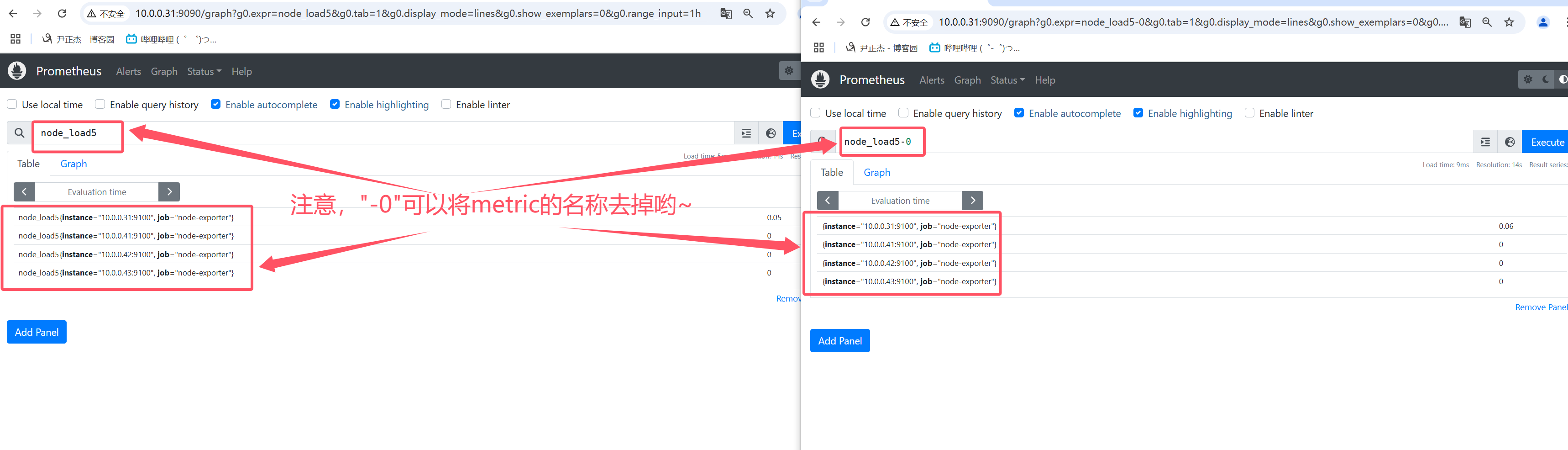
如上图所示,我们可以查询指标时,将对应的metrirs移除。参考语句: 'node_load5-0'
4.比较运算符示例
4.1 阈值判断
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes) / node_memory_MemTotal_bytes > 0.95
4.2 布尔值判断
prometheus_http_requests_total > bool 3000
温馨提示:
- 1.对于比较运算符,条件成立由结果输出,否则没有结果输出;
- 2.使用bool运算符后,布尔运算不会对时间序列进行过滤,而是直接依次瞬时向量中的各个样本数据与标量的比较结果0或者1,从而形成一条新的时间序列;
4.3 内存利用率是否超过80%
( 1 - node_memory_MemFree_bytes/node_memory_MemTotal_bytes) * 100 > bool 80
5.逻辑运算符示例
5.1 or并集
node_memory_MemTotal_bytes{instance="10.0.0.41:9100"} or node_memory_MemFree_bytes{instance="10.0.0.42:9100"}
node_memory_MemTotal_bytes{instance=~"10.0.0.(41|43):9100"}
5.2 and交集
node_memory_MemTotal_bytes{instance=~"10.0.0.42:9100"} and node_memory_MemFree_bytes{job="yinzhengjie-node-exporter"}
5.3 unless补集
node_memory_MemTotal_bytes{job="yinzhengjie-node-exporter"} unless node_memory_MemTotal_bytes{instance="10.0.0.43:9100"}
6.其他补充
向量匹配关键字:
- ignoring:
定义匹配检测时需要忽略的标签。
- on:
定义匹配检测时只使用的标签。
组修饰符:
- group_left:
多对一。
- group_right:
一对多。
举例说明:
- 假设metrics采集的原始数据如下:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
...
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
- 一对一查询语句如下:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
输出结果为:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
- 多对一查询语法如下:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
输出结果为:
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
推荐阅读:
https://prometheus.io/docs/prometheus/latest/querying/operators/#vector-matching-keywords
https://prometheus.io/docs/prometheus/latest/querying/operators/#group-modifiers
https://prometheus.io/docs/prometheus/latest/querying/operators/#one-to-one-vector-matches
二.PromQL的聚合运算函数
1.聚合操作概述
一般来说,单个指标的价值不大,监控场景中往往需要联合并可视化一组指标,这种联合机制是指"聚合"操作,例如将计数,求和,平均值,分位数,标准差,方差等统计函数应用于时间序列的样本之上生成具体统计学意义的结果等。
Prometheus支持以下内置聚合运算符:
- sum()
对样本值求和。
- min()
取样本值中的最小值。
- max()
取样本值的最大值。
- avg()
对样本值求平均值,这是进行指标数据分析的标准方法。
- stddev()
对样本值求标准差,以帮助用户了解数据的波动大小或者波动程度。
- stdvar()
对样本值求方差,它是求取标准差过程中的中间状态。
- count()
对分组内的时间序列进行数量统计。
- count_values()
对分组内的时间序列的相同样本值进行数量统计。
- bottomk()
顺序返回分组内样本最小的前K个时间序列及其值。
- topk()
逆序返回分组内的样本值最大的前K个时间序列及其值。
- quantile()
分位数用于评估数据的分布状态,该函数会返回分组内的指定分位数的值,即数据落在小于等于指定分区间的比例。
- group()
对数据进行分组。
- limitk()
sample n elements。
- limit_ratio()
sample elements with approximately 𝑟 ratio if 𝑟 > 0, and the complement of such samples if 𝑟 = -(1.0 - 𝑟)
可以借助without和by功能获取数据集的一部分进行分组统计:
- without:
表示显示信息的时候,排除此处指定的标签列表,对以外的标签进行分组统计。
使用除此标签之外的其他标签进行分组统计。
- by:
表示显示信息的时候,仅显示指定标签的分组统计,即针对哪些分组统计。
参考链接:
https://prometheus.io/docs/prometheus/latest/querying/operators/#aggregation-operators
2.实战案例
2.1 count计数函数
1.统计ubuntu系统主机数
count(node_os_version{id="ubuntu"})
2.统计集群CPU核心数
count(node_cpu_seconds_total{mode='user'})
2.2 count_values分组统计函数
1.统计不同OS的数量,将node_os_version返回值value分组统计个数,将不同value加个新标签为'yinzhengjie_os_version'。
count_values("yinzhengjie_os_version",node_os_version)
2.统计文件系统大小,将node_filesystem_size_bytes返回值value分组统计个数,将不同value加个新标签为'yinzhengjie_fs_size'。
count_values('yinzhengjie_fs_size',node_filesystem_size_bytes)
2.3 sum,max,min,avg案例
1.统计集群内存总量
sum(node_memory_MemTotal_bytes)/1024/1024/1024
2.计算Prometheus网站访问成功率的百分比
(sum(prometheus_http_requests_total{code=~"2.*|3.*"}) / sum(prometheus_http_requests_total) ) * 100
3.获取最大的值
max(prometheus_http_requests_total)
4.获取最小的值
min(prometheus_http_requests_total)
5.获取平均值
avg(prometheus_http_requests_total)
2.4 topk和bottomk最值案例
1.查看最前面的10个排名数据:
topk(10,prometheus_http_response_size_bytes_bucket)
topk(10,prometheus_http_requests_total)
2.查看最后面的5个排名数据:
bottomk(5,prometheus_http_response_size_bytes_bucket)
bottomk(5,prometheus_http_requests_total)
2.5 分组案例
1.按instance分组统计内存总量
sum(node_memory_MemTotal_bytes) by (instance)
2.统计每个主机CPU的总核心数
count(node_cpu_seconds_total{mode="idle"}) by (instance)
3.按照handler,instance标签分组统计
max(prometheus_http_requests_total) by (handler,instance)
4.仅对mode标签进行分组求和
sum(node_cpu_seconds_total) by (mode)
5.多个分组统计
count(prometheus_http_requests_total) by (code,instance,job)
6.对除了instance和job以外的标签分组求和
sum(prometheus_http_requests_total) without (instance,job)
7.查出200响应码全部占全部请求的百分比
sum(prometheus_http_requests_total{handler=~"/api/v1/l.*",code="200"}/prometheus_http_requests_total{handler=~"/api.*"}) by (handler)
三.PromQL的功能函数
1.功能函数概述
如上图所示,Prometheus官方提供了多个功能函数。
计算相关函数:
- abs(): 绝对值。
- deriv(): 导数。
- exp(): 指数。
- ln(): 对数。
- log2(): 二进制对数。
- log10(): 十进制对数。
- sqrt(): 平方根。
- ceil(): 向上取整。
- floor(): 向下取整。
- round(): 四舍五入。
- idelta(): 样本差。
- delta(): 差值。
- increase(): 递增值。
- resets(): 重置次数。
- irate(): 递增率。
- rate(): 变化率。
- holt_winters(): 平滑值,Prometheus 3.X更名为"double_exponential_smoothing"。
- histogram_quantile(): 直方百分比。
- predict_linear(): 预测值。
- vector(): 参数。
- min_over_time(): 范围最小值。
- max_over_time(): 范围最大值。
- avg_over_time(): 范围平均值。
- sum_over_time(): 范围求和值。
- count_voer_time(): 范围计数值。
- quantile_over_time(): 范围分位数。
- stddev_over_time(): 范围标准差。
- stdvar_over_time(): 范围方差。
- last_over_time(): 指定间隔内的最新点值。
- present_over_time(): 指定间隔内任何系列的值。
- sgn(): 如果整数返回1,负数返回-1,0则返回0。
- histogram_avg(): 返回存储在本地直方图中的观测值的算术平均值。
- histogram_count(): 返回存储在本地直方图中的观测值计数
- histogram_sum(): 返回存储在本地直方图中的观测值之和
- histogram_fraction(): 返回所提供的上下限值之间的估计观测分数
- histogram_stddev(): 基于观测值所在的桶的几何平均值,返回本地直方图中观测值的估计标准偏差。
- histogram_stdvar(): 返回本地直方图中观测值的估计标准方差。
取样相关函数:
- absent(): 获取样本。
- sort(): 升序。
- sort_desc(): 降序。
- sort_by_label(): 基于标签的升序。
- sort_by_label_desc(): 基于标签的降序。
- changes(): 变化数。
- scalar(): 即使数据转换为标量。
- clamp(): 选取一个范围值。
- clamp_max(): 判断大。
- clamp_min(): 判断小。
- absent_over_time(): 范围采样值。
时间相关函数:
- day_of_month()
- day_of_week()
- day_of_year()
- days_in_month()
- hour()
- minute()
- month()
- time()
- timestamp()
- year()
标签相关函数:
- label_join(): 合并标签。
- label_replace(): 标签替换。
其他函数:
- info() (experimental)
- Limitations
2.计算相关函数案例
2.1 取整
1.向上取整
ceil(node_load15{instance=~"10.0.0.4.*:9100"} * 10)
2.向下取整
floor(node_load15{instance=~"10.0.0.4.*:9100"} * 10)
3.四舍五入
round(node_load15{instance=~"10.0.0.4.*:9100"} * 10)
2.2 统计CPU使用率
1.查询核心数编号为'0'的CPU最近1分钟空闲状态时间
increase(node_cpu_seconds_total{cpu="0",mode="idle"}[1m])
2.查看集群各节点CPU利用率
(1- sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) /sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100
2.3 rate和irate统计变化率
1.查看过去一分钟每次磁盘读的变化率
rate(node_disk_read_bytes_total[1m])
2.一分钟内网卡传输的字节数(换算为MB)
rate(node_network_transmit_bytes_total{device="eth0"}[1m])/1024/1024
3.判断在过去5分钟内HTTP请求状态码以'5'开头的请求速率是否大于所有HTTP请求速率的10%
(1-avg(irate(prometheus_http_requests_total{code=~"5.*"}[5m])) by (instance)) * 100
4.每台主机CPU在5分钟内的平均使用率
(1 -avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)) * 100
5.查看5分钟内最多的增长率
irate(node_cpu_seconds_total{instance="10.0.0.42:9100",mode="idle"}[5m])
6.查看1m内访问"/-/ready"状态码为200的变化率【写个脚本访问'http://10.0.0.31:9090/-/ready'】
irate(prometheus_http_requests_total{code="200",handler="/-/ready",job="prometheus"}[1m])
温馨提示:
irate和rate都可以用于计算某个指标在一定时间间隔内的变化速率,但是他们的计算方法有所不同。
- irate:
取得是在指定时间范围内的最近两个数据点来算速率。
- rate:
取得是指定时间范围内所有的数据点,算出一组速率,然后取平均值作为结果。
综上所述,官方建议irate适合快速变化的计数器,而rate适合缓慢变化的计数器。
2.4 without和by过滤标签
1.使用without去掉标签
sum without(code) (rate(prometheus_http_requests_total[10m]))
sum without(code,handler) (rate(prometheus_http_requests_total[10m]))
2.使用by保留标签
sum by(code) (rate(prometheus_http_requests_total[10m]))
2.5 查看分位置
1.histogram_quantile可以查看分位置,比如查看9999的分位置:
histogram_quantile(0.9999,sum(rate(prometheus_http_request_duration_seconds_bucket[5m])) by (le))
2.计算过去10m内请求持续时间的第90个百分位数
histogram_quantile(0.9,rate(prometheus_http_request_duration_seconds_bucket[10m]))
2.6 offset查看数据偏移量
- 查看5分钟内的QPS总量:
sum(rate(prometheus_http_requests_total[5m]))
- 查看2小时前,5分钟内的QPS总量:
sum(rate(prometheus_http_requests_total[5m] offset 2h))
- 查看最近2小时内数据的增量:
sum(rate(prometheus_http_requests_total[5m])) - sum(rate(prometheus_http_requests_total[5m] offset 2h))
3.取样相关函数
3.1 absent报警
absent的返回值为1时表示查询的数据为空,此时absent返回空,则说明查询到了数据。
有值返回空,无值返回1,可用于告警判断。
举个例子:
- absent(yinzhengjie)
返回值为1,表示查询的结果为空,就会触发报警。
- absent(sum(rate(prometheus_http_requests_total[5m])))
返回值如果为空,则说明查询到数据,因此不会触发报警。
3.2 scalar转换标量
Scalar函数返回的类型就是标量,即一个简单的数字浮点值。在做一些数值运算时很有用。
scalar(sum(node_memory_MemTotal_bytes{instance="10.0.0.31:9100",job="yinzhengjie_bigdata_exporter"})/1024/1024/1024)
4.时间相关函数
4.1 统计一小时内Prometheus网站访问的时间总和
sum_over_time(prometheus_http_requests_total[1h])
4.2 计算当前每个主机的运行时间
(time() - node_boot_time_seconds)/3600
4.3 计算所有主机的总运行时间
sum((time() - node_boot_time_seconds))/3600
5.推荐阅读
参考链接:
https://prometheus.io/docs/prometheus/latest/querying/functions/
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/18799074,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号