

Prometheus基础架构,环境部署及数据类型概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
目录
一.Prometheus概述
1.Prometheus基础架构
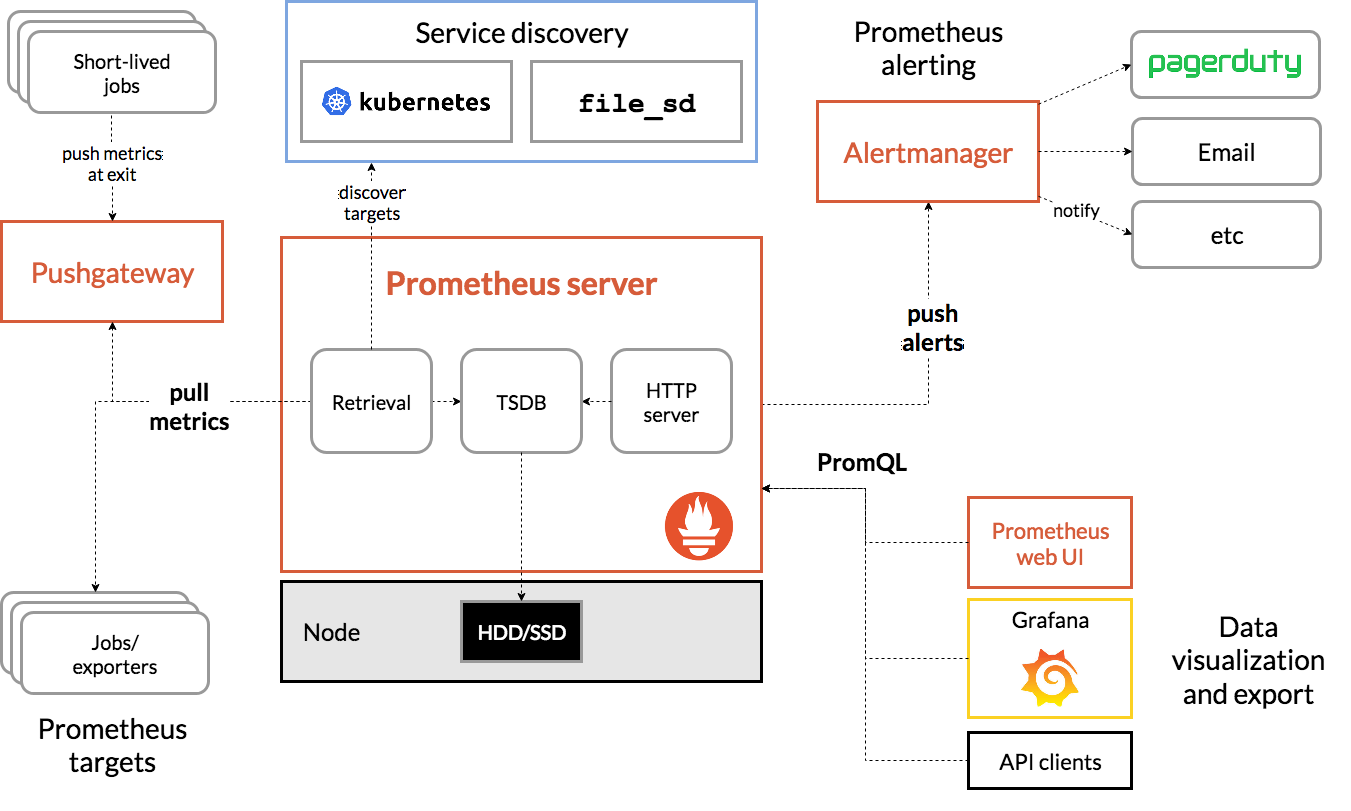
- Prometheus的官网地址:
https://prometheus.io/
- 无论是官方还是社区大佬都在研究Prometheus系统:
https://prometheus.io/docs/instrumenting/exporters/
- 很多系统集成了Prometheus的SDK:
https://prometheus.io/docs/instrumenting/exporters/#software-exposing-prometheus-metrics
- ranking数据库排名:(2024年能排进前50,2020年甚至能排进前3)
https://db-engines.com/en/ranking
2.Prometheus的优缺点
学习Prometheus优点:
- Prometheus有丰富的promQL实时查询聚合引擎;
- 单机千万级别并发写入的QPS;
- kubernetes监控的不二选择;
- Prometheus可以被各种SDK集成;
- 学习Prometheus目前也是云原生高薪的必备技能;
Prometheus面临的问题:
- 如何实现存储的高可用性;
- 如何实现高基数查询延迟和资源开销高的问题;
- 如何实现采集端exporters的批量管理;
- 如何实现长期查询降低采样以节省成本;
- 如何实现配置文件操作繁琐的配置;
3.Prometheus学习目标
- 第一梯队: 熟悉Prometheus及其生态圈内组件的使用,配置调优;
1.可以熟练配置采集常见的对象,比如: docker,K8S,Ceph,ElasticStack生态及常见的中间件监控。
2.熟练编写PromQL查询和告警表达式,熟练运用各种函数;
3.alertmanager路由和分组配置;
4.使用"预聚合"手段对"重查询"提速;
- 第二梯队: 能够发现单点问题并有高可用解决方案;
1.采集端高可用性;
2.存储的高可用性;
3.查询告警高可用性;
- 第三梯队: 对时序监控底层原理的理解有较深理解;
1.倒排索引;
2.时序数据压缩算法;
3.数据聚合的实现;
4.底层原理针对:采集,传输,存储,查询,告警,优化等维度。
- 第四梯度: 可以进行二次开发或者使用Go开发周边项目以集成Prometheus到对应SDK;
1.研发exporters管理平台;
2.结合CMDB产品,监控和服务树整合的平台;
3.监控链路配置平台;
温馨提示:
"运维同学"侧重前三个阶段教学,第四阶段适合"运维开发同学"后期拔高,因为需要学员有Golang基础。
二.部署Prometheus环境
1.部署Prometheus server
推荐阅读:
https://www.cnblogs.com/yinzhengjie/p/18426199
2.部署node_exporter
推荐阅读:
https://www.cnblogs.com/yinzhengjie/p/18432546
三.Prometheus的基本概念
1.Prometheus指标概述
1.1 Metrics指标组成部分
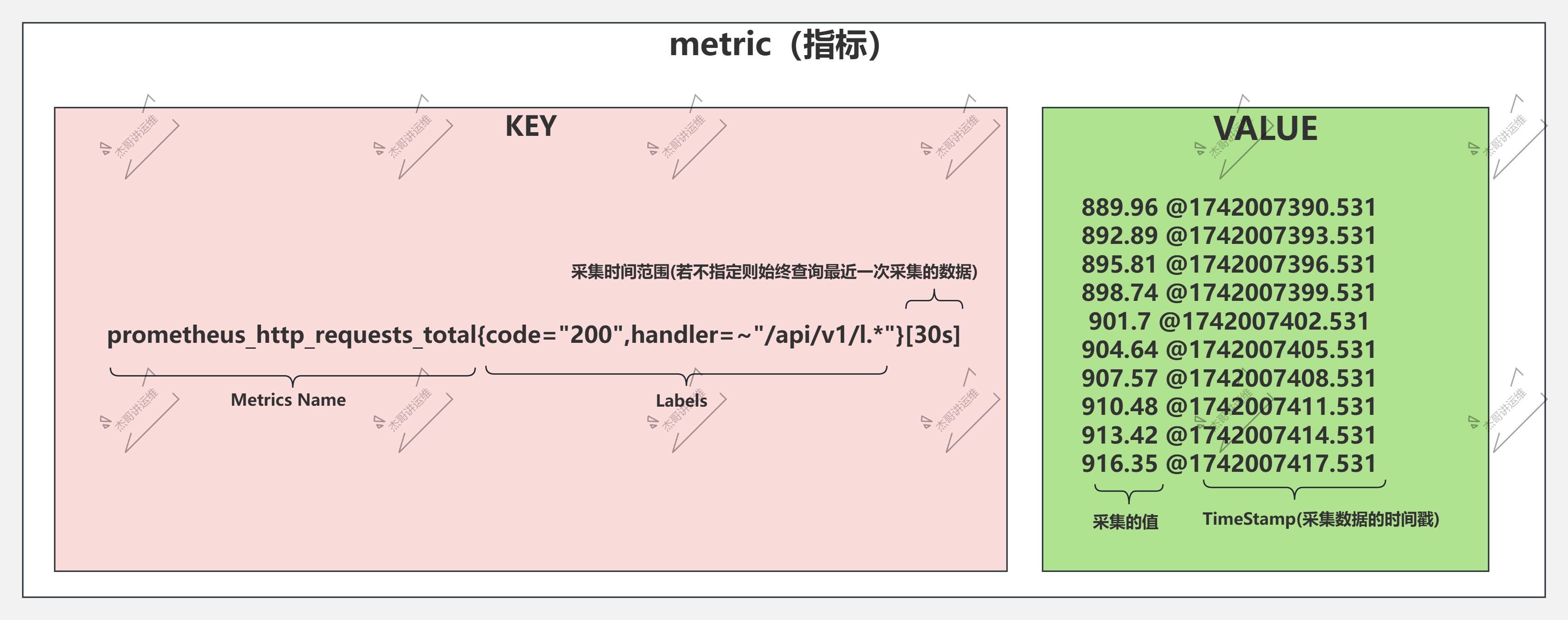
如上图所示,Prometheus的每个数据样本由两部分组成,即KEY和VALUE。
KEY:
大致包含metrics名称,Labeles,时间范围。
VALUE:
float64格式的数据及采集时的时间戳。
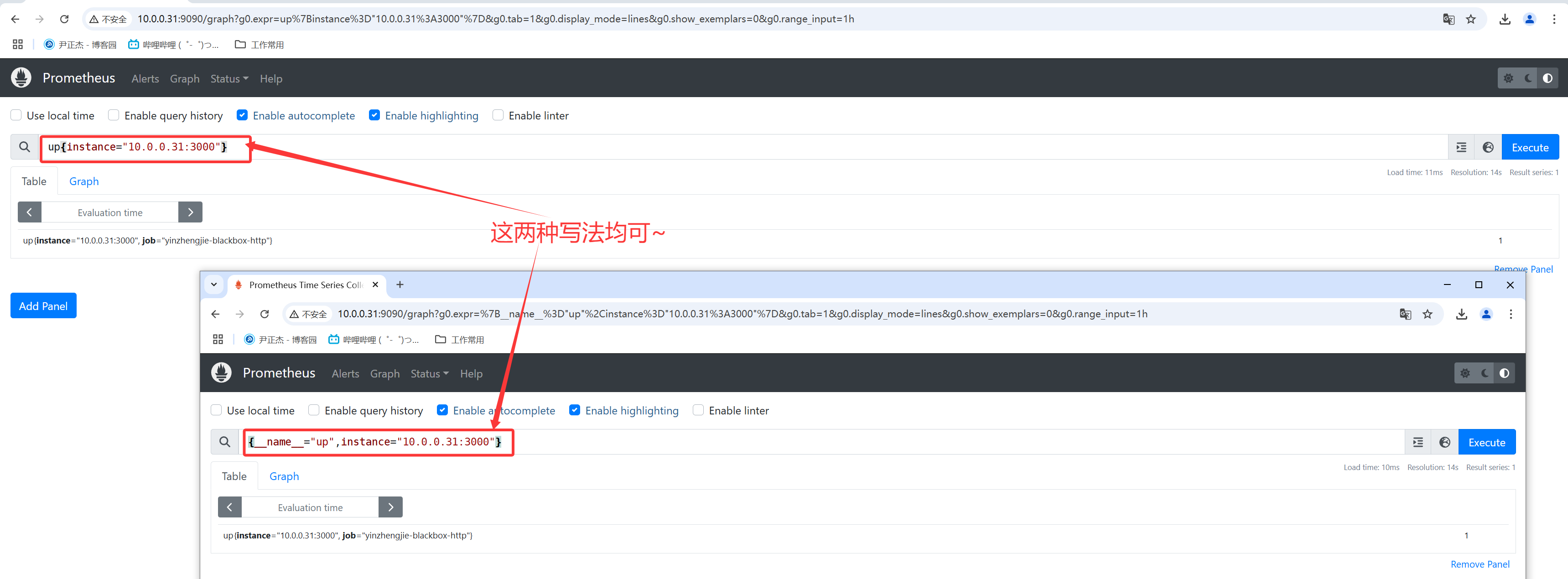
如下图所示,我们在写语句时,对于指标的命名可以使用"__name__"内置标签来指定。
up{instance="10.0.0.31:3000"}
{__name__="up",instance="10.0.0.31:3000"}
大多数情况下,我是不推荐使用"__name__"指定的,除非你的指标名称有多个匹配查询的场景,如下所示:
{__name__=~"node_cpu_.*", job="yinzhengjie-node-exporter"}
1.2 sample数据点
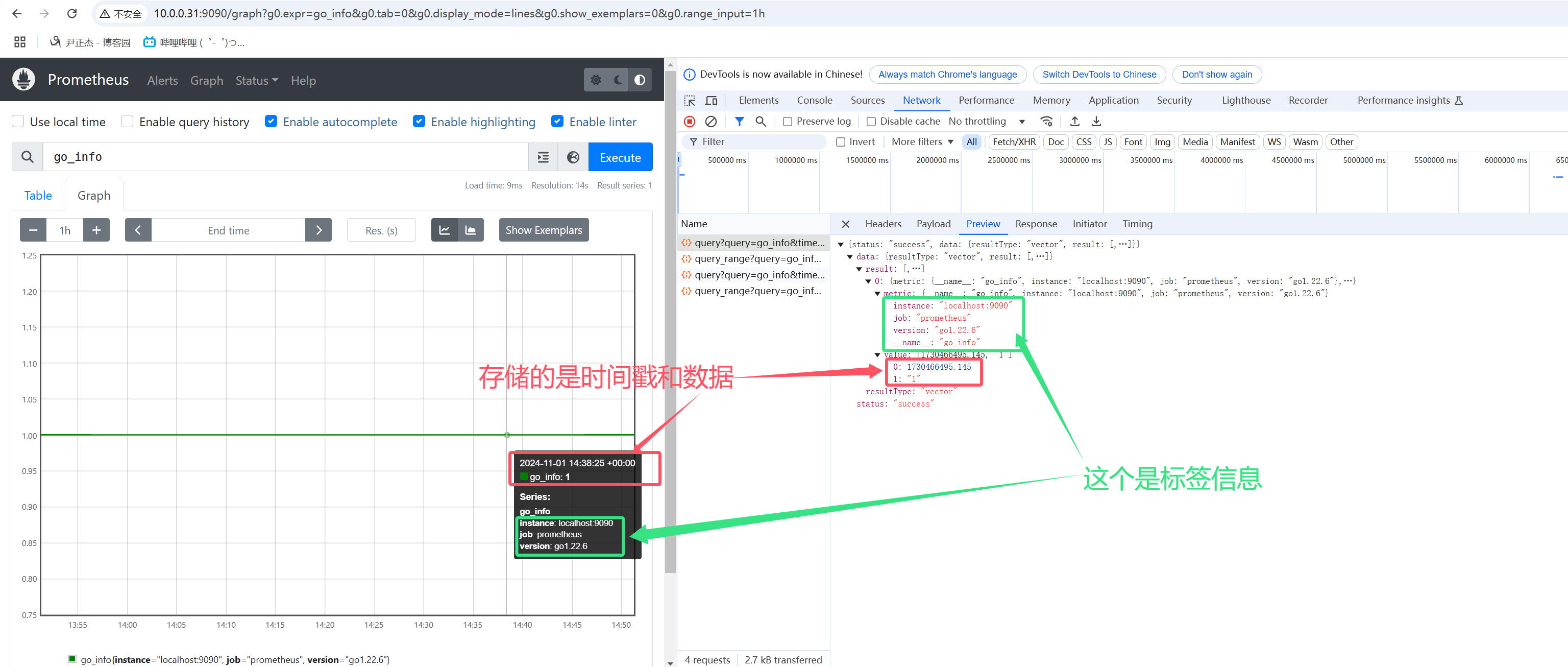
Sample代表的是一个数据点,这个数据点内置了Point,里面存储的信息包含时间戳,数值及标签信息。
如上图所示,表示1个Sample数据点的案例,而下图表示的是5个Sample数据点的案例。
Golang源代码参考如下:
// github.com/prometheus/prometheus/pkg/labels/labels.go
type Label struct {
Name,Value string
}
// github.com/prometheus/prometheus/pkg/labels/labels.go
type Lables []Label
// github.com/prometheus/prometheus/promql/value.go
type Point struc {
T int64
V float64
}
// github.com/prometheus/prometheus/promql/value.go
type Sample struc {
Point
Metric labels.Labels
}
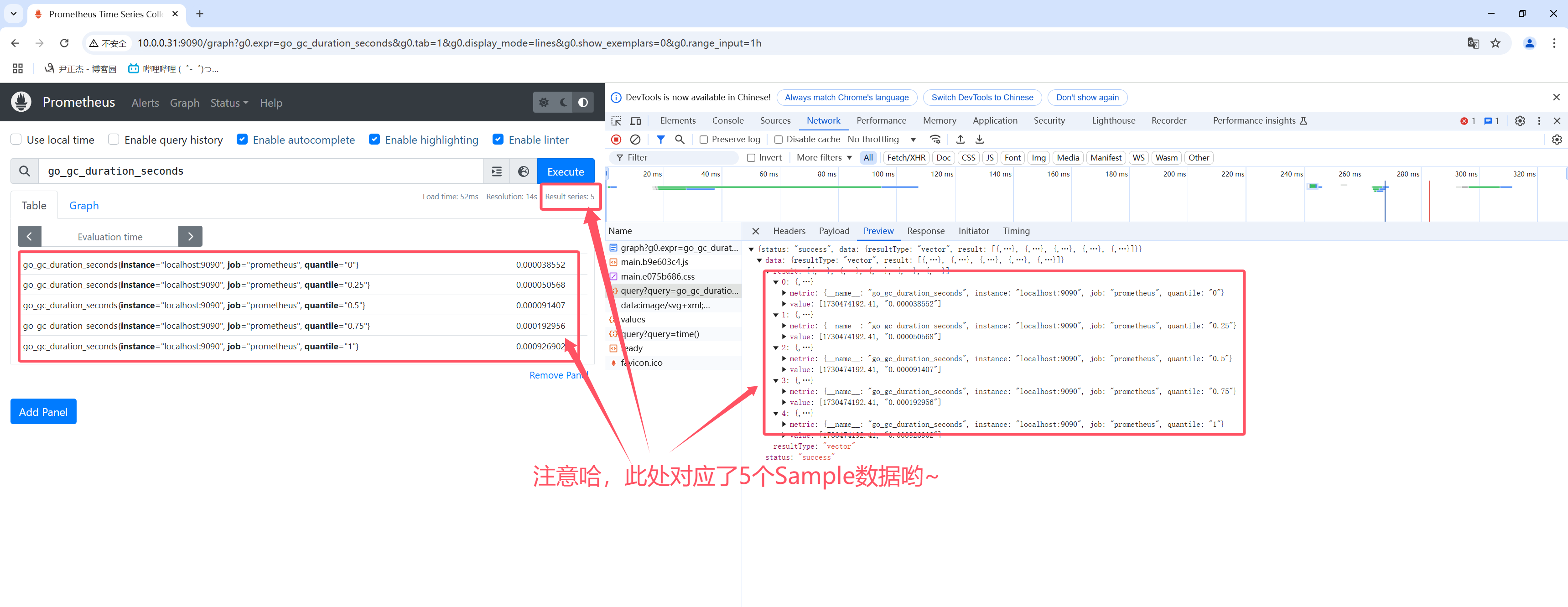
2.Prometheus四种查询类型
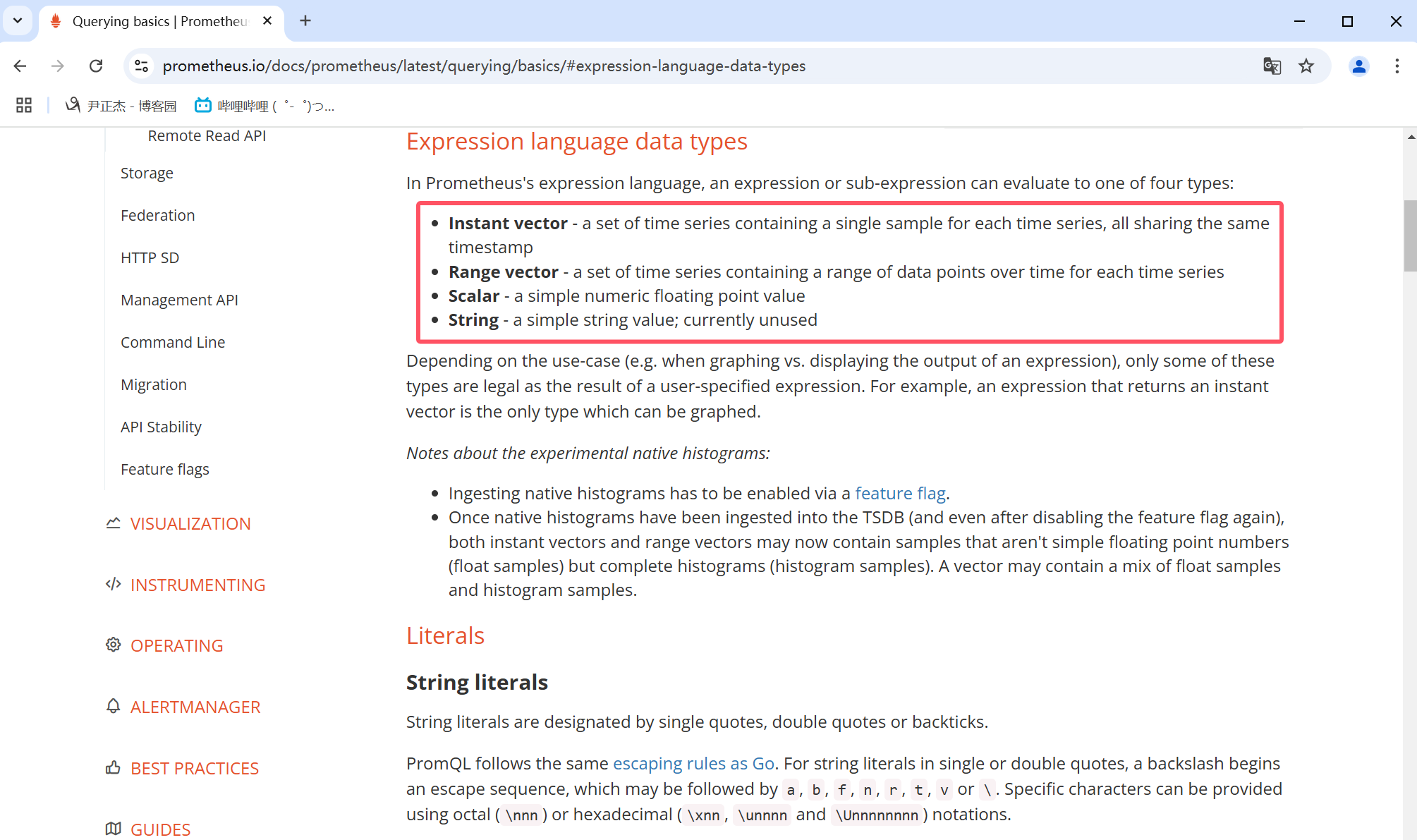
如上图所示,官方提供了四种查询类型
- Instant vector(即时向量):
一组时间序列,包含每个时间序列的单个样本,所有样本共享相同的时间戳,表示一个时刻的结果。
- Range vector(范围向量):
一组时间序列,包含每个时间序列随时间变化的数据点范围,表示一段时间的结果。
- Scalar(标量)
一个简单的数字浮点值。
- String(字符串)
一个简单的字符串值;当前未使用
参考地址:
https://prometheus.io/docs/prometheus/latest/querying/basics/#expression-language-data-types
2.1 Instant vector(即时向量,一个时刻的结果)
Instant vector(即时向量):
一组时间序列,包含每个时间序列的单个样本,所有样本共享相同的时间戳,表示一个时刻的结果。
Instant vector概要:
- 1.vector向量源码位置:
// github.com/prometheus/prometheus/promql/value.go
type Vector []Sample
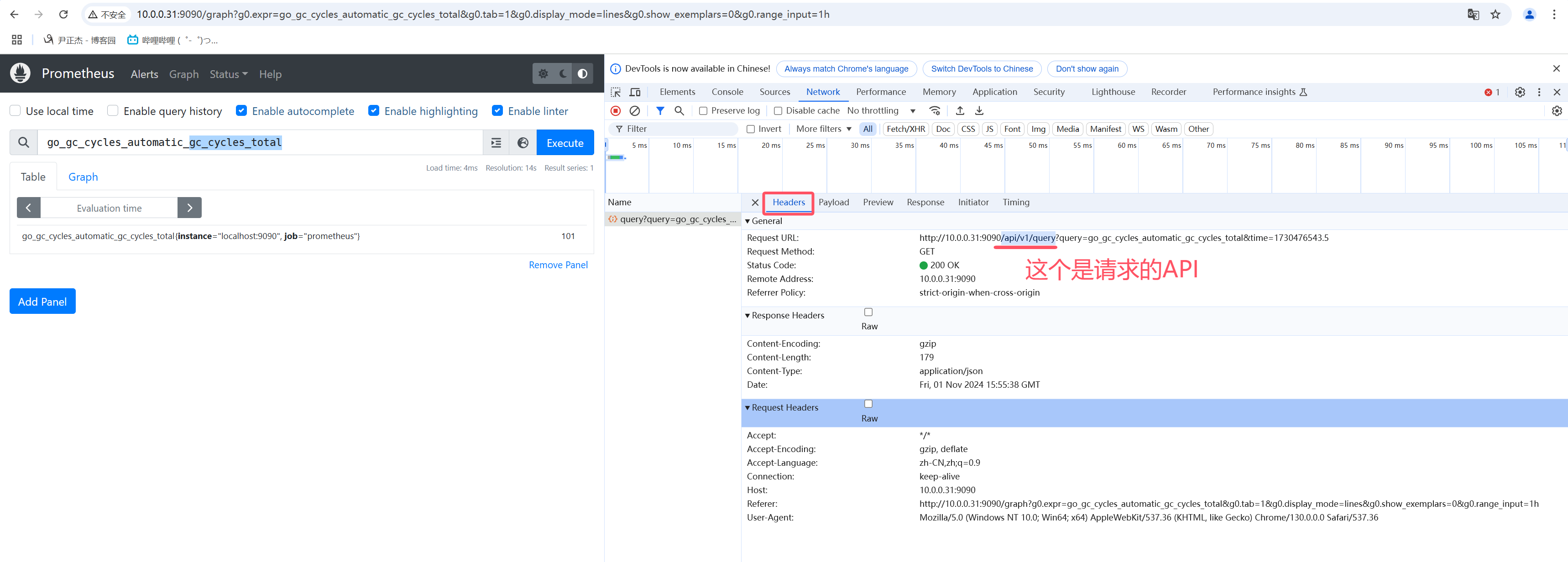
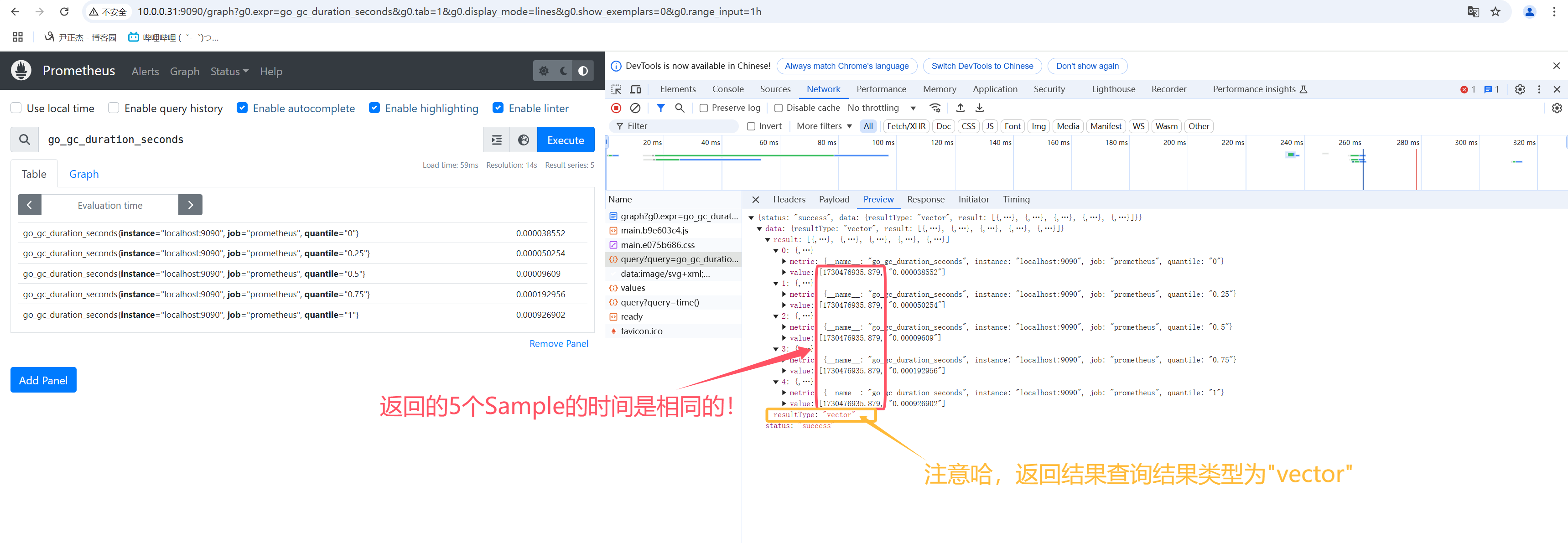
- 2.vector向量是Sample的别名,但是所有Sample具有相同timetamp,常用做instant_query的结果;
- 3.如上图所示,在Prometheus的WebUI上table查询,对应查询接口是"/api/v1/query"
- 4.如下图所示,在Prometheus的WebUI上返回值的类型(resultType)是: "vector"
测试案例:
[root@prometheus-server31 ~]# curl -d 'query=go_gc_cycles_automatic_gc_cycles_total' --data time=`date +%s` http://10.0.0.31:9090/api/v1/query;echo
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"go_gc_cycles_automatic_gc_cycles_total","instance":"localhost:9090","job":"prometheus"},"value":[1742009360,"48"]}]}}
[root@prometheus-server31 ~]#
2.2 Range vector(范围向量,一段时间的结果)
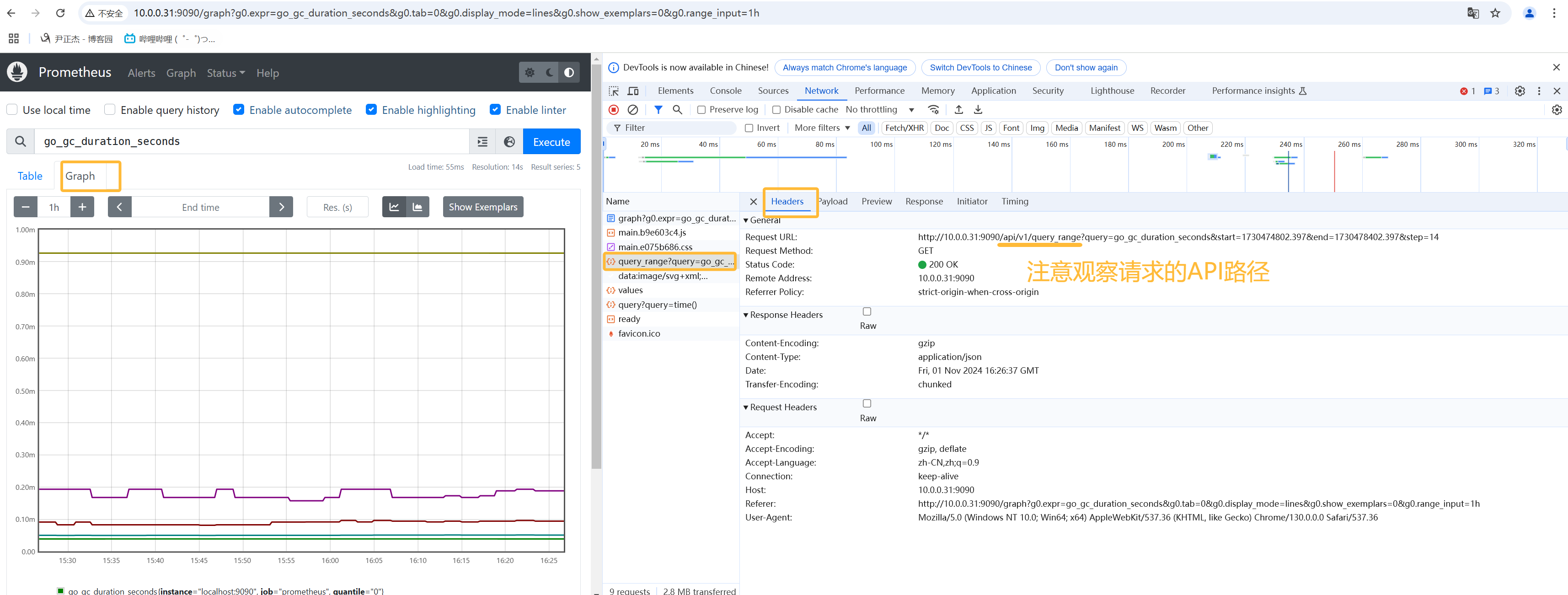
Range vector(范围向量):
一组时间序列,包含每个时间序列随时间变化的数据点范围,表示一段时间的结果。
Range vector(范围向量)概要:
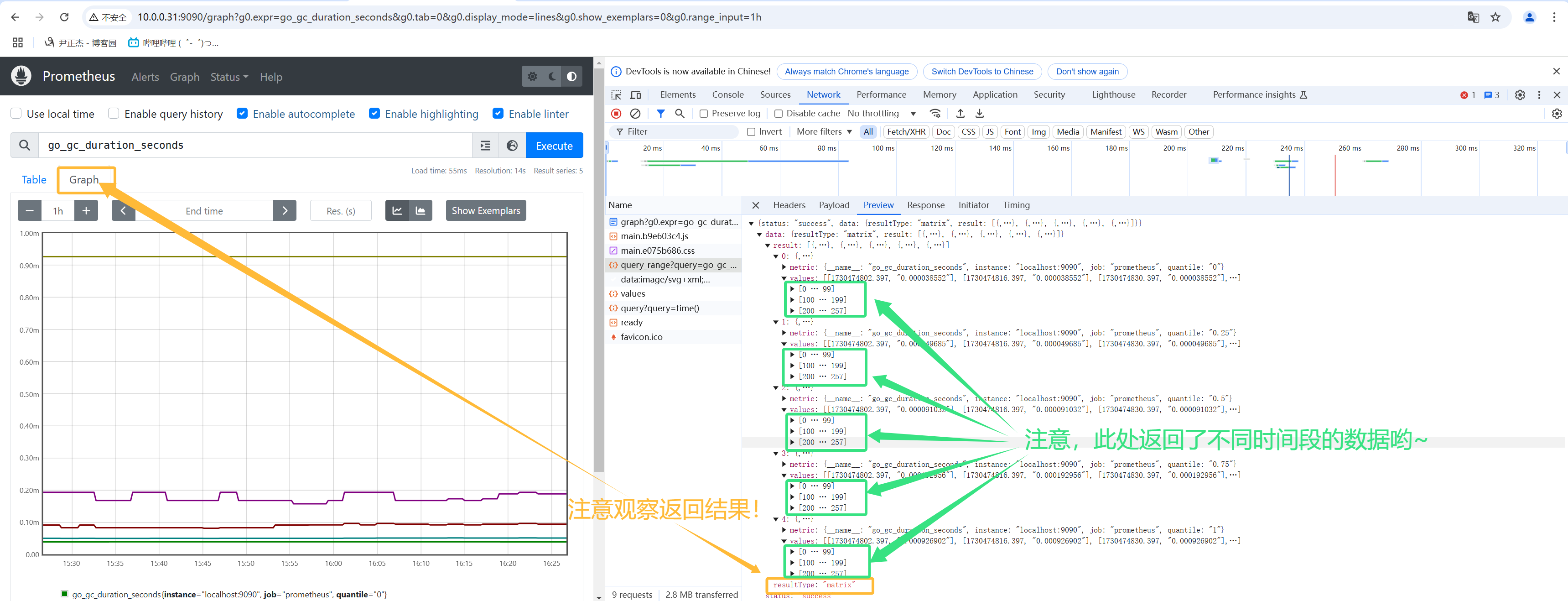
- 1.如上图所示,在Prometheus页面上就是graph查询,对应查询接口是"/api/v1/query_range";
- 2.如下图所示,返回的结果就是Matrix矩阵;
- 3.Matrix是Series的切片,源码位置:
// github.com/prometheus/prometheus/promql/value.go
type Matrix []Series
- 4.Series是标签组和Points的组合,源码位置:
// github.com/prometheus/prometheus/promql/value.go
type Series struct {
Metric []Lables.Labels `json:"metric"`
Points []Point `json:"values"`
}
测试案例:
[root@prometheus-server31 ~]# curl -d 'query=node_cpu_seconds_total{ instance!~"10.0.0.(31|42|43):9100",mode="idle",job="yinzhengjie_bigdata_exporter"}[30s]' --data time=`date +%s` http://10.0.0.31:9090/api/v1/query;echo
{"status":"success","data":{"resultType":"matrix","result":[{"metric":{"__name__":"node_cpu_seconds_total","cpu":"0","instance":"10.0.0.41:9100","job":"yinzhengjie_bigdata_exporter","mode":"idle"},"values":[[1742010103.299,"3582.8"],[1742010106.299,"3585.78"],[1742010109.299,"3588.76"],[1742010112.299,"3591.73"],[1742010115.299,"3594.71"],[1742010118.301,"3597.68"],[1742010121.299,"3600.66"],[1742010124.299,"3603.62"],[1742010127.299,"3606.58"],[1742010130.299,"3609.54"]]},{"metric":{"__name__":"node_cpu_seconds_total","cpu":"1","instance":"10.0.0.41:9100","job":"yinzhengjie_bigdata_exporter","mode":"idle"},"values":[[1742010103.299,"3588.88"],[1742010106.299,"3591.85"],[1742010109.299,"3594.82"],[1742010112.299,"3597.8"],[1742010115.299,"3600.77"],[1742010118.301,"3603.74"],[1742010121.299,"3606.71"],[1742010124.299,"3609.69"],[1742010127.299,"3612.68"],[1742010130.299,"3615.68"]]}]}}
[root@prometheus-server31 ~]#
2.3 Scalar(标量,浮点数应用场景)
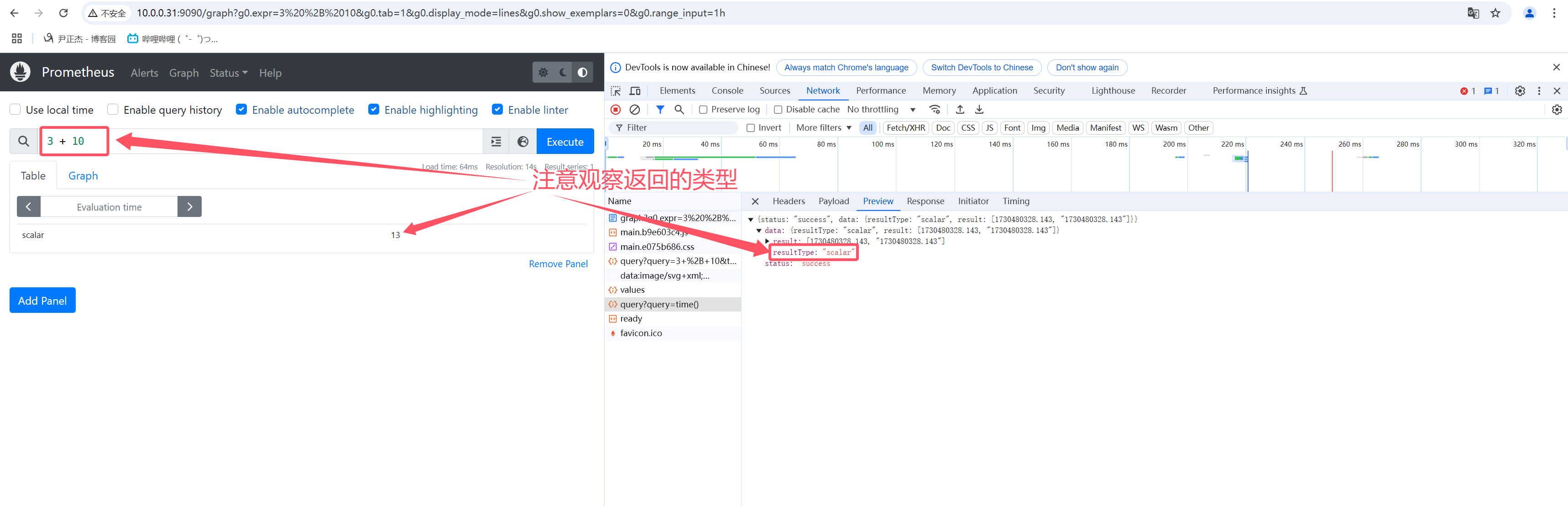
Scalar(标量):
一个简单的数字浮点值。
如上图所示,在做一些数值运算时,返回的类型就是Scalar了哟~
测试案例:
[root@prometheus-server31 ~]# curl -d 'query=scalar(sum(node_memory_MemTotal_bytes{instance="10.0.0.31:9100",job="yinzhengjie_bigdata_exporter"})/1024/1024/1024)' --data time=`date +%s` http://10.0.0.31:9090/api/v1/query;echo
{"status":"success","data":{"resultType":"scalar","result":[1742010451,"3.7850265502929688"]}}
[root@prometheus-server31 ~]#
2.4 String(字符串)
String(字符串)
一个简单的字符串值;当前未使用
3.Prometheus四种标签匹配模式
3.1 等于
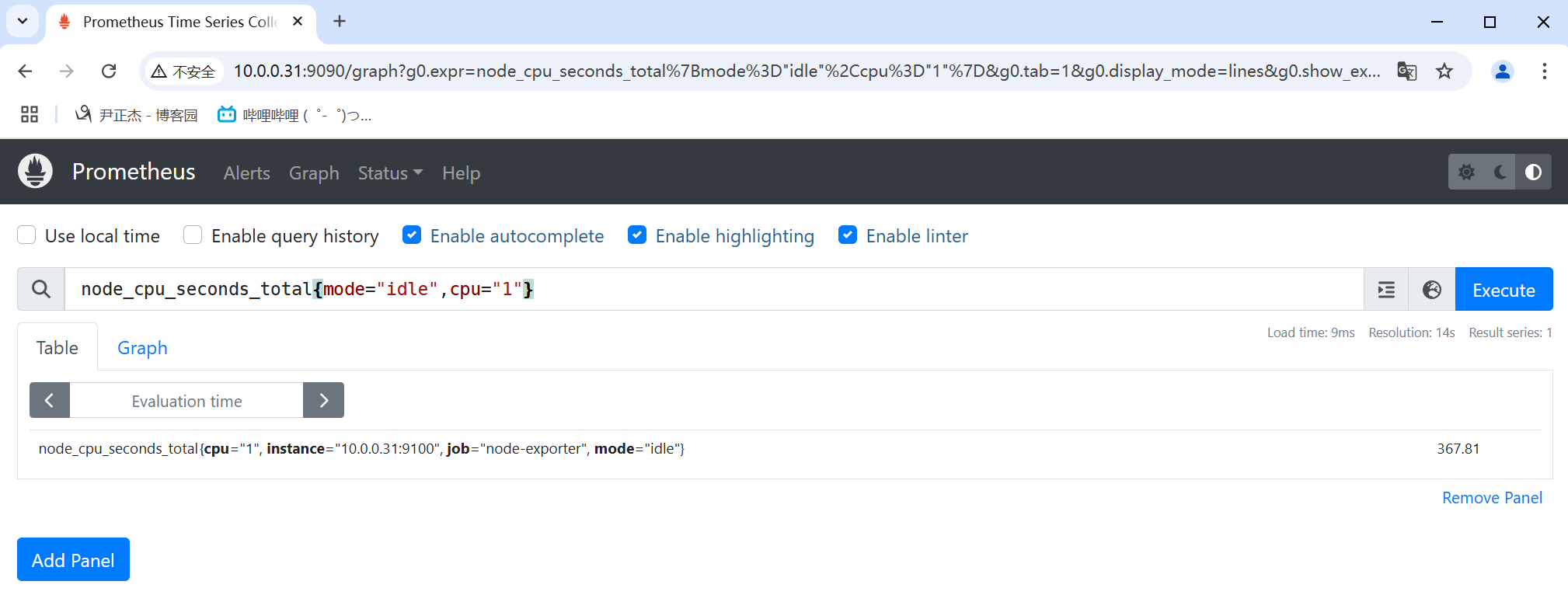
等于的关系使用"="表示。
举个例子:
node_cpu_seconds_total{mode="idle",cpu="1"}
3.2 不等于
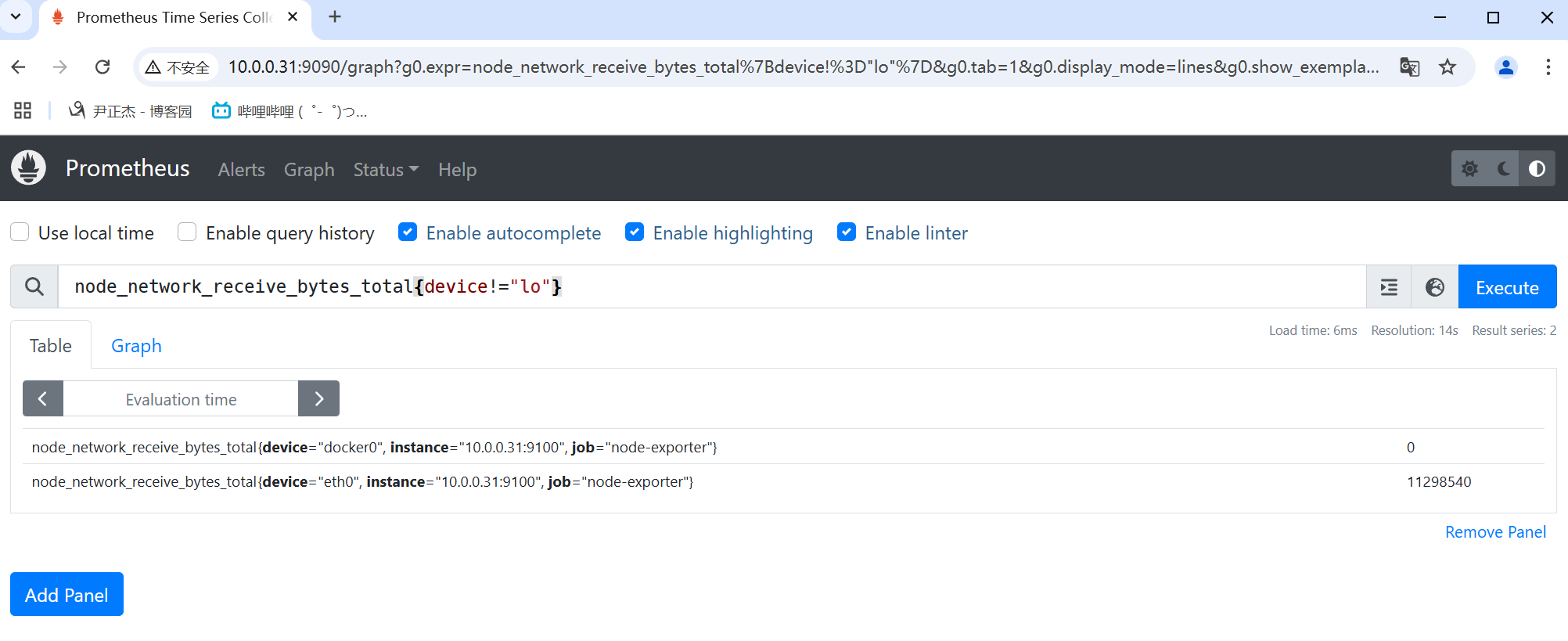
不等于使用"!="表示。
举个例子:
- node_network_receive_bytes_total{device!="lo"}
- prometheus_http_requests_total{code!="200"}
3.3 正则匹配
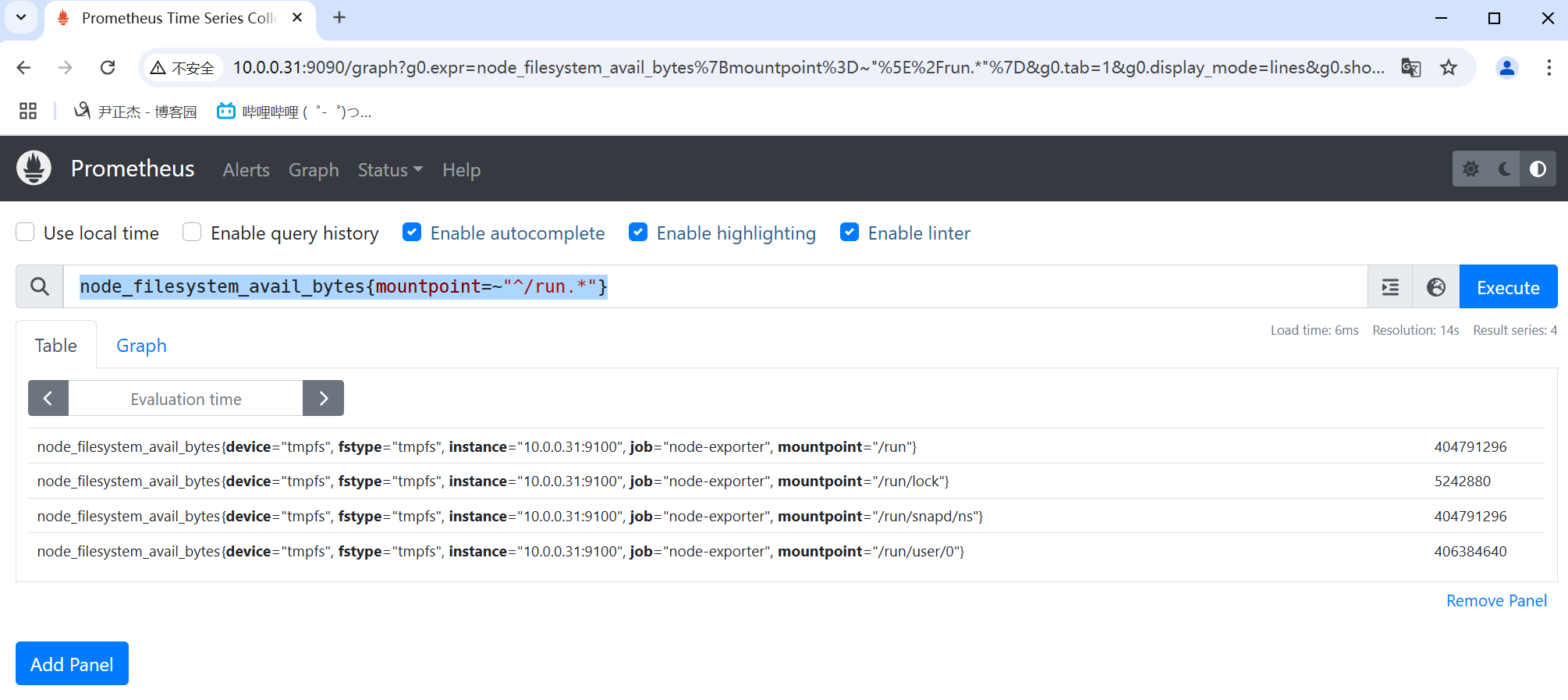
正则匹配使用"=~"表示。其中"__name__"也是个标签,可以匹配metrics。
举个例子:
- node_filesystem_avail_bytes{mountpoint=~"^/run.*"}
- prometheus_http_requests_total{handler=~"^/api.*"}
- {__name__=~"prometheus_engine.*",quantile=~".*0.*"}
4.4 正则非匹配
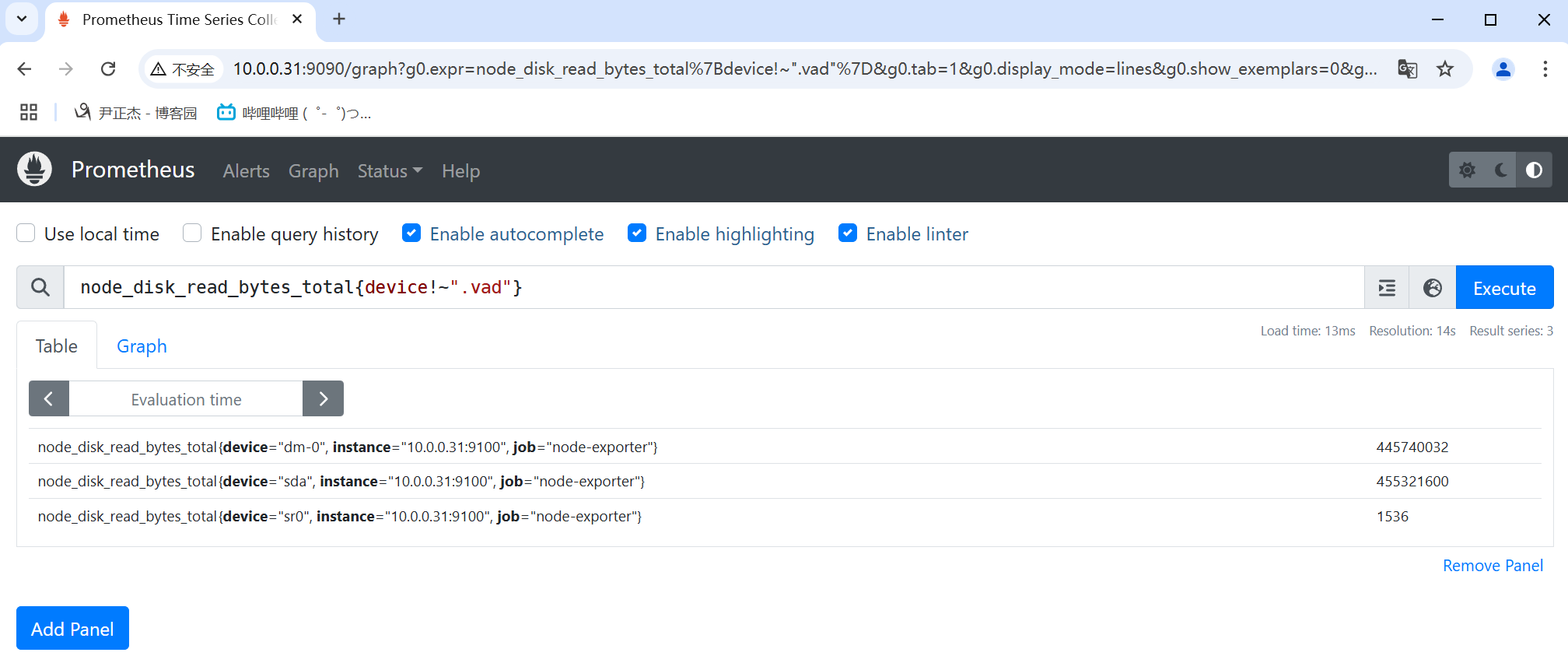
正则非匹配使用"!~"表示。
举个例子:
- node_disk_read_bytes_total{device!~".vad"}
- prometheus_http_requests_total{code!=".*00"}
4.Prometheus的四种数据类型
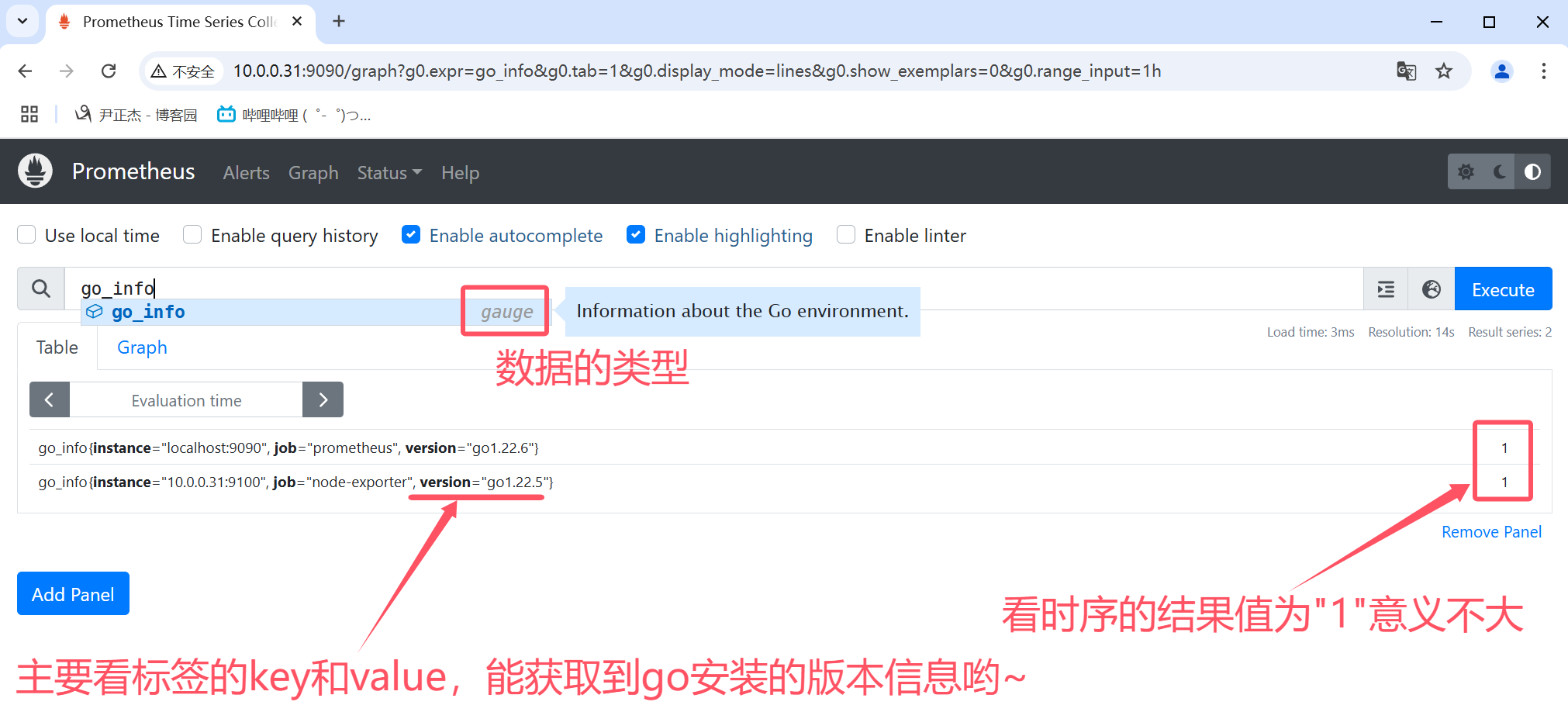
4.1 gauge
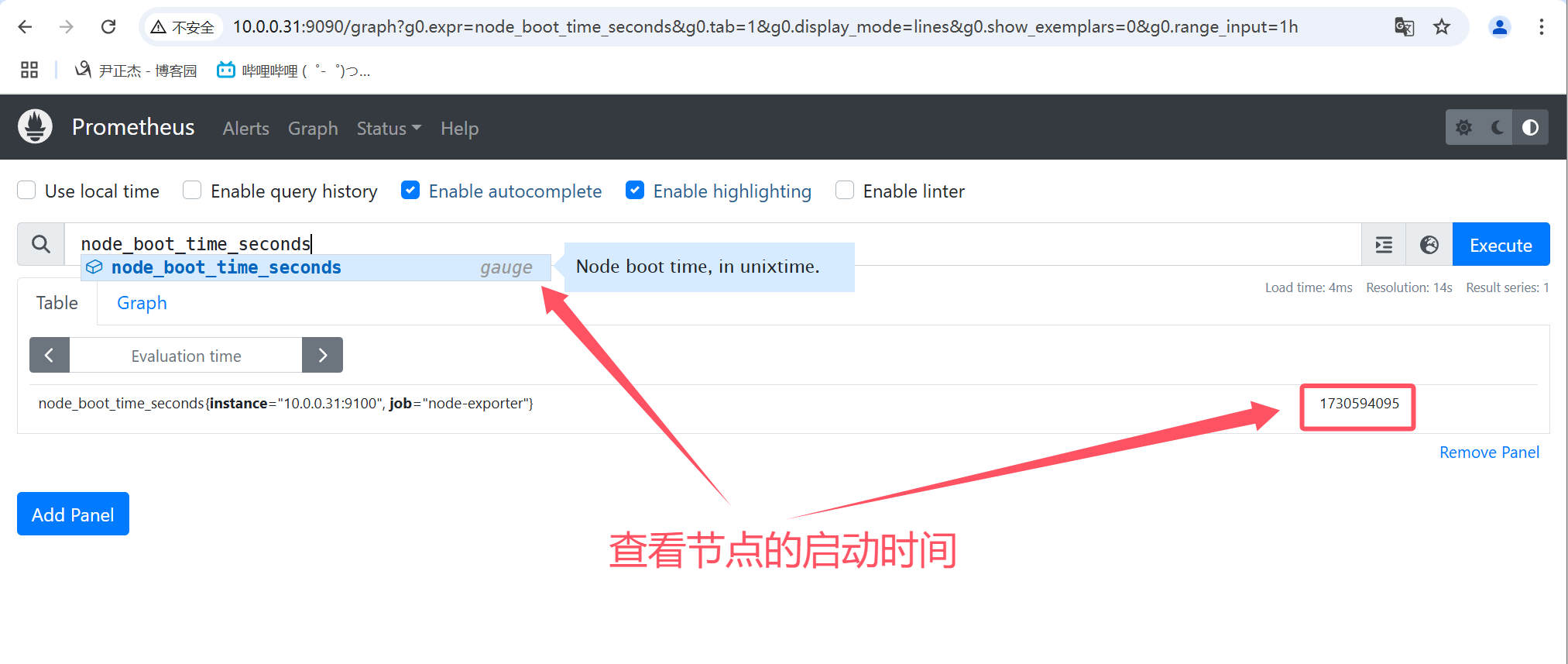
gauge数据类型表示当前的值,是一种所见即所得的情况。
如上图所示,使用"node_boot_time_seconds"指标查看节点的启动时间,表示的是当前值。
如下图所示,使用"go_info"指标查看go的版本信息,其返回值意义不大,这个时候标签的KEY和VALUE就能获取到我们想要的信息。
4.2 counter
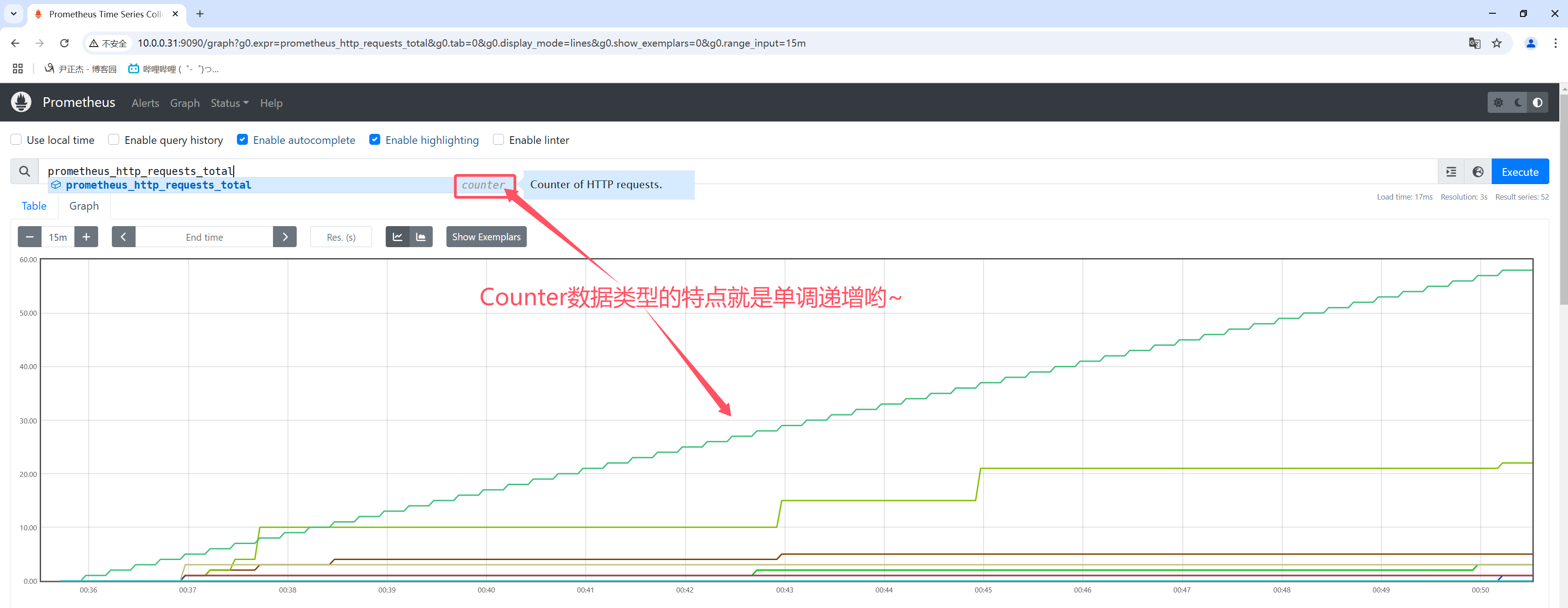
counter数据类型表示一个指标单调递增的计数器。
一般可以结合rate查看QPS,比如: rate(prometheus_http_requests_total[1m])
也可以结合increase查看增量,比如: increase(prometheus_http_requests_total[1m])
查询平均访问时间:
prometheus_http_request_duration_seconds_sum / prometheus_http_request_duration_seconds_count
4.3 histogram
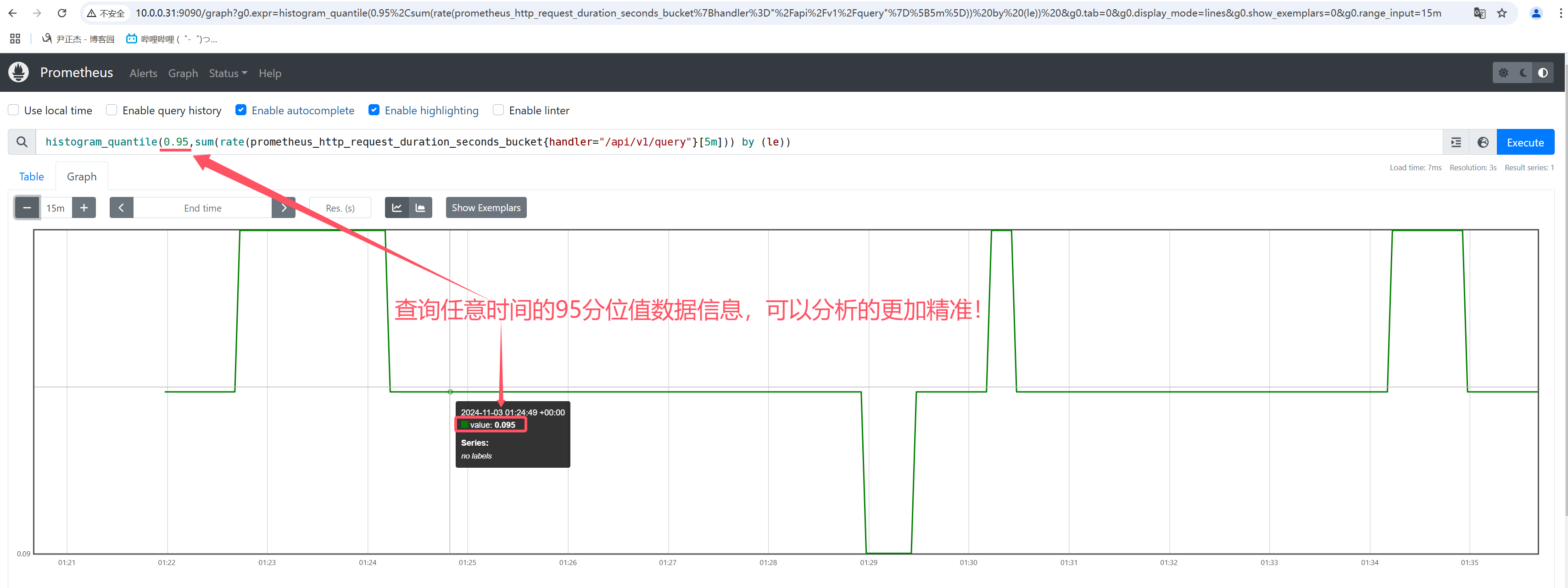
histogram数据类型表示直方图样本观测,通常用于查询"所有观察值的总和","请求持续时间","响应时间"等场景。
上一个案例中,我们可以使用"prometheus_http_request_duration_seconds_sum / prometheus_http_request_duration_seconds_count"查询平均访问时间。
但这种统计方式比较粗糙,用"请求的响应时间/请求的次数",算的是平均响应时间,并不能反应在某个时间段内是否有故障,比如在"12:30~12:35"之间出现大面积服务无法响应,其他时间段都是正常提供服务的,最终使用上面的公式算出来的是没有延迟的,因为5分钟的微小延迟在24小时内平均下来的话可能就可以忽略了,从而运维人员就无法及时发现问题并处理,这对于用户体验是比较差的。
因此Prometheus可以使用histogram数据类型可以采用分位值的方式随机采样短时间范围内的数据,从而及时发现问题,这需要配合histogram_quantile函数来使用。
举个例子: HTTP请求的延迟柱状图(下面的"0.95"表示的是分位值,你可以根据需求自行修改即可。)
histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket[1m])) by (le))
histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket{handler="/api/v1/query"}[5m])) by (le))
输出格式请参考:
https://www.cnblogs.com/yinzhengjie/p/18522782#二-histogram数据说明
4.4 summary
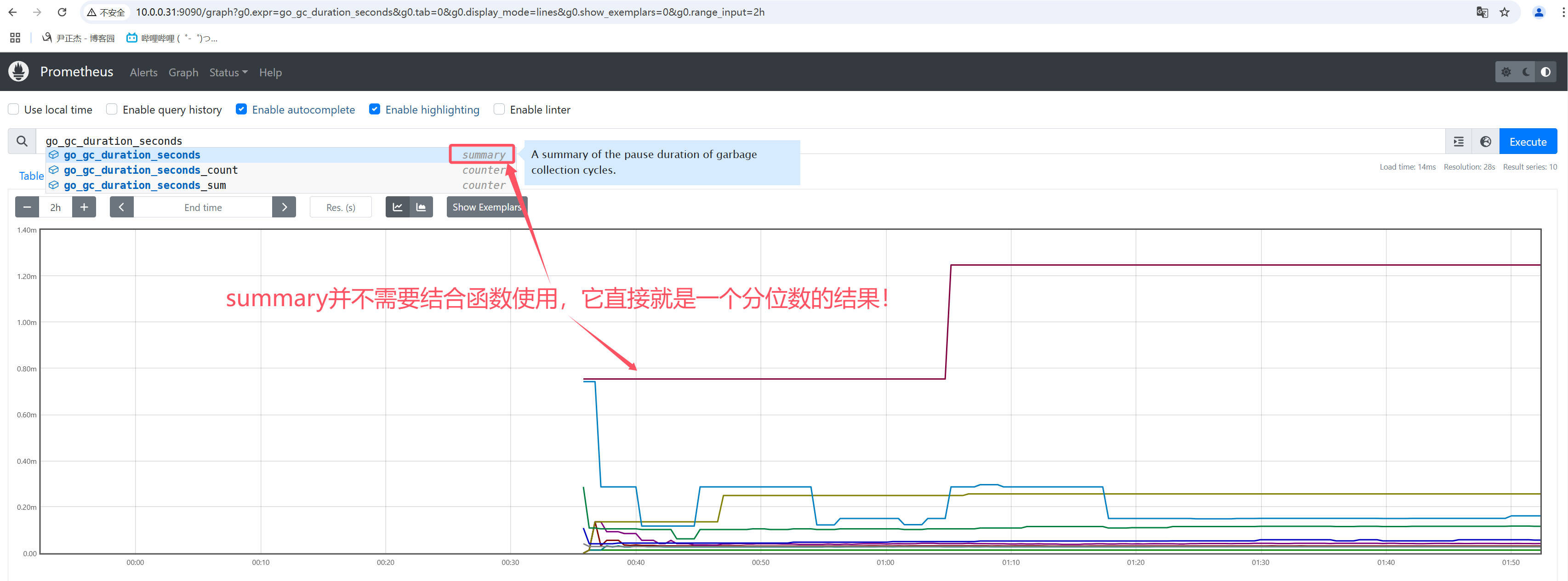
相比于histogram需要结合histogram_quantile函数进行实时计算结果,summary数据类型的数据是分值值的一个结果。
输出格式请参考:
https://www.cnblogs.com/yinzhengjie/p/18522782#三-summary数据说明
4.5 分位值sumary和histogram对比
4.5.1 什么是分位值
- 1.什么是分位值
分位值是随机变量的特征数之一。将随机变量分布曲线与X轴包围的面积作N等分,得N—1个值(X_1、X_2……X_(N-1)),这些值称为N分位值。
分位值(数)在统计学中也有很多应用,比如在一般的数据分析当中,需要我们计算25分位(下四分位),50分位(中位),75分位(上四分位)值。
- 2.分位值的意义是什么
分位值即把所有数据从小到达排序,取前N%位置的值,即为该分位的值。
一般用分位值来观察大部分用户数据,平均值会"削峰填谷",同时高氛围的稳定性可以忽略掉少量的长尾数据。
高分位数据不适用于全部的业务场景,例如金融支付行业,可能就会要求100%的成功。
4.5.2 分位值是如何计算的
以95分位值为例,将采集到的100个数据,从小到大排列,95分位值就是取出第95个用户的数据做统计,同理,50非文职就是第50个人的数据。
举个例子: 有一组数 A=【65 23 55 78 98 54 88 90 33 48 91 84】,计算他的25分位,50分位,75分位值。
- 1.先把上面12个数按从小到大排序:
23、33、48、54、55、65、78、84、88、90、91、98
- 2.12个数有11个间隔,每个四分位间11/4=2.75个数
- 3.手工计算分位值:先把上面12个数按从小到大排序
- 计算25分位:
第1个四分位数为上面12个数中的第1+2.75=3.75个数
指第3个数对应的值48及第3个数与第4个数之间的0.75位置处,即:48+(0.75)*(54-48)=52.5 (52.5为25分位值)。
- 计算50分位:
第2个四分位数为上面12个数中的第1+2.75*2=6.5个数
指第6个数对应的值65及第6个数与第7个数之间的0.5位置处,即:65+(0.5)*(78-65)=71.5 (71.5为50分位值)。
中位值也可以用一种很简单的方法计算,按从小到大排列后:
若数组中数的个数为奇数,则最中间那个数对应的值则为中位值;
若数组中数的个数为偶数,则取中间两个数值的平均值则为中位值,如上(78+65)/2=71.5
- 计算75分位:
第3个四分位数为上面12个数中的第1+2.75*3=9.25个数
指第9个数对应的值88及第9个数与第10个数之间的0.25位置处,即:88+(0.25)*(90-88)=88.5 (88.5为75分位值)。
课后练习:
将1到100分为10等分,则有10个10分位,用以上的方法可计算10分位值和90分位值。
4.5.3 histogram数据说明
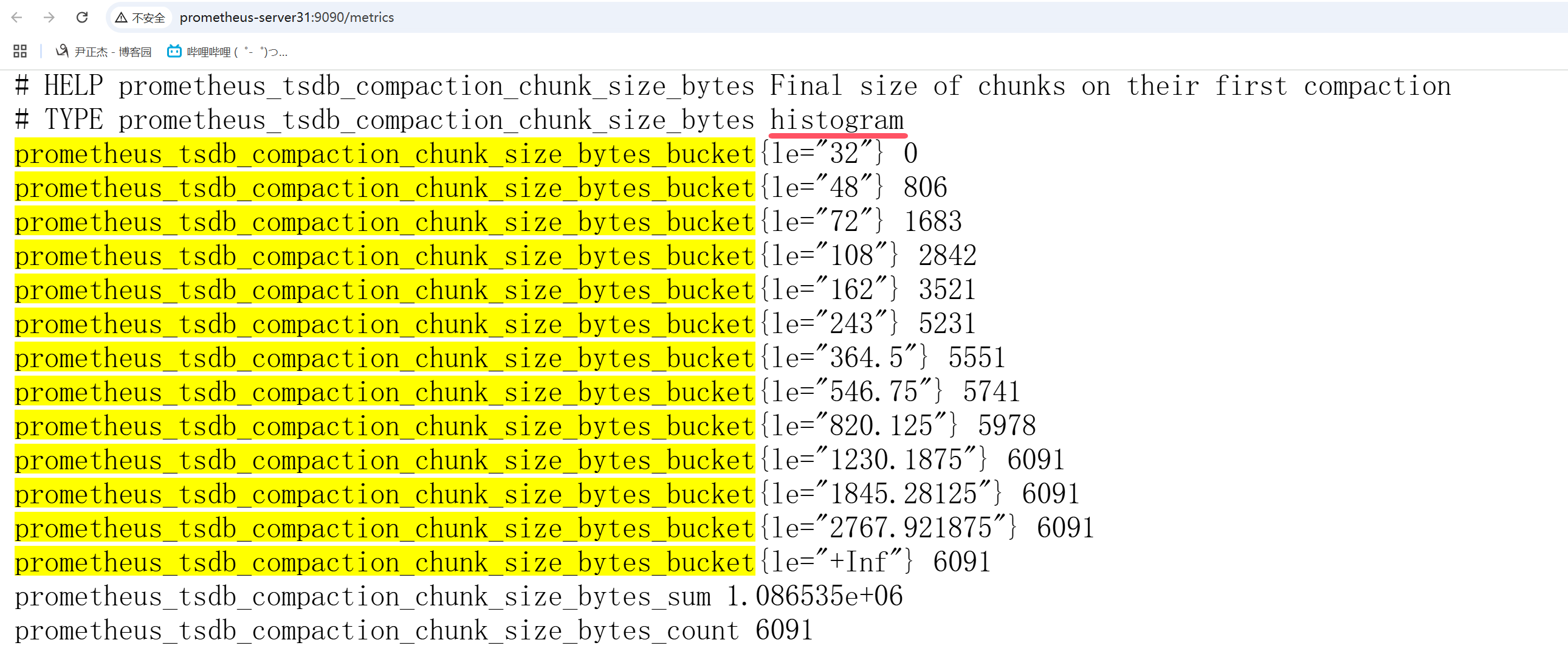
histogram数据指标格式说明:
- XXX_bucket:
代表描述"tsdb_compaction_chunk_size_bytes"小于这个le的记录数位多少个:
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="32"} 0
tsdb压缩块大小小于32bytes的有0个。
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="48"} 806
tsdb压缩块大小小于48byte的有806个。
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="72"} 1683
tsdb压缩块大小小于72byte的有1683个。
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="108"} 2842
tsdb压缩块大小小于108byte的有2842个。
...
prometheus_tsdb_compaction_chunk_size_bytes_bucket{le="+Inf"} 6091
最后一定是一个"+Inf"(表示"正无穷")的记录,因为算分位值的时候要用到"+Inf"。
值得注意的是,一个新的数据上报时,会把大于这个value的bucket全部"+1"。
- XXX_sum:
代表记录的和,比如这个指标就是"tsdb_compaction_chunk_size_bytes"tsdb压缩块大小字节总和为"1.086535e+06"(将近1MB)。
- XXX_count:
代表记录"tsdb_compaction_chunk_size_bytes"的数量和,就是一共"6091"次上报。
Prometheus可以使用histogram数据类型可以采用分位值的方式随机采样短时间范围内的数据,从而及时发现问题,这需要配合histogram_quantile函数来使用。
举个例子: HTTP请求的延迟柱状图(下面的"0.95"表示的是分位值,你可以根据需求自行修改即可。)
histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket[1m])) by (le))
histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket{handler="/api/v1/query"}[5m])) by (le))
4.5.4 summary数据说明

summary数据指标格式说明:
- XXX{...,quantile=XXX}:
使用quantile关键字定义具体的分位值。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.01"} 14.997928423
代表就是"1"分位值为"14.997928423"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.05"} 14.998842243
代表就是"5"分位值为"14.997928423"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.5"} 15.000025528
代表就是"50"分位值为"15.000025528"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.9"} 15.000811084
代表就是"90"分位值为"15.000811084"秒。
prometheus_target_interval_length_seconds{interval="15s",quantile="0.99"} 15.001590525
代表就是"99"分位值为"15.001590525"秒。
- XXX_sum:
代表记录的和,比如这个指标就是"target_interval(采集目标间隔时间)"消耗描述的和为"4785.00520029"。
- XXX_count:
代表记录的数量和,一共上报了"319"次。
5.范围向量选择器(Range Vector Selectors)
5.1 范围向量元素时间单位
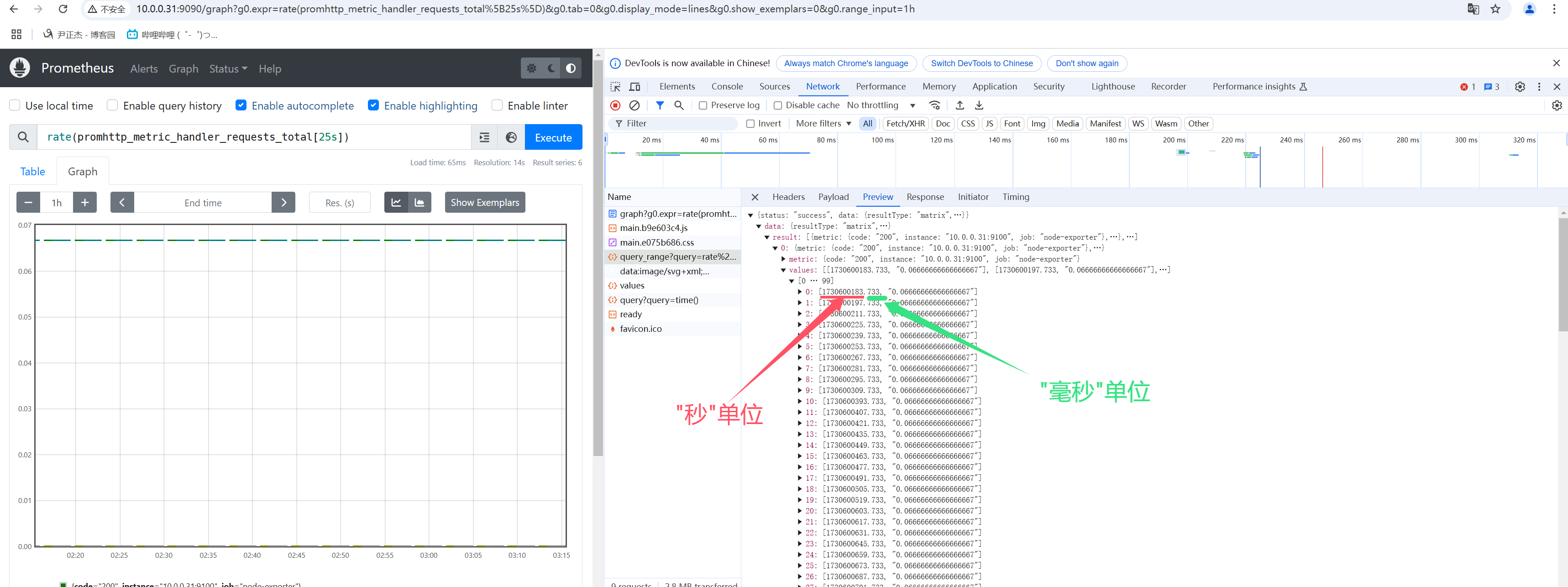
范围矢量的工作方式与即时矢量一样,不同之处在于它们从当前即时中选择了一定范围的样本。语法上,将持续时间附加在"[]"向量选择器末尾的方括号"()"中,以指定应为每个结果范围向量元素提取多远的时间值。
常见的范围向量元素时间单位:
- 毫秒 : ms
- 秒 : s
- 分钟 : m
- 小时 : h
- 天 : d
- 周 : w
- 年 : y
如上图所示,Prometheus返回的都是毫秒时间戳
- 10位代表"秒时间戳"
- 13位代表"毫秒时间戳"(毫秒时间戳代表着数据采集的更加精确)
5.2 时间范围使用注意事项
- 时间范围向量选择器只能作用在Counter类型上;
- 时间范围一般搭配非聚合函数,如: rate,irate,delta,idelta,sum等;
例如:计算网卡流量
rate(promhttp_metric_handler_requests_total[1m])
- 时间范围,不能低于采集间隔,否则查不到数据
例如: 采集时间是"scrape_interval: 15s"采集一次, 则5s内的数据查不到
rate(promhttp_metric_handler_requests_total[5s])
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/18419616,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号