

Ceph Reef(18.2.X)之数据存储原理及Crush实战
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.ceph分布式集群原理图
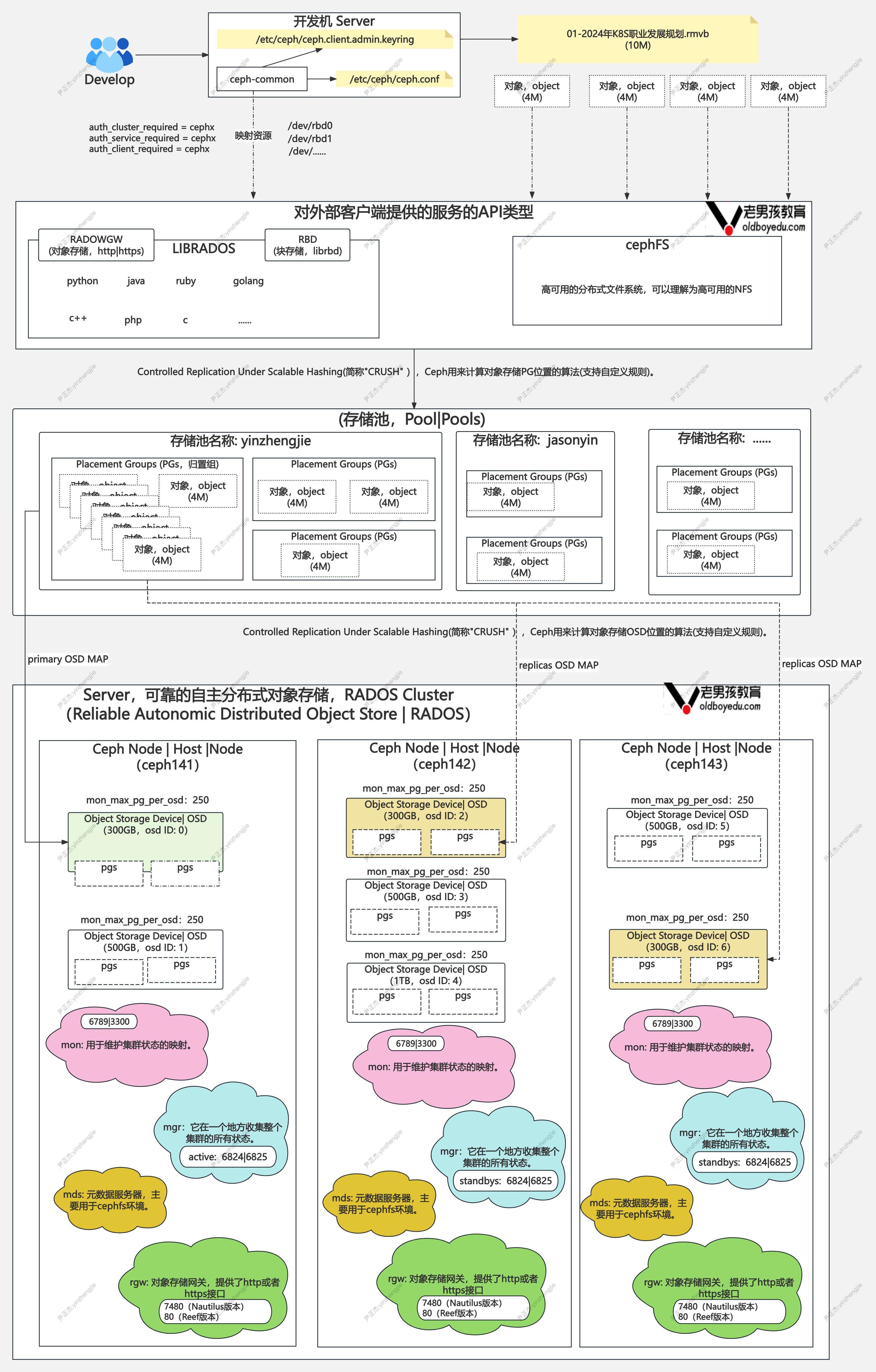
1.存储池(pools)
RADOS存储集群提供的基础存储服务由存储池(POOL)分割为逻辑存储区域,是用于存储对象的逻辑组。
对于Ceph集群来说,它的存储主要由默认的副本池(replicated pool)和纠删码池(erasure code)两种类型组成。
存储池还可以进一步细分为多个子名称空间,命名格式为: "{根名称空间}.{应用名称空间}.{子空间}"
[root@ceph141 ~]# ceph osd pool ls
.mgr
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta
default.rgw.buckets.index
default.rgw.buckets.data
...
[root@ceph141 ~]#
推荐阅读:
https://docs.ceph.com/en/reef/rados/operations/pools/
2.归置组(Placement Groups)
归置组(PG)是ceph如何分发数据的内部实现细节,将对象映射到归置组,归置组是逻辑对象池的分配或片段,它们将对象作为一个组放在OSD中。
推荐阅读:
https://docs.ceph.com/en/reef/rados/operations/placement-groups/
3.CRUSH 映射(CRUSH Maps)
CRUSH是让Ceph在正常运行情况下进行数据扩展的重要部分,能够实现对象到归置组的映射,也能过实现归置组到OSD到映射。
CRUSH算法允许客户端计算对象应该存储在哪,从而实现客户端能够快速联系上主OSD以存储或检索对象:
- 1.ceph客户端输入pool名称和对象ID
rados put {object_name} /path/to/file -p {pool_name}
- 2.ceph获取对象ID后对其进行hash处理
hash(对象ID名称) % PG_num
- 3.ceph基于PG数为模对PG进行哈希计算后获取PG ID;
root@ceph141 ~]# ceph osd map xixi fstab
osdmap e505 pool 'yinzhengjie' (10) object 'fstab' -> pg 10.45a53d91 (10.14) -> up ([3,1,2,0,4,5], p3) acting ([3,1,2,0,4,5], p3)
[root@ceph141 ~]#
- 4.ceph根据pool名称获取pool ID,比如存储id为"10"
[root@ceph141 ~]# ceph osd pool ls detail
...
pool 10 'yinzhengjie' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 291 lfor 0/0/287 flags hashpspool stripe_width 0 application cephfs read_balance_score 1.69
...
[root@ceph141 ~]#
- 5.ceph将pool ID附加到PG ID,比如存储id为"10.14"。
root@ceph141 ~]# ceph pg dump pgs
PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG LOG_DUPS DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP SNAPTRIMQ_LEN LAST_SCRUB_DURATION SCRUB_SCHEDULING OBJECTS_SCRUBBED OBJECTS_TRIMMED
....
10.1f 0 0 0 0 0 0 0 0 14 0 14 active+clean 2024-09-08T00:18:33.492328+0000 294'14 505:502 [2,1,3] 2 [2,1,3] 2 294'14 2024-09-08T00:18:33.492113+0000 294'14 2024-09-04T12:20:08.742301+0000 0 1 periodic scrub scheduled @ 2024-09-09T03:42:23.584543+0000 0 0
...
10.14 0 0 0 0 0 0 0 0 18 0 18 active+clean 2024-09-08T00:15:44.676668+0000 294'18 505:312 [1,3,2] 1 [1,3,2] 1 294'18 2024-09-06T23:59:15.330770+0000 0'0 2024-08-31T08:49:29.941831+0000 0 1 periodic deep scrub scheduled @ 2024-09-08T08:04:05.012730+0000 0 0
* NOTE: Omap statistics are gathered during deep scrub and may be inaccurate soon afterwards depending on utilization. See http://docs.ceph.com/en/latest/dev/placement-group/#omap-statistics for further details.
dumped pgs
[root@ceph141 ~]#
推荐阅读:
https://docs.ceph.com/en/reef/rados/operations/cursh-map
4.平衡器(Balancer)
平衡器(Balancer)是一个功能,它会自动优化PG跨设备的分布,以实现数据的均衡分布,最大化集群可以存储数据量。
推荐阅读:
https://docs.ceph.com/en/reef/rados/operations/balancer/
5.对象存储设备(OSD)
对于Acting Set到Ceph OSD守护进程主要有四种状态:
- Up(启动已运行)
- Down(关闭未运行)
- In(集群中)
- Out(集群外)
我们可以通过一些命令来查看OSD到状态信息:
[root@ceph141 ~]# ceph osd stat
6 osds: 6 up (since 93m), 6 in (since 93m); epoch: e505
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.46489 root default
-3 0.48830 host ceph141
0 hdd 0.19530 osd.0 up 1.00000 1.00000
1 hdd 0.29300 osd.1 up 1.00000 1.00000
-5 0.48830 host ceph142
2 hdd 0.19530 osd.2 up 1.00000 1.00000
4 hdd 0.29300 osd.4 up 1.00000 1.00000
-7 0.48830 host ceph143
3 hdd 0.29300 osd.3 up 1.00000 1.00000
5 hdd 0.19530 osd.5 up 1.00000 1.00000
[root@ceph141 ~]#
[root@ceph141 ~]# ceph -s
cluster:
id: c0ed6ca0-5fbc-11ef-9ff6-cf3a9f02b0d4
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph141,ceph142,ceph143 (age 2h)
mgr: ceph141.fuztcs(active, since 2h), standbys: ceph142.vdsfzv
mds: 1/1 daemons up, 1 standby
osd: 6 osds: 6 up (since 105m), 6 in (since 105m)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 10 pools, 481 pgs
objects: 271 objects, 889 KiB
usage: 411 MiB used, 1.5 TiB / 1.5 TiB avail
pgs: 481 active+clean
[root@ceph141 ~]#
推荐阅读:
https://docs.ceph.com/en/reef/rados/operations/monitoring-osd-pg/
二.归置组
1.PG简介
当用户在ceph存储集群中创建存储池pool的时候,我们往往会为它创建PG和PGP,如果我们没有指定PG和PGP的话,则ceph使用配置文件中的默认值来创建pool的GP和PGP。
通常情况下,我们建议用户根据实际情况在配置文件中自定义pool的对象副本数量和PG数目。
关于对象副本数目,用户可以根据自身的数据安全性的要求程度来进行设置,ceph默认存储一份主数据对象和两个副本数据(OSD pool default size = 3)。
对于PG数目,假如数据对象副本数目为N,集群OSD数量为M,则每个OSD上的PG数量为X,官方提供了一个默认的PG数量计算公式。
PG|PGP数量 = M * X / N
官方推荐X为100(但OSD默认的PG数量上限为: 250),PG算出来的数据往往不是一个整数,但我们通常讲结果取值为2的幂次方值。
举个例子,假设Ceph集群有200个OSD,存储池副本为3,则创建的PG数量总和为: 200 * 100 /3 = 6666.66,也就是说ceph创建的PG总数不建议超过6666个哟~
PG数量在设置的时候,要遵循所有的pool的PG数量要小于OSD所能够承载的容量,默认情况下,OSD最大PG数量上限为250。
推荐阅读:
https://docs.ceph.com/en/latest/rados/configuration/pool-pg-config-ref/
2.临时PG
对于CRUSH来说,如果出现主OSD异常,会重新分配一个新的主OSD,我们会借助于临时PG来完成数据的同步操作。
临时PG产生的流程如下所示:
- 1.假设一个PG的acting set为:[0,1,2]列表。此时如果OSD.0出现故障,导致CRUSH算法重新分配该PG的acting set为[3,1,2]。
- 2.此时OSD.3为该的主OSD,但是OSD.3为该新加入的OSD,并不能负担该PG上的读操作。
- 3.所以PG向monitor申请一个临时的PG,OSD.1为临时的主OSD,这时up set变为[1,3,2],acting set依然为[3,1,2],导致acting set和up set不同。
- 4.当OSD.3完成backfill过程之后,临时PG被取消,该PG的up set修复为acting set,此时acting set和up set都是[3,1,2]列表。
3.PG的相关操作
3.1 修改OSD的pg数量上限
[root@ceph141 ~]# ceph osd pool set yinzhengjie pg_num 512
Error ERANGE: pool id 22 pg_num 512 size 3 for this pool would result in 491 cumulative PGs per OSD (2949 total PG replicas on 6 'in' root OSDs by crush rule) which exceeds the mon_max_pg_per_osd value of 250 # 很明显,默认的上限值为250
[root@ceph141 ~]#
[root@ceph141 ~]#
[root@ceph141 ~]# ceph tell mon.* injectargs --mon-max-pg-per-osd=1000 # 修改属性的上限值,注意命令后的参数和配置文件参数的略微变化哟~
mon.ceph141: {}
mon.ceph141: mon_max_pg_per_osd = '' (not observed, change may require restart)
mon.ceph142: {}
mon.ceph142: mon_max_pg_per_osd = '' (not observed, change may require restart)
mon.ceph143: {}
mon.ceph143: mon_max_pg_per_osd = '' (not observed, change may require restart)
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd pool set yinzhengjie pg_num 512
set pool 22 pg_num to 512
[root@ceph141 ~]#
温馨提示:
pg_num的属性必须大于等于pgp_num,一般情况下,我们按照官网的建议将这两个数据设置为相等的。
3.2 获取精简的pg统计信息
1.获取特殊状态的PG
[root@ceph141 ~]# ceph pg dump_stuck
ok
[root@ceph141 ~]#
[root@ceph141 ~]# ceph pg dump_stuck stale
ok
[root@ceph141 ~]#
2.查看集群状态
[root@ceph141 ~]# ceph -s
cluster:
id: c0ed6ca0-5fbc-11ef-9ff6-cf3a9f02b0d4
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph141,ceph142,ceph143 (age 5h)
mgr: ceph141.fuztcs(active, since 5h), standbys: ceph142.vdsfzv
mds: 1/1 daemons up, 1 standby
osd: 6 osds: 6 up (since 5h), 6 in (since 5h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 17 pools, 705 pgs
objects: 271 objects, 889 KiB
usage: 754 MiB used, 1.5 TiB / 1.5 TiB avail
pgs: 705 active+clean # 会返回归置组当前的状态
[root@ceph141 ~]#
对于pg状态的状态我们只需重点关注clean和active,其他状态都属于特殊状态,有些事临时的。
如果遇到pg异常我们通常的解决办法可参考如下方案:
- 1.重启OSD相关服务;
- 2.调整属性参数;
- 3.重置PG;
PG组常见的状态有:
active:
ceph可处理归置组的请求。
clean:
ceph把归置组的内存复制了规定次数。
scrubbing:
ceph正在检查归置组的一致性。
degraded:
归置组的对象还没复制到规定次数。
creating:
ceph仍在创建归置组。
down:
包含必备数据的副本挂了,所以归置组离线。
replay:
某OSD崩溃后,归置组在等待客户端重放操作。
splitting:
ceph正在把一个归置组分割为多个。
inconsistent:
ceph检测到了归置组内一个或多个副本间不一致现象。
peering:
归置组正在互联。
repair:
ceph正在检查归置组,并试图修复发现的不一致。
recovring:
ceph正在迁移/同步对象及其副本。
backfill:
ceph正在扫描并同步整个归置组的内容,backfill是恢复的一种特殊情况。
wait-backfill:
归置组正在排队,等待backfill。
backfill-toofull:
一回填操作在等待,因为目标OSD使用率超过了沾满率。
incomplete:
ceph探测到某一归置组异常。
stale:
归置组处于一种未知状态,从归置组运行图变更起就没有在收到它的更新。
remapped:
归置组被临时映射到了另外一组OSD,它们不是CRUSH算法指定的。
undersized:
此归置组的副本数小于配置的存储池副本水平。
peered:
此归置组已互联,因为副本没有达到标准,不能向客户端提供服务。
异常状态标识:
inactive:
归置组不能处理读写,因为它们在等待一个最新数据的OSD复活且进入集群。
unclean:
归置组含有副本数未达到期望数量的对象,它们应该在恢复中。
stale:
归置组处于未知状态,存储它们的OSD长时间没有向mon报告了。
degraded:
归置组的对象还没复制到规定次数。
undersized:
此归置组的副本数小于配置的存储池副本水平。
3.3 查看所有pg的状态
[root@ceph141 ~]# ceph pg stat
754 pgs: 1 peering, 753 active+clean; 889 KiB data, 639 MiB used, 1.5 TiB / 1.5 TiB avail
[root@ceph141 ~]#
3.4 查看pg对应osd编号的详细信息
[root@ceph141 ~]# ceph osd pool ls detail | grep yinzhengjie
pool 22 'yinzhengjie' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 61 pgp_num 61 pg_num_target 32 pgp_num_target 32 autoscale_mode on last_change 1121 lfor 0/1121/1119 flags hashpspool stripe_width 0 read_balance_score 1.67
[root@ceph141 ~]#
[root@ceph141 ~]# ceph pg dump | grep 22
...
22.1d 0 0 0 0 0 0 0 0 0 0 0 active+clean 2024-09-08T05:53:31.794521+0000 0'0 1149:716 [1,4,5] 1 [1,4,5] 1 0'0 2024-09-08T05:47:08.551874+0000 0'0 2024-09-08T05:40:18.162657+0000 0 1 periodic scrub scheduled @ 2024-09-09T06:16:15.930166+0000 0 0
0 0
...
22.2 0 0 0 0 0 0 0 0 0 0 0 active+clean 2024-09-08T05:53:04.508680+0000 0'0 1149:691 [3,4,1] 3 [3,4,1] 3 0'0 2024-09-08T05:45:33.315456+0000 0'0 2024-09-08T05:43:46.326900+0000 0 1 periodic scrub scheduled @ 2024-09-09T14:17:49.333267+0000 0 0
...
3.5 查看指定pg值的统计信息
[root@ceph141 ~]# ceph pg 22.1d query
{
"snap_trimq": "[]",
"snap_trimq_len": 0,
"state": "active+clean",
"epoch": 1272,
"up": [
1,
4,
5
],
"acting": [
1,
4,
5
],
"acting_recovery_backfill": [
"1",
"4",
"5"
],
"info": ...,
"peer_info": ...,
"recovery_state": ...,
"scrubber": {
"active": false,
"must_scrub": false,
"must_deep_scrub": false,
"must_repair": false,
"need_auto": false,
"scrub_reg_stamp": "2024-09-09T06:16:15.930166+0000",
"schedule": "scrub scheduled @ 2024-09-09T06:16:15.930"
},
"agent_state": {}
}
[root@ceph141 ~]#
3.6 列出不一致的PG
[root@ceph141 ~]# rados list-inconsistent-pg yinzhengjie
[]
[root@ceph141 ~]#
三.运行图
1.map简介
对于ceph集群来说,有个非常重要的特点就是高性能,而高性能有一个非常突出的特点就是单位时间内处理业务数据。
所有的map只有一个目的,将相关资源进行关联,查找时候比较方便。
ceph集群中常见的map如下所示:
minitor map:
mon节点所有节点的连接信息,包括ceph集群ID,monitor节点名称,IP地址和端口等。
crush map:
让ceph在正常运行情况下进行高效数据操作的重要支撑部分,包括数据的写入和查询用到的设备列表,存储桶。
osd map:
保存OSD的基本信息,包括ID,状态,副本,PG,OSD信息等,便于数据等均衡性操作。
mds map:
保存MDS的基本信息,包括版本号,创建和修改时间,数据和元数据存储池,数量,MDS状态等。
pg map:
保存pg等基本信息,包括pg等ID,数量,状态,版本号,时间戳,容量百分比等。
2.查看mon相关信息
[root@ceph141 ~]# ceph mon dump
epoch 3
fsid c0ed6ca0-5fbc-11ef-9ff6-cf3a9f02b0d4
last_changed 2024-08-21T13:11:17.811485+0000
created 2024-08-21T12:56:24.217633+0000
min_mon_release 18 (reef)
election_strategy: 1
0: [v2:10.0.0.141:3300/0,v1:10.0.0.141:6789/0] mon.ceph141
1: [v2:10.0.0.142:3300/0,v1:10.0.0.142:6789/0] mon.ceph142
2: [v2:10.0.0.143:3300/0,v1:10.0.0.143:6789/0] mon.ceph143
dumped monmap epoch 3
[root@ceph141 ~]#
[root@ceph141 ~]#
3.查看osd相关信息
[root@ceph141 ~]# ceph mon dump
epoch 3
fsid c0ed6ca0-5fbc-11ef-9ff6-cf3a9f02b0d4
last_changed 2024-08-21T13:11:17.811485+0000
created 2024-08-21T12:56:24.217633+0000
min_mon_release 18 (reef)
election_strategy: 1
0: [v2:10.0.0.141:3300/0,v1:10.0.0.141:6789/0] mon.ceph141
1: [v2:10.0.0.142:3300/0,v1:10.0.0.142:6789/0] mon.ceph142
2: [v2:10.0.0.143:3300/0,v1:10.0.0.143:6789/0] mon.ceph143
dumped monmap epoch 3
[root@ceph141 ~]#
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd dump
epoch 1272
fsid c0ed6ca0-5fbc-11ef-9ff6-cf3a9f02b0d4
created 2024-08-21T12:56:27.504471+0000
modified 2024-09-08T05:56:59.577568+0000
flags sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit
crush_version 55
full_ratio 0.95
backfillfull_ratio 0.9
nearfull_ratio 0.85
require_min_compat_client luminous
min_compat_client luminous
require_osd_release reef
stretch_mode_enabled false
...
pg_upmap_items 5.b [0,1]
pg_upmap_items 9.c3 [0,1]
pg_upmap_items 9.d5 [0,1]
pg_upmap_items 19.15 [3,5]
pg_upmap_items 22.c [1,0]
pg_upmap_items 22.15 [1,0]
pg_upmap_items 22.1b [1,0]
pg_upmap_items 22.1c [1,0]
blocklist 10.0.0.141:0/3150379988 expires 2024-09-09T00:15:54.932932+0000
blocklist 10.0.0.141:6819/2331435219 expires 2024-09-09T00:15:54.932932+0000
blocklist 10.0.0.141:0/4020122836 expires 2024-09-09T00:15:54.932932+0000
blocklist 10.0.0.141:6818/2331435219 expires 2024-09-09T00:15:54.932932+0000
blocklist 10.0.0.141:0/2212058050 expires 2024-09-09T00:15:54.932932+0000
blocklist 10.0.0.141:0/2094157237 expires 2024-09-09T00:15:54.932932+0000
blocklist 10.0.0.141:6801/3769640836 expires 2024-09-09T00:15:28.137408+0000
blocklist 10.0.0.141:6800/3769640836 expires 2024-09-09T00:15:28.137408+0000
[root@ceph141 ~]#
4.查看mds相关信息
[root@ceph141 ~]# ceph node ls mds
{
"ceph141": [
"yinzhengjie-cephfs.ceph141.ezrzln"
],
"ceph142": [
"yinzhengjie-cephfs.ceph142.oflxbm"
]
}
[root@ceph141 ~]#
[root@ceph141 ~]#
5.查看crush相关信息
[root@ceph141 ~]# ceph osd crush dump
{
"devices": [ # 设备列表信息
{
"id": 0,
"name": "osd.0",
"class": "hdd"
},
{
"id": 1,
"name": "osd.1",
"class": "hdd"
},
{
"id": 2,
"name": "osd.2",
"class": "hdd"
},
{
"id": 3,
"name": "osd.3",
"class": "hdd"
},
{
"id": 4,
"name": "osd.4",
"class": "hdd"
},
{
"id": 5,
"name": "osd.5",
"class": "hdd"
}
],
"types": [ # 资源类型列表有12类,主要有: osd,host,chassis,rack,row,pdu,pod,room,datacenter,zone,region,root
{
"type_id": 0,
"name": "osd"
},
{
"type_id": 1,
"name": "host"
},
...,
],
"buckets": ...,
"rules": ...,
"tunables": ...,
"choose_args": {}
}
[root@ceph141 ~]#
6.查看pg相关的信息
[root@ceph141 ~]# ceph pg dump
version 22273
stamp 2024-09-08T12:12:24.037941+0000
last_osdmap_epoch 0
last_pg_scan 0
PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG LOG_DUPS DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP SNAPTRIMQ_LEN LAST_SCRUB_DURATION SCRUB_SCHEDULING OBJECTS_SCRUBBED OBJECTS_TRIMMED
...
22.1b 0 0 0 0 0 0 0 0 0 0 0 active+clean 2024-09-08T05:56:59.845757+0000 0'0 1272:1055 [2,3,0] 2 [2,3,0] 2 0'0 2024-09-08T05:45:57.491750+0000 0'0 2024-09-08T05:40:18.162657+0000 0 1 periodic scrub scheduled @ 2024-09-09T07:12:49.760000+0000 0 0
...
22.3 0 0 0 0 0 0 0 0 0 0 0 active+clean 2024-09-08T05:56:29.753641+0000 0'0 1272:1014 [4,3,1] 4 [4,3,1] 4 0'0 2024-09-08T05:45:20.070451+0000 0'0 2024-09-08T05:40:18.162657+0000 0 1 periodic scrub scheduled @ 2024-09-09T07:16:03.160202+0000 0 0
...
sum 271 0 0 0 0 910539 5417 12 40595 40595
OSD_STAT USED AVAIL USED_RAW TOTAL HB_PEERS PG_SUM PRIMARY_PG_SUM
5 120 MiB 200 GiB 120 MiB 200 GiB [0,1,2,3,4] 282 89
4 113 MiB 300 GiB 113 MiB 300 GiB [0,1,2,3,5] 424 136
3 156 MiB 300 GiB 156 MiB 300 GiB [0,1,2,4,5] 439 139
2 155 MiB 200 GiB 155 MiB 200 GiB [0,1,3,4,5] 297 103
1 146 MiB 300 GiB 146 MiB 300 GiB [0,2,3,4,5] 420 146
0 121 MiB 200 GiB 121 MiB 200 GiB [1,2,3,4,5] 301 92
sum 811 MiB 1.5 TiB 811 MiB 1.5 TiB
* NOTE: Omap statistics are gathered during deep scrub and may be inaccurate soon afterwards depending on utilization. See http://docs.ceph.com/en/latest/dev/placement-group/#omap-statistics for further details.
dumped all
[root@ceph141 ~]#
7.查看pg-OSD关系图
[root@ceph141 ~]# ceph pg map 22.10
osdmap e1272 pg 22.10 (22.10) -> up [4,3,1] acting [4,3,1]
[root@ceph141 ~]#
8.提交文件到对应OSD列表
[root@ceph141 ~]# rados put os-release /etc/os-release -p yinzhengjie
[root@ceph141 ~]#
9.查看ceph文件对象对应pg和osd关系图
[root@ceph141 ~]# ceph osd map yinzhengjie os-release
osdmap e1272 pool 'yinzhengjie' (22) object 'os-release' -> pg 22.a41909d6 (22.16) -> up ([1,4,3], p1) acting ([1,4,3], p1)
[root@ceph141 ~]#
四.CRUSH实战
1.CRUSH Map概述
CRUSH英文全称为"Controlled Replication Under Scalable Hashing",是Ceph的核心设计之一,它本质上是ceph存储集群使用的一种数据分发算法,类似于openstack的swift的AQS对象存储所使用的哈希和一致性hash数据分布算法。
CRUSH算法通过接收多维参数,通过一定的计算对客户端对象数据进行分布存位置的确定,来解决数据动态分发的问题。因此ceph客户端无需经过传统查表的方式来获取数据的索引,进而根据索引来读取数据,只需通过crush算法计算后直接和对应的OSD交互进行数据读写。这样,ceph就避免了查表这种传统中心化存在的单点故障,性能瓶颈以及不易扩展的缺陷。这就是ceph相较于其他分布式存储系统具有高扩展性,高可用和高性能特点的主要原因。
ceph中的寻找至少要经历以下三次映射:
- 1.File和object映射:
文件数据object的数据块切片操作,便于多数据的并行化处理。
- 2.Object和PG映射:
将文件数据切分后的每一个Object通过简单的Hash算法归到一个PG中。
- 3.PG和OSD映射:
将PG映射到主机实际的OSD数据磁盘上。
CRUSH算法提供了 配置和更改和数据动态再平衡等关键特性,而CRUSH算法存储数据对象的过程可通过CRUSH Map控制并进行自定义修改,CRUSH map是ceph集群物理拓扑结构,副本策略以及故障域等信息抽象配置段,借助于CRUSH Map可以将数据伪随机地分布到集群的各个OSD上。
OSD出现异常的时候,为了避免故障风暴,往往会实现一个所谓的故障域。
2.CRUSH Map的组成
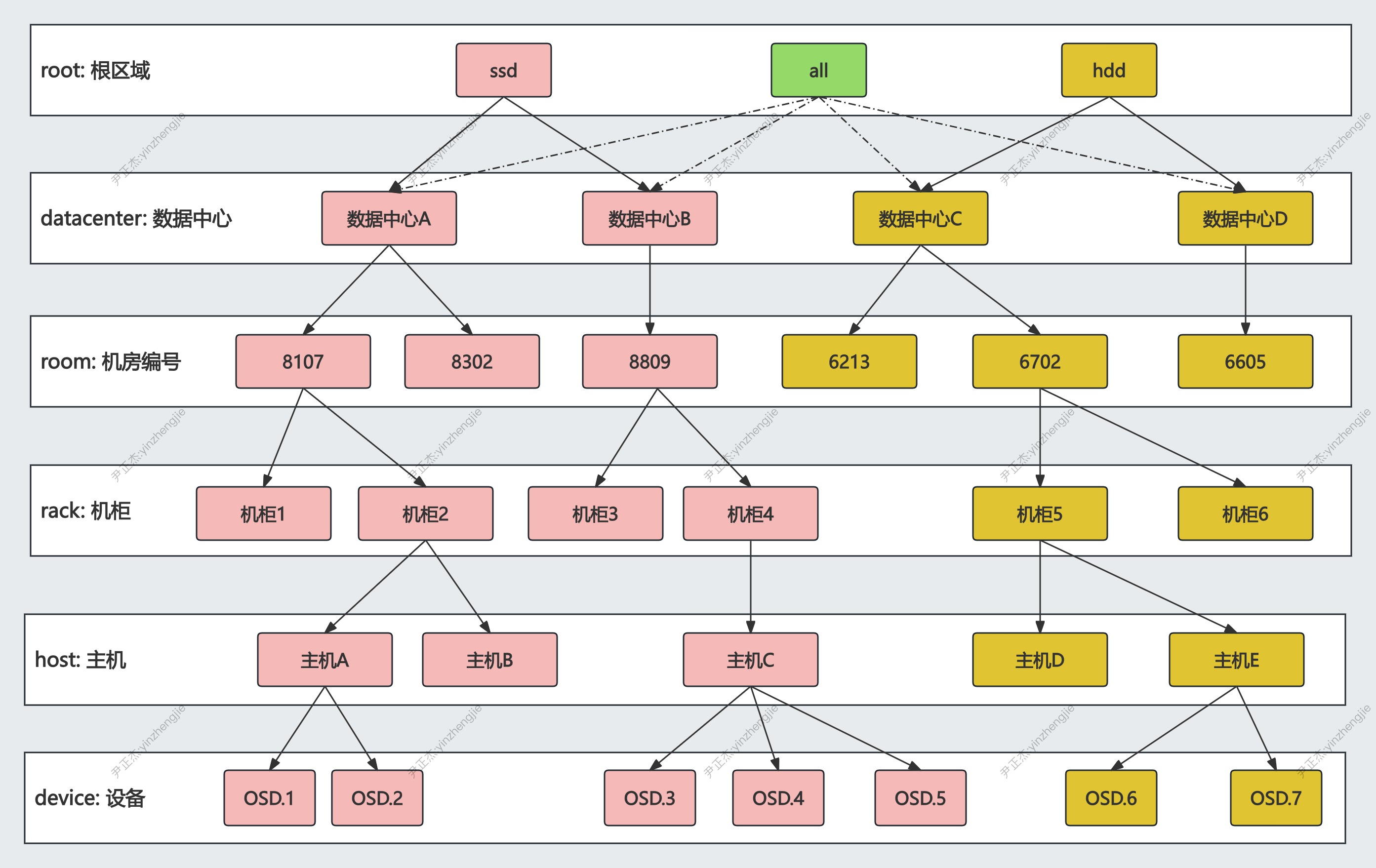
CRUSH Map由不同层次的逻辑Buckets和Devices组成:
- Buckets:
Root指的是多区域,datacenter是数据中心,room是机房,rack是机柜,host是主机,region是可用区域,datacenter是数据区域。
- Devices:
主要指各种OSD存储设备。
对于每一个ceph集群来说,CRUSH Map在正式上线前已经确定好了,如果用户需要自定义更改CRUSH Map的话,必须在集群上线前进行更改和核实,然后应用到CRUSDH算法中。
CRUSH Map中buckets是用户自定义增加的,每个层级的Bucket对应不同的故障域,对于Ceph N版本来说,它默认声明了12种Buckets:
- root: 根分区。
- region: 可用区域。
- zone: 数据区域。
- datacenter: 数据中心。
- room: 机房。
- pod: 机房单间。
- pdu: 电源插座。
- row: 机柜排。
- rack: 机柜。
- chassis: 机箱。
- host: 主机。
- osd: 磁盘。
3.crush map操作步骤
对于crush来说,如果你的设备量非常的大,那么crush文件可能巨大。
由于crush内容比较多,格式比较繁琐,所以在操作的时候,我们会基于现有的crush现象生成一个模板文件,在模板文件上进行后续操作。
crush相关的信息,我们可以通过两种方法进行操作:
- 1.获取crush相关信息
相关命令:"ceph osd crush dump"。
- 2.操作crush相关信息
获取"crush map"信息后进行格式转换,编辑文本后再次应用"crush map"数据。
4.操作crush信息
1.从monitor节点上获取CRUSH map
[root@ceph141 ~]# ceph osd getcrushmap -o yinzhengjie-crushmap.file
14
[root@ceph141 ~]#
[root@ceph141 ~]# file yinzhengjie-crushmap.file # 默认获取的文件并不会是文本文件,无法直接查看。
yinzhengjie-crushmap.file: data
[root@ceph141 ~]#
2.获取该crushmap文件后,编译为可读文件
[root@ceph141 ~]# apt -y install ceph-base
[root@ceph141 ~]#
[root@ceph141 ~]# crushtool -d yinzhengjie-crushmap.file -o yinzhengjie-crushmap.txt
[root@ceph141 ~]#
[root@ceph141 ~]# file yinzhengjie-crushmap.txt
yinzhengjie-crushmap.txt: ASCII text
[root@ceph141 ~]#
3.查看文件内容
[root@ceph141 ~]# cat yinzhengjie-crushmap.txt
# begin crush map # 设定修正bug,优化算法,以及向后兼容老版本等属性信息。
tunable choose_local_tries 0 # 为做向后兼容保持为0。
tunable choose_local_fallback_tries 0 # 为做向后兼容应保持为0,
tunable choose_total_tries 50 # 选择bucket的最大重试次数,
tunable chooseleaf_descend_once 1 # 为做向后兼容应保持为1,
tunable chooseleaf_vary_r 1 # 修复旧bug,为做向后兼容应保持为1。
tunable chooseleaf_stable 1 # 避免不必要的pg迁移,为做向后兼容应保持为1。
tunable straw_calc_version 1 # straw算法版本,为做向后兼容应保持为1。
tunable allowed_bucket_algs 54 # 允许使用bucket选择算法,通过位运算得出的值。
# devices # 该部分保存了ceph集群中所有OSD设备和ceph-osd守护进程的映射关系。
device 0 osd.0 class hdd # 格式: device {num} {osd.name} [class {class}]
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
# types # 该部分定义了在CRUSH层次结构中用到的buckets类型,crush里面的故障域等信息,如果不在这里用type定义,后面无法直接使用。
type 0 osd # 格式: type {num} {bucket-name},此处指定OSD守护进程编号,比如osd.0,osd.1,osd.2等。
type 1 host # OSD所在主机名称
type 2 chassis # host所在机箱名称
type 3 rack # 机箱所在机柜名称
type 4 row # 机柜所在排名称
type 5 pdu # 机柜排所在的电源插座
type 6 pod # 电源插座专属的单间
type 7 room # 房间所属的机房
type 8 datacenter # 机房所属的数据中心
type 9 zone # 数据中心所属的数据区域。
type 10 region # 数据区域所属的可用区域。
type 11 root # 设备管理的根路径。
# buckets # 该部分定义了一个个具体的type类型的设备区域。
host ceph141 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.48830
alg straw2 # strwa2算法减少集群发生了改变后的数据移动。
hash 0 # bucket使用hash算法,默认是:"rjenkins1"
item osd.0 weight 0.19530 # 低一层的bucket名称,以及其对应的weight。
item osd.1 weight 0.29300
}
host ceph142 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.48830
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.19530
item osd.4 weight 0.29300
}
host ceph143 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.48830
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.29300
item osd.5 weight 0.19530
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 1.46489 # 这里的权重可用不指定,会自动获取。
alg straw2
hash 0 # rjenkins1
item ceph141 weight 0.48830 # 低一层级的bucket名称,以及其对应的weight,这个是实际的磁盘容量值。
item ceph142 weight 0.48830
item ceph143 weight 0.48830
}
# rules # 部分定义了存储池的属性,以及存储池中数据的存储方式,尤其是复制(replication)和放置(placement)数据。
rule replicated_rule {
id 0 # 定制所属规则集。
type replicated # 作用副本存储池范围,指定rule作用的存储池类型,比如replicated|erasure。
# min_size 1 # 副本少于1个,规则失效,在Reef版本中以及不支持,但N版本是存在的。
# max_size 10 # 副本大于10个,规则失效,在Reef版本中以及不支持,但N版本是存在的。
step take default # 作用于default类型的bucket。
step chooseleaf firstn 0 type host # 作用于包含3个子bucket和host。
step emit # 表示数据处理的方式,处理完数据后,清理处理过程。
}
# end crush map
[root@ceph141 ~]#
5.修改并应用模板
1.修改模板的文件
[root@ceph141 ~]# vim yinzhengjie-crushmap.txt
...
root default {
...
# alg straw2
alg straw # 将原有行注视掉,修改算法内容。
}
2.将修改后的文件转换为新的二进制文件
[root@ceph141 ~]# crushtool -c yinzhengjie-crushmap.txt -o new-crushmap.txt
3.将新的crushmap注入到ceph集群
[root@ceph141 ~]# ceph osd crush dump | grep straw2 # 在修改前注意有8个straw2。
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd setcrushmap -i new-crushmap.txt
16
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd crush dump | grep straw2 # 对比2次的查询结果可以看出来,的确减少了,只有6个。
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
[root@ceph141 ~]#
温馨提示:
本案例看似修改成功,但是修改的参数并不明显。
五.crush实战案例
1.案例需求分析
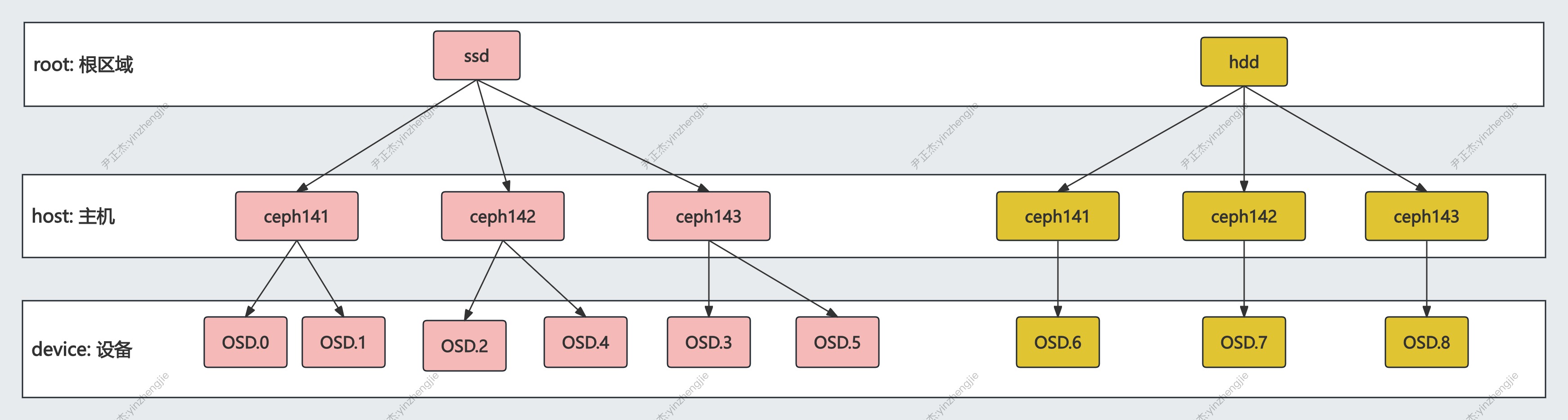
随着存储技术的发展,目前存储平台中的存储介质的类型也越来越多了,目前主要有两大类型,SSD,SAS|SATA磁盘。
我们可以根据应用对于场景的使用特点,高性能场景的数据存储使用SSD磁盘,而普通数据的存储我们采用SAS磁盘,所以在SSD场景中,我们就可以基于SSD磁盘组成高性能pool,将基于SAS|SATA磁盘组成常规Pool。
以openstack场景为例,对于VM实例来说,Nova对于实施数据I/O要求较高,所以推荐使用SSD存储池。VM实例创建过程中不高的冷数据,比如Glance镜像数据和Cinder块设备备份数据,推荐使用SAS|SATA的常规pool。
如上图所示,为了区分SSD和SAS磁盘,需要在CRUSH map中增加root层,增加SAS和SSD区域。
- 业务A对性能要求较高,将SSD作为数据盘,需要创建3副本的SSD存储池。
- 业务B对性能要求不高,但数据量较大,将SAS作为数据盘降低成本,需创建3副本的SAS存储池。
2.环境准备
1.实验环境环境前OSD信息
[root@ceph141 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.46489 root default
-3 0.48830 host ceph141
0 hdd 0.19530 osd.0 up 1.00000 1.00000
1 hdd 0.29300 osd.1 up 1.00000 1.00000
-5 0.48830 host ceph142
2 hdd 0.19530 osd.2 up 1.00000 1.00000
4 hdd 0.29300 osd.4 up 1.00000 1.00000
-7 0.48830 host ceph143
3 hdd 0.29300 osd.3 up 1.00000 1.00000
5 hdd 0.19530 osd.5 up 1.00000 1.00000
[root@ceph141 ~]#
2.添加新OSD(每个节点准备1TB对硬盘)
[root@ceph141 ~]# ceph orch daemon add osd ceph141:/dev/sdd
Created osd(s) 6 on host 'ceph141'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph142:/dev/sdd
Created osd(s) 7 on host 'ceph142'
[root@ceph141 ~]#
[root@ceph141 ~]# ceph orch daemon add osd ceph143:/dev/sdd
Created osd(s) 8 on host 'ceph143'
[root@ceph141 ~]#
3.再次查看OSD信息
[root@ceph141 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 4.46489 root default
-3 1.48830 host ceph141
0 hdd 0.19530 osd.0 up 1.00000 1.00000
1 hdd 0.29300 osd.1 up 1.00000 1.00000
6 hdd 1.00000 osd.6 up 1.00000 1.00000
-5 1.48830 host ceph142
2 hdd 0.19530 osd.2 up 1.00000 1.00000
4 hdd 0.29300 osd.4 up 1.00000 1.00000
7 hdd 1.00000 osd.7 up 1.00000 1.00000
-7 1.48830 host ceph143
3 hdd 0.29300 osd.3 up 1.00000 1.00000
5 hdd 0.19530 osd.5 up 1.00000 1.00000
8 hdd 1.00000 osd.8 up 1.00000 1.00000
[root@ceph141 ~]#
3.实战案例
3.1 从monitor节点上获取CRUSH map
[root@ceph141 ~]# ceph osd getcrushmap -o yinzhengjie-hdd.file
37
[root@ceph141 ~]#
[root@ceph141 ~]# file yinzhengjie-hdd.file
yinzhengjie-hdd.file: data
[root@ceph141 ~]#
3.2 获取该crushmap文件后,编译为可读文件
[root@ceph141 ~]# apt -y install ceph-base
[root@ceph141 ~]#
[root@ceph141 ~]# crushtool -d yinzhengjie-hdd.file -o yinzhengjie-hdd-ssd.file
[root@ceph141 ~]#
[root@ceph141 ~]# file yinzhengjie-hdd-ssd.file
yinzhengjie-hdd-ssd.file: ASCII text
[root@ceph141 ~]#
3.3 查看修改前的内容
[root@ceph141 ~]# cat yinzhengjie-hdd-ssd.file
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host ceph141 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.19530
item osd.1 weight 0.29300
item osd.6 weight 1.00000
}
host ceph142 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.19530
item osd.4 weight 0.29300
item osd.7 weight 1.00000
}
host ceph143 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.29300
item osd.5 weight 0.19530
item osd.8 weight 1.00000
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 4.46489
alg straw2
hash 0 # rjenkins1
item ceph141 weight 1.48830
item ceph142 weight 1.48830
item ceph143 weight 1.48830
}
# rules
rule replicated_rule {
id 0
type replicated
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
[root@ceph141 ~]#
3.4 修改文本文件内容
[root@ceph141 ~]# cat yinzhengjie-hdd-ssd.file
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host ceph141 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.19530
item osd.1 weight 0.29300
item osd.6 weight 1.00000
}
host ceph142 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.19530
item osd.4 weight 0.29300
item osd.7 weight 1.00000
}
host ceph143 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.29300
item osd.5 weight 0.19530
item osd.8 weight 1.00000
}
host ceph141-ssd {
id -13 # do not change unnecessarily
id -14 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.19530
item osd.1 weight 0.29300
}
host ceph141-hdd {
id -15 # do not change unnecessarily
id -16 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.6 weight 1.00000
}
host ceph142-ssd {
id -17 # do not change unnecessarily
id -18 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.19530
item osd.4 weight 0.29300
}
host ceph142-hdd {
id -19 # do not change unnecessarily
id -20 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.7 weight 1.00000
}
host ceph143-ssd {
id -21 # do not change unnecessarily
id -22 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.29300
item osd.5 weight 0.19530
}
host ceph143-hdd {
id -23 # do not change unnecessarily
id -24 class hdd # do not change unnecessarily
# weight 1.48830
alg straw2
hash 0 # rjenkins1
item osd.8 weight 1.00000
}
root ssd {
id -53
id -54 class ssd
alg straw2
hash 0
item ceph141-ssd weight 1.48830
item ceph142-ssd weight 1.48830
item ceph143-ssd weight 1.48830
}
root hdd {
id -55
id -56 class ssd
alg straw2
hash 0
item ceph141-hdd weight 1.48830
item ceph142-hdd weight 1.48830
item ceph143-hdd weight 1.48830
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 4.46489
alg straw2
hash 0 # rjenkins1
item ceph141 weight 1.48830
item ceph142 weight 1.48830
item ceph143 weight 1.48830
}
rule ssd_rule {
id 1
type replicated
step take ssd
step chooseleaf firstn 0 type host
step emit
}
rule hdd_rule {
id 2
type replicated
step take hdd
step chooseleaf firstn 0 type host
step emit
}
rule replicated_rule {
id 0
type replicated
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
[root@ceph141 ~]#
温馨提示:
- 1.核心思路就是不修改原有的数据,因为之前创建的存储池引用了之前的规则,如果你贸然修改或删除可能导致集群无法启动;
- 2.在现有的基础上做修改,但要确保id不能冲突即可;
3.5 应用配置文件
[root@ceph141 ~]# crushtool -c yinzhengjie-hdd-ssd.file -o yinzhengjie-hdd-ssd.crushmap
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd setcrushmap -i yinzhengjie-hdd-ssd.crushmap
38
[root@ceph141 ~]#
3.6 查看OSD信息
[root@ceph141 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-55 4.46489 root hdd
-15 1.48830 host ceph141-hdd
6 hdd 1.00000 osd.6 up 1.00000 1.00000
-19 1.48830 host ceph142-hdd
7 hdd 1.00000 osd.7 up 1.00000 1.00000
-23 1.48830 host ceph143-hdd
8 hdd 1.00000 osd.8 up 1.00000 1.00000
-53 4.46489 root ssd
-13 1.48830 host ceph141-ssd
0 hdd 0.19530 osd.0 up 1.00000 1.00000
1 hdd 0.29300 osd.1 up 1.00000 1.00000
-17 1.48830 host ceph142-ssd
2 hdd 0.19530 osd.2 up 1.00000 1.00000
4 hdd 0.29300 osd.4 up 1.00000 1.00000
-21 1.48830 host ceph143-ssd
3 hdd 0.29300 osd.3 up 1.00000 1.00000
5 hdd 0.19530 osd.5 up 1.00000 1.00000
-1 4.46489 root default
-3 1.48830 host ceph141
0 hdd 0.19530 osd.0 up 1.00000 1.00000
1 hdd 0.29300 osd.1 up 1.00000 1.00000
6 hdd 1.00000 osd.6 up 1.00000 1.00000
-5 1.48830 host ceph142
2 hdd 0.19530 osd.2 up 1.00000 1.00000
4 hdd 0.29300 osd.4 up 1.00000 1.00000
7 hdd 1.00000 osd.7 up 1.00000 1.00000
-7 1.48830 host ceph143
3 hdd 0.29300 osd.3 up 1.00000 1.00000
5 hdd 0.19530 osd.5 up 1.00000 1.00000
8 hdd 1.00000 osd.8 up 1.00000 1.00000
[root@ceph141 ~]#
[root@ceph141 ~]# ceph -s
cluster:
id: c0ed6ca0-5fbc-11ef-9ff6-cf3a9f02b0d4
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph141,ceph142,ceph143 (age 47m)
mgr: ceph141.fuztcs(active, since 47m), standbys: ceph142.vdsfzv
mds: 1/1 daemons up, 1 standby
osd: 9 osds: 9 up (since 37m), 9 in (since 37m)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 11 pools, 513 pgs
objects: 325 objects, 32 MiB
usage: 821 MiB used, 4.5 TiB / 4.5 TiB avail
pgs: 513 active+clean
[root@ceph141 ~]#
温馨提示:
此步骤变动较大,建议在部署ceph集群时就要定义好相应的规则。
3.7 创建存储池测试自定义规则
1.创建存储池
[root@ceph141 ~]# ceph osd pool create yinzhengjie-c 8 8 replicated ssd_rule
pool 'yinzhengjie-ssd' created
[root@ceph141 ~]#
[root@ceph141 ~]# ceph osd pool create yinzhengjie-hdd 8 8 replicated hdd_rule
pool 'yinzhengjie-hdd' created
[root@ceph141 ~]#
2.查看存储池对应的规则id(启动ssd对应的crush_rule为1,而hdd对应的crush_rule为2)
[root@ceph141 ~]# ceph osd pool ls detail | egrep "ssd|hdd"
pool 12 'yinzhengjie-ssd' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 462 flags hashpspool stripe_width 0 read_balance_score 2.25
pool 13 'yinzhengjie-hdd' replicated size 3 min_size 2 crush_rule 2 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 465 flags hashpspool stripe_width 0 read_balance_score 1.50
[root@ceph141 ~]#
3.查看ssd的PG底层对应的OSD范围为[0-5,共计6块磁盘]
[root@ceph141 ~]# ceph pg ls-by-pool yinzhengjie-ssd
PG OBJECTS DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG LOG_DUPS STATE SINCE VERSION REPORTED UP ACTING SCRUB_STAMP DEEP_SCRUB_STAMP LAST_SCRUB_DURATION SCRUB_SCHEDULING
12.0 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [0,2,5]p0 [0,2,5]p0 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T00:37:37.463325+0000
12.1 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [1,3,4]p1 [1,3,4]p1 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T02:04:52.625959+0000
12.2 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [0,3,4]p0 [0,3,4]p0 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T01:38:47.506968+0000
12.3 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [0,4,5]p0 [0,4,5]p0 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T04:15:17.091066+0000
12.4 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [5,1,4]p5 [5,1,4]p5 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T05:39:37.740284+0000
12.5 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [1,4,3]p1 [1,4,3]p1 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T11:20:15.435413+0000
12.6 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [4,0,5]p4 [4,0,5]p4 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T02:45:43.380018+0000
12.7 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:15 [4,1,3]p4 [4,1,3]p4 2024-09-09T23:37:31.344480+0000 2024-09-09T23:37:31.344480+0000 0 periodic scrub scheduled @ 2024-09-11T06:16:03.860232+0000
* NOTE: Omap statistics are gathered during deep scrub and may be inaccurate soon afterwards depending on utilization. See http://docs.ceph.com/en/latest/dev/placement-group/#omap-statistics for further details.
[root@ceph141 ~]#
4.查看hdd的PG底层对应的OSD范围为[6-8,共计3块磁盘]
[root@ceph141 ~]# ceph pg ls-by-pool yinzhengjie-hdd
PG OBJECTS DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG LOG_DUPS STATE SINCE VERSION REPORTED UP ACTING SCRUB_STAMP DEEP_SCRUB_STAMP LAST_SCRUB_DURATION SCRUB_SCHEDULING
13.0 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [7,8,6]p7 [7,8,6]p7 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T08:08:33.119146+0000
13.1 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [8,7,6]p8 [8,7,6]p8 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T04:58:11.350898+0000
13.2 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [8,6,7]p8 [8,6,7]p8 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T09:34:37.806444+0000
13.3 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [6,8,7]p6 [6,8,7]p6 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T01:33:09.301727+0000
13.4 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [7,6,8]p7 [7,6,8]p7 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T06:35:58.151487+0000
13.5 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [7,8,6]p7 [7,8,6]p7 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T03:11:06.500690+0000
13.6 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [8,6,7]p8 [8,6,7]p8 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T08:44:01.273325+0000
13.7 0 0 0 0 0 0 0 0 0 active+clean 2m 0'0 465:12 [8,6,7]p8 [8,6,7]p8 2024-09-09T23:37:56.343585+0000 2024-09-09T23:37:56.343585+0000 0 periodic scrub scheduled @ 2024-09-11T07:30:21.197921+0000
* NOTE: Omap statistics are gathered during deep scrub and may be inaccurate soon afterwards depending on utilization. See http://docs.ceph.com/en/latest/dev/placement-group/#omap-statistics for further details.
[root@ceph141 ~]#
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/18403765,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号