
Hadoop YARN资源管理-容量调度器(Yahoo!的Capacity Scheduler)
Hadoop YARN资源管理-容量调度器(Yahoo!的Capacity Scheduler)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.队列和子队列
1>.YARN资源调度器概述
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13341939.html
2>.队列概述
容量调度器依赖于队列的概念来控制集群中的资源分配。一个(作业)队列是作业的有序列表。当创建队列是,为其分配一些集群资源。
然后,用户应用程序被提交到此队列以访问队列的资源,关于队列我们需要了解以下几点:
(1)可以配置队列容量的软限制以及硬限制;
(2)被提交到队列的应用程序以FIFO顺序运行;
(3)一旦提交到队列的应用程序开始运行,它们不能被抢占,但随着任务的完成,任何空闲的资源都将被分配到其他资源低于允许容量的队列;
(4)如果一个队列没有使用分配给它的所有资源,那么多余的资源可以被集群中的其他队列使用,从而优化集群的资源利用率;
容量调度器支持使用分层队列来确保组织(在多租户设置中,指共享相同集群的多个组织)资源在其子队列之间共享,这优先于让其他队列使用这些可用资源。
3>.Apache Hadoop的容量调度器默认队列
作业队列是一切事情的开端,可以在"${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml"文件中设置队列,该文件默认位于Hadoop安装目录的下的"etc/hadoop/"目录中。
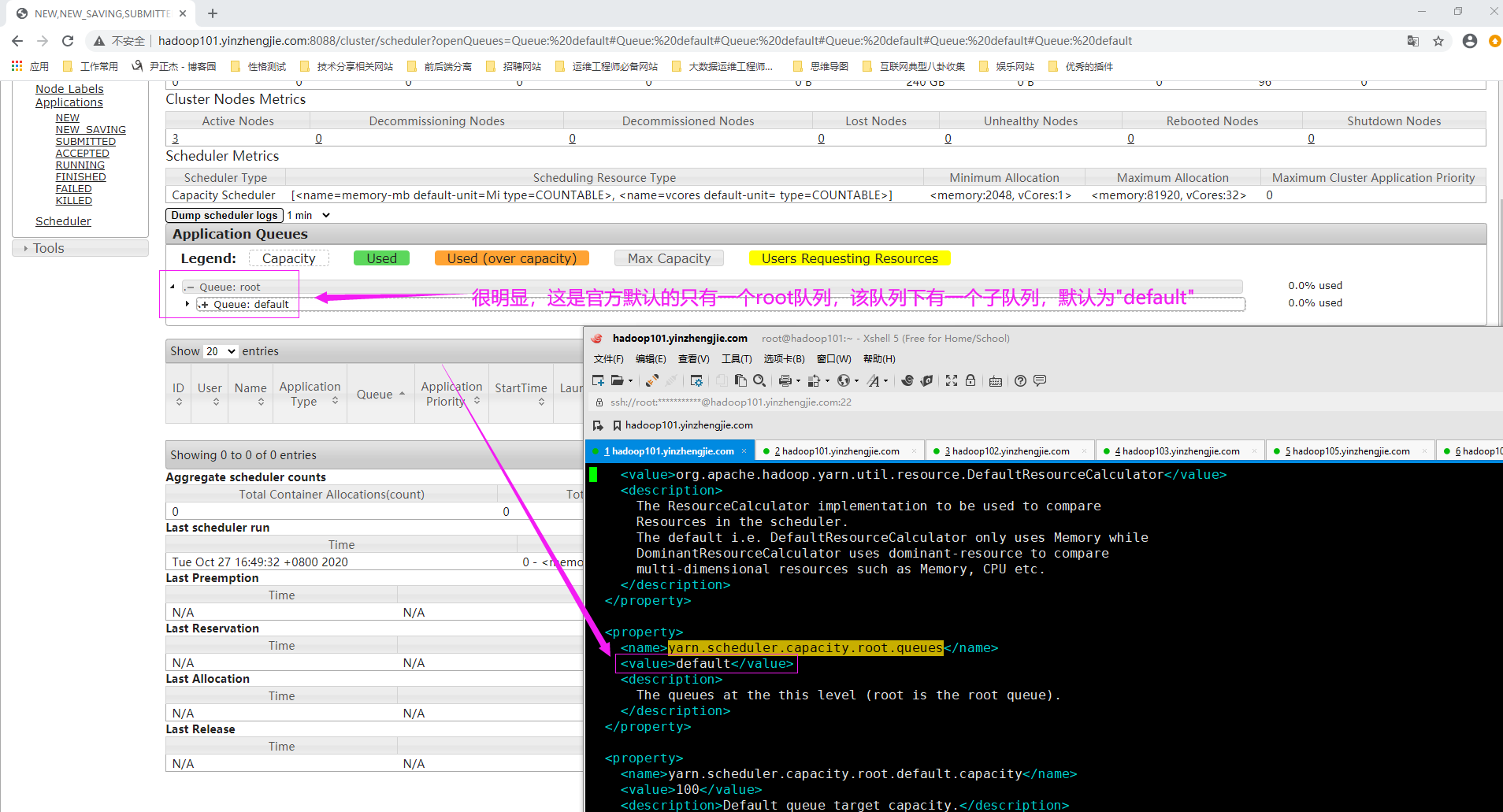
如下图所示,root队列是预定的队列,随后创建的所有队列都将被视为root队列下的子队列(比如Apache Hadoop在其root队列下就有默认的子队列"default")。
4>.容量调度器队列的命名规则
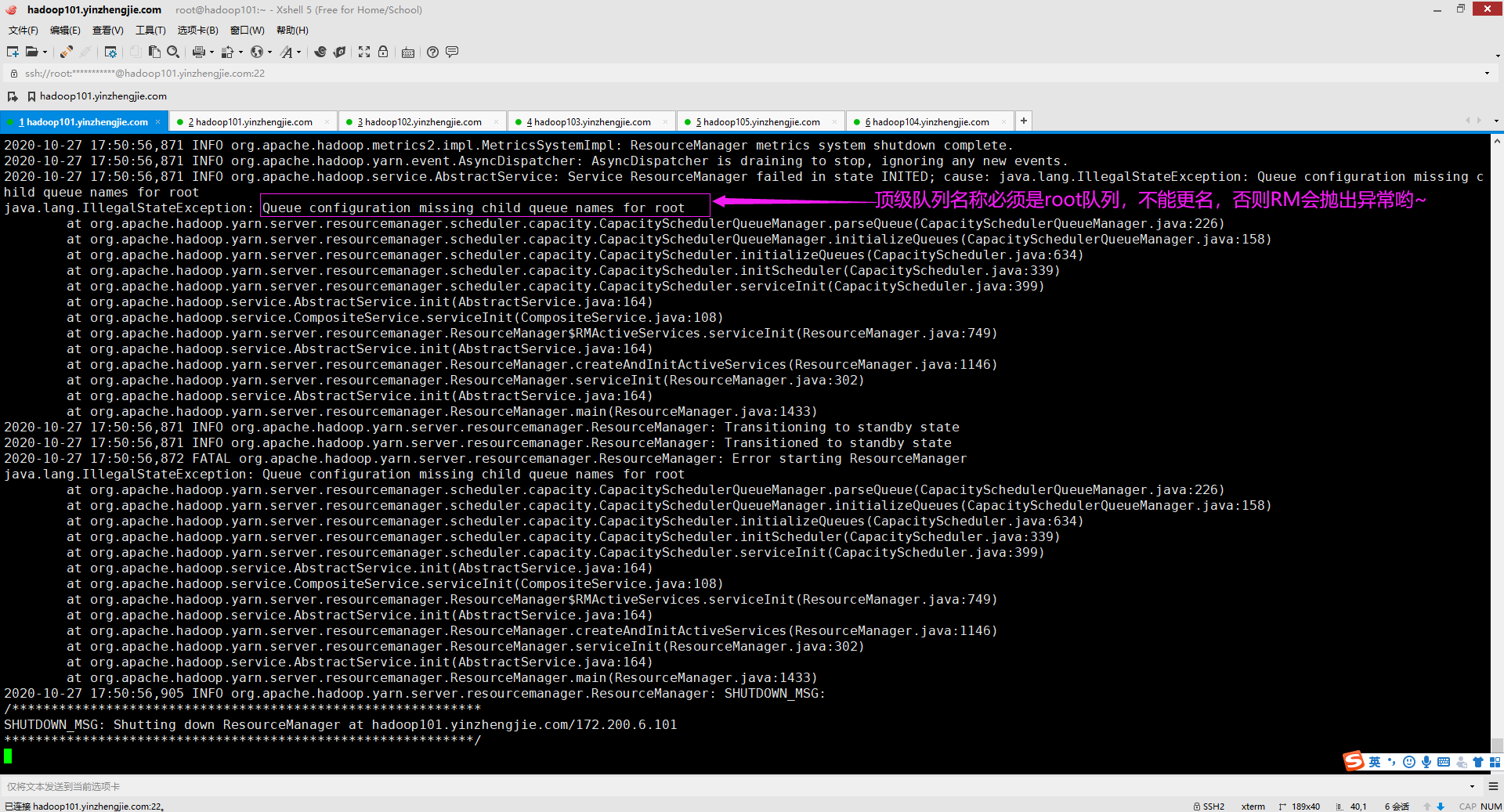
创建任何的队列相对于队列路径来命名,该路径显示队列的层次结构,使用YARN配置属性"yarn.scheduler.capacity.<queue-path>.queues"来配置队列。 yarn.scheduler.capacity.root.queues yarn.scheduler.capacity.root.queues.default.queues yarn.scheduler.capacity.root.queues.yinzhengjie.queues yarn.scheduler.capacity.root.queues.yinzhengjie.queues.op.queues 温馨提示: root始终是创建所有队列的顶级队列(这一点不能更改,如果你将顶级队列进行更名,那么YARN集群在启动时就会抛出如下图所示的异常),此外,子队列可能有也可能没有哟。 顶级子队列(如下图所示的"default")是直接位于root队列下的子队列。在每个顶级子队列下,也可以创建子队列,因此我们可以说队列是支持嵌套的。
5>.分层队列
为了细粒度级别控制资源分配,还可以在每个队列下配置称为分层队列的子队列,从而允许来自特定组织的应用程序有效利用分配给它的所有资源。
队列的多余或空闲资源只有在其子队列满足其资源需求之后才被其他队列使用。
除了队列的配额和最大容量之外,管理员还可以做以下限制:
(1)特定用户可以使用最大的资源量;
(2)每个队列(或每个用户)的待处理任务数量;
(3)每个队列(或每个用户)的活动(或接受)作业的数量;
(4)容量保证和弹性;
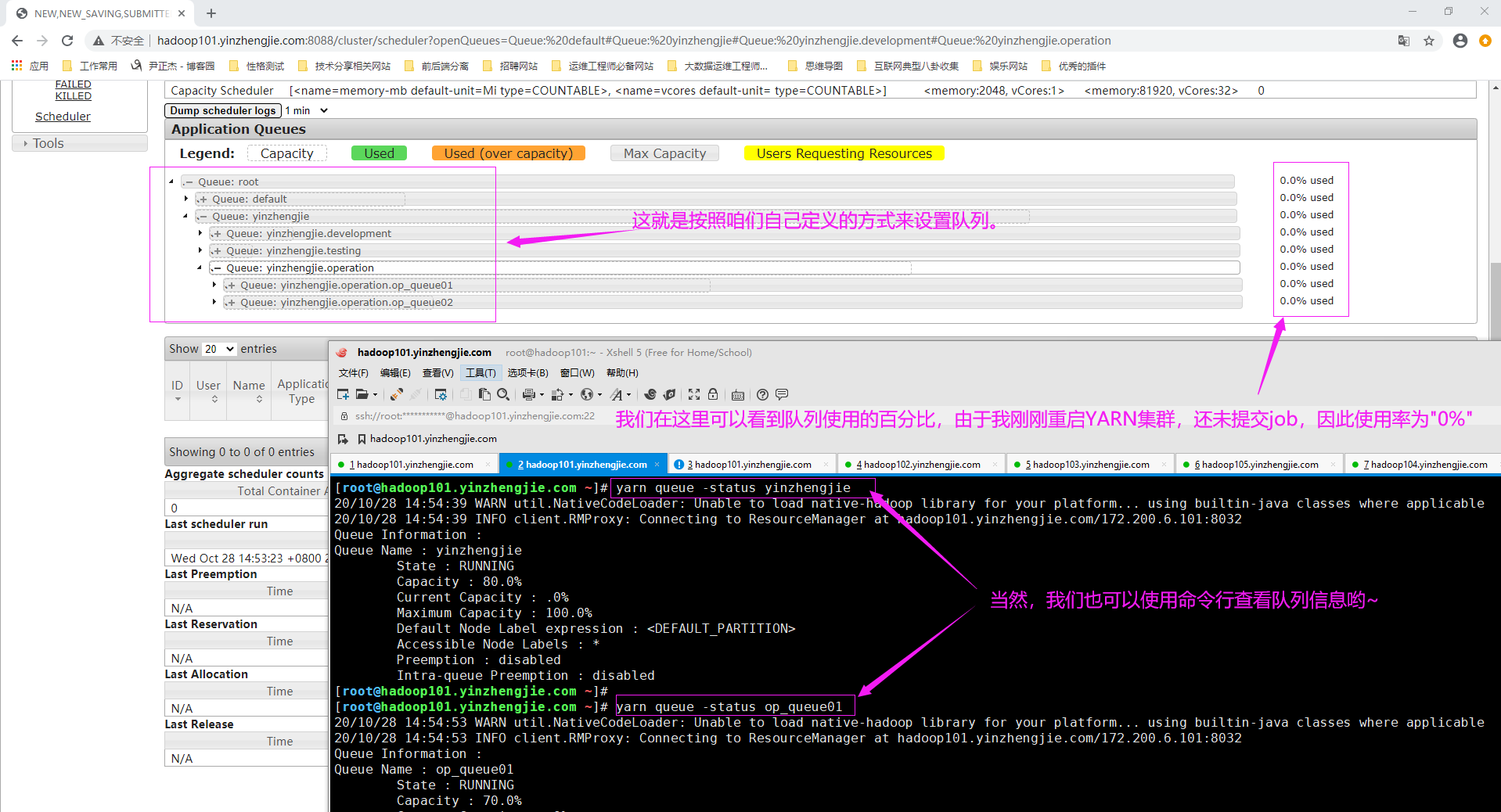
如下图所示,就是典型的容量调度器队列分层的案例。

6>.容量保证
容量调度器的主要目标是确保资源共享的可预测性。它通过为配置的作业队列提供容量保证来实现这一可预测性。发送到队列的应用程序能够访问队列的容量。
每个队列被分配一部分集群容量,因此具体容量在队列中。可以为队列分配的容量设置软和硬(可选)限制。
7>.队列弹性
为了充分利用集群资源,调度器还允许队列具有一定弹性,如果集群中有空闲资源,则队列总是可以利用超出其配置容量的资源。
这里的弹性是指基于资源的可用性(或不可用性),集群可以分配超过(或少于)原始配置的资源。这意味着超载的作业队列可以潜在地使用集群中其他队列的未使用容量,从而最优使用集群资源。
当然,随着其他队列的增加并要求为它们保证容量,Hadoop将回收分配给队列的超额资源。为了防止队列使用比分配的容量更多的资源,可以设置队列弹性的上线。
8>.容量调度器的元素
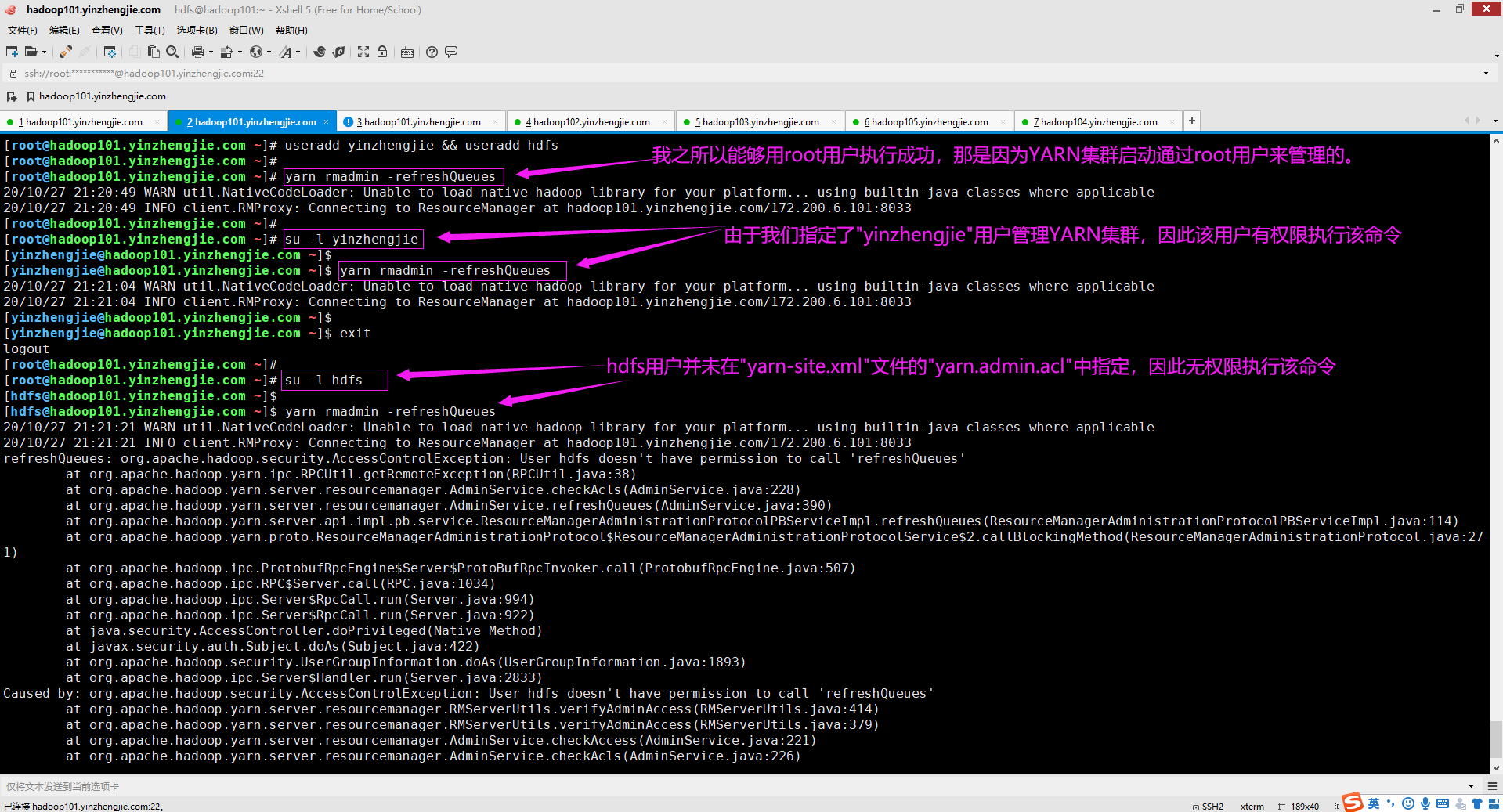
以上我们了解了容量调度器的基本配置元素,接下来我们探讨如何在集群中设置调度器,需要做两件事: (1)设置队列; (2)配置队列的容量; 容量调度器配置文件(${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml)中的队列元素是容量调度器中关键的调度单位,一切都围绕它来做。因此,要配置容量调度器,必须首先配置队列。 容量调度器中可以有多个队列,每个队列具有以下特性: (1)队列名称和完整队列路径名; (2)子队列和应用程序的列表; (3)用户列表及其资源分配限制; (4)队列的保证容量和最大容量; (5)队列的状态(运行或停止); (6)队列的访问控制,格式为Access Control List(ACL); 可以在调度器的配置文件(${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml)中指定所有这些属性,该文件通常位于Hadoop安装目录的下的"etc/hadoop/"目录中。 温馨提示: 如下图所示,可以通过配置"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"文件中的"yarn.admin.acl"属性控制谁可以通过"yarn rmadmin -refreshQueues"命令来更新"capacity-scheduler.xml"文件。 <property> <name>yarn.admin.acl</name> <value>yinzhengjie</value> <description>用于指定谁可以管理YARN集群的ACL,默认值为"*",即任何用户都可以用来管理Hadoop集群.</description> </property>


[root@hadoop101.yinzhengjie.com ~]# yarn rmadmin -help rmadmin is the command to execute YARN administrative commands. The full syntax is: yarn rmadmin [-refreshQueues] [-refreshNodes [-g|graceful [timeout in seconds] -client|server]] [-refreshNodesResources] [-refreshSuperUserGroupsConfiguration] [-refreshUserToGroupsMappings ] [-refreshAdminAcls] [-refreshServiceAcl] [-getGroup [username]] [-addToClusterNodeLabels <"label1(exclusive=true),label2(exclusive=false),label3">] [-removeFromClusterNodeLabels <label1,label2,label3>] [-replaceLabelsOnNode <"node1[:port]=label1,label2 node2[:port]=label1"> [-failOnUnknownNodes]] [-directlyAccessNodeLabelStore] [-refreshClusterMaxPriority] [-updateNodeResource [NodeID] [MemSize] [vCores] ([OvercommitTimeout]) [-help [cmd]] -refreshQueues: Reload the queues' acls, states and scheduler specific properties. ResourceManager will reload the mapred-queues configuration file. -refreshNodes [-g|graceful [timeout in seconds] -client|server]: Refresh the hosts information at the ResourceManager. Here [-g|graceful [timeout in seconds] -client|server] is optional, if we specify the timeout then ResourceManager will wait for timeout before marking the NodeManager as decommissioned. The -client|server indicates if the timeout tracking should be handled by the client or the ResourceManager. The client-side tracking is blocking, while the server-side tracking is not. Omitting the timeout, or a timeout of -1, indicates an infinite timeout. Known Issue: the server-side tracking will immediately decommission if an RM HA failover occurs. -refreshNodesResources: Refresh resources of NodeManagers at the ResourceManager. -refreshSuperUserGroupsConfiguration: Refresh superuser proxy groups mappings -refreshUserToGroupsMappings: Refresh user-to-groups mappings -refreshAdminAcls: Refresh acls for administration of ResourceManager -refreshServiceAcl: Reload the service-level authorization policy file. ResourceManager will reload the authorization policy file. -getGroups [username]: Get the groups which given user belongs to. -addToClusterNodeLabels <"label1(exclusive=true),label2(exclusive=false),label3">: add to cluster node labels. Default exclusivity is true -removeFromClusterNodeLabels <label1,label2,label3> (label splitted by ","): remove from cluster node labels -replaceLabelsOnNode <"node1[:port]=label1,label2 node2[:port]=label1,label2"> [-failOnUnknownNodes] : replace labels on nodes (please note that we do not support specifying multiple lab els on a single host for now.) [-failOnUnknownNodes] is optional, when we set this option, it will fail if specified nodes are unknown. -directlyAccessNodeLabelStore: This is DEPRECATED, will be removed in future releases. Directly access node label store, with this option, all node label related operations will not conn ect RM. Instead, they will access/modify stored node labels directly. By default, it is false (access via RM). AND PLEASE NOTE: if you configured yarn.node-labels.fs-store.root-dir to a local directory (instead of NFS or HDFS), this option will only work when the command run on the machine where RM is running. -refreshClusterMaxPriority: Refresh cluster max priority -updateNodeResource [NodeID] [MemSize] [vCores] ([OvercommitTimeout]): Update resource on specific node. -help [cmd]: Displays help for the given command or all commands if none is specified. Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines The general command line syntax is: command [genericOptions] [commandOptions] [root@hadoop101.yinzhengjie.com ~]#
9>.队列创建示例
以下示例是将第5点介绍的分层队列所画图的关系来定义容量调度器的配置。 配置成功后可直接使用"yarn rmadmin -refreshQueues"命令来刷新队列配置信息,而无需重启YARN集群。
温馨提示:
(1)我们不能直接向root队列提交JOB,当然也不能向父队列提交JOB,仅能向叶子队列提交JOB。
(2)如果您试图想要将正在运行的叶子队列更改为父队列(即将状态为RUNNING的叶子队列创建为父队列),则需要重启YARN集群哟;
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml
[root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- root始终是创建所有队列的顶级队列,因此我们现在顶级队列中创建2个子顶级队列。 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,yinzhengjie</value>
<description>这是为root顶级队列定义子队列,默认值为:"default"</description>
</property>
<!-- 注意哈,当我们定义好顶级队列的子队列后,我们接下来做为其设置队列容量,如果你没有做该步骤,那么启动RM将会失败。 -->
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.capacity</name>
<value>80</value>
<description>这里指定的是root顶队列下的yinzhengjie这个子队列,该队列占用整个集群的80%的资源</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>20</value>
<description>这里指定的是root顶队列下的default这个子队列,该队列占用整个集群的20%的资源</description>
</property>
<!--
我们可以为子顶队列继续分配子队列,比如我们将yinzhengjie这个队列分为:"operation","development"和"testing"这3个子队列。
下面配置的队列存在以下关系:
(1)我们可以说"yinzhengjie"这个队列是"operation","development"和"testing"的父队列;
(2)"operation","development"和"testing"这3个队列是"yinzhengjie"的子队列;
温馨提示:
我们不能直接向父队列提交作业,只能向叶子队(就是没有子队列的队列)列提交作业。
-->
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.queues</name>
<value>operation,development,testing</value>
<description>此处我在"yinzhengjie"这个顶级队列中定义了三个子顶队列,分别为"operation","development"和"testing"</description>
</property>
<!--
按百分比为"yinzhengjie"的3个子队列(即"operation","development"和"testing")分配容量,其容量之和为100%。
需要注意的是:
各个子队列容量之和为父队列的总容量,但其父队列的总容量又受顶队列资源限制;
换句话说,"operation","development"和"testing"这3个队列能使用的总容量只有集群总量的80%,因为"yinzhengjie"这个队列容量我配置的就是80%.
-->
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.operation.capacity</name>
<value>85</value>
<description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.development.capacity</name>
<value>10</value>
<description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.testing.capacity</name>
<value>5</value>
<description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description>
</property>
<!--
接下来我做的的操作基本上是在重复上述的步骤,大致步骤如下:
(1)为"root.yinzhengjie.operation"队列新建了2个子队列,分别为:"op_queue01","op_queue02";
(2)再为这些叶子队列配置容量比例;
-->
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.operation.queues</name>
<value>op_queue01,op_queue02</value>
<description>此处我在"yinzhengjie"这个顶级队列中定义了三个子顶队列,分别为"operation","development"和"testing"</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue01.capacity</name>
<value>70</value>
<description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.capacity</name>
<value>30</value>
<description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description>
</property>
</configuration>
[root@hadoop101.yinzhengjie.com ~]#
二.集群如何分配资源
1>.集群资源概述
队列资源分配的第一个原则是Hadoop永远不会让容量空闲。如果队列不适用为其配置的容量,则其队列将获取这些资源,即这这些队列将使用超出其配置容量的资源。这就是上面所说的弹性原理。 Hadoop根据每个队列当前使用配置容量的多少来确定如何在集群队列之间分配资源。它首先向使用配置容量最少的队列分配资源,从而在队列中分配可用的资源。 队列当前使用的容量越低,从集群接受额外资源的优先级越高。一旦父队列获得了额外的资源,它将使用完全相同的原则,首先将这些资源分配给当前使用配置容量最少的叶子队列。 我们来看个分析个案例,假设目前集群有100TB内存容量,按照上面的案例的容量比例来划分,将顶级队列root划分成"yinzhengjie"和"default"两个顶级子队列。 我们以"yinzhengjie"队列为例,且满足以下三个条件: (1)假设"operation"队列没有作业运行情况,这意味着"operation"所有的分配容量(该队列分配容量约有68T内存,其占"yinzhengjie"队列的85%的资源)是空闲的; (2)假设另外两个队列,即"development"和"testing",正在充分利用其配置容量(假设利用率高达90%以上); (3)假设两个用户"Jason"和"Tom"两位DevOps开发人员将每个应用程序提交给"op_queue02"叶子队列; 集群资源分配情况如下: (1)即使"op_queue02"队列的配置容量只有父队列("operation")的百分之30%,即配置容量总共只有约20.4T; (2)但由于"op_queue02"队列父队列("operation")的其他叶子队列(即"op_queue01")中没有任何作业在运行,所以调度器为两个用户中的每个用户分配了20.4T内存空间; (3)如果有更多的用户将作业提交到"op_queue02"叶子队列,则它们可以占用分配给"op_queue02"叶子队列的所有资源,因为没有人将作业提交给该队列(即"op_queue01"队列);
综上所述,当没有人将作业提交到"op_queue01"叶子队列时,所有这一切都很好。当有人将作业提交到此队列时会发生什么情况呢?
(1)因为队列的资源已被"op_queue02"叶子队列中运行的作业所使用,那么这个作业必须等到"op_queue02"队列中运行的作业开始释放容量才能运行;
(2)随着时间的推移,两个叶子队列的资源使用趋于配置的2:1(因为我配置的"op_queue01"占据父队列(即"operation"队列)的70%,而"op_queue02"占据父队列(即"operation"队列)的30%)的比例;
(3)如果不希望用户等待使用向数据队列承诺的"容量保证",则必须启用抢占模式(后面会详细介绍)。
温馨提示:
以我的经验,使用容量调度器是最重要的两点是容量平衡和弹性。这两者之间有一个折中:如果设置刚性容器限制(配置最大容量),则队列变得不那么有弹性,从而背离了容量调度器的关键目标之一。
2>.限制用户容量
现在我们知道了如何创建队列和叶子队列,以及如何配置它们的容量。接下来我们讨论一下集群中最重要的实体:用户!即将作业提交配置的队列的用户。 容量调度器使用FIFO原则(注意哈,这里不是指FIFO调度器),因此先前提交大作业将优先于稍后提交的作业运行。 我们可以限制分配给叶子队列中运行作业的用户的资源。可以使用以下参数限制用户可以消耗多少叶子队列的容量: [root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml ... <!-- 配置限制用户容量的相关参数 --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.user-limit-factor</name> <value>2</value> <description> 为支持叶子队列中特定用户设置最大容量。defalut队列用户将百分比限制在0.0到1.0之间。此参数的默认值为1,这意味着用户可以使用所有叶子队列的配置容量。 如果将此参数的值设置大于1,则用户可以使用超出叶子队列容量限制的资源。比如设置为2,则意味着用户最多可以使用2倍与配置容量的容量哟。 如果将其设置为0.25,则该用户仅可以使用队列配置容量的四分之一。 </description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.maximum-capacity</name> <value>50</value> <description> 此参数用于设置容量的硬限制,此参数的默认值为100。如果要确保用户不能获取所有父队列的容量,则可以设置此参数。 此处我将向"root.yinzhengjie.operation.op_queue02"叶子队列提交作业的用户不能占用"root.yinzhengjie.operation"队列容量的50%以上。 </description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.minmum-user-limit-percent</name> <value>10</value> <description> 假设配置了可以占用500GB RAM的叶子队列,如果20个用户象征队列提交作业怎么样?当然,你可以让所有20个用户的容器占用25GB的RAM,但那样太慢了。 我们可以通过配置该参数来控制分配给叶子队列用户的最小资源百分比。 如果将此参数的值设置为10,则意味着通过此队列运行的应用程序至少会被分配10%的已配置给op_queue02叶子队列的容量。 第一个向这个叶子队列提交作业的用户可以使用100%的叶子队列的资源分配,随着其他用户开始将作业提交到此队列,最终每个用户可以稳定地使用队列10%的资源, 综上所述,只有10个用户可以随时使用队列,而其他用户必须等待前10名用户任意一个用户释放资源。才能依次运行已提交的Job。 </description> </property> ... [root@hadoop101.yinzhengjie.com ~]#
3>.限制应用程序数量
单个用户或队列可能垄断集群的资源。为了避免过度使用集群,可以限制任何给定时间内在集群中能够调度的最大应用程序数量。 限制应用程序数量的关键参数如下所示: [root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml ... <!-- 限制应用程序数量 --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.maximum-applications</name> <value>5000</value> <description> 该参数可以对容量调度器提交的应用程序数量设置上限,即为在任何时候给定时间可以运行的最大应用程序数量设置硬限制。此参数root队列的默认值为10000。 对应的子顶队列以及叶子队列的最大应用上限也有对应的计算公式,比如我们要计算default队列的最大容器大小公式如下: default_max_applications = root_max_applications * (100 - yarn.scheduler.capacity.root.yinzhengjie.capacity) 最终算得default_max_applications的值为2000(带入上面的公式:"10000 * (100 - 80)%",即:10000 * 0.2) </description> </property> <property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>10</value> <description> 该参数用于设置所有正在运行的ApplicationMasters可以使用的集群资源的百分比,即控制并发运行的应用程序的数量。此参数的默认值为10%。 当设置为10%这意味着所有ApplicationMaster不能占用集群资源的10%以上(ApplicationMaster容器的RAM内存分配,这是为应用程序创建第一个容器)。 </description> </property> ... [root@hadoop101.yinzhengjie.com ~]#
4>.抢占申请
抢占一个应用程序意味着其他应用程序的容器可能要被杀死,以便于为新应用程序(ApplicationMaster)腾出空间。
如果不希望后来的应用程序在特定的叶子队列等待,因为叶子队列中其他运行的应用程序正在占用所有分配的资源,则可以使用抢占策略。
在这种情况下,尽管已经为"队列"设置一个容量,但是没有可用的资源给这个叶子队列分配。杀死ApplicationMaster容器只能作为最后的手段,优先考虑杀死尚未执行的容器。
YARN可以通过以下两种方式抢占作业:
最小份额抢占:
当资源池的占用低于配置的最小份额时。
公平份额抢占:
当一个资源池在其公平份额下运行时。
温馨提示:
(1)这两种方式中,最小份额抢占更严格。当一个资源池低于其最小份额运行的时长达到某个特定的值后,最小份额抢占会立即介入。该时长取决于最小共享抢占超时参数。
(2)公平份额抢占则没这么激进。只有当一个资源池在其公平份额的一半以下运行某段时长后,才开始介入。该时长取决于公平份额抢占超时时间。
(3)一旦抢占开始,低于最小份额的资源池可以增加至其最小份额,同时低于公平份额50%的资源池也会一直增加至其公平份额。
可以在yarn-site.xml文件中设置几个与抢占相关的配置参数:
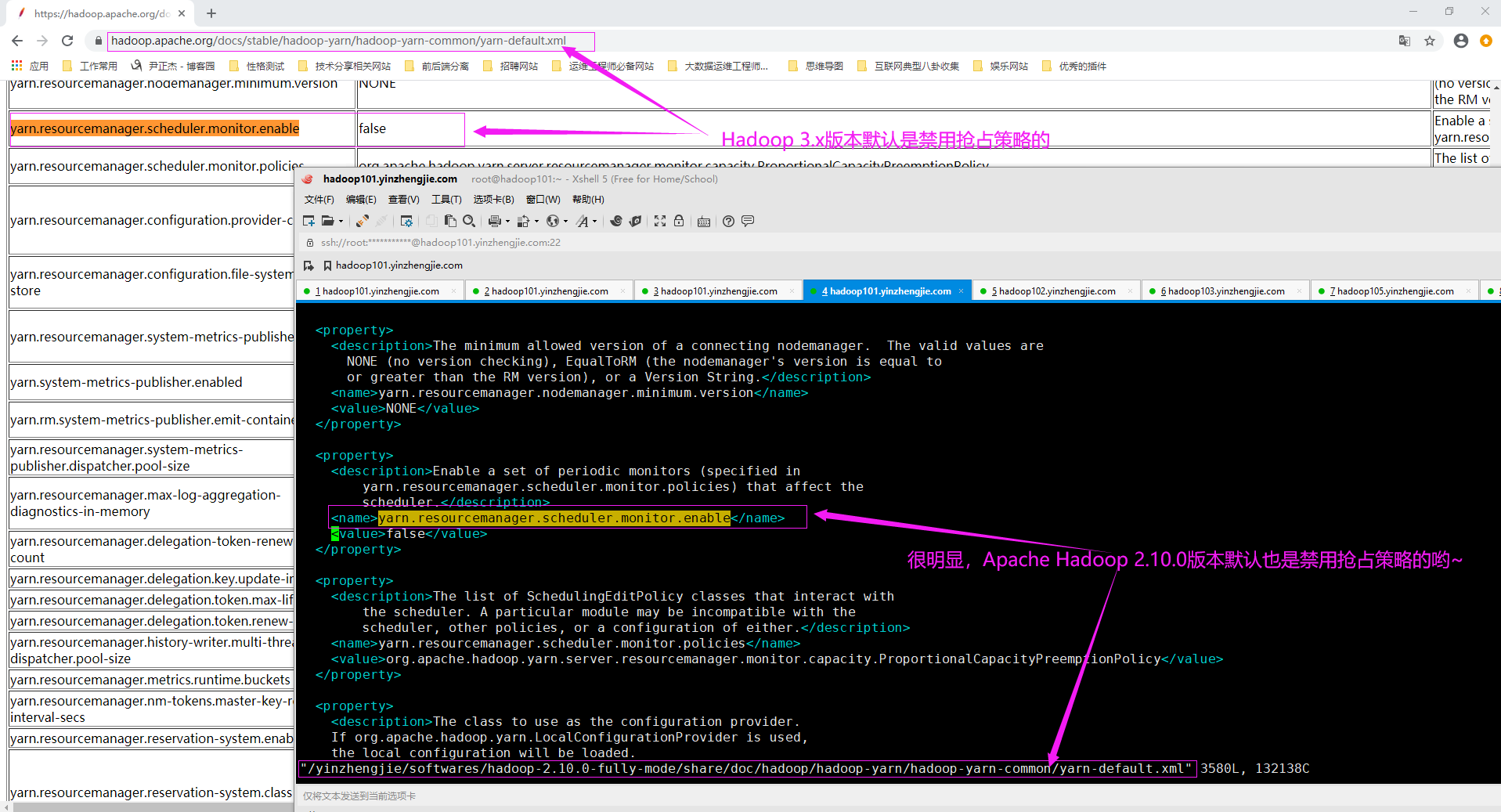
(1)如下图所示,Apache Hadoop在默认情况下,已经禁用了抢占策略,将"yarn.resourcemanager.scheduler.monitor.enable"的值设置为true可以启用抢占策略。
(2)也可以通过配置"yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_round"参数来抢占速度,即设置在一轮定期监控中抢占资源的最大百分比。
5>.启用容量调度器
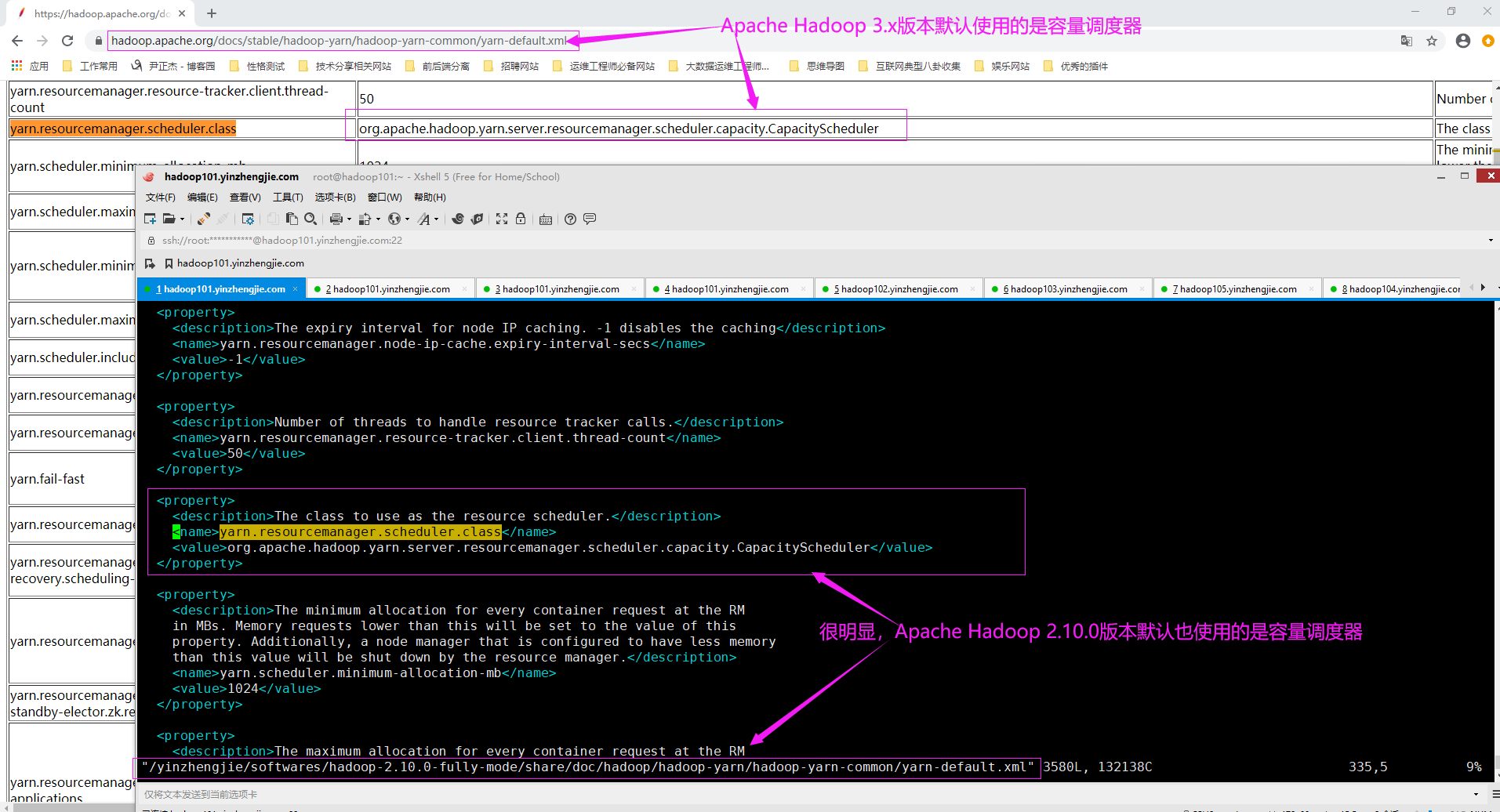
必须配置ResourceManager才能在集群中开启并使用容量调度器。 在"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"文件中为"yarn.resourcemanager.scheduler.class"参数添加以下属性,就可以使用容量调度器。 <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> <description>指定resourcemanager的调度器(如上所示,默认为容量调度器)</description> </property> 如下图所示,Apache Hadoop默认的调度器是容量调度器,因为我们可以不做该步骤,除非你要显示指定你使用的调度器是公平调度器。 温馨提示: 容量调度器(Yahoo!的Capacity Scheduler)是Apache Hadoop的默认调度器,而对于某些Hadoop发行版本,如Cloudera,则公平调度器(Fackbook的Fair Scheduler)是默认调度器。
6>.队列状态管理
可以随时在跟对任意队列级别停止或启动队列,并使用"yarn rmadmin -refreshQueues"使得配置生效,无需重启整个YARN集群。
队列有两种状态,即STOPPED和RUNNING,默认均是RUNNING状态。
温馨提示:
(1)如果停止root或者父队列,则叶子队列将变为非活动状态(即STOPPED状态)。
(2)如果停止运行中的队列(即将一个队列由RUNNING状态变更为STOPPED状态),则当前正在运行的应用程序将继续运行,直到完成该队列中的已经运行的所有作业,并且不会将新的的应用程序提交到此队列。
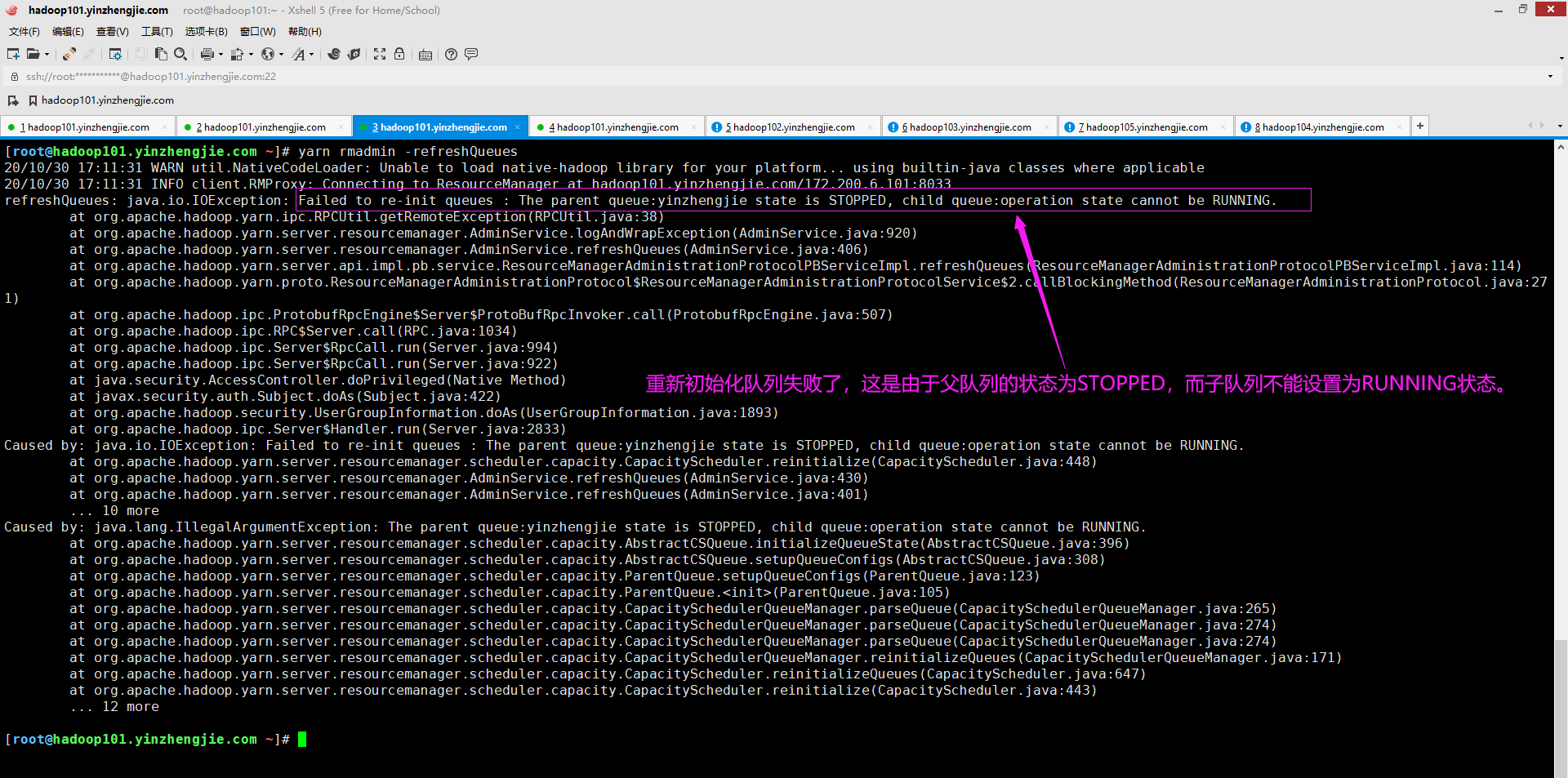
(3)若父队列为STOPPED,则子队列无法配置为RUNNING,若您真这样做,将会抛出如下图所示的异常哟。
7>.博主推荐阅读
博主推荐阅读: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
三.一个典型的容量调度器案例
1>.配置一个完整的容量调度器示例
[root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- root始终是创建所有队列的顶级队列,因此我们现在顶级队列中创建2个子顶级队列。 --> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,yinzhengjie</value> <description>这是为root顶级队列定义子队列,默认值为:"default"</description> </property> <!-- 注意哈,当我们定义好顶级队列的子队列后,我们接下来做为其设置队列容量,如果你没有做该步骤,那么启动RM将会失败。 --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.capacity</name> <value>80</value> <description>这里指定的是root顶队列下的yinzhengjie这个子队列,该队列占用整个集群的80%的资源</description> </property> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>20</value> <description>这里指定的是root顶队列下的default这个子队列,该队列占用整个集群的20%的资源</description> </property> <!-- 我们可以为子顶队列继续分配子队列,比如我们将yinzhengjie这个队列分为:"operation","development"和"testing"这3个子队列。 下面配置的队列存在以下关系: (1)我们可以说"yinzhengjie"这个队列是"operation","development"和"testing"的父队列; (2)"operation","development"和"testing"这3个队列是"yinzhengjie"的子队列; 温馨提示: 我们不能直接向父队列提交作业,只能向叶子队(就是没有子队列的队列)列提交作业。 --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.queues</name> <value>operation,development,testing</value> <description>此处我在"yinzhengjie"这个顶级队列中定义了三个子顶队列,分别为"operation","development"和"testing"</description> </property> <!-- 按百分比为"yinzhengjie"的3个子队列(即"operation","development"和"testing")分配容量,其容量之和为100%。 需要注意的是: 各个子队列容量之和为父队列的总容量,但其父队列的总容量又受顶队列资源限制; 换句话说,"operation","development"和"testing"这3个队列能使用的总容量只有集群总量的80%,因为"yinzhengjie"这个队列容量我配置的就是80%. --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.capacity</name> <value>85</value> <description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.development.capacity</name> <value>10</value> <description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.testing.capacity</name> <value>5</value> <description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description> </property> <!-- 接下来我做的的操作基本上是在重复上述的步骤,大致步骤如下: (1)为"root.yinzhengjie.operation"队列新建了2个子队列,分别为:"op_queue01","op_queue02"; (2)再为这些叶子队列配置容量比例; --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.queues</name> <value>op_queue01,op_queue02</value> <description>此处我在"yinzhengjie"这个顶级队列中定义了三个子顶队列,分别为"operation","development"和"testing"</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue01.capacity</name> <value>70</value> <description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.capacity</name> <value>30</value> <description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源归该队列使用</description> </property> <!-- 配置限制用户容量的相关参数 --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.user-limit-factor</name> <value>2</value> <description> 为支持叶子队列中特定用户设置最大容量。defalut队列用户将百分比限制在0.0到1.0之间。此参数的默认值为1,这意味着用户可以使用所有叶子队列的配置容量。 如果将此参数的值设置大于1,则用户可以使用超出叶子队列容量限制的资源。比如设置为2,则意味着用户最多可以使用2倍与配置容量的容量哟。 如果将其设置为0.25,则该用户仅可以使用队列配置容量的四分之一。 </description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.maximum-capacity</name> <value>50</value> <description> 此参数用于设置容量的硬限制,此参数的默认值为100。如果要确保用户不能获取所有父队列的容量,则可以设置此参数。 此处我将向"root.yinzhengjie.operation.op_queue02"叶子队列提交作业的用户不能占用"root.yinzhengjie.operation"队列容量的50%以上。 </description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.minmum-user-limit-percent</name> <value>10</value> <description> 假设配置了可以占用500GB RAM的叶子队列,如果20个用户象征队列提交作业怎么样?当然,你可以让所有20个用户的容器占用25GB的RAM,但那样太慢了。 我们可以通过配置该参数来控制分配给叶子队列用户的最小资源百分比。如果将此参数的值设置为10,则意味着通过此队列运行的应用程序至少会被分配10%的已配置给op_queue02叶子队列的容量。 综上所述,此参数可以限制用户的最小值资源百分比,最大值取决于集群中运行应用程序的用户数,它的工作流程如下: (1)当第一个向这个叶子队列提交作业的用户可以使用100%的叶子队列的资源分配; (2)当第二个向这个叶子队列提交作业的用户使用该队列的50%的资源; (3)当第三个用户向队列提交应用程序时,所有用户被限制为该队列33%; (4)随着其他用户开始将作业提交到此队列,最终每个用户可以稳定地使用队列10%的资源,但不会低于该值,这就是我们设置最小资源百分比的作用; (5)需要注意的时,只有10个用户可以随时使用队列(因为10个用户已经占用完该队列资源),而其他用户必须等待前10名用户任意一个用户释放资源。才能依次运行已提交的Job; </description> </property> <!-- 限制应用程序数量 --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.maximum-applications</name> <value>5000</value> <description> 该参数可以对容量调度器提交的应用程序数量设置上限,即为在任何时候给定时间可以运行的最大应用程序数量设置硬限制。此参数root队列的默认值为10000。 对应的子顶队列以及叶子队列的最大应用上限也有对应的计算公式,比如我们要计算default队列的最大容器大小公式如下: default_max_applications = root_max_applications * (100 - yarn.scheduler.capacity.root.yinzhengjie.capacity) 最终算得default_max_applications的值为2000(带入上面的公式:"10000 * (100 - 80)%",即:10000 * 0.2) </description> </property> <property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>0.2</value> <description> 该参数用于设置所有正在运行的ApplicationMasters可以使用的集群资源的百分比,即控制并发运行的应用程序的数量。此参数的默认值为10%。 当设置为0.2这意味着所有ApplicationMaster不能占用集群资源的20%以上(ApplicationMaster容器的RAM内存分配,这是为应用程序创建第一个容器)。 </description> </property> <!-- 配置队列管理权限 --> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.acl_administer_queue</name> <value>hadoop_admin</value> <description> 指定谁可以管理root.yinzhengjie.operation.op_queue02该叶子队列,其中"*"表示术语指定组的任何人都可以管理此队列。 可以配置容量调度器队列管理员来执行队列管理操作,例如将应用程序提交到队列,杀死应用程序,停止队列和查看队列信息等。 上面我配置的"hadoop_admin",这意味着在hadoop_admin组的所有用户均可以管理"root.yinzhengjie.operation.op_queue02"队列哟~ </description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.acl_submit_applications</name> <value>jason,yinzhengjie</value> <description> 此参数可以指定那些用户将应用程序提交到队列的ACL。如果不知定制,则从层次结果中的父队列派生ACL。根队列的默认值为"*",即表示任何用户 常规用户无法查看或修改其他用户提交的应用程序,作为集群管理员,你可以对队列和作业执行以下操作: (1)在运行时更改队列的定义和属性; (2)停止队列以防止提交新的应用程序; (3)启动停止的备份队列; </description> </property> <!-- 配置用户映射到队列 --> <property> <name>yarn.scheduler.capacity.queue-mappings</name> <value>u:jason:op_queue02,g:hadoop_admin:op_queue01,u:yinzhengjie:%primary_group</value> <description> 此参数可以将用户映射到指定队列,其中u表示用户,g表示组。 "u:jason:op_queue02": 表示将jason用户映射到op_queue02队列中。 "g:hadoop_admin:op_queue01": 表示将hadoop_admin组中的用户映射到op_queue01队列中。 "u:yinzhengjie:%primary_group": 表示将yinzhengjie用户映射到与Linux中主组名相同的队列。 温馨提示: YARN从左到右匹配此属性的映射,并使用其找到的第一个有效映射。 </description> </property> <!-- 配置队列运行状态 --> <property> <name>yarn.scheduler.capacity.root.state</name> <value>RUNNING</value> <description> 可以随时在跟对任意队列级别停止或启动队列,并使用"yarn rmadmin -refreshQueues"使得配置生效,无需重启整个YARN集群。 队列有两种状态,即STOPPED和RUNNING,默认均是RUNNING状态。 需要注意的是: (1)如果停止root或者父队列,则叶子队列将变为非活动状态(即STOPPED状态)。 (2)如果停止运行中的队列,则当前正在运行的应用程序会继续运行直到完成,并且不会将新的的应用程序提交到此队列。 (3)若父队列为STOPPED,则子队列无法配置为RUNNING,若您真这样做,将会抛出异常哟。 温馨提示: 可以通过ResourceManager Web UI的Application页面中的Scheduler页面,来监视容量调度器队列的状态和设置。 </description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.state</name> <value>RUNNING</value> <description>将"root.yinzhengjie"队列的状态设置为"RUNNING"状态</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.state</name> <value>RUNNING</value> <description>将"root.yinzhengjie.operation"队列设置为"RUNNING"状态</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.development.state</name> <value>RUNNING</value> <description>将"root.yinzhengjie.development"队列设置为"RUNNING"状态</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.testing.state</name> <value>RUNNING</value> <description>将"root.yinzhengjie.testing"队列设置为"RUNNING"状态</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue01.state</name> <value>RUNNING</value> <description>将"root.yinzhengjie.operation.op_queue01"队列设置为"RUNNING"状态</description> </property> <property> <name>yarn.scheduler.capacity.root.yinzhengjie.operation.op_queue02.state</name> <value>RUNNING</value> <description>将"root.yinzhengjie.operation.op_queue02"队列设置为"RUNNING"状态</description> </property> </configuration> [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]#
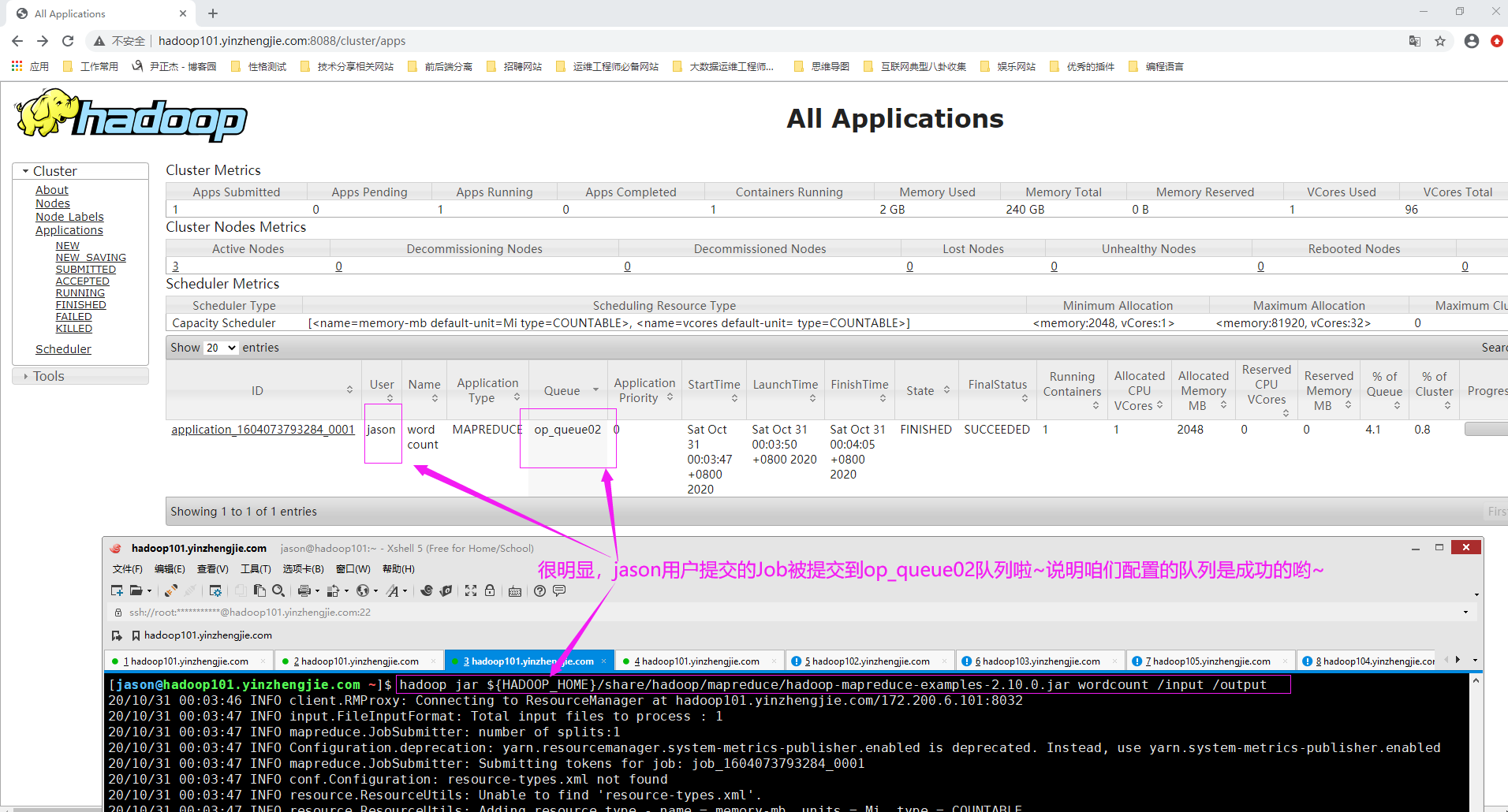
2>.使用jason用户提交一个Job,在RM WebUI查看其队列信息(如下图所示,若是op_queue02说明咱们的配置生效啦~)
[root@hadoop101.yinzhengjie.com ~]# su -l jason [jason@hadoop101.yinzhengjie.com ~]$ [jason@hadoop101.yinzhengjie.com ~]$ [jason@hadoop101.yinzhengjie.com ~]$ hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /input /output 20/10/31 00:03:46 INFO client.RMProxy: Connecting to ResourceManager at hadoop101.yinzhengjie.com/172.200.6.101:8032 20/10/31 00:03:47 INFO input.FileInputFormat: Total input files to process : 1 20/10/31 00:03:47 INFO mapreduce.JobSubmitter: number of splits:1 20/10/31 00:03:47 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled 20/10/31 00:03:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1604073793284_0001 20/10/31 00:03:47 INFO conf.Configuration: resource-types.xml not found 20/10/31 00:03:47 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 20/10/31 00:03:47 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE 20/10/31 00:03:47 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE 20/10/31 00:03:47 INFO impl.YarnClientImpl: Submitted application application_1604073793284_0001 20/10/31 00:03:47 INFO mapreduce.Job: The url to track the job: http://hadoop101.yinzhengjie.com:8088/proxy/application_1604073793284_0001/ 20/10/31 00:03:47 INFO mapreduce.Job: Running job: job_1604073793284_0001 20/10/31 00:03:55 INFO mapreduce.Job: Job job_1604073793284_0001 running in uber mode : false 20/10/31 00:03:55 INFO mapreduce.Job: map 0% reduce 0% 20/10/31 00:04:00 INFO mapreduce.Job: map 100% reduce 0% 20/10/31 00:04:05 INFO mapreduce.Job: map 100% reduce 100% 20/10/31 00:04:06 INFO mapreduce.Job: Job job_1604073793284_0001 completed successfully 20/10/31 00:04:07 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=1014 FILE: Number of bytes written=417761 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=781 HDFS: Number of bytes written=708 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=3152 Total time spent by all reduces in occupied slots (ms)=2538 Total time spent by all map tasks (ms)=3152 Total time spent by all reduce tasks (ms)=2538 Total vcore-milliseconds taken by all map tasks=3152 Total vcore-milliseconds taken by all reduce tasks=2538 Total megabyte-milliseconds taken by all map tasks=6455296 Total megabyte-milliseconds taken by all reduce tasks=5197824 Map-Reduce Framework Map input records=3 Map output records=99 Map output bytes=1057 Map output materialized bytes=1014 Input split bytes=119 Combine input records=99 Combine output records=75 Reduce input groups=75 Reduce shuffle bytes=1014 Reduce input records=75 Reduce output records=75 Spilled Records=150 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=329 CPU time spent (ms)=1840 Physical memory (bytes) snapshot=532664320 Virtual memory (bytes) snapshot=7253307392 Total committed heap usage (bytes)=419430400 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=662 File Output Format Counters Bytes Written=708 [jason@hadoop101.yinzhengjie.com ~]$
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/13383344.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号