

在YARN集群上运行部署MapReduce分布式计算框架
在YARN集群上运行部署MapReduce分布式计算框架
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本篇博客主要讲解在YARN集群上配置Mapreduce分布式计算框架。与此同时,启动HistoryServer服务,便于在RM Web UI界面查看聚合日志内容。
一.本地运行一个MapReduce程序
1>.准备数据


[root@hadoop101.yinzhengjie.com ~]# vim hadoop.txt [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat hadoop.txt The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.[root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# ll total 4 -rw-r--r-- 1 root root 662 Oct 22 16:26 hadoop.txt [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# mkdir input && mv hadoop.txt input [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll total 0 drwxr-xr-x 2 root root 24 Oct 22 16:28 input [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll input/ total 4 -rw-r--r-- 1 root root 662 Oct 22 16:26 hadoop.txt [root@hadoop101.yinzhengjie.com ~]#
2>.操作系统本地运行一个MapReduce任务
[root@hadoop101.yinzhengjie.com ~]# ll total 0 drwxr-xr-x 2 root root 24 Oct 22 16:28 input [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount file:///root/input file:///root/output 20/10/22 16:42:57 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 20/10/22 16:42:57 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 20/10/22 16:42:58 INFO input.FileInputFormat: Total input files to process : 1 20/10/22 16:42:58 INFO mapreduce.JobSubmitter: number of splits:1 20/10/22 16:42:58 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local352750999_0001 20/10/22 16:42:58 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 20/10/22 16:42:58 INFO mapreduce.Job: Running job: job_local352750999_0001 20/10/22 16:42:58 INFO mapred.LocalJobRunner: OutputCommitter set in config null 20/10/22 16:42:58 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 20/10/22 16:42:58 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 20/10/22 16:42:58 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 20/10/22 16:42:58 INFO mapred.LocalJobRunner: Waiting for map tasks 20/10/22 16:42:58 INFO mapred.LocalJobRunner: Starting task: attempt_local352750999_0001_m_000000_0 20/10/22 16:42:58 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 20/10/22 16:42:58 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 20/10/22 16:42:58 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 20/10/22 16:42:58 INFO mapred.MapTask: Processing split: file:/root/input/hadoop.txt:0+662 20/10/22 16:42:58 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 20/10/22 16:42:58 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 20/10/22 16:42:58 INFO mapred.MapTask: soft limit at 83886080 20/10/22 16:42:58 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 20/10/22 16:42:58 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 20/10/22 16:42:58 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 20/10/22 16:42:58 INFO mapred.LocalJobRunner: 20/10/22 16:42:58 INFO mapred.MapTask: Starting flush of map output 20/10/22 16:42:58 INFO mapred.MapTask: Spilling map output 20/10/22 16:42:58 INFO mapred.MapTask: bufstart = 0; bufend = 1057; bufvoid = 104857600 20/10/22 16:42:58 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214004(104856016); length = 393/6553600 20/10/22 16:42:58 INFO mapred.MapTask: Finished spill 0 20/10/22 16:42:58 INFO mapred.Task: Task:attempt_local352750999_0001_m_000000_0 is done. And is in the process of committing 20/10/22 16:42:58 INFO mapred.LocalJobRunner: map 20/10/22 16:42:58 INFO mapred.Task: Task 'attempt_local352750999_0001_m_000000_0' done. 20/10/22 16:42:58 INFO mapred.Task: Final Counters for attempt_local352750999_0001_m_000000_0: Counters: 23 File System Counters FILE: Number of bytes read=304107 FILE: Number of bytes written=812979 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=0 HDFS: Number of bytes written=0 HDFS: Number of read operations=0 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Map-Reduce Framework Map input records=3 Map output records=99 Map output bytes=1057 Map output materialized bytes=1014 Input split bytes=92 Combine input records=99 Combine output records=75 Spilled Records=75 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=0 Total committed heap usage (bytes)=213385216 File Input Format Counters Bytes Read=662 20/10/22 16:42:58 INFO mapred.LocalJobRunner: Finishing task: attempt_local352750999_0001_m_000000_0 20/10/22 16:42:58 INFO mapred.LocalJobRunner: map task executor complete. 20/10/22 16:42:58 INFO mapred.LocalJobRunner: Waiting for reduce tasks 20/10/22 16:42:58 INFO mapred.LocalJobRunner: Starting task: attempt_local352750999_0001_r_000000_0 20/10/22 16:42:58 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 20/10/22 16:42:58 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 20/10/22 16:42:58 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 20/10/22 16:42:58 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@12d5a3a6 20/10/22 16:42:58 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshol d=1020/10/22 16:42:58 INFO reduce.EventFetcher: attempt_local352750999_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 20/10/22 16:42:58 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local352750999_0001_m_000000_0 decomp: 1010 len: 1014 to MEMORY 20/10/22 16:42:58 INFO reduce.InMemoryMapOutput: Read 1010 bytes from map-output for attempt_local352750999_0001_m_000000_0 20/10/22 16:42:58 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 1010, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->1010 20/10/22 16:42:58 WARN io.ReadaheadPool: Failed readahead on ifile EBADF: Bad file descriptor at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method) at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267) at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146) at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:208) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 20/10/22 16:42:58 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 20/10/22 16:42:58 INFO mapred.LocalJobRunner: 1 / 1 copied. 20/10/22 16:42:58 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 20/10/22 16:42:58 INFO mapred.Merger: Merging 1 sorted segments 20/10/22 16:42:58 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1001 bytes 20/10/22 16:42:58 INFO reduce.MergeManagerImpl: Merged 1 segments, 1010 bytes to disk to satisfy reduce memory limit 20/10/22 16:42:58 INFO reduce.MergeManagerImpl: Merging 1 files, 1014 bytes from disk 20/10/22 16:42:58 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 20/10/22 16:42:58 INFO mapred.Merger: Merging 1 sorted segments 20/10/22 16:42:58 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1001 bytes 20/10/22 16:42:58 INFO mapred.LocalJobRunner: 1 / 1 copied. 20/10/22 16:42:58 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 20/10/22 16:42:58 INFO mapred.Task: Task:attempt_local352750999_0001_r_000000_0 is done. And is in the process of committing 20/10/22 16:42:58 INFO mapred.LocalJobRunner: 1 / 1 copied. 20/10/22 16:42:58 INFO mapred.Task: Task attempt_local352750999_0001_r_000000_0 is allowed to commit now 20/10/22 16:42:58 INFO output.FileOutputCommitter: Saved output of task 'attempt_local352750999_0001_r_000000_0' to file:/root/output/_temporary/0/task_local352750999_0001_r_000000 20/10/22 16:42:58 INFO mapred.LocalJobRunner: reduce > reduce 20/10/22 16:42:58 INFO mapred.Task: Task 'attempt_local352750999_0001_r_000000_0' done. 20/10/22 16:42:58 INFO mapred.Task: Final Counters for attempt_local352750999_0001_r_000000_0: Counters: 29 File System Counters FILE: Number of bytes read=306167 FILE: Number of bytes written=814717 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=0 HDFS: Number of bytes written=0 HDFS: Number of read operations=0 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Map-Reduce Framework Combine input records=0 Combine output records=0 Reduce input groups=75 Reduce shuffle bytes=1014 Reduce input records=75 Reduce output records=75 Spilled Records=75 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=6 Total committed heap usage (bytes)=246415360 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Output Format Counters Bytes Written=724 20/10/22 16:42:58 INFO mapred.LocalJobRunner: Finishing task: attempt_local352750999_0001_r_000000_0 20/10/22 16:42:58 INFO mapred.LocalJobRunner: reduce task executor complete. 20/10/22 16:42:59 INFO mapreduce.Job: Job job_local352750999_0001 running in uber mode : false 20/10/22 16:42:59 INFO mapreduce.Job: map 100% reduce 100% 20/10/22 16:42:59 INFO mapreduce.Job: Job job_local352750999_0001 completed successfully 20/10/22 16:42:59 INFO mapreduce.Job: Counters: 35 File System Counters FILE: Number of bytes read=610274 FILE: Number of bytes written=1627696 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=0 HDFS: Number of bytes written=0 HDFS: Number of read operations=0 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Map-Reduce Framework Map input records=3 Map output records=99 Map output bytes=1057 Map output materialized bytes=1014 Input split bytes=92 Combine input records=99 Combine output records=75 Reduce input groups=75 Reduce shuffle bytes=1014 Reduce input records=75 Reduce output records=75 Spilled Records=150 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=6 Total committed heap usage (bytes)=459800576 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=662 File Output Format Counters Bytes Written=724 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll total 0 drwxr-xr-x 2 root root 24 Oct 22 16:28 input drwxr-xr-x 2 root root 88 Oct 22 16:42 output [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll output/ total 4 -rw-r--r-- 1 root root 708 Oct 22 16:42 part-r-00000 -rw-r--r-- 1 root root 0 Oct 22 16:42 _SUCCESS [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# ll total 0 drwxr-xr-x 2 root root 24 Oct 22 16:28 input drwxr-xr-x 2 root root 88 Oct 22 16:42 output [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll output/ total 4 -rw-r--r-- 1 root root 708 Oct 22 16:42 part-r-00000 -rw-r--r-- 1 root root 0 Oct 22 16:42 _SUCCESS [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat output/part-r-00000 Apache 1 Apache™ 1 Hadoop 1 Hadoop® 1 It 1 Rather 1 The 2 a 3 across 1 allows 1 and 2 application 1 at 1 be 1 cluster 1 clusters 1 computation 1 computers 1 computers, 1 computing. 1 data 1 deliver 1 delivering 1 designed 2 detect 1 develops 1 distributed 2 each 2 failures 1 failures. 1 for 2 framework 1 from 1 handle 1 hardware 1 high-availability, 1 highly-available 1 is 3 itself 1 large 1 layer, 1 library 2 local 1 machines, 1 may 1 models. 1 of 6 offering 1 on 2 open-source 1 processing 1 programming 1 project 1 prone 1 reliable, 1 rely 1 scalable, 1 scale 1 servers 1 service 1 sets 1 simple 1 single 1 so 1 software 2 storage. 1 than 1 that 1 the 3 thousands 1 to 5 top 1 up 1 using 1 which 1 [root@hadoop101.yinzhengjie.com ~]#
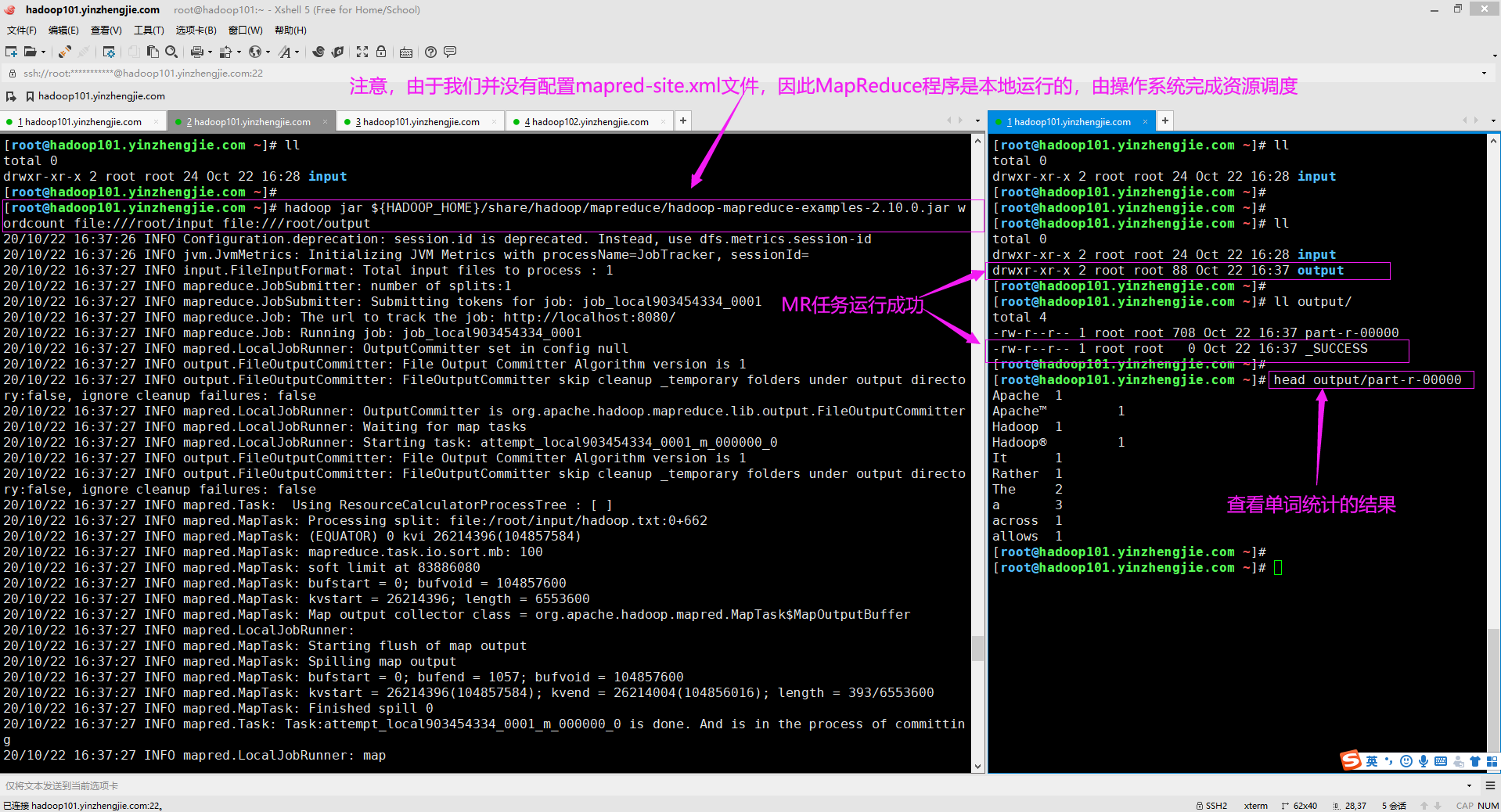
3>.查看YARN的web界面,我们发现并没有MapReduce类型的任务
如下图所示,由于我们没有对mapred-site.xml文件,因此任务并未提交到YARN上,而是交由操作系统完成资源调度(因为"mapreduce.framework.name"的默认值是"local")。 搭建YARN集群: https://www.cnblogs.com/yinzhengjie/p/13123597.html

二.在YARN集群上运行部署MapReduce分布式计算框架
1>.搭建YARN集群并启动
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13123597.html
2>.修改mapred-site.xml配置文件
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/mapred-site.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>用于执行MapReduce作业的运行时框架。它的值可以是local(交由当前操作系统),classic(交由第一代MR计算引擎)或yarn(交由第二代MR计算引擎)。默认值为local。</description> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1536m</value> <description> 我们都知道mapper进程在JVM中运行,除了JVM的内存需求和为每个map任务分配的内存之外,还必须满足其他内存请求,这个内存使用被称为"进程的开销"。 当"进程的开销"用完这个JVM的内存时,这就意味着我们的mapper任务不会被分配到任何内存。 综上所述,为了避免JVM占用分配给map任务的内存,可以使用"mapreduce.map.java.opts"参数来限制mapper的Java堆内存大小。 这里有一个很好的经验,即将"mapreduce.map.memory.mb"参数值的70%-75%作为"mapreduce.map.java.opts"参数的值。 </description> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx1536m</value> <description> 我们都知道reducer进程在JVM中运行,除了JVM的内存需求和为每个reduce任务分配的内存之外,还必须满足其他内存请求,这个内存使用被称为"进程的开销"。 当"进程的开销"用完这个JVM的内存时,这就意味着我们的reduce任务不会被分配到任何内存。 综上所述,为了避免JVM占用分配给reduce任务的内存,可以使用"mapreduce.reduce.java.opts"参数来限制reducer的Java堆内存大小。 这里有一个很好的经验,即将"mapreduce.reduce.memory.mb"参数值的70%-75%作为"mapreduce.reduce.java.opts"参数的值。 </description> </property> <property> <name>mapreduce.job.heap.memory-mb.ratio</name> <value>0.75</value> <description> 改参数用于指定堆大小与容器大小的比率。默认值为:"0.8"。 如果没有使用"mapreduce.{map|reduce}.java.opts"指定-Xmx,则计算内存公式为:"(mapreduce.{map|reduce}.memory.mb * mapreduce.heap.memory-mb.ratio)"。 如果使用"mapreduce.{map|reduce}.java.opts"指定了-Xmx,但未指定"mapreduce.{map|reduce}.memory.mb",则计算公式为:"(heapSize / mapreduce.heap.memory-mb.ratio)"。 </description> </property> <property> <name>mapreduce.map.memory.mb</name> <value>2048</value> <description> 指定为每个map任务分配的内存大小,如果未指定或者为非正值(默认值为-1),则从"mapreduce.map.java.opts"和"mapreduce.job.heap.memory-mb.ratio"两个值进行计算。 如果连"mapreduce.map.java.opts"的值也未指定,则默认值为1024MB。在生产环境中,大多数集群需要更高的值(大多数情况下为2~4GB)。我这里配置的是2G。 </description> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>2048</value> <description> 指定为每个reduce任务分配的内存大小,如果未指定或者为非正值(默认值为-1),则从"mapreduce.reduce.java.opts"和"mapreduce.job.heap.memory-mb.ratio"两个值进行计算。 如果连"mapreduce.reduce.java.opts"的值也未指定,则默认值为1024MB。在生产环境中,大多数集群需要更高的值(大多数情况下为2~4GB)。我这里配置的是2G。 </description> </property> <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/yinzhengjie/workspace/mapreduce</value> <description> 改参数用于他提交作业的暂存目录,其默认值为"/tmp/hadoop-yarn/staging"。 一般情况下,我们将其指向一个HDFS目录,YARN存储所有应用程序相关信息,例如运行作业时创建的临时文件,作业计数器和作业配置等,该目录路径自定义即可。 </description> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/yinzhengjie/history_logs/mapreduce/done_intermediate</value> <description>指定MapReduce作业写入历史文件的目录(严格意义上来说是一个中间产物)。默认值为"${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate"</description> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/yinzhengjie/history_logs/mapreduce/done</value> <description>指定JobHistoryServer管理历史记录文件的目录。默认值为"${yarn.app.mapreduce.am.staging-dir}/history/done"</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop105.yinzhengjie.com:10020</value> <description>使用此参数指定MapReduce JobHistory服务器IPC,默认值为"0.0.0.0:10020"。</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop105.yinzhengjie.com:19888</value> </property> </configuration> [root@hadoop101.yinzhengjie.com ~]#
3>.修改yarn-site.xml配置文件(着重关注"yarn.log-aggregation-enable"和"yarn.log.server.url"这两个参数,因为我在配置聚合日志)
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
[root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 配置YARN支持MapReduce框架 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
此属性可以包含多个辅助服务的列表,以支持在YARN下运行的不同应用程序框架。以逗号分隔的服务列表,其中服务名称应仅包含a-zA-Z0-9_并且不能以数字开头。
设置此属性以通知NodeManager需要实现名为"mapreduce_shuffle"。该属性让NodeManager知道MapReduce容器从map任务到reduce任务的过程中需要执行shuffle操作。
因为shuffle是一个辅助服务,而不是NodeManager的一部分,所以必须在此显式设置其值。否则无法运行MR任务。
默认值为空,在本例中,指定了mapreduce_shuffle值,因为当前仅在集群中运行基于MapReduce的作业。
</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<description>
此参数指示MapReduce如何执行shuffle操作。本例中为该参数指定的值是"org.apache.hadoop.mapred.ShuffleHandler"(其实就是默认值)。指示YARN使用这个类执行shuffle操作。
提供的类名称指示如何实现为属性"yarn.nodemanager.aux-services"设置的值。
</description>
</property>
<!-- 配置ResourceManager(简称RM)相关参数 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101.yinzhengjie.com</value>
<description>指定RM的主机名。默认值为"0.0.0.0"</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
<description>
指定调度程序接口的地址,即RM对ApplicationMaster暴露的访问地址。
ApplicationMaster通过该地址向RM申请资源、释放资源等。若不指定默认值为:"${yarn.resourcemanager.hostname}:8030"
</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
<description>指定RM对NM暴露的地址。NM通过该地址向RM汇报心跳,领取任务等。若不指定默认值为:"${yarn.resourcemanager.hostname}:8031"</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
<description>
指定RM中的应用程序管理器接口的地址,即RM对客户端暴露的地址。
客户端通过该地址向RM提交应用程序,杀死应用程序等。若不指定默认值为:"${yarn.resourcemanager.hostname}:8032"
</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
<description>RM对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等。若不指定默认值为:"${yarn.resourcemanager.hostname}:8033"</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
<description>RM Web应用程序的http地址。如果仅提供主机作为值,则将在随机端口上提供webapp。若不指定默认值为:"${yarn.resourcemanager.hostname}:8088"</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
<description>用作资源调度程序的类。目前可用的有FIFO、CapacityScheduler和FairScheduler。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.client.thread-count</name>
<value>50</value>
<description>处理来自NodeManager的RPC请求的Handler数目。默认值为50</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>50</value>
<description>处理来自ApplicationMaster的RPC请求的Handler数目。默认值为50</description>
</property>
<property>
<name>yarn.resourcemanager.nodes.include-path</name>
<value></value>
<description>指定包含节点的文件路径。即设置白名单,默认值为空。(改参数并不是必须配置的,先混个眼熟,后续用到可以直接拿来配置。)</description>
</property>
<property>
<name>yarn.resourcemanager.nodes.exclude-path</name>
<value></value>
<description>
指定包含要排除的节点的文件路径。即设置黑名单,默认值为空。(改参数并不是必须配置的,先混个眼熟,后续用到可以直接拿来配置。)
如果发现若干个NodeManager存在问题,比如故障率很高,任务运行失败率高,则可以将之加入黑名单中。注意,这两个配置参数可以动态生效。(调用一个refresh命令即可)
</description>
</property>
<property>
<name>yarn.resourcemanager.nodemanagers.heartbeat-interval-ms</name>
<value>3000</value>
<description>集群中每个NodeManager的心跳间隔(以毫秒为单位)。默认值为1000ms(即1秒)</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>
RM上每个容器请求的最小分配(以MB为单位)。低于此值的内存请求将被设置为此属性的值。此外,如果节点管理器配置为内存小于此值,则资源管理器将关闭该节点管理器。
此参数指定分配的每个容器最小内存为2048MB(即2G),该值不宜设置过大。默认值为1024MB。
由于我们将yarn.nodemanager.resource.memory-mb的值设置为81920MB,因此意味着此节点限制在任何给定时间内运行的容器数量不超过40个(81920/2048)个。
</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>81920</value>
<description>
RM上每个容器请求的最大分配(MB)。高于此值的内存请求将引发InvalidResourceRequestException。
此参数指定分配的每个容器最大内存为81920MB(即80G),该值不宜设置过小。默认值为8192MB(即8G)。
</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
<description>
就虚拟CPU内核而言,RM上每个容器请求的最小分配。低于此值的请求将设置为此属性的值。默认值为1。
此外,资源管理器将关闭配置为具有比该值更少的虚拟核的节点管理器。
</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>32</value>
<description>
就虚拟CPU核心而言,RM处每个容器请求的最大分配。默认值为4。
高于此值的请求将引发InvalidResourceRequestException。
</description>
</property>
<!-- 配置NodeManager(简称NM)相关参数 -->
<property>
<name>yarn.nodemanager.hostname</name>
<value>0.0.0.0</value>
<description>指定NodeManager的主机名,默认值为:"0.0.0.0",可惜啊,我们在配置Kerberos的"_HOST"变量不能在这里使用,因此该选项我们目前先保持默认即可.</description>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>${yarn.nodemanager.hostname}:6666</value>
<description>指定NodeManager中容器管理器的地址,默认值为"${yarn.nodemanager.hostname}:0"</description>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>${yarn.nodemanager.hostname}:8042</value>
<description>指定NodeManager的WebUI端口,默认值为"${yarn.nodemanager.hostname}:8042" </description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>81920</value>
<description>
此参数用于指定YARN可以在每个节点上消耗的总内存(用于分配给容器的物理内存量,以MB为单位)。在生产环境中建议设置为物理内存的70%的容量即可.
如果设置为-1(默认值)且yarn.nodemanager.resource.detect-hardware-capabilities为true,则会自动计算(在Windows和Linux中)。在其他情况下,默认值为8192MB(即8GB)。
</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
<description>
此参数可以指定分配给YARN容器的CPU内核数。理论上应该将其设置为小于节点上物理内核数。但在实际生产环境中可以将一个物理cpu当成2个来用,尤其是在CPU密集型的集群。
如果设置为-1(默认值)且yarn.nodemanager.resource.detect-hardware-capabilities为true,则会自动计算(在Windows和Linux中)。在其他情况下,默认值为8。
</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3.0</value>
<description>
此参数指定YARN容器配置的每个map和reduce任务使用的虚拟内存比的上限(换句话说,每使用1MB物理内存,最多可用的虚拟内存数)。
默认值是2.1,可以设置一个不同的值,比如3.0。不过生产环境中我一般都会禁用swap分区,目的在于尽量避免使用虚拟内存哟。因此若禁用了swap分区,个人觉得改参数配置可忽略。
</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>
每个DataNode上的NodeManager使用此属性来聚合应用程序日志。默认值为"false",启用日志聚合时,Hadoop收集作为应用程序一部分的每个容器的日志,并在应用完成后将这些文件移动到HDFS。
可以使用"yarn.nodemanager.remote-app-log-dir"和"yarn.nodemanager.remote-app-log-dir-suffix"属性来指定在HDFS中聚合日志的位置。
</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop105.yinzhengjie.com:19888/yinzhengjie/history_logs/aggregation</value>
<description>指定日志聚合服务器的URL,若不指定,默认值为空。</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/yinzhengjie/logs/hdfs/</value>
<description>
此属性指定HDFS中聚合应用程序日志文件的目录。JobHistoryServer将应用日志存储在HDFS中的此目录中。默认值为"/tmp/logs"
</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>yinzhengjie-logs</value>
<description>远程日志目录将创建在"{yarn.nodemanager.remote-app-log-dir}/${user}/{thisParam}",默认值为"logs"。</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/yinzhengjie/logs/yarn/container1,/yinzhengjie/logs/yarn/container2,/yinzhengjie/logs/yarn/container3</value>
<description>
指定存储容器日志的位置,默认值为"${yarn.log.dir}/userlogs"。此属性指定YARN在Linux文件系统上发送应用程序日志文件的路径。通常会配置多个不同的挂在目录,以增强I/O性能。
由于上面启用了日志聚合功能,一旦应用程序完成,YARN将删除本地文件。可以通过JobHistroyServer访问它们(从汇总了日志的HDFS上)。
在该示例中将其设置为"/yinzhengjie/logs/yarn/container",只有NondeManager使用这些目录。
</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/yinzhengjie/data/hdfs/nm1,/yinzhengjie/data/hdfs/nm2,/yinzhengjie/data/hdfs/nm3</value>
<description>
指定用于存储本地化文件的目录列表(即指定中间结果存放位置,通常会配置多个不同的挂在目录,以增强I/O性能)。默认值为"${hadoop.tmp.dir}/nm-local-dir"。
YARN需要存储其本地文件,例如MapReduce的中间输出,将它们存储在本地文件系统上的某个位置。可以使用此参数指定多个本地目录,YARN的分布式缓存也是用这些本地资源文件。
</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>保留用户日志的时间(以秒为单位)。仅在禁用日志聚合的情况下适用,默认值为:10800s(即3小时)。</description>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/yinzhengjie/softwares/hadoop/etc/hadoop:/yinzhengjie/softwares/hadoop/etc/hadoop:/yinzhengjie/softwares/hadoop/etc/hadoop:/yinzhengjie/softwares/hadoop/share/hadoop/common/l
ib/*:/yinzhengjie/softwares/hadoop/share/hadoop/common/*:/yinzhengjie/softwares/hadoop/share/hadoop/hdfs:/yinzhengjie/softwares/hadoop/share/hadoop/hdfs/lib/*:/yinzhengjie/softwares/hadoop/share/hadoop/hdfs/*:/yinzhengjie/softwares/hadoop/share/hadoop/yarn:/yinzhengjie/softwares/hadoop/share/hadoop/yarn/lib/*:/yinzhengjie/softwares/hadoop/share/hadoop/yarn/*:/yinzhengjie/softwares/hadoop/share/hadoop/mapreduce/lib/*:/yinzhengjie/softwares/hadoop/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar:/yinzhengjie/softwares/hadoop/share/hadoop/yarn/*:/yinzhengjie/softwares/hadoop/share/hadoop/yarn/lib/*</value> <description>
此属性指定本地文件系统上用于存储在集群中执行应用程序所需的Hadoop,YARN和HDFS常用JAR文件的位置。以逗号分隔的CLASSPATH条目列表。
当此值为空时,将使用以下用于YARN应用程序的默认CLASSPATH。
对于Linux:
$HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $HADOOP_YARN_HOME/share/hadoop/yarn/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
对于Windows:
%HADOOP_CONF_DIR%, %HADOOP_COMMON_HOME%/share/hadoop/common/*, %HADOOP_COMMON_HOME%/share/hadoop/common/lib/*,
%HADOOP_HDFS_HOME%/share/hadoop/hdfs/*, %HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*, %HADOOP_YARN_HOME%/share/hadoop/yarn/*,
%HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*
应用程序的ApplicationMaster和运行该应用程序都需要知道本地文件系统图上各个HDFS,YARN和Hadoop常用JAR文件所在的位置。
温馨提示:
综上所述的变量可惜我一个都没有配置,因为我只配置了一个"${HADOOP_HOME}"变量,这个时候在命令行执行"yarn classpath",将该命令的输出复制在上面即可。
其实也可以不配置该属性,了解一下即可,因为不配置集群正常能运行,若你写错类路径反而会出现新的问题。因此改参数我生产环境中并未在配置文件中指定。
</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop102</value>
</property>
</configuration>
[root@hadoop101.yinzhengjie.com ~]#
4>.使用ansible工具分发文件
[root@hadoop101.yinzhengjie.com ~]# tail -17 /etc/ansible/hosts #Add by yinzhengjie for Hadoop. [nn] hadoop101.yinzhengjie.com [snn] hadoop105.yinzhengjie.com [dn] hadoop102.yinzhengjie.com hadoop103.yinzhengjie.com hadoop104.yinzhengjie.com [other] hadoop102.yinzhengjie.com hadoop103.yinzhengjie.com hadoop104.yinzhengjie.com hadoop105.yinzhengjie.com [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# ansible other -m copy -a "src=${HADOOP_HOME}/etc/hadoop/mapred-site.xml dest=${HADOOP_HOME}/etc/hadoop/" hadoop104.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "a3c9b3c9ae4ea0fa4174ec662a05e5218d44601a", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/mapred-site.xml", "gid": 0, "group": "root", "md5sum": "563229cdb5886de57578fc73f4880d00", "mode": "0644", "owner": "root", "size": 5970, "src": "/root/.ansible/tmp/ansible-tmp-1603367317.76-23139-194503291697925/source", "state": "file", "uid": 0 } hadoop105.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "a3c9b3c9ae4ea0fa4174ec662a05e5218d44601a", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/mapred-site.xml", "gid": 0, "group": "root", "md5sum": "563229cdb5886de57578fc73f4880d00", "mode": "0644", "owner": "root", "size": 5970, "src": "/root/.ansible/tmp/ansible-tmp-1603367317.78-23140-145396785530889/source", "state": "file", "uid": 0 } hadoop103.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "a3c9b3c9ae4ea0fa4174ec662a05e5218d44601a", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/mapred-site.xml", "gid": 0, "group": "root", "md5sum": "563229cdb5886de57578fc73f4880d00", "mode": "0644", "owner": "root", "size": 5970, "src": "/root/.ansible/tmp/ansible-tmp-1603367317.77-23138-187921628068181/source", "state": "file", "uid": 0 } hadoop102.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "a3c9b3c9ae4ea0fa4174ec662a05e5218d44601a", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/mapred-site.xml", "gid": 0, "group": "root", "md5sum": "563229cdb5886de57578fc73f4880d00", "mode": "0644", "owner": "root", "size": 5970, "src": "/root/.ansible/tmp/ansible-tmp-1603367317.72-23136-208231198915460/source", "state": "file", "uid": 0 } [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# ansible other -m copy -a "src=${HADOOP_HOME}/etc/hadoop/yarn-site.xml dest=${HADOOP_HOME}/etc/hadoop/" hadoop103.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "4790ce675045af0497e541b856c56b9422be5ef7", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/yarn-site.xml", "gid": 0, "group": "root", "md5sum": "0d22f3caad29fcdb1a7c96ed01e64172", "mode": "0644", "owner": "root", "size": 15062, "src": "/root/.ansible/tmp/ansible-tmp-1603435266.76-92458-41322174772235/source", "state": "file", "uid": 0 } hadoop104.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "4790ce675045af0497e541b856c56b9422be5ef7", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/yarn-site.xml", "gid": 0, "group": "root", "md5sum": "0d22f3caad29fcdb1a7c96ed01e64172", "mode": "0644", "owner": "root", "size": 15062, "src": "/root/.ansible/tmp/ansible-tmp-1603435266.77-92459-181252690147252/source", "state": "file", "uid": 0 } hadoop102.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "4790ce675045af0497e541b856c56b9422be5ef7", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/yarn-site.xml", "gid": 0, "group": "root", "md5sum": "0d22f3caad29fcdb1a7c96ed01e64172", "mode": "0644", "owner": "root", "size": 15062, "src": "/root/.ansible/tmp/ansible-tmp-1603435266.74-92456-71927339102459/source", "state": "file", "uid": 0 } hadoop105.yinzhengjie.com | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "4790ce675045af0497e541b856c56b9422be5ef7", "dest": "/yinzhengjie/softwares/hadoop/etc/hadoop/yarn-site.xml", "gid": 0, "group": "root", "md5sum": "0d22f3caad29fcdb1a7c96ed01e64172", "mode": "0644", "owner": "root", "size": 15062, "src": "/root/.ansible/tmp/ansible-tmp-1603435266.83-92460-211858934867748/source", "state": "file", "uid": 0 } [root@hadoop101.yinzhengjie.com ~]#
5>.重启YARN和HistoryServer服务
[root@hadoop101.yinzhengjie.com ~]# cat `which manage-mapreduce.sh` #!/bin/bash # #******************************************************************** #Author: yinzhengjie #QQ: 1053419035 #Date: 2019-11-27 #FileName: manage-yarn.sh #URL: http://www.cnblogs.com/yinzhengjie #Description: The test script #Copyright notice: original works, no reprint! Otherwise, legal liability will be investigated. #******************************************************************** #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数"; exit fi #调用操作系统自带的函数,(我这里需要用到action函数,可以使用"declare -f action"查看该函数的定义过程) . /etc/init.d/functions function start_mr(){ ansible snn -m shell -a "mr-jobhistory-daemon.sh start historyserver" #提示用户服务启动成功 action "Starting HistoryServer:" true } function stop_mr(){ ansible snn -m shell -a "mr-jobhistory-daemon.sh stop historyserver" #提示用户服务停止成功 action "Stoping HistoryServer:" true } function status_mr(){ ansible all -m shell -a 'jps' } case $1 in "start") start_mr ;; "stop") stop_mr ;; "restart") stop_mr start_mr ;; "status") status_mr ;; *) echo "Usage: manage-mapreduce.sh start|stop|restart|status" ;; esac [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# cat `which manage-yarn.sh` #!/bin/bash # #******************************************************************** #Author: yinzhengjie #QQ: 1053419035 #Date: 2019-11-27 #FileName: manage-yarn.sh #URL: http://www.cnblogs.com/yinzhengjie #Description: The test script #Copyright notice: original works, no reprint! Otherwise, legal liability will be investigated. #******************************************************************** #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数"; exit fi #调用操作系统自带的函数,(我这里需要用到action函数,可以使用"declare -f action"查看该函数的定义过程) . /etc/init.d/functions function start_yarn(){ ansible nn -m shell -a 'yarn-daemon.sh start resourcemanager' ansible dn -m shell -a 'yarn-daemon.sh start nodemanager' #提示用户服务启动成功 action "Starting YARN:" true } function stop_yarn(){ ansible nn -m shell -a 'yarn-daemon.sh stop resourcemanager' ansible dn -m shell -a 'yarn-daemon.sh stop nodemanager' #提示用户服务停止成功 action "Stoping YARN:" true } function status_yarn(){ ansible all -m shell -a 'jps' } case $1 in "start") start_yarn ;; "stop") stop_yarn ;; "restart") stop_yarn start_yarn ;; "status") status_yarn ;; *) echo "Usage: manage-yarn.sh start|stop|restart|status" ;; esac [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# manage-yarn.sh restart hadoop101.yinzhengjie.com | CHANGED | rc=0 >> stopping resourcemanager hadoop103.yinzhengjie.com | CHANGED | rc=0 >> stopping nodemanager nodemanager did not stop gracefully after 5 seconds: killing with kill -9 hadoop104.yinzhengjie.com | CHANGED | rc=0 >> stopping nodemanager nodemanager did not stop gracefully after 5 seconds: killing with kill -9 hadoop102.yinzhengjie.com | CHANGED | rc=0 >> stopping nodemanager nodemanager did not stop gracefully after 5 seconds: killing with kill -9 Stoping YARN: [ OK ] hadoop101.yinzhengjie.com | CHANGED | rc=0 >> starting resourcemanager, logging to /yinzhengjie/softwares/hadoop-2.10.0-fully-mode/logs/yarn-root-resourcemanager-hadoop101.yinzhengjie.com.out hadoop103.yinzhengjie.com | CHANGED | rc=0 >> starting nodemanager, logging to /yinzhengjie/softwares/hadoop/logs/yarn-root-nodemanager-hadoop103.yinzhengjie.com.out hadoop104.yinzhengjie.com | CHANGED | rc=0 >> starting nodemanager, logging to /yinzhengjie/softwares/hadoop/logs/yarn-root-nodemanager-hadoop104.yinzhengjie.com.out hadoop102.yinzhengjie.com | CHANGED | rc=0 >> starting nodemanager, logging to /yinzhengjie/softwares/hadoop/logs/yarn-root-nodemanager-hadoop102.yinzhengjie.com.out Starting YARN: [ OK ] [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# manage-mapreduce.sh restart hadoop105.yinzhengjie.com | CHANGED | rc=0 >> stopping historyserver Stoping HistoryServer: [ OK ] hadoop105.yinzhengjie.com | CHANGED | rc=0 >> starting historyserver, logging to /yinzhengjie/softwares/hadoop/logs/mapred-root-historyserver-hadoop105.yinzhengjie.com.out Starting HistoryServer: [ OK ] [root@hadoop101.yinzhengjie.com ~]#
三.运行MapReduce,在YARN的RM Web UI查看日志信息
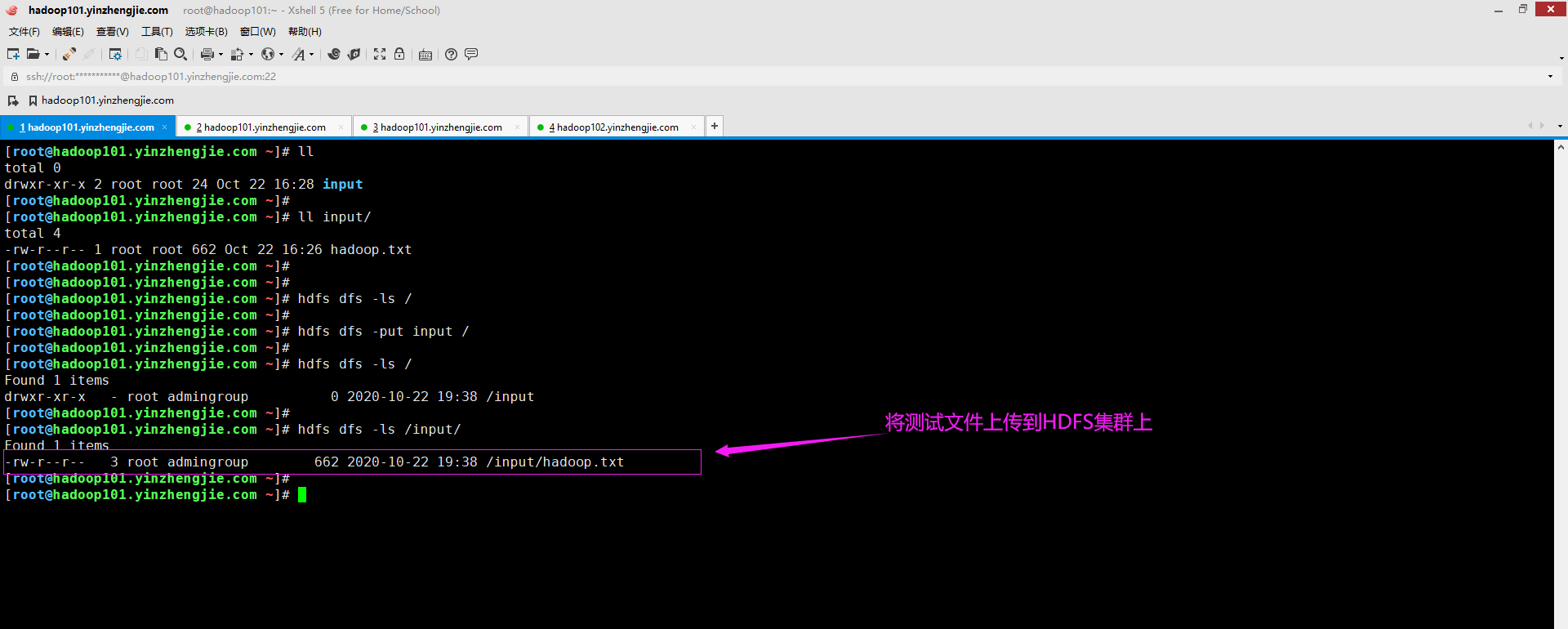
1>.上传测试文件
[root@hadoop101.yinzhengjie.com ~]# ll total 0 drwxr-xr-x 2 root root 24 Oct 22 16:28 input [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll input/ total 4 -rw-r--r-- 1 root root 662 Oct 22 16:26 hadoop.txt [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls / [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -put input / [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls / Found 1 items drwxr-xr-x - root admingroup 0 2020-10-22 19:38 /input [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls /input/ Found 1 items -rw-r--r-- 3 root admingroup 662 2020-10-22 19:38 /input/hadoop.txt [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]#
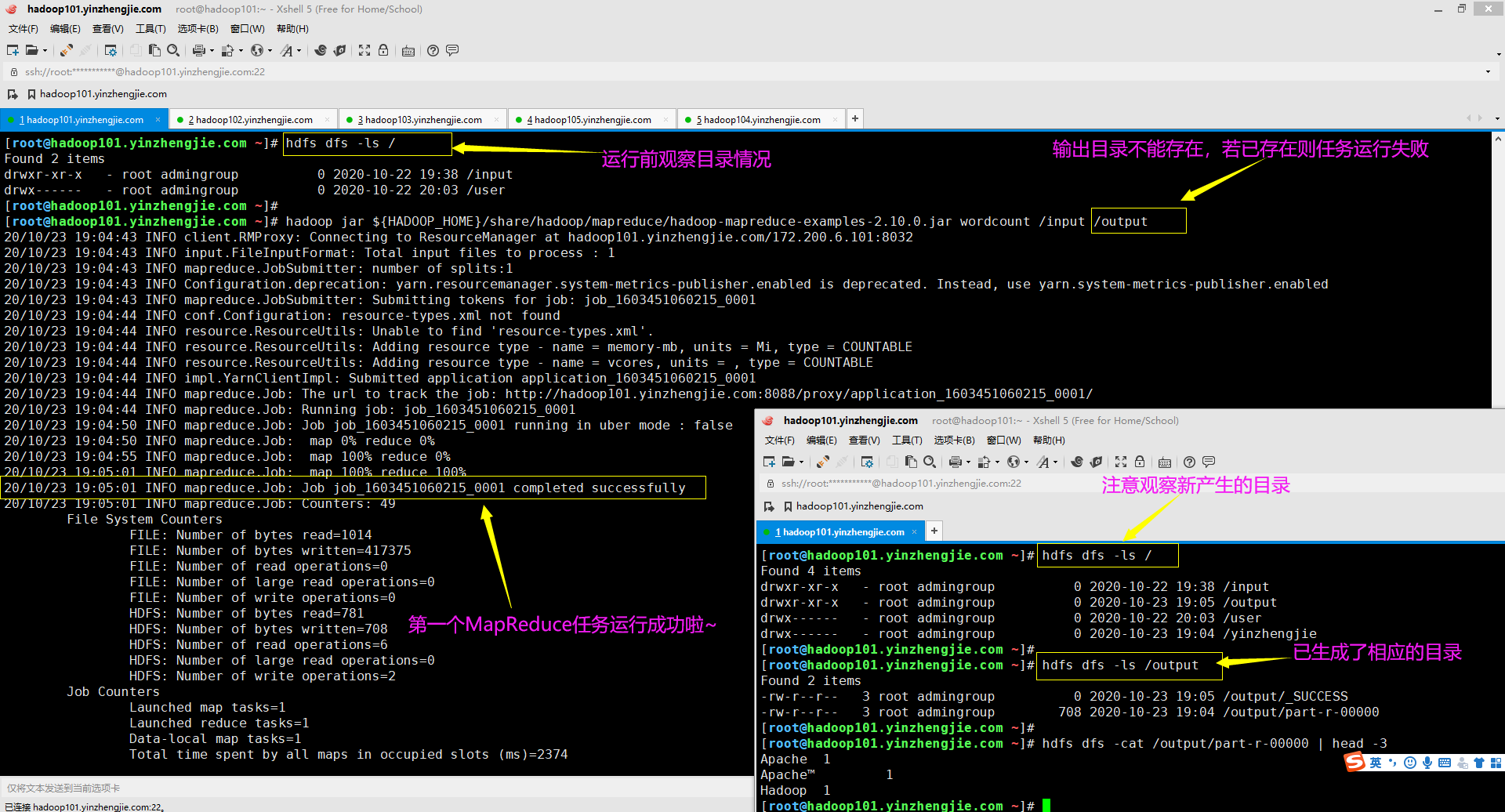
2>.运行一个MapReduce程序
[root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls / Found 2 items drwxr-xr-x - root admingroup 0 2020-10-22 19:38 /input drwx------ - root admingroup 0 2020-10-22 20:03 /user [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /input /output 20/10/23 19:04:43 INFO client.RMProxy: Connecting to ResourceManager at hadoop101.yinzhengjie.com/172.200.6.101:8032 20/10/23 19:04:43 INFO input.FileInputFormat: Total input files to process : 1 20/10/23 19:04:43 INFO mapreduce.JobSubmitter: number of splits:1 20/10/23 19:04:43 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled 20/10/23 19:04:43 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1603451060215_0001 20/10/23 19:04:44 INFO conf.Configuration: resource-types.xml not found 20/10/23 19:04:44 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 20/10/23 19:04:44 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE 20/10/23 19:04:44 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE 20/10/23 19:04:44 INFO impl.YarnClientImpl: Submitted application application_1603451060215_0001 20/10/23 19:04:44 INFO mapreduce.Job: The url to track the job: http://hadoop101.yinzhengjie.com:8088/proxy/application_1603451060215_0001/ 20/10/23 19:04:44 INFO mapreduce.Job: Running job: job_1603451060215_0001 20/10/23 19:04:50 INFO mapreduce.Job: Job job_1603451060215_0001 running in uber mode : false 20/10/23 19:04:50 INFO mapreduce.Job: map 0% reduce 0% 20/10/23 19:04:55 INFO mapreduce.Job: map 100% reduce 0% 20/10/23 19:05:01 INFO mapreduce.Job: map 100% reduce 100% 20/10/23 19:05:01 INFO mapreduce.Job: Job job_1603451060215_0001 completed successfully 20/10/23 19:05:01 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=1014 FILE: Number of bytes written=417375 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=781 HDFS: Number of bytes written=708 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=2374 Total time spent by all reduces in occupied slots (ms)=2676 Total time spent by all map tasks (ms)=2374 Total time spent by all reduce tasks (ms)=2676 Total vcore-milliseconds taken by all map tasks=2374 Total vcore-milliseconds taken by all reduce tasks=2676 Total megabyte-milliseconds taken by all map tasks=4861952 Total megabyte-milliseconds taken by all reduce tasks=5480448 Map-Reduce Framework Map input records=3 Map output records=99 Map output bytes=1057 Map output materialized bytes=1014 Input split bytes=119 Combine input records=99 Combine output records=75 Reduce input groups=75 Reduce shuffle bytes=1014 Reduce input records=75 Reduce output records=75 Spilled Records=150 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=98 CPU time spent (ms)=780 Physical memory (bytes) snapshot=514875392 Virtual memory (bytes) snapshot=7236321280 Total committed heap usage (bytes)=389545984 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=662 File Output Format Counters Bytes Written=708 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls / Found 4 items drwxr-xr-x - root admingroup 0 2020-10-22 19:38 /input drwxr-xr-x - root admingroup 0 2020-10-23 19:05 /output drwx------ - root admingroup 0 2020-10-22 20:03 /user drwx------ - root admingroup 0 2020-10-23 19:04 /yinzhengjie [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 root admingroup 0 2020-10-23 19:05 /output/_SUCCESS -rw-r--r-- 3 root admingroup 708 2020-10-23 19:04 /output/part-r-00000 [root@hadoop101.yinzhengjie.com ~]#
[root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 root admingroup 0 2020-10-23 19:05 /output/_SUCCESS -rw-r--r-- 3 root admingroup 708 2020-10-23 19:04 /output/part-r-00000 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -ls /output/part-r-00000 -rw-r--r-- 3 root admingroup 708 2020-10-23 19:04 /output/part-r-00000 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfs -cat /output/part-r-00000 Apache 1 Apache™ 1 Hadoop 1 Hadoop® 1 It 1 Rather 1 The 2 a 3 across 1 allows 1 and 2 application 1 at 1 be 1 cluster 1 clusters 1 computation 1 computers 1 computers, 1 computing. 1 data 1 deliver 1 delivering 1 designed 2 detect 1 develops 1 distributed 2 each 2 failures 1 failures. 1 for 2 framework 1 from 1 handle 1 hardware 1 high-availability, 1 highly-available 1 is 3 itself 1 large 1 layer, 1 library 2 local 1 machines, 1 may 1 models. 1 of 6 offering 1 on 2 open-source 1 processing 1 programming 1 project 1 prone 1 reliable, 1 rely 1 scalable, 1 scale 1 servers 1 service 1 sets 1 simple 1 single 1 so 1 software 2 storage. 1 than 1 that 1 the 3 thousands 1 to 5 top 1 up 1 using 1 which 1 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]#
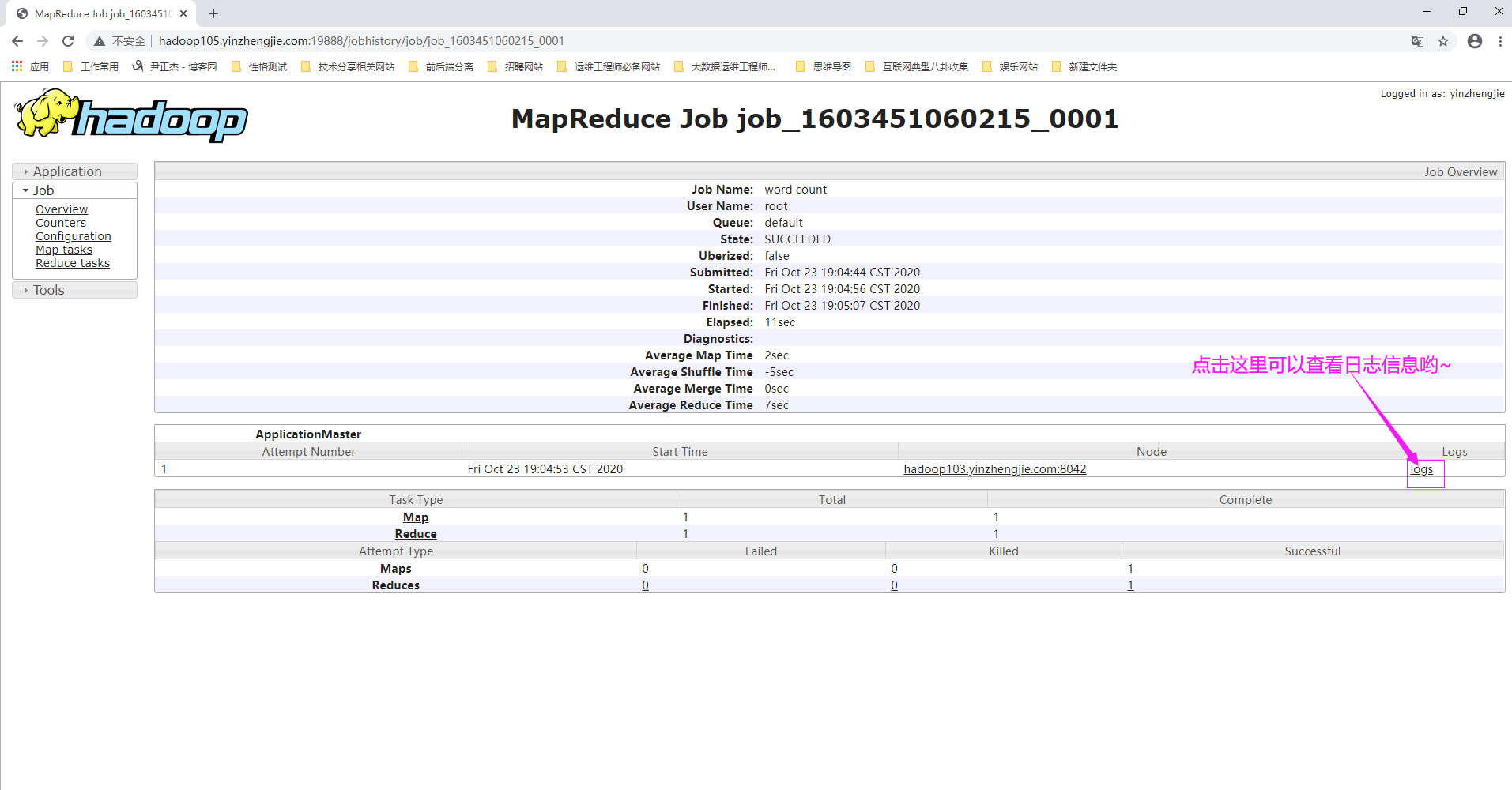
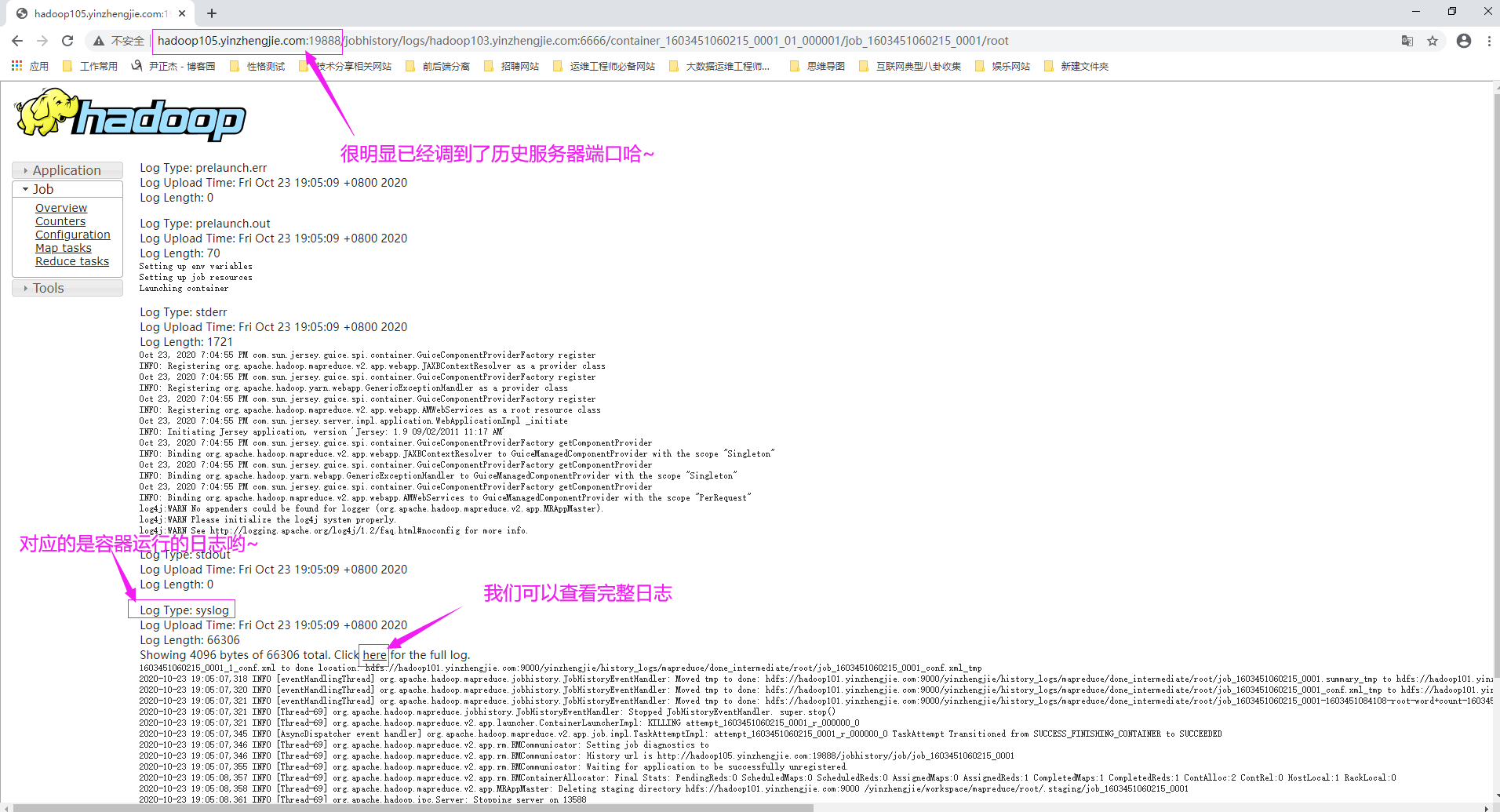
3>.查看日志
如下图所示,打开ResourceManager的Web UI就可以查看到我们刚刚运行的第一个MapReduce任务状态啦~

如下图所示,继续点击"logs"。
如下图所示,我们点击"here",可以查看完整的容器日志哟~
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/13174616.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号