


日志分析解决三个成功!!!!哈哈哈哈
哈哈哈哈哈、太棒了!!!
终于解决了
分析日志 /root/secure.zip ,编写脚本 /root/12.sh,如右图(注意对齐):
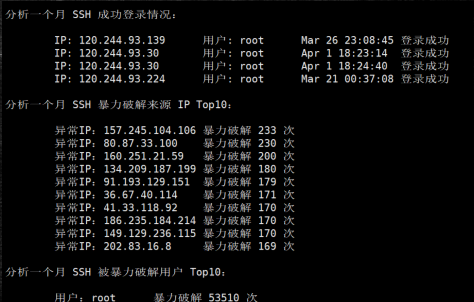
第一题: grep Accepted /tmp/secure-202303* /tmp/secure | cut -d: -f2- | awk '{printf "IP:%s 用户:%s %s %s %s\n", $11,$9,$1,$2,$3}'
第二题: 不用 按大小排序 找最多的就行
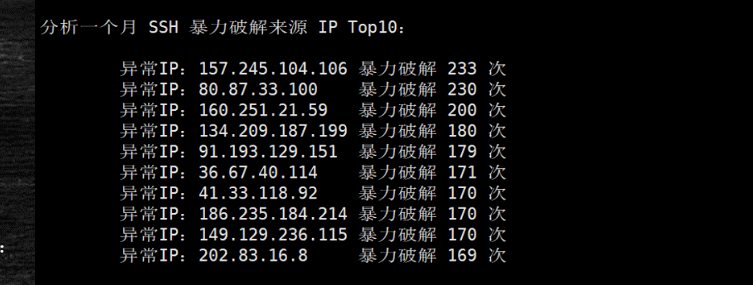
一步一步分析:要找出出现次数最多的IP,需在现有命令后添加统计次数、排序并取TopN的操作,完整命令如下:
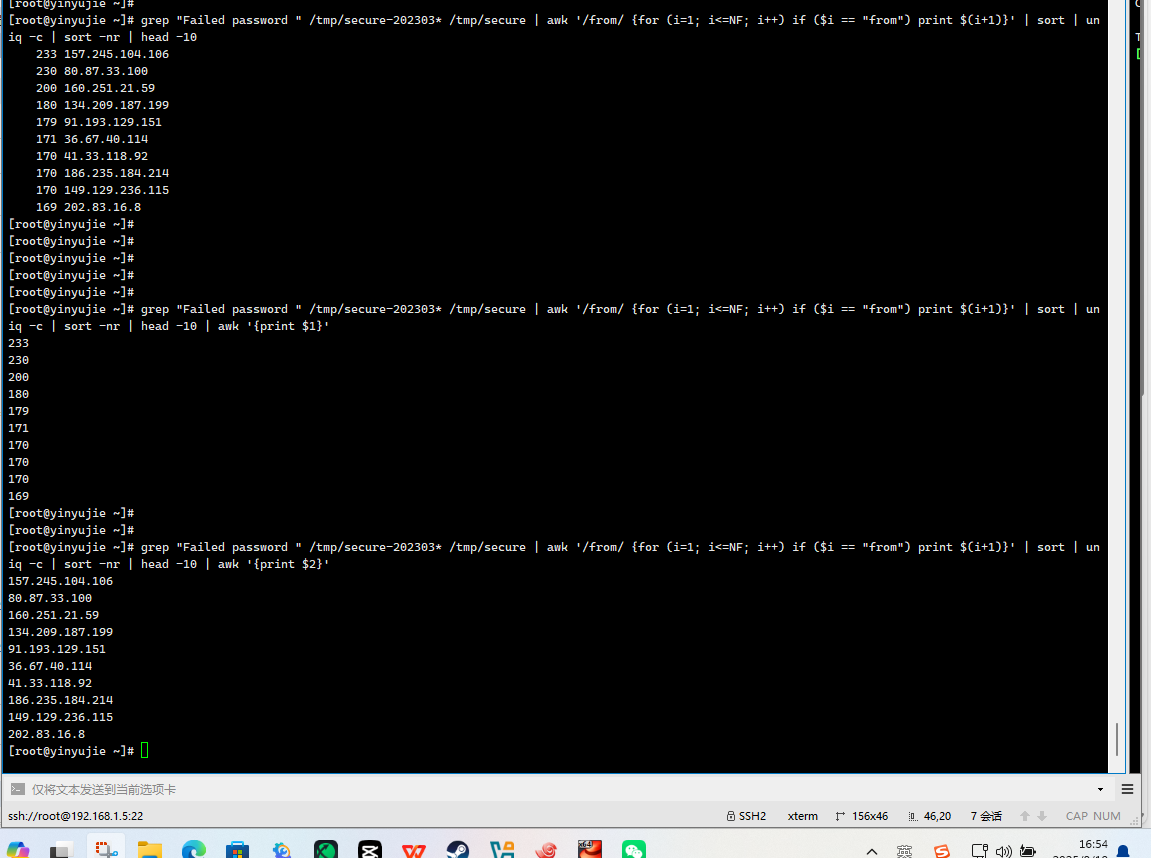
grep "Failed password " /tmp/secure-202303* /tmp/secure | awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i+1)}' | sort | uniq -c | sort -nr | head -n 10
各步骤解释:
grep "Failed password " /tmp/secure-202303* /tmp/secure:从指定日志文件中,筛选出包含Failed password(SSH密码验证失败,即暴力破解尝试)的行。awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i+1)}':在筛选出的行中,找到包含from的字段,打印from后面的IP地址(因为SSH日志中“from [IP]”是固定格式)。sort:将提取出的IP地址按字符串顺序排序,让相同IP连续排列(为后续“统计次数”做准备)。uniq -c:统计相邻且重复的IP的出现次数,输出格式为「次数 IP」。sort -nr:对“次数”进行数字降序排序(-n表示按数字排序,-r表示逆序),让次数多的IP排在前面。head -n 10:取排序后的前10行,即出现次数最多的10个IP(若要TopN,可修改10为目标数字)。
这样就能得到类似“一个月SSH暴力破解来源IP Top10”的统计结果(包含IP和对应破解次数)。
成功!!!!!哈哈哈哈哈哈哈
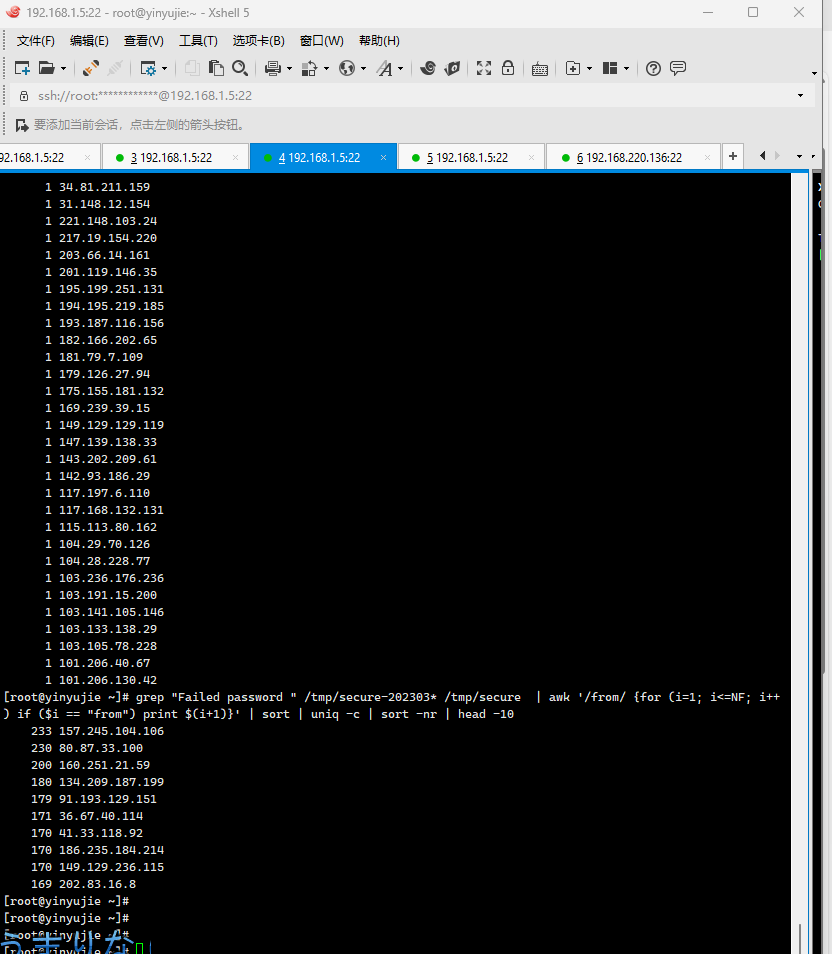
第二题:grep "Failed password " /tmp/secure-202303* /tmp/secure | awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i+1)}' | sort | uniq -c | sort -nr | head -10
第三题: grep "Failed password " /tmp/secure-202303* /tmp/secure | awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i-1)}' | sort -nr | uniq -c | sort -nr | head -10
分xi 日志过后发现
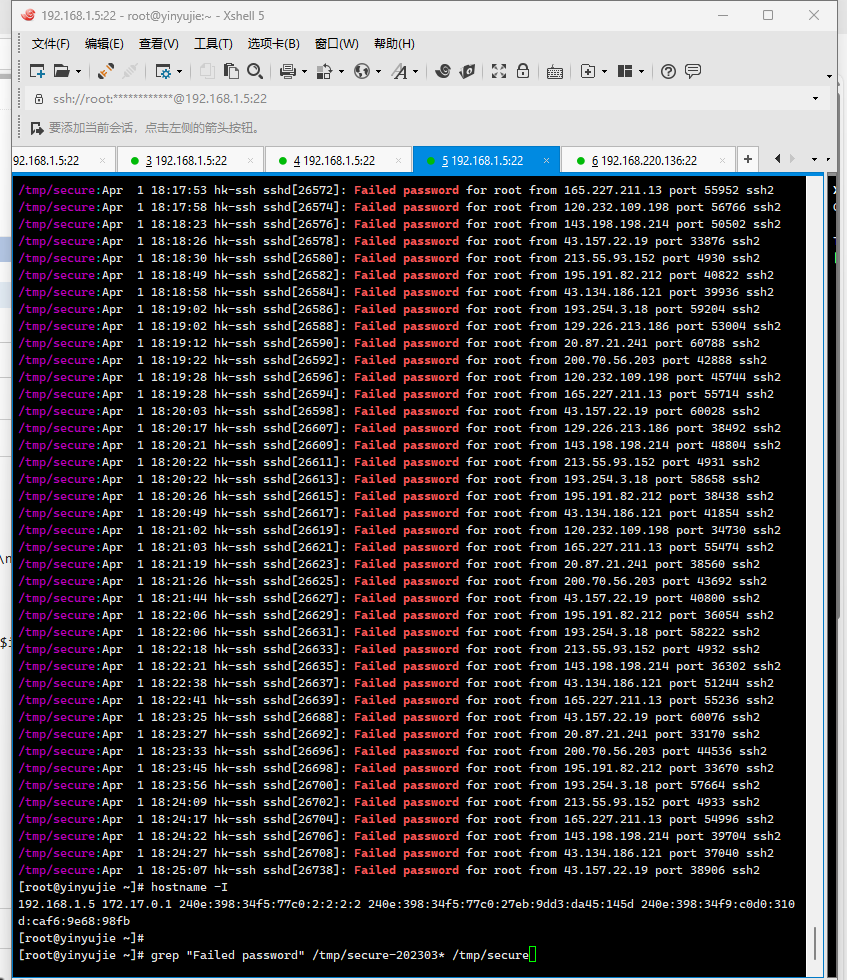
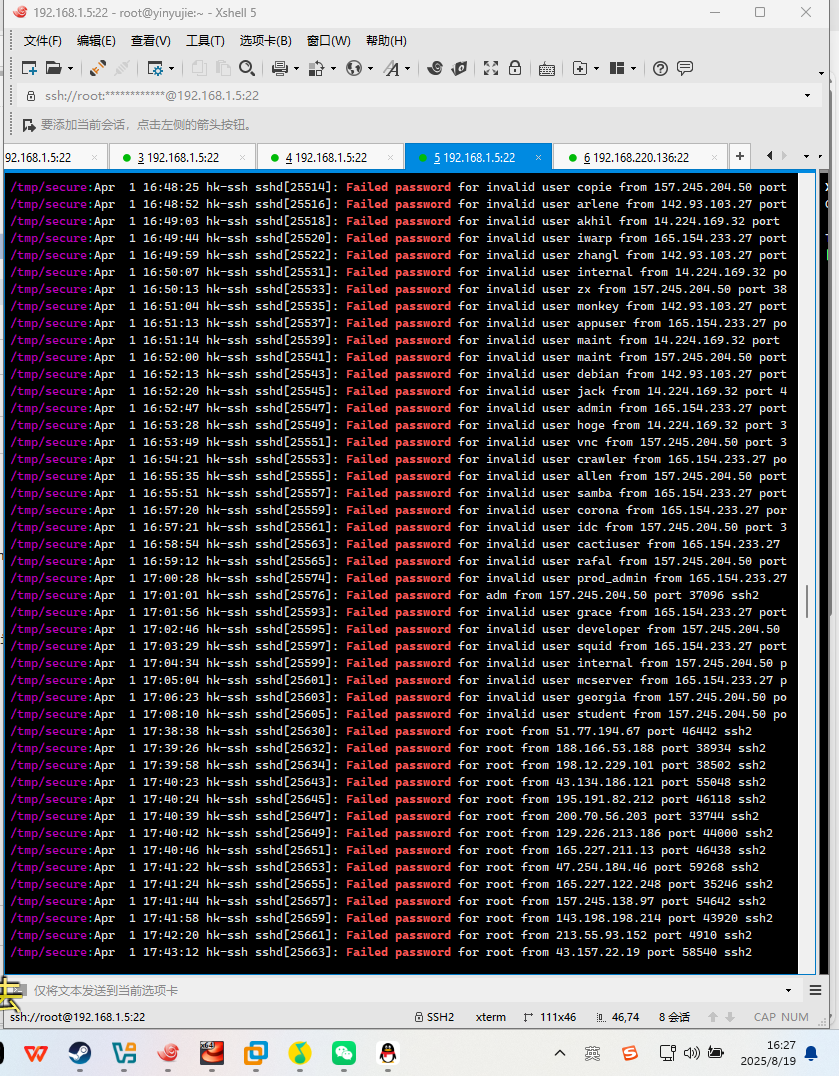
所有的都在 from 前面 ip 是在form后面 所以可以搞个 awk的 if函数 解决这第二题与第三题
最后使用xshell脚本 编好,成功!
总结: 分xi 安全日志 的内容 看form 前面还是后面 ,分xi 函数:
awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i+1)}' 具体什么意思基础讲解
这个awk命令的作用是在包含"from"的行中,找出值为"from"的字段,并打印该字段后面紧跟的那个字段。下面分部分详细解释:
1. 整体结构:awk '模式 {动作}'
awk是处理文本的工具,核心语法是awk '模式 {动作}',意思是:
- 对每一行文本,先判断是否符合“模式”;
- 若符合,则执行“动作”中的代码。
2. 模式部分:/from/
/from/是一个正则表达式模式,表示:只处理包含字符串"from"的行。
如果一行文本中没有"from",则跳过这行,不执行后面的动作。
3. 动作部分:{for (i=1; i<=NF; i++) if ($i == "from") print $(i+1)}
这部分是具体要执行的操作,拆解如下:
-
NF:awk的内置变量,表示“当前行的字段总数”。
(字段默认以空格/制表符分隔,比如"a b c"中,NF=3,有3个字段) -
for (i=1; i<=NF; i++):循环遍历当前行的所有字段。
i是字段索引(从1开始,不是0),比如i=1表示第1个字段,i=2表示第2个字段,直到最后一个字段(i=NF)。 -
if ($i == "from"):判断第i个字段是否正好是字符串"from"。
$i表示“第i个字段的值”(比如$1是第1个字段,$2是第2个字段)。 -
print $(i+1):如果第i个字段是"from",则打印它后面的那个字段(第i+1个字段)。
举例说明
假设处理以下文本行:
I am from Beijing
He comes from Shanghai
from here to there
hello from
执行命令后,结果会是:
Beijing
Shanghai
here
解释:
- 第1行:字段3是"from",所以打印字段4(
Beijing); - 第2行:字段3是"from",所以打印字段4(
Shanghai); - 第3行:字段1是"from",所以打印字段2(
here); - 第4行:字段2是"from",但它是最后一个字段(
NF=2),i+1=3超过NF,所以无输出。
总结
这个命令的功能是:从所有包含"from"的行中,提取出"from"后面紧跟的那个单词。常用于日志分析、文本提取等场景(比如从邮件日志中提取发件人地址,假设格式是from 邮箱)。
awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i-1)}'什么意思
这个awk命令的作用是:在包含"from"的行中,找出值为"from"的字段,并打印该字段前面紧邻的那个字段。
逐部分解析:
1. 模式部分:/from/
和之前的命令一样,这个正则表达式模式表示:只处理包含字符串"from"的行。不包含"from"的行会被跳过。
2. 动作部分:{for (i=1; i<=NF; i++) if ($i == "from") print $(i-1)}
核心逻辑是“找from,并打印它前面的字段”,拆解如下:
NF:awk内置变量,代表当前行的“字段总数”(字段默认以空格/制表符分隔)。for (i=1; i<=NF; i++):循环遍历当前行的所有字段(索引i从1开始,到NF结束)。if ($i == "from"):判断第i个字段是否正好是字符串"from"($i表示第i个字段的值)。print $(i-1):如果第i个字段是"from",则打印它前面紧邻的字段(即第i-1个字段)。
特殊情况说明:
如果from是当前行的第1个字段(即i=1),此时i-1=0,而awk中$0代表“整个行的内容”,因此会打印整行文本。
举例说明
假设处理以下文本行:
Beijing from China
from Shanghai to
He from here
Hello world from today
执行命令后,输出结果为:
Beijing
from Shanghai to # 因为"from"是第1个字段,i=1,i-1=0,所以打印整行
He
world # "from"是第3个字段,i=3,i-1=2,第2个字段是"world"
总结
这个命令的核心功能是:从包含"from"的行中,提取"from"前面紧邻的那个单词(如果from在句首,则会打印整行)。适用于需要反向关联“from”前后内容的场景(比如从文本中提取“来源前的主体”)。
成功!!!!!哈哈哈哈哈
最后的修改: 润色
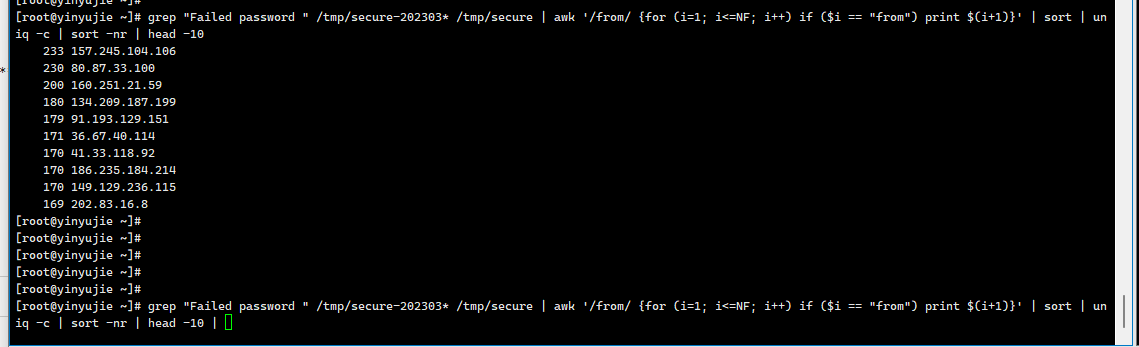
改暴力破解 和 ip的图标,应该是用awk的printf函数 ,试试 例子: awk '{printf "IP:%s 用户:%s %s %s %s\n", $11,$9,$1,$2,$3}' awk {printf " " , $例子 } 注意一定是逗号!英语的!!!!!!!!
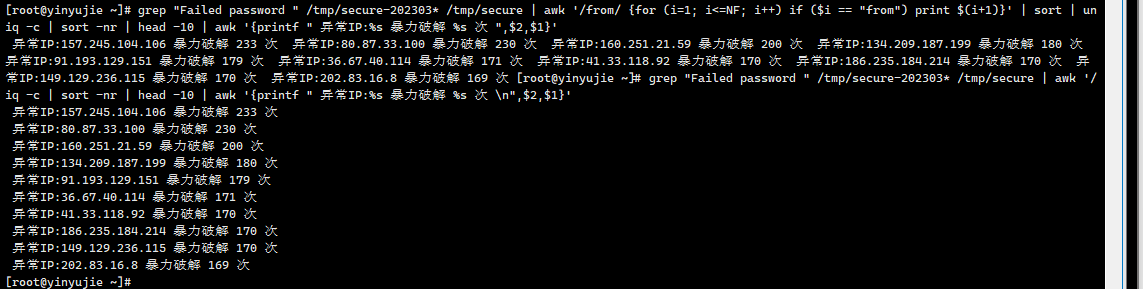
记得要加 \n ,不然看不清楚
第二题最终: grep "Failed password " /tmp/secure-202303* /tmp/secure | awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i+1)}' | sort | uniq -c | sort -nr | head -10 | awk '{printf " 异常IP:%s 暴力破解 %s 次 \n",$2,$1}' 一步一步理解敲也是一样的
第三题最终:
grep "Failed password " /tmp/secure-202303* /tmp/secure | awk '/from/ {for (i=1; i<=NF; i++) if ($i == "from") print $(i-1)}' | sort -nr | uniq -c | sort -nr | head -10 | awk '{printf " 用户:%s 暴力破解 %s 次 \n",$2,$1}'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号