


shell脚本
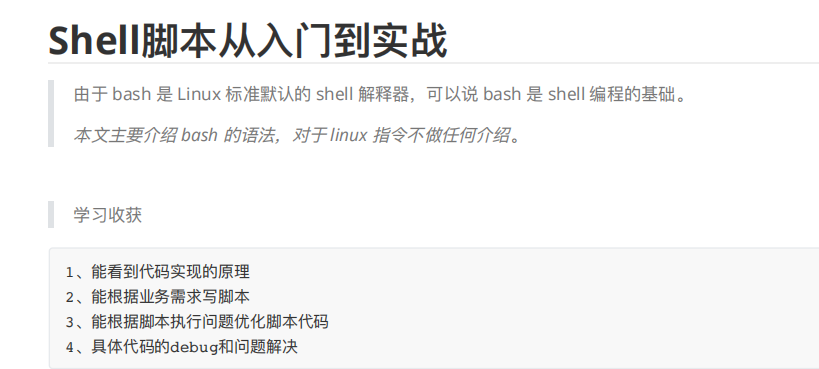
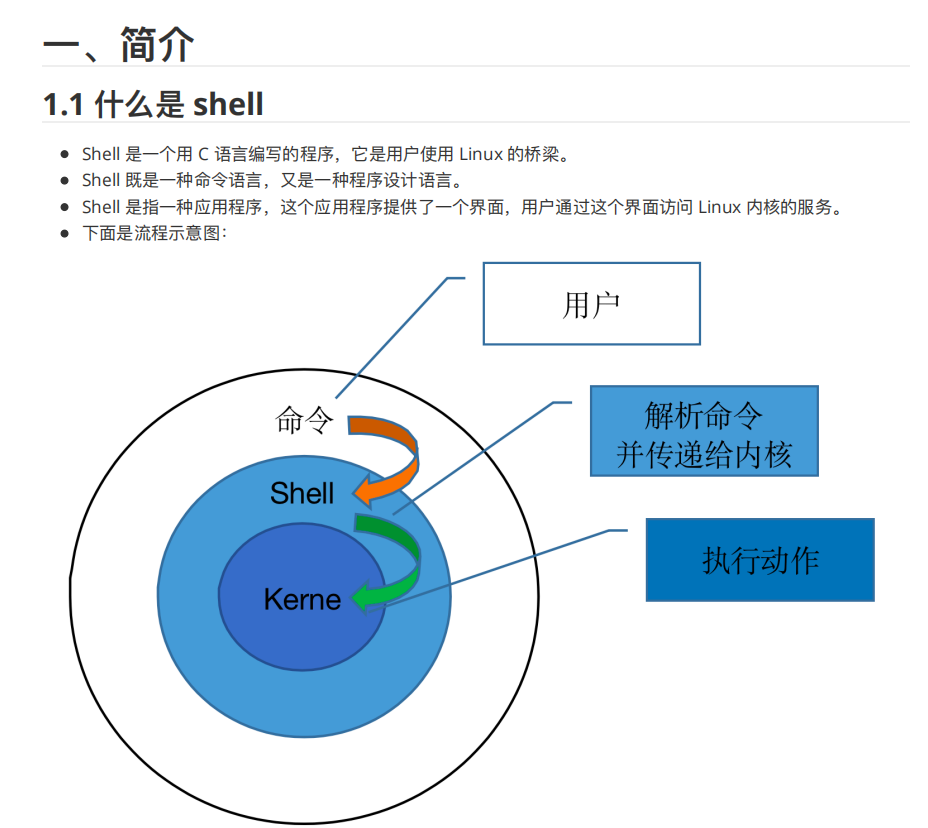

1.3.2 模式
shell 有交互和⾮交互两种模式。
交互模式
简单来说,你可以将 shell 的交互模式理解为执⾏命令⾏。
看到形如下⾯的东⻄,说明 shell 处于交互模式下:
接着,便可以输⼊⼀系列 Linux 命令,⽐如 ls , grep , cd , mkdir , rm 等等。
⾮交互模式
简单来说,你可以将 shell 的⾮交互模式理解为执⾏ shell 脚本。
在⾮交互模式下,shell 从⽂件或者管道中读取命令并执⾏。
当 shell 解释器执⾏完⽂件中的最后⼀个命令,shell 进程终⽌,并回到⽗进程。
可以使⽤下⾯的命令让 shell 以⾮交互模式运⾏:
上⾯的例⼦中, script.sh 是⼀个包含 shell 解释器可以识别并执⾏的命令的普通⽂本⽂件, sh 和 bash 是 shell
解释器程序。你可以使⽤任何喜欢的编辑器创建 script.sh (vim,nano,Sublime Text, Atom 等等)。
其中, source /shell/script.sh 和 ./shell/script.sh 是等价的。
除此之外,你还可以通过 chmod 命令给⽂件添加可执⾏的权限,来直接执⾏脚本⽂件:
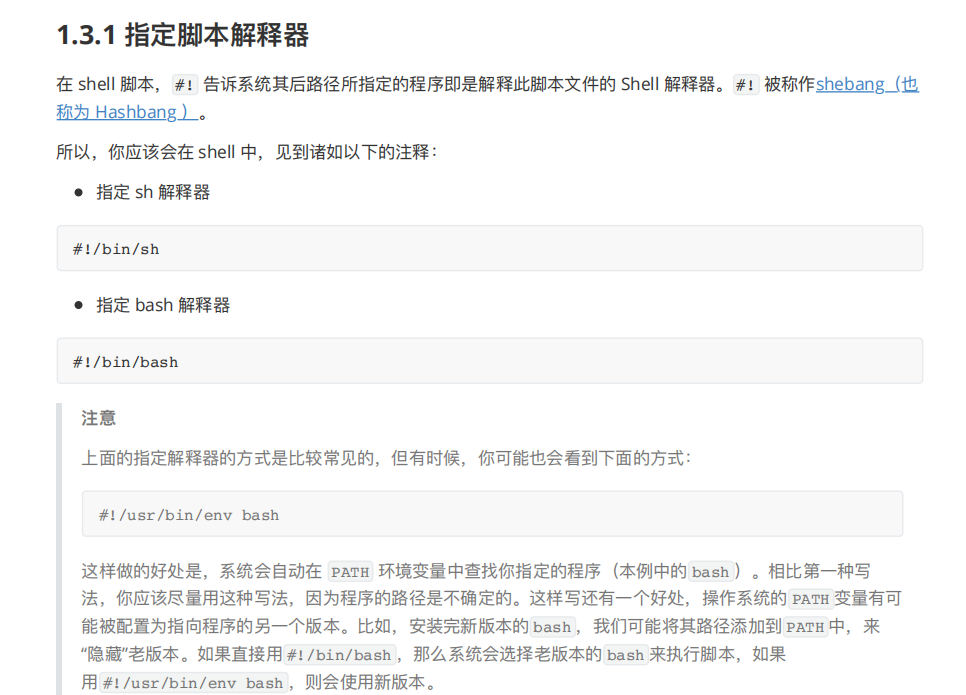
这种⽅式要求脚本⽂件的第⼀⾏必须指明运⾏该脚本的程序,⽐如:
!
『示例源码』
!/usr/bin/env bash
echo "Hello, world!"
上⾯的例⼦中,我们使⽤了⼀个很有⽤的命令 echo 来输出字符串到屏幕上。

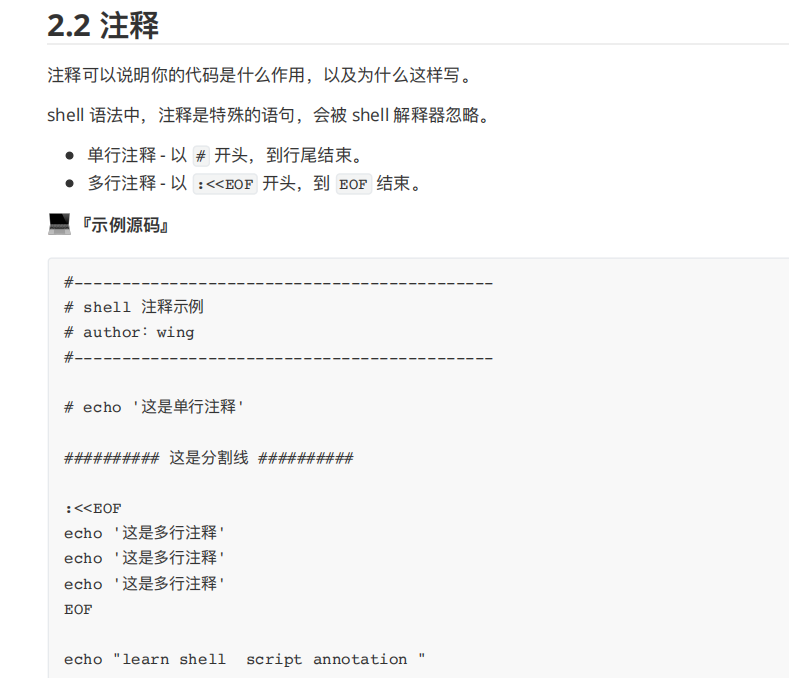
2.3 echo
echo ⽤于字符串的输出。
输出普通字符串:
以下两种⽅式都可以指定 shell 解释器为 bash,第⼆种⽅式更好
!/bin/bash
!/usr/bin/env bash
--------------------------------------------
shell 注释示例
author:wing
--------------------------------------------
echo '这是单⾏注释'
########## 这是分割线 ##########
:<<EOF
echo '这是多⾏注释'
echo '这是多⾏注释'
echo '这是多⾏注释'
EOF
echo "learn shell script annotation "
echo "hello, world"
Output: hello, world
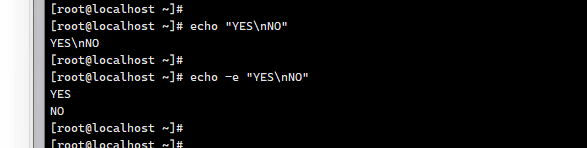
创造shell 路径
2.4 printf
printf ⽤于格式化输出字符串。
默认,printf 不会像 echo ⼀样⾃动添加换⾏符,如果需要换⾏可以⼿动添加 \n 。
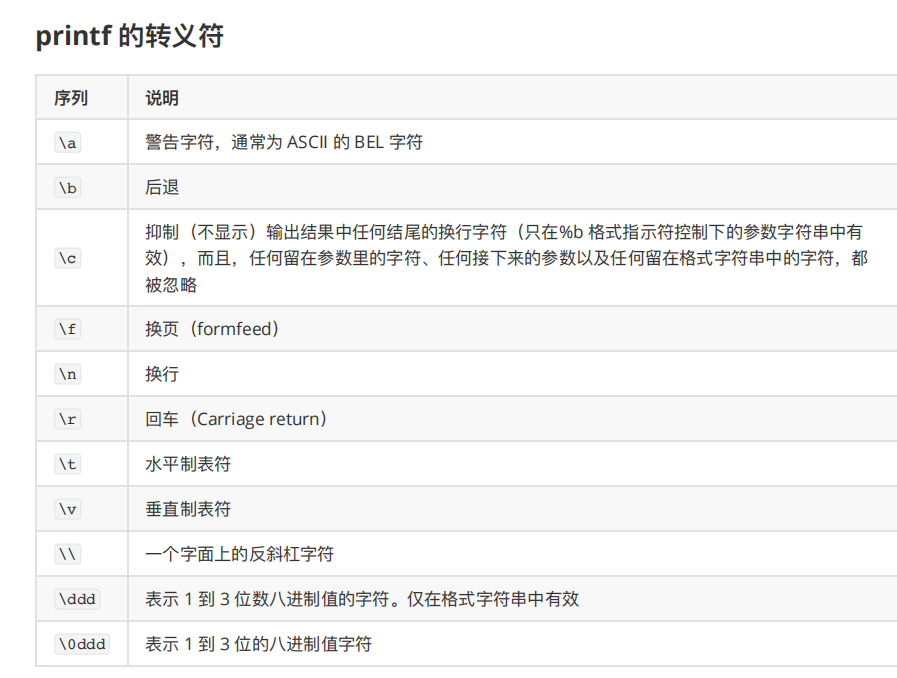

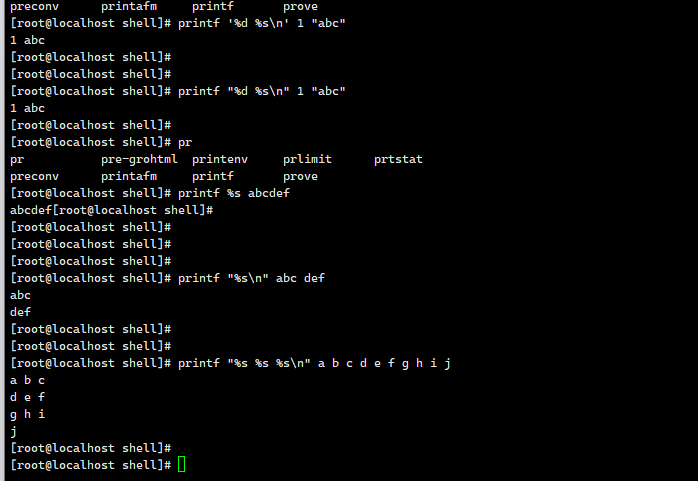
%s:占位符 代表一个整体字母或连一起的算一个 、斜杠n 换行


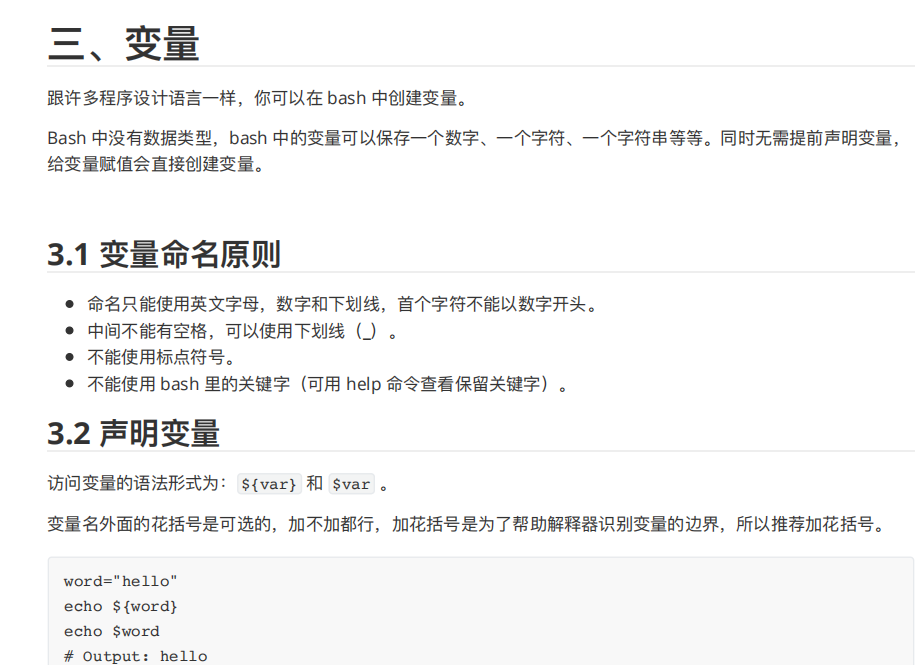


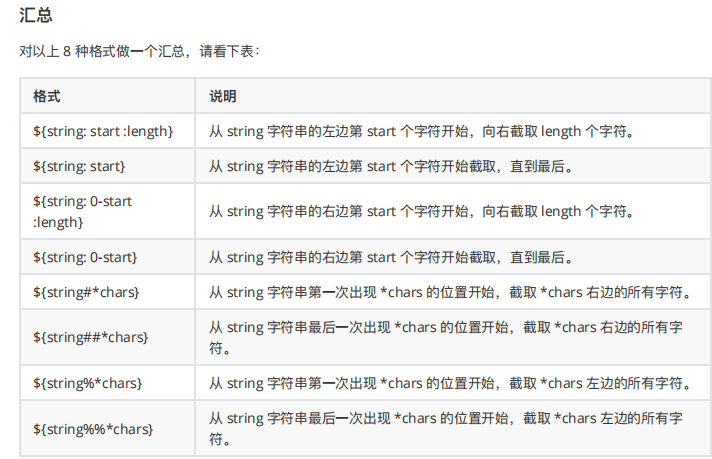
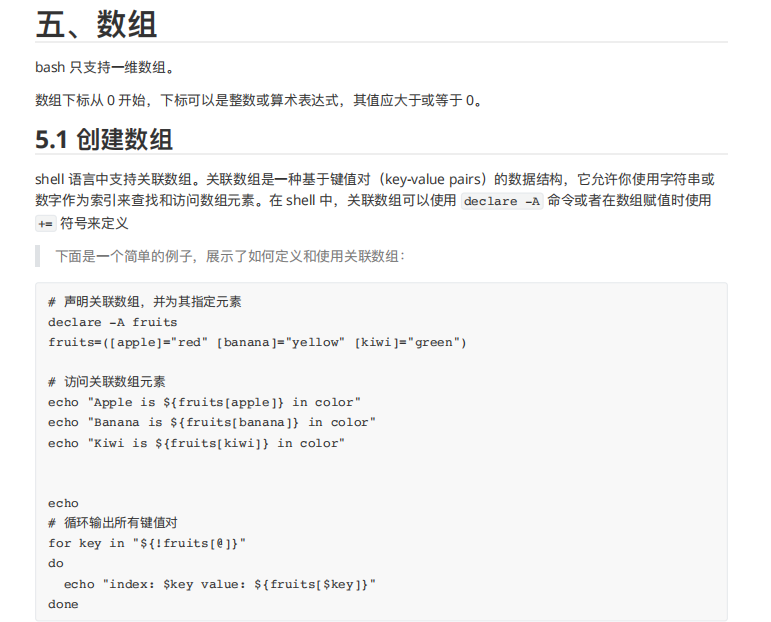
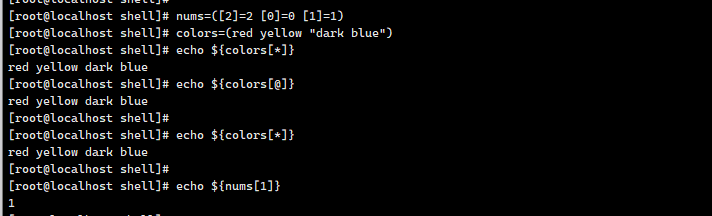
3.5 变量作⽤域
局部变量 - 局部变量是仅在某个脚本内部有效的变量。它们不能被其他的程序和脚本访问。
环境变量 - 环境变量是对当前 shell 会话内所有的程序或脚本都可⻅的变量。创建它们跟创建局部变量类似,
但使⽤的是 export 关键字,shell 脚本也可以定义环境变量。
常⻅的系统环境变量:
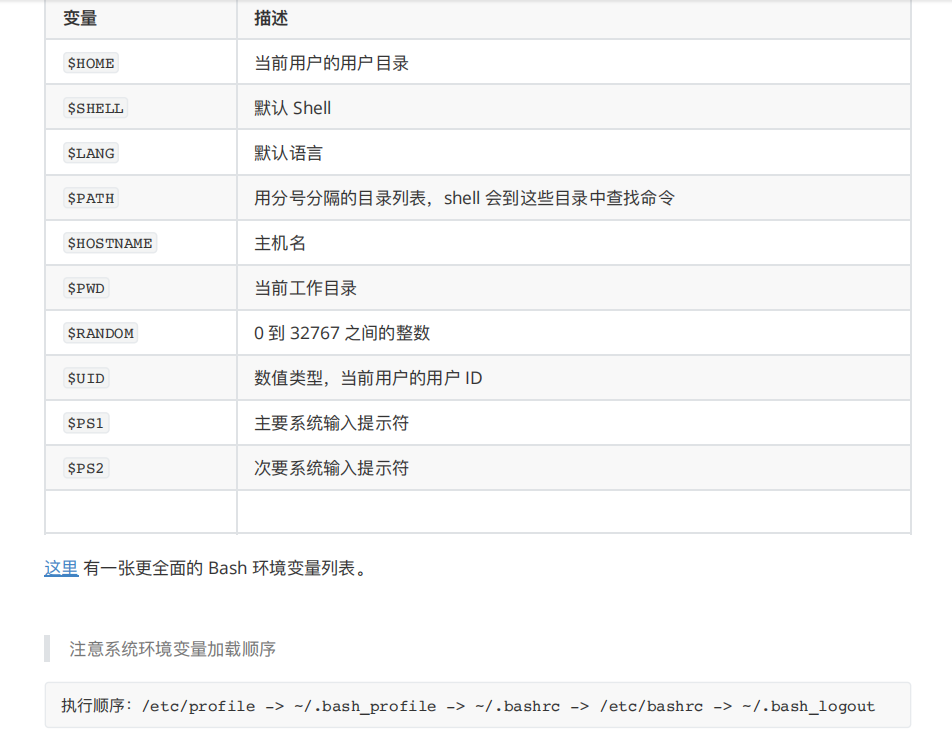

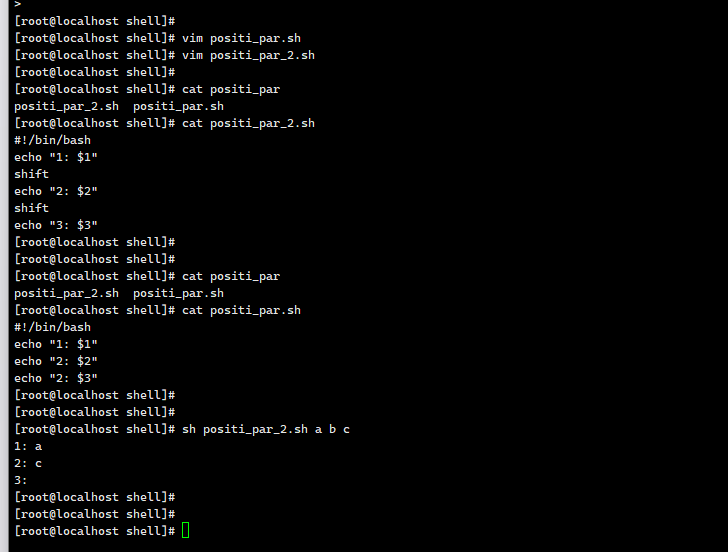
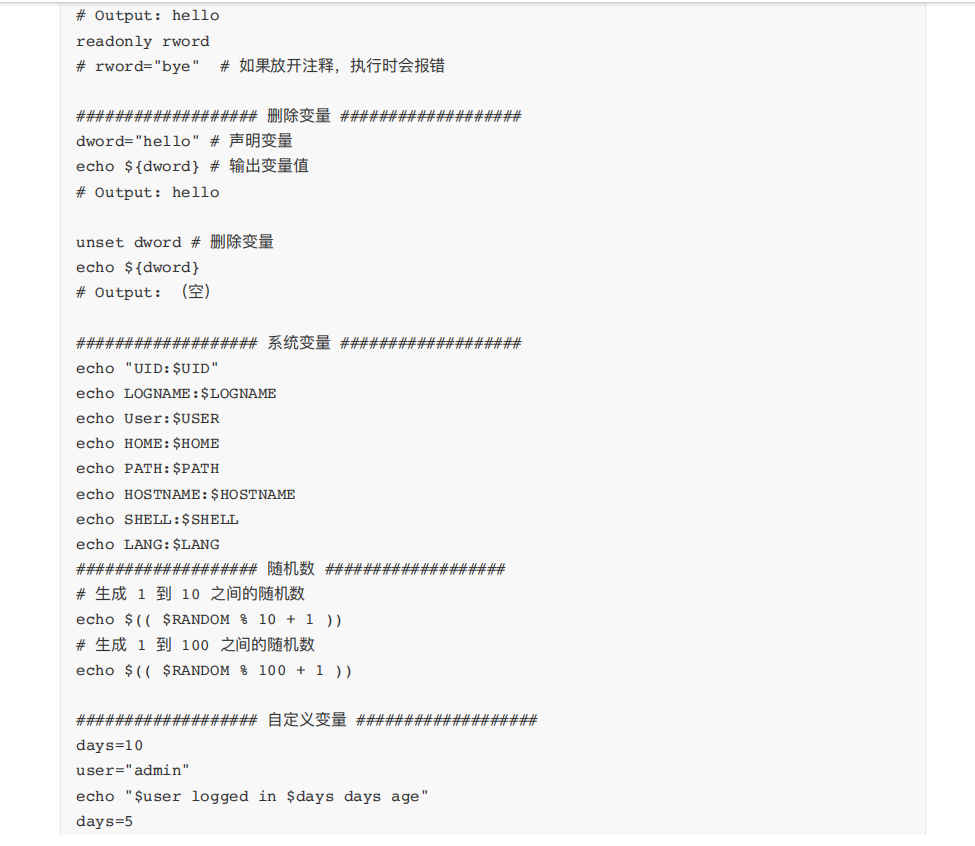
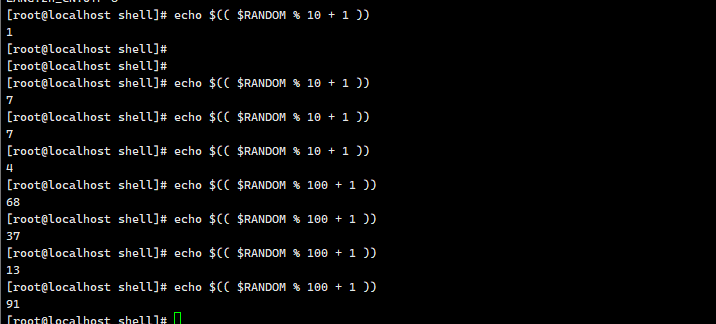
每执⾏⼀次 shift 命令,位置变量个数就会减⼀,⽽变量值则提前⼀位。shift n,可设置向前移动n 位。



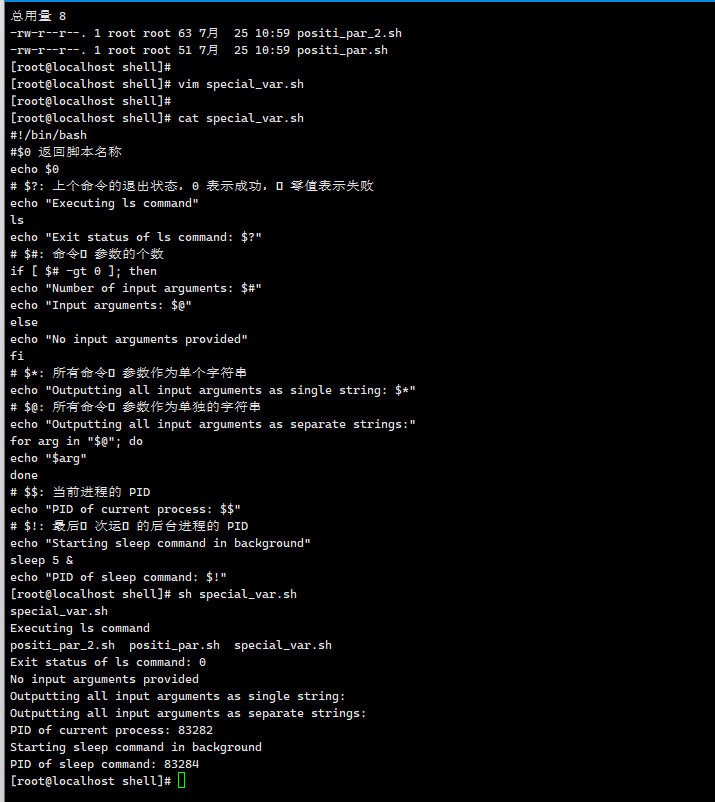
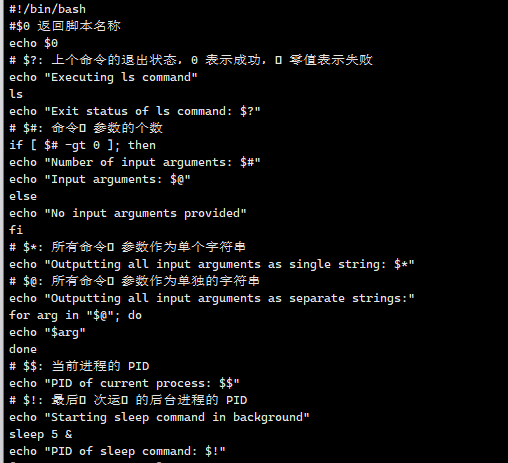
以下是对该Shell脚本的逐行详细解释,涵盖 变量含义、命令作用 及 运行逻辑:
1. 脚本头部:指定解释器
#!/bin/bash
- 声明脚本使用
bash解释器运行(系统需安装bash)。
2. 变量 $0:脚本名称
echo $0
$0表示 脚本本身的文件名(包含路径时会显示完整路径,如./test.sh或/home/user/test.sh)。
3. 变量 $?:上一命令的退出状态
echo "Exit status of ls command: $?"
ls
- 执行逻辑:先运行
ls命令(列出当前目录文件),再通过$?获取ls的 退出状态:0表示命令成功执行;- 非
0(如1、2等)表示命令失败(例如目录不存在时,ls会返回非0值)。
4. 变量 $#:参数个数判断
if [ $# -gt 0 ]; then
echo "Number of input arguments: $#"
echo "Input arguments: $@"
else
echo "No input arguments provided"
fi
$#:表示 脚本运行时传入的参数个数(如./script a b,则$#=2)。- 条件判断:
[ $# -gt 0 ]检查参数个数是否大于0:- 若有参数:输出参数个数(
$#)和所有参数($@,见下文解释); - 若无参数:提示“未提供参数”。
- 若有参数:输出参数个数(
5. 变量 $* vs $@:参数格式差异
echo "Outputting all input arguments as single string: $*"
echo "Outputting all input arguments as separate strings:"
for arg in "$@"; do
echo "$arg"
done
$*:将所有参数 合并为一个字符串(参数间用环境变量IFS分隔,默认是空格)。
例如:传入参数a "b c",$*会变成"a b c"(视为一个字符串)。$@:将每个参数 视为独立元素(保留参数内的空格,需配合引号使用,即"$@")。
例如:传入参数a "b c","$@"会拆分为a和b c两个元素。- 循环逻辑:通过
for arg in "$@"遍历参数,每个参数单独输出(即使参数含空格,也能正确识别)。
6. 变量 $$:当前进程PID
echo "PID of current process: $$"
$$表示 当前脚本进程的PID(可通过ps命令验证)。
7. 变量 $!:最后后台进程的PID
echo "Starting sleep command in background"
sleep 5 &
echo "PID of sleep command: $!"
- 后台运行:
sleep 5 &让sleep命令在 后台运行(&符号),睡眠5秒。 $!:捕获 最后一个后台进程的PID,此处即sleep进程的ID。
关键变量总结
| 变量 | 含义 | 典型场景 |
|---|---|---|
$0 |
脚本文件名 | 打印脚本自身信息 |
$? |
上一命令退出状态 | 检查命令是否成功 |
$# |
参数个数 | 判断是否传入参数 |
$@ |
所有参数(独立元素,需引号) | 遍历参数(处理含空格的参数) |
$* |
所有参数(合并为字符串) | 简单拼接参数 |
$$ |
当前进程PID | 调试进程 |
$! |
最后后台进程PID | 跟踪后台任务 |
通过这些变量,脚本实现了 参数处理、命令状态检查、进程ID跟踪 等功能,是Shell脚本中最基础且常用的语法。








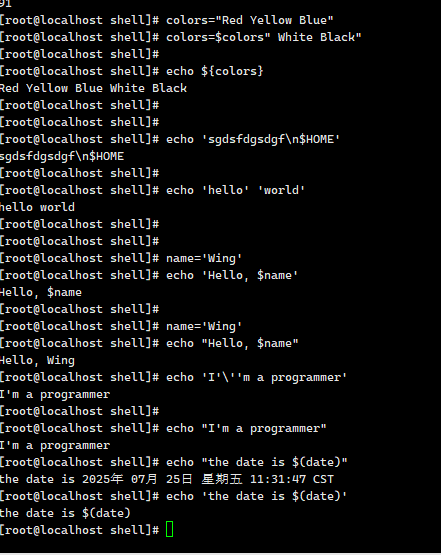
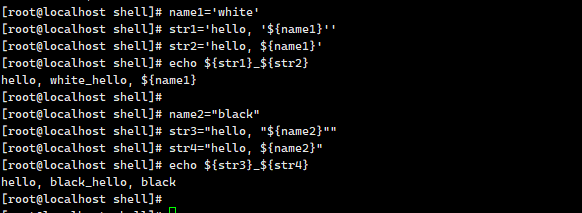
单引号 :所见即所得 不会解析 双引号 :可以识别 解析


:获取长度
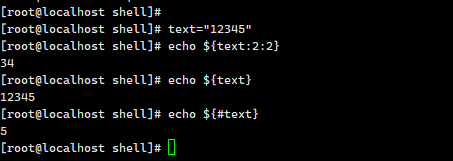


直到‘:’前面的忽略
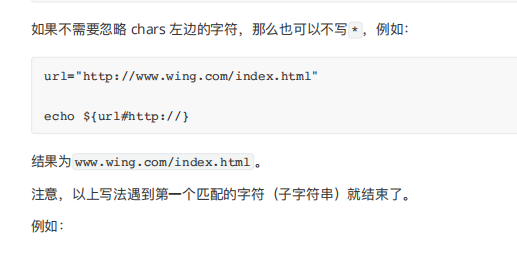
要分析 url="http://www.wing.com/index.html" 和 echo ${url#:*} 的行为,需理解 Shell 变量的「前缀删除」展开规则,核心是 ${var#pattern} 的语法逻辑:
1. 语法:${var#pattern} 的作用
- 功能:删除变量
var中 从开头开始、与pattern匹配的最短前缀(非贪婪匹配)。 pattern:通配符模式(如*代表任意字符序列,:是普通字符)。
2. 案例拆解:url="http://www.wing.com/index.html"
变量 url 的值为:http://www.wing.com/index.html(结构:http: + //www.wing.com/index.html)。
3. 模式匹配:pattern=":*"
:*的含义:匹配 以冒号(:)结尾的最短前缀(即从字符串开头,到第一个冒号为止的部分)。- 对
url来说:- 开头的字符序列是
http:(包含冒号:),这是第一个满足:*的前缀。
- 开头的字符序列是
4. 执行结果:删除匹配的前缀
- 原字符串:
http://www.wing.com/index.html - 删除
http:后,剩余部分://www.wing.com/index.html - 因此,
echo ${url#:*}输出//www.wing.com/index.html
扩展对比:# vs ##(最短 vs 最长匹配)
${var#pattern}:删除 最短 匹配的前缀(只删第一个符合条件的部分)。${var##pattern}:删除 最长 匹配的前缀(删到最后一个符合条件的部分)。
例如,若 url="a:b:c:d":
echo ${url#*:}→ 删最短前缀(a:),结果b:c:decho ${url##*:}→ 删最长前缀(a:b:c:),结果d
总结核心逻辑
${url#:*} 的本质是 「切割字符串」:通过通配符模式 :*,精准删除变量开头到第一个冒号的部分,最终保留冒号之后的内容。这种语法是 Shell 中高效处理字符串的技巧,无需调用 awk/sed 等外部工具。

逐行解析(基于 Shell 变量前缀删除扩展规则:#删最短、##删最长):
1. url="http://www.wing.com/index.html"
定义变量 url,值为 http://www.wing.com/index.html(结构:http:// + www.wing.com/index.html)。
2. echo ${url#:*}
- 规则:
${var#pattern}→ 删除变量开头 最短 匹配pattern的前缀。 - pattern:
:*(匹配「从开头到第一个冒号」的部分)。 - 计算:
http:是第一个含冒号的前缀,删除后剩//www.wing.com/index.html。
3. echo ${url##:}
- 规则:
${var##pattern}→ 删除变量开头 最长 匹配pattern的前缀。 - pattern:
:(匹配「从开头到最后一个冒号」的部分,此处仅1个冒号)。 - 计算:同
#:*(仅1个冒号),删除http:后剩//www.wing.com/index.html。
4. echo ${url##://}(推测实际应为 ##http://,否则逻辑矛盾)
- 若 实际是
##http://:- pattern:
http://(匹配协议头)。 - 计算:删除
http://后剩www.wing.com/index.html(符合用户最终输出)。
- pattern:
- 若真为
##://:因://不是字符串开头(开头是http:),不匹配前缀,输出原字符串(与用户结果矛盾,故判定为输入笔误)。
核心逻辑
#vs##:前者删最短匹配前缀,后者删最长匹配前缀。- pattern 匹配:必须从字符串开头开始匹配,否则不删除。
- 用户最终行的合理逻辑是
echo ${url##http://},用于提取「协议头后的域名+路径」。
![image]()
在 Shell 变量扩展中,*是通配符,用于匹配 任意长度的字符序列(包括空字符),核心作用是 定位要删除的前缀的边界。结合#(最短前缀删除)和##(最长前缀删除),具体逻辑如下:

1. 语法回顾
${var#pattern}:删除变量var中 从开头开始、与pattern匹配的最短前缀(非贪婪匹配)。${var##pattern}:删除变量var中 从开头开始、与pattern匹配的最长前缀(贪婪匹配)。
2. * 的作用(以案例分析)
假设 url="http://www.wing.com/index.html":
案例 1:echo ${url#*p:}
pattern:*p:→ 含义是 “任意字符序列 +p:”(*匹配任意字符,直到遇到p:)。- 匹配过程:从
url开头找 第一个满足*p:的前缀(即http:,因为h+ttp:符合*p:)。 - 结果:删除
http:,剩余//www.wing.com/index.html。
案例 2:echo ${url##*ttp:}
pattern:*ttp:→ 含义是 “任意字符序列 +ttp:”(*匹配任意字符,直到遇到ttp:)。- 匹配过程:从
url开头找 最后一个满足*ttp:的前缀(此处只有http:,因为h+ttp:符合*ttp:)。 - 结果:删除
http:,剩余//www.wing.com/index.html(因只有一个匹配,#和##结果相同)。
核心结论
pattern 中的 * 是 通配符,用于 模糊匹配字符序列,帮助 Shell 定位 “要删除的前缀的结束位置”:
- 配合
#:找第一个满足pattern的前缀(最短匹配)。 - 配合
##:找最后一个满足pattern的前缀(最长匹配)。
简单说:* 让 Shell 知道 “在哪些字符之后切割前缀”。


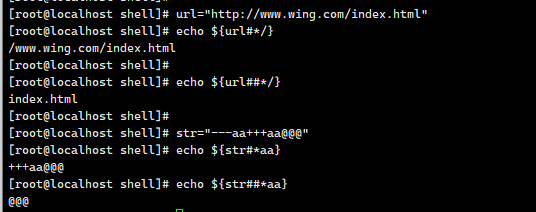
要理解这些 Shell 变量扩展,核心是掌握 #(最短前缀删除) 和 ##(最长前缀删除) 的规则,结合通配符 * 的匹配逻辑:
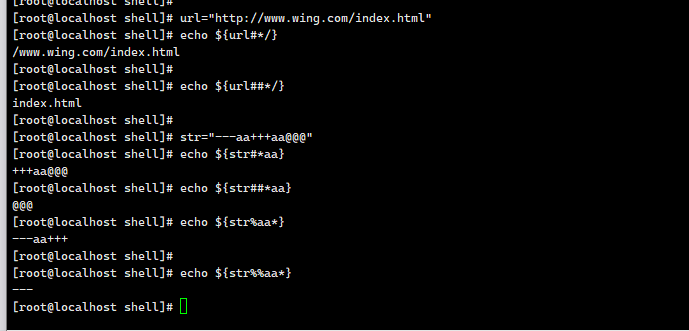
一、URL 案例解析
变量:url="http://www.wing.com/index.html"
1. echo ${url#*/}
- 规则:
${var#pattern}→ 删除 最短 匹配pattern的前缀。 - pattern:
*/→ 匹配「任意字符(*) + 斜杠(/)」的最短前缀。 - 匹配过程:
url开头是http://,第一个/出现在http:后(即http:/)。- 删除
http:/,剩余//www.wing.com/index.html。
2. echo ${url##*/}
- 规则:
${var##pattern}→ 删除 最长 匹配pattern的前缀。 - pattern:
*/→ 匹配「任意字符(*) + 斜杠(/)」的最长前缀。 - 匹配过程:
url中最后一个/是http://www.wing.com/末尾的/。- 删除
http://www.wing.com/,剩余index.html。
二、字符串 str 案例解析
变量:str="--aa+++aa@@@"
1. echo ${str#*aa}
- 规则:
${var#pattern}→ 删最短匹配pattern的前缀。 - pattern:
*aa→ 匹配「任意字符(*) +aa」的最短前缀。 - 匹配过程:
- 第一个
aa出现在开头--aa中,*匹配--,加上aa形成--aa。 - 删除
--aa,剩余+++aa@@@。
- 第一个
2. echo ${str##*aa}
- 规则:
${var##pattern}→ 删最长匹配pattern的前缀。 - pattern:
*aa→ 匹配「任意字符(*) +aa」的最长前缀。 - 匹配过程:
- 最后一个
aa出现在+++aa中,*匹配--aa+++,加上aa形成--aa+++aa。 - 删除
--aa+++aa,剩余@@@。
- 最后一个
核心逻辑总结
| 语法 | 作用 | * 的角色 |
匹配策略 |
|---|---|---|---|
${var#*x} |
删最短前缀(到第一个x) |
* 匹配 x 之前的任意字符 |
非贪婪(最短) |
${var##*x} |
删最长前缀(到最后一个x) |
* 匹配 x 之前的所有字符 |
贪婪(最长) |
*是通配符,负责模糊匹配「目标字符前的内容」,帮 Shell 定位删除的边界。#和##的区别在于:前者找第一个匹配,后者找最后一个匹配。
理解这两点,就能快速分析类似的变量扩展行为!



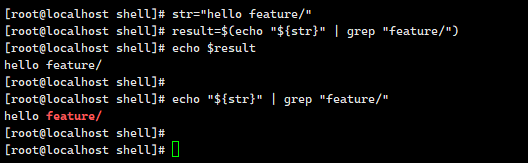
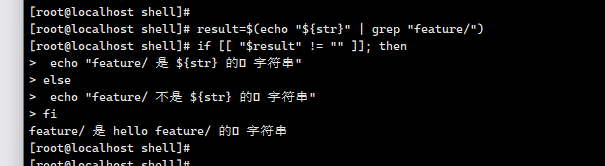
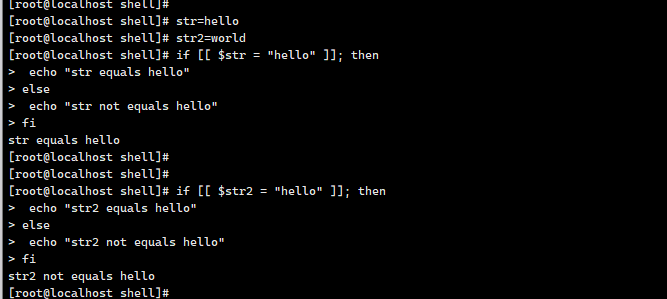
这段代码是 Shell 脚本,用于判断变量 $str 中是否包含子字符串 feature/,核心逻辑基于 grep 命令的匹配结果。以下逐行解析:
1. 提取匹配结果
result=$(echo "$str" | grep "feature/")
$(...):命令替换,将括号内命令的输出结果赋值给变量result。echo "$str":输出变量str的内容(双引号保证变量内的空格等特殊字符被正确处理)。| grep "feature/":管道符将echo的输出传给grep,grep查找是否包含子串feature/:- 如果找到,
grep会输出匹配的行(此处因str通常是单行,所以输出整行内容); - 如果没找到,
grep无输出(result为空字符串)。
- 如果找到,
2. 条件判断
if [[ "$result" != "" ]]; then
[[ ... ]]:Bash 增强的条件测试语法(比[ ... ]更强大,支持字符串比较、模式匹配等)。"$result" != "":判断result是否非空(即grep是否找到匹配内容)。
3. 分支逻辑
-
满足条件(
result非空,即找到feature/):echo "feature/ 是 ${str} 的子字符串"输出提示,表明
feature/是$str的子串。 -
不满足条件(
result为空,即未找到feature/):echo "feature/ 不是 ${str} 的子字符串"输出提示,表明
feature/不是$str的子串。
🌰 示例验证
假设 str="https://example.com/feature/list":
echo "$str" | grep "feature/"会输出整行(因包含feature/),result非空 → 执行then分支,提示“是子字符串”。
假设 str="https://example.com/home":
grep未找到feature/,result为空 → 执行else分支,提示“不是子字符串”。
✨ 补充说明
- 潜在问题:如果
str未定义(unset),echo "$str"会输出空行,grep也会匹配失败(result为空)。 - 更简洁的写法:可直接用
grep的退出状态判断(无需捕获输出),例如:
(if echo "$str" | grep -q "feature/"; then echo "包含" else echo "不包含" fi-q让grep静默运行,仅通过退出码$?判断是否找到,更高效。)
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
![image]()
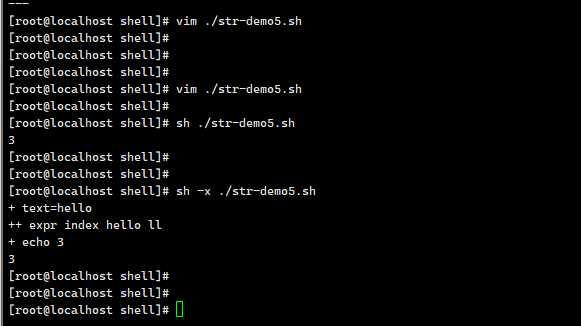
这段代码是 Shell 脚本(通常用于 Linux/Unix 环境),用于演示 变量运算 和 条件判断,以下逐行解析:






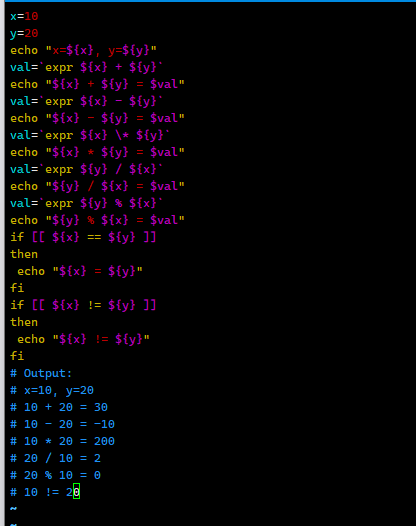

1. 变量定义
x=10
y=20
- 定义两个变量:
x的值为10,y的值为20。
2. 输出变量值
echo "x=${x}, y=${y}"
- 作用:输出
x和y的值。 - 结果:
x=10, y=20(${x}和${y}是变量替换,会被实际值替换)。
3. 算术运算(依赖 expr 命令)
expr 是 Shell 中用于整数运算的命令,需注意:
- 运算符(
+、-、*、/、%)两侧必须有空格; - 乘法
*需要转义(写为\*,否则会被 Shell 当作通配符解析)。
(1) 加法
val=`expr ${x} + ${y}` # 计算 x + y,结果存入 val(10+20=30)
echo "${x} + ${y} = ${val}" # 输出:10 + 20 = 30
(2) 减法
val=`expr ${x} - ${y}` # 计算 x - y(10-20=-10)
echo "${x} - ${y} = ${val}" # 输出:10 - 20 = -10
(3) 乘法
val=`expr ${x} \* ${y}` # 乘法需转义 *,计算 10*20=200
echo "${x} * ${y} = ${val}" # 输出:10 * 20 = 200
(4) 除法
val=`expr ${y} / ${x}` # 计算 y / x(20/10=2)
echo "${y} / ${x} = ${val}" # 输出:20 / 10 = 2
(5) 取余(模运算)
val=`expr ${y} % ${x}` # 计算 y % x(20%10=0)
echo "${y} % ${x} = ${val}" # 输出:20 % 10 = 0
4. 条件判断([[ ... ]] 语法)
[[ ... ]] 是 Bash 扩展的条件表达式(比传统 [ ... ] 更强大),支持 ==(相等)、!=(不等)等比较。
(1) 判断是否相等
if [[ ${x} == ${y} ]]; then
echo "${x} = ${y}"
fi
- 逻辑:判断
x和y是否相等(10 == 20?不成立),因此不会执行echo。
(2) 判断是否不等
if [[ ${x} != ${y} ]]; then
echo "${x} != ${y}"
fi
- 逻辑:判断
x和y是否不等(10 != 20?成立),因此执行echo,输出:10 != 20。
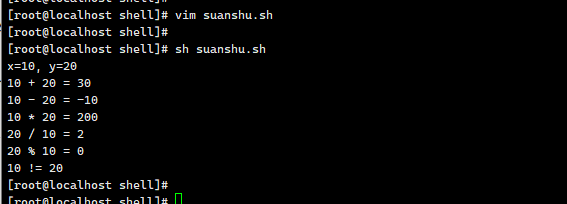
最终运行结果
结合注释里的预期输出,实际运行后会打印:
x=10, y=20
10 + 20 = 30
10 - 20 = -10
10 * 20 = 200
20 / 10 = 2
20 % 10 = 0
10 != 20
注意事项
expr的局限:仅支持整数运算,若需浮点运算,需用bc等工具。- 转义问题:乘法必须转义
*,否则 Shell 会将其视为“文件通配符”(匹配任意字符)。 - 变量引用:
${x}是推荐的变量引用方式(比$x更安全,避免歧义)。
这段脚本主要是演示 Shell 中最基础的算术运算和条件判断,适合入门学习。
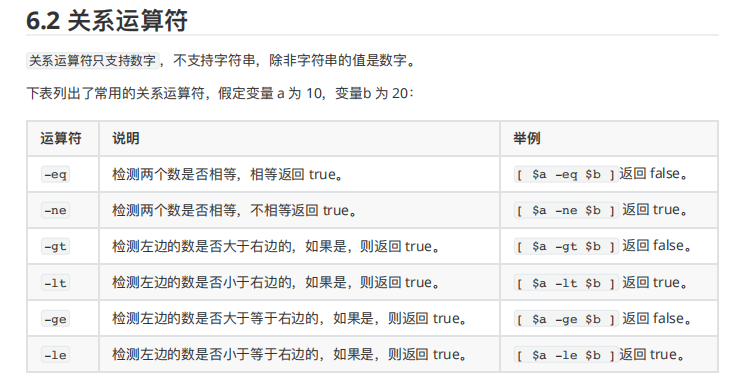
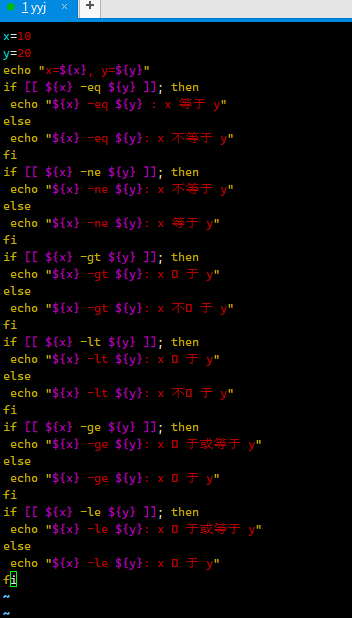
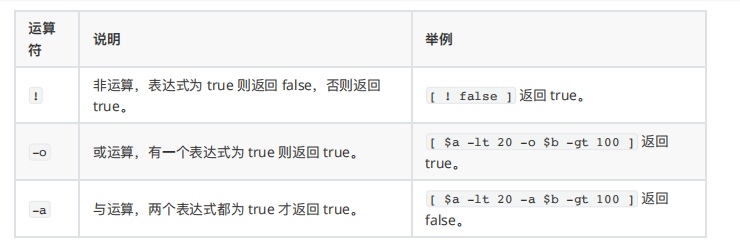
6.3 布尔运算符
下表列出了常⽤的布尔运算符,假定变量 a为 10,变量 b 为 20:



6.5 字符串运算符
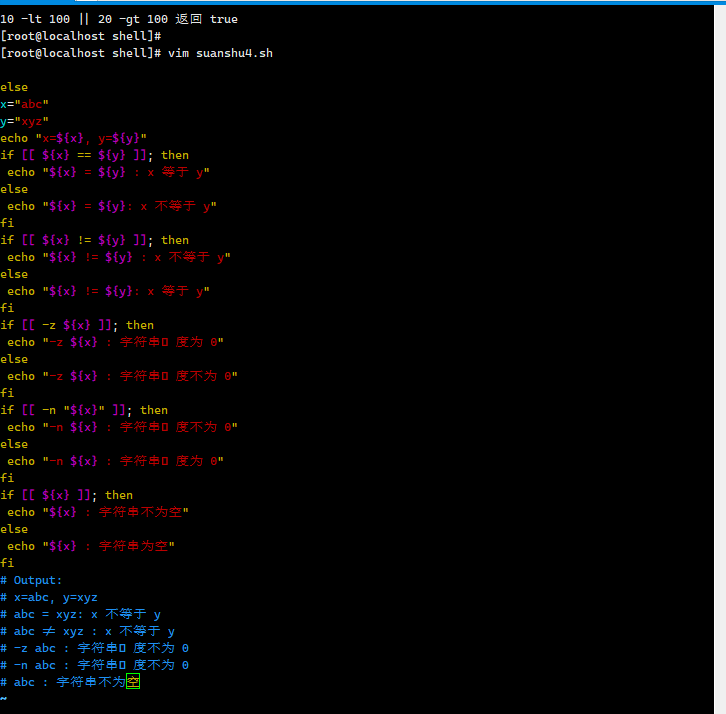
下表列出了常⽤的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:

6.6 ⽂件测试运算符
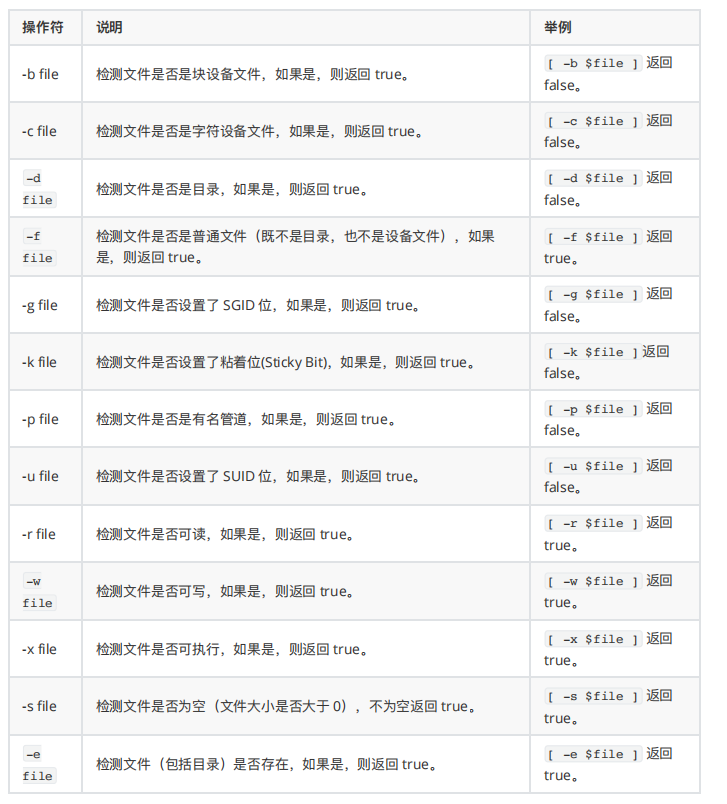
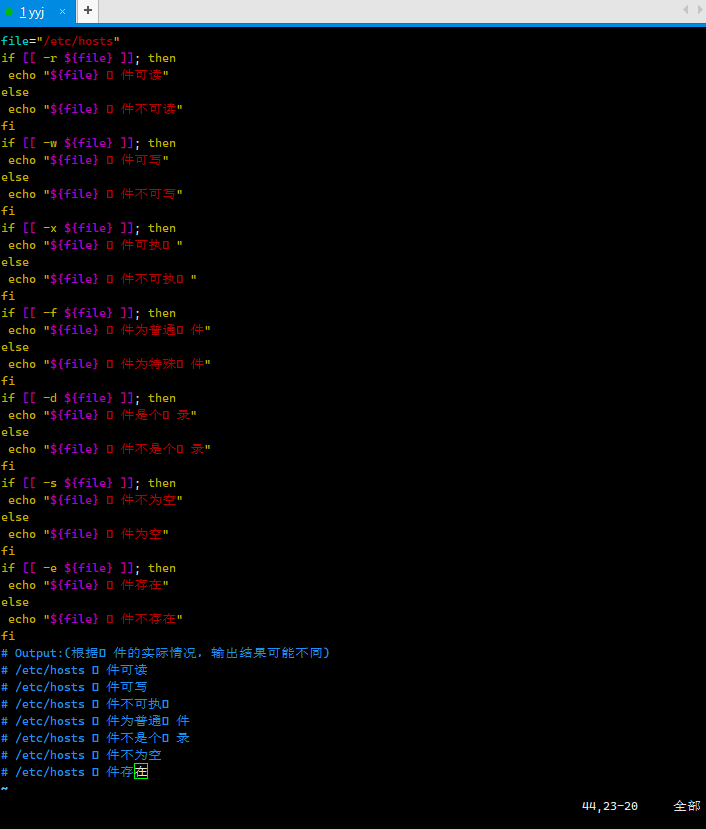
⽂件测试运算符⽤于检测 Unix ⽂件的各种属性。
属性检测描述如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号