


#学习笔记# VALSE 2019.01.09 朱俊彦 --- Learning to Synthesize Images, Videos, and 3D Objects
视频类型:VALSE-webinar
报告时间:2019年01月09日
报告人:MIT朱俊彦
报告题目:Learning to Synthesize Images, Videos, and 3D Objects
报告网址:http://valser.org/article-298-1.html
视频地址:http://www.iqiyi.com/w_19s78pzlsx.html#vfrm=8-8-0-1
Part 1 : image generation
给定一个输入图像x,学习一个生成器G,使输出图像尽可能与真实图像y相似。
该问题面临三个挑战:
- How to design an objective L?
- How to optimize L?
- How to collect data (x, y)?
解决篇
1. How to design an objective L?
pix2pix,可以自动设计损失函数。
不仅要生成高清的图像,还要生成的图像和输入相匹配。
pix2pix提供了一个可学习的损失函数,受到GAN的启发,但也用到了输入图像。
2. How to optimize L?
pix2pixHD, Large-scale optimization。
使用到传统思想 Image Pyramid [Burt and Adelson 1987],即coarse-to-fine。先生成低分辨率的图像,然后增强细节,直到生成高分辨率的图像。
好处:(1)smooth energy landscape 。处理低分辨率图像时,图像的起伏landscape会平缓很多。
(2)reduce the number of parameters。参数数量减少,训练速度加快。
实现:
(1)训练一个模型生成低分辨率图像,pix2pix实现
(2)用低分辨率的输出图像和高分辨率的输入图像结合,生成高分辨率图像。具体如图或参考原文。

3. How to collect data (x, y)?
CycleGAN, learning without pairs. 不用成对的数据,学习两个域间的映射。
First reference: Mark Twain提出,在语言翻译中(如,英语翻译到法语再到英语),即使一个人不懂法语,也可以检查翻译的质量,通过“back translation”,看翻译回来的句子和最初的句子是否一致。
由以上启发提出cycle-consistency loss,解决了mode-collapse问题,从一张马的图像x出发,通过正向映射G,得到输出G(x),同时使用对抗损失来判别输出斑马的真假,同时学习反向的映射F,把斑马再变回马,测量重建的马和原始的马之间的差距。这就解决了mode-collapse的问题。
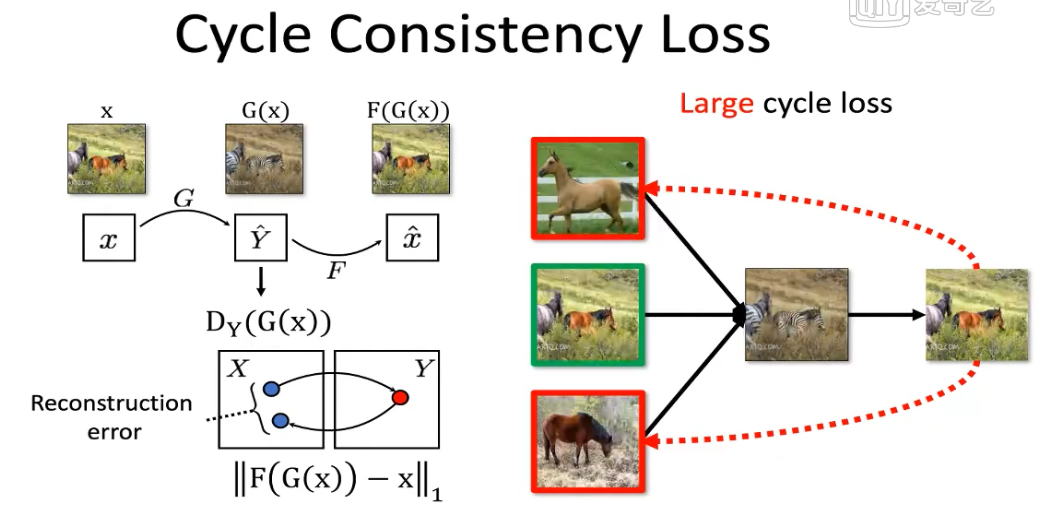
但是CycleGAN不会永远成功。斑马人的例子,是由于训练数据集中只有野马的图像,没包括马上的骑手,所以在测试阶段对新物体并不有效。
Part 2 : Understanding Black-box Networks
问题:如何理解这样一个黑盒子网络?如果出现问题,该如何调试?
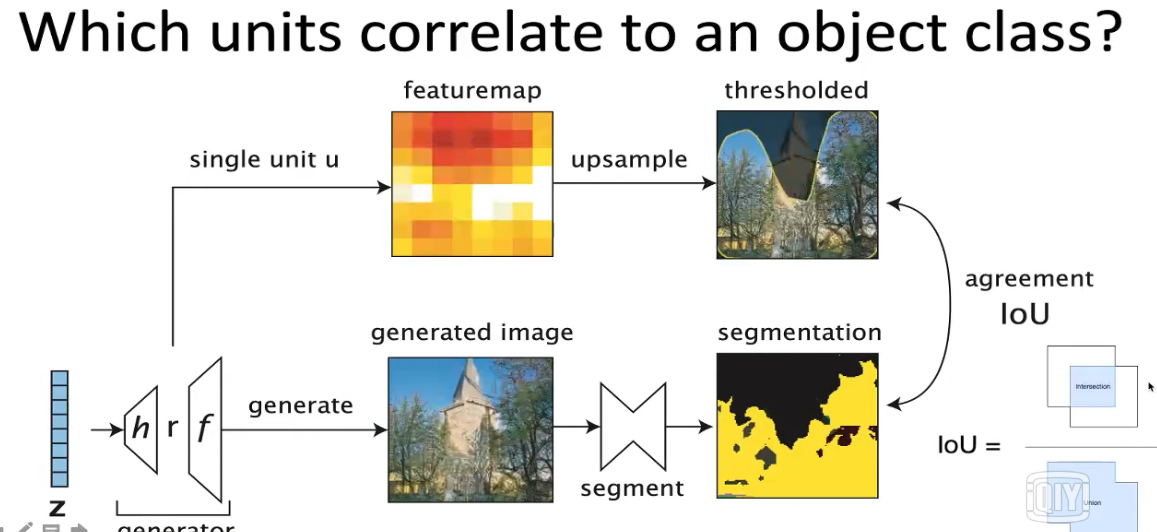
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
通过训练集,训练出决定某个物体的units,可以控制这个units来控制图像中某物体(如树)的有无或数量,实现对图像中物体的增减。也可以找出决定瑕疵的单元,去除这个单元就能达到去瑕疵的效果。(具体内容和原理见论文,暂时看不懂原理)
Part 3 : 2D-->3D
为了使GAN能够支持视频生成、游戏体验、虚拟现实等场景,我们需要从2D出发,向3D扩展,甚至4D,5D,即包括相机视角、时间戳以及三维空间坐标的五维空间。即vid2vid
#sequential generator#
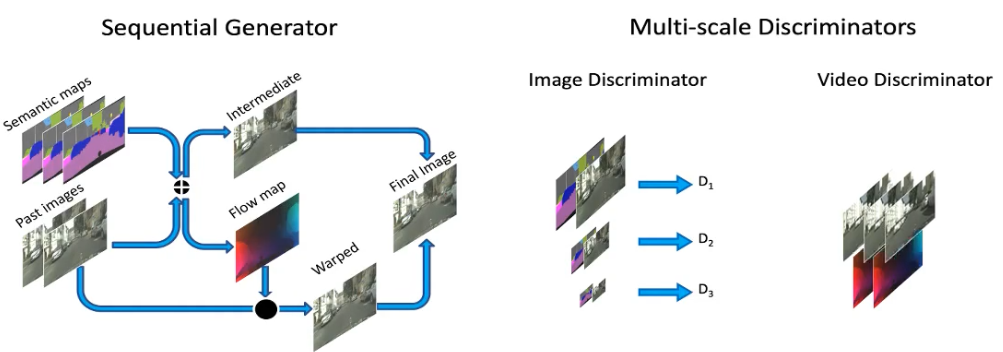
给定输入语义标签图,我们要生成对应的输出视频,一种方法就是直接用pix2pixHD逐帧生成,但是结果看上去并不好,帧与帧之间有大量的闪烁,因此在英伟达赞助下,我们提出了一种方法。基本思路是使用基于图像扭转(warpping-based)的方法,生成当前帧到下一帧的光流,以及一些细节,再通过基于光流的方法,将两部分融合在一起。网络需要学习光流信息,才能合成下一帧。其中的关键在于,前面生成的帧还可以重复使用,只需要增添一些新的细节即可。每生成一帧后,便将其加入之前的帧序列中,送进网络中。这有点像循环神经网络。
#multi-scale discriminators#
我们还考察了不同的判别器,引入了空间多尺度和时间多尺度,比如时域上我们观察两帧,四帧到八帧的时间尺度,以保持长期的时域一致性。
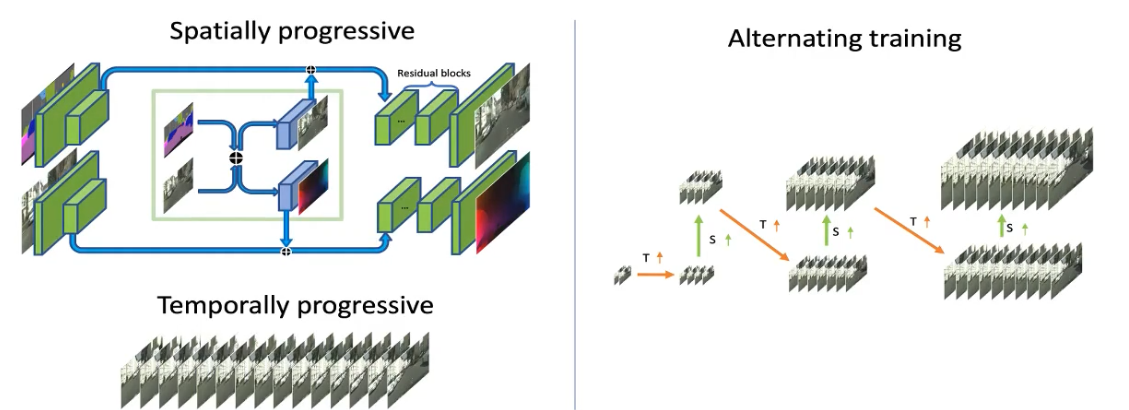
#progressive training#
同时在训练时,采用增量递进(progressive growing)的策略,先从合成低分辨率图像开始,然后增大分辨率。对时域也同样处理,先生成连续两帧,然后再到四帧,再训练模型生成八帧,直到最后一次生成十六帧。
#alternative training#
空域和时域的增长交替进行,首先合成低分辨率图像,连续四帧,然后让分辨率稍作提升,接着增加帧数,比如八帧,然后再提升分辨率,再增加时长,整个训练是一个增量式的过程。
应用:street views,customized gaming,motion transfer
Part 4 : 2D vs 3D
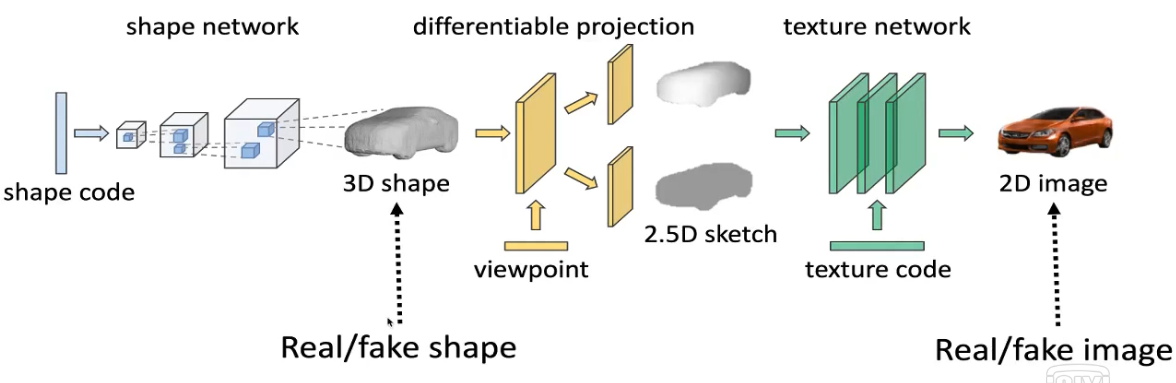
WGAN-GP是传统的2D生成对抗网络,能够生成样本。提出了Visual object networks,不仅能合成2D图像,还能创建3D模型,可以将模型投影到深度图加掩模的2.5D表示,再合成最终的2D图像。这其中最大的优势在于,可以生成不同视角下的图像,或者改变物体形状而保持视角和表面纹理,或者固定物体形状和视角,只更换表面纹理,从而使这三个要素彼此分离,共同支撑3D场景中的编辑。
#learning 3D disentanglement#
首先给定物体形状的编码,训练一个网络来生成3D模型,同样地,用判别器来检查生成样本是真是假。接着,将3D模型投影,得到2.5D的中间表示,投影算法的实现是可以反向求导的,梯度可以从2.5D表示传回3D模型层。之后再添加纹理,这部分比较像CycleGAN,从2.5D的草图生成2D图像。物体的形状、观察的视角以及表面纹理都可以由对应的编码所控制。整个模型采用端到端训练,对于2D图像和3D模型都有相应的判别器去鉴别真伪,所有的模块一同参与训练。
小结:
图像生成部分之外的部分,没看过论文,理解不是很深刻,具体原理不是很清楚。但是大佬的这些工作让人受益匪浅,在GAN领域真是相当厉害了。趁热打铁补论文~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号