
Xadmin控件的实现:〇八查询视图六——list视图filter功能
前面讲到了list视图里的search和action两个功能,那两个功能实现的都比较简单,今天要实现的功能就难了——filter.
为了能参考admin组件里的filter,我们先看看他的效果
class BookConf(admin.ModelAdmin): list_display = ['title','publisher','price'] search_fields = ['price'] def patch_init(self,request,queryset): print(queryset) patch_init.short_description = '测试action' actions = [patch_init] list_filter = ['publisher','authors'] admin.site.register(models.Books,BookConf)
就是通过list_filter列表来设置filter的属性的
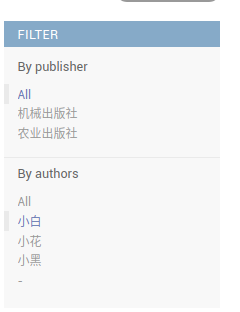
就是出来了这样的效果
filter里没有放title这种内容基本不重复的字段,是因为如果默认情况下只有ALL和分别显示所有数据的filter,当书特别多的时候每本书的title都会显示在filter里。所以一般用filter都是一对多或者多对多的字段,就像上面的publisher和author一样。
然后可以看一下这些a标签,看看页面的源代码
<h3> By authors </h3> <ul> <li class="selected"> <a href="?publisher__id__exact=5" title="All">All</a></li> <li> <a href="?authors__id__exact=1&publisher__id__exact=5" title="小白">小白</a></li> <li> <a href="?authors__id__exact=3&publisher__id__exact=5" title="小花">小花</a></li> <li> <a href="?authors__id__exact=2&publisher__id__exact=5" title="小黑">小黑</a></li> <li> <a href="?authors__isnull=True&publisher__id__exact=5" title="-">-</a></li> </ul>
注意URL点特点。我们后面会用到。
还有一点,如果我们设置了多个filter后,先后点击选项以后是合并搜索的
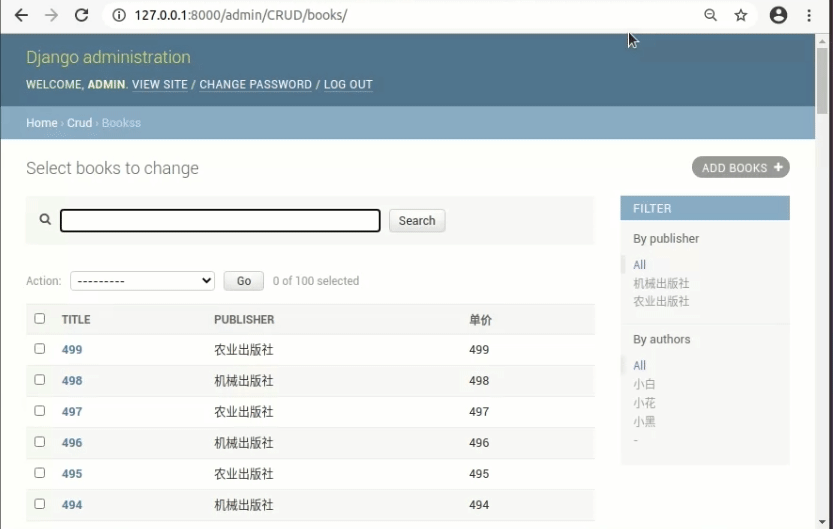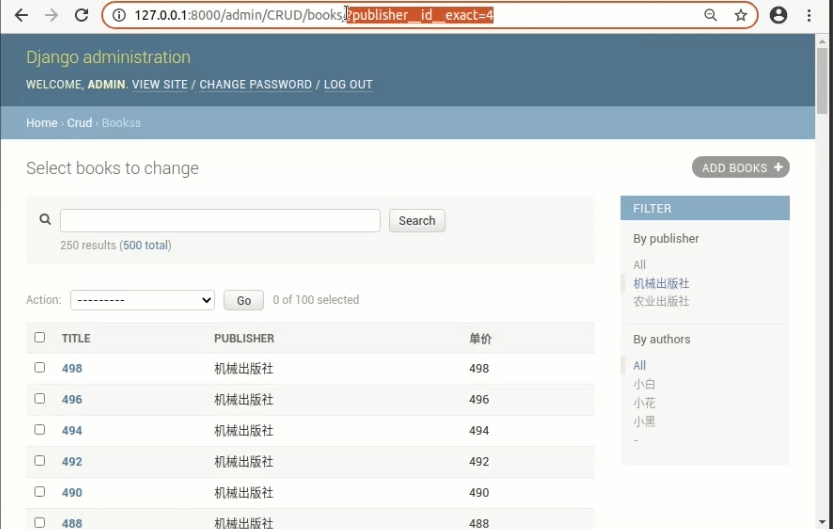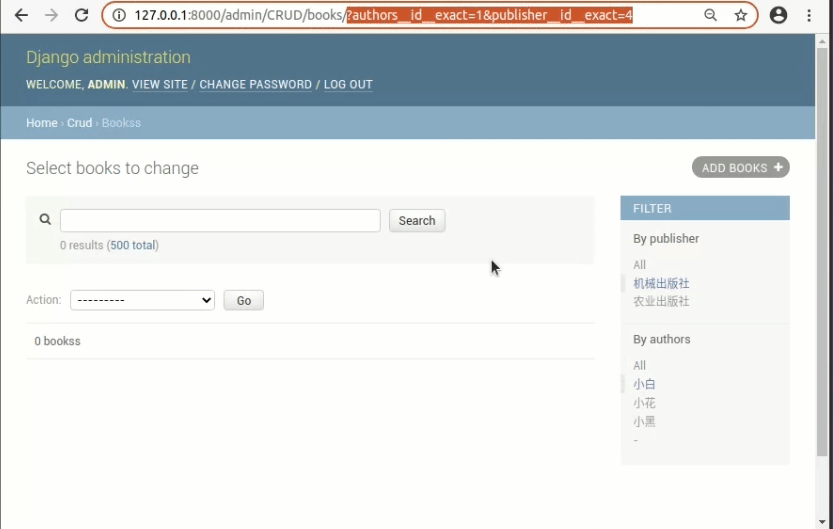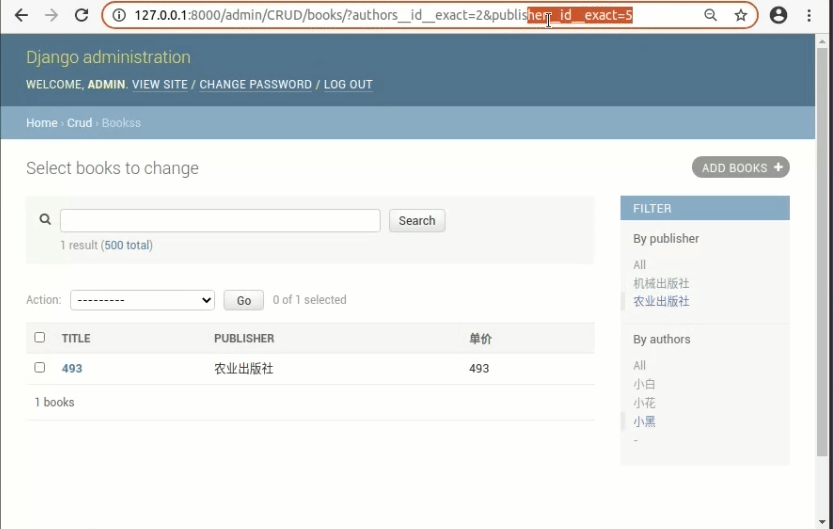
着重关注点击链接以后的URL变化,当点击多个filter的时候URL里是叠加的效果。
还有一点图上没有显示出来,在点击一个字段的filter标签的时候,URL里只更新当前的字段。
而一旦点击了filter里的标签以后,相当于发送了一个GET请求,页面响应以后所有filter里的URL都会相应的发生变化。也就是说这个filter里的a标签是有状态保持效果的,和分页的功能差不多。
上面讲了admin组件里的filter功能的实际效果,下面我们就来试一下怎么给我们的Xadmin控件添加上filter的功能。
前端的a标签
首先看一下这个a标签是怎么拿到的
比方说我们就先定义一个publiser的字段要执行filter,那么在前端的页面上要显示出来所有publisher的内容。因为要生成在前端渲染的a标签,就把这个生成a标签的函数放在List_View类里。先把代码放出来我们一步步来分析
1 def get_filter_linktags(self): 2 3 ret = "<h2>Filter</h2>" 4 for filter_field in self.conf_obj.list_filter: 5 current_id = self.request.GET.get(filter_field) 6 7 all_pram = deepcopy(self.request.GET) 8 param = deepcopy(self.request.GET) 9 10 filter_field_obj = self.conf_obj.model._meta.get_field(filter_field) 11 12 if filter_field in all_pram: 13 del all_pram[filter_field] 14 15 all_url = all_pram.urlencode() 16 17 ret += """ 18 <div class='well'> 19 <h3>{0}</h3> 20 <a href = '?{1}' class='default'>All </a>""".format(filter_field,all_url) 21 22 else: 23 all_url = all_pram.urlencode() 24 ret += """ 25 <div class='well'> 26 <h3>{0}</h3> 27 <a href = '?{1}' class='active'>All </a>""".format(filter_field,all_url) 28 29 data_list = filter_field_obj.remote_field.model.objects.all() 30 for data in data_list: 31 param[filter_field]=data.pk 32 _url = param.urlencode() 33 if current_id == str(data.pk): 34 35 ret += "<div><a href='?{0}' class='active'>{1}</a></div>".format(_url,data) 36 else: 37 ret += "<div><a href='?{0}' class='default'>{1}</a></div>".format(_url,data) 38 ret += "</div>" 39 return ret
整段代码包含了一些后续的功能,所以看起来比较长,主要的地方是在滴29行后面的。
第一步是通过我们在list_filter列表里的元素搜索对应的字段里的元素,这个操作有些类似SQL里的聚合查询,提出来所有的内容
filter_field_obj = self.conf_obj.model._meta.get_field(filter_field)
data_list = filter_field_obj.remote_field.model.objects.all()
如果我们filter的对象是Books类里的Publisher字段,那么filter_field_obj就是我们在定义Book类的时候的Foreignkey类。

图里就是打印的type。django在定义Foreignkey的时候已经给出了获取这个字段关联的另一张表里的内容的方法就是上面的remote_field
daga_list就是通过book表里的publisher字段查询Publisher表里的所有对象。
然后就是通过第30行开始的for循环来生成所有的a标签。
状态的保持
和前面讲到分页一样,这个filter也要考虑到有其他参数的保持的状态(比方先后对publisher和authors字段进行filter)。方法就是通过第31行的赋值语句,param是通过request.GET获取的字典,字典里分为下面几种状态:
- 无任何filter状态
- 有字段1,但需要追加一个字段2的filter
- 有字段1和2,但是需要更改2的状态
所以这个字典是个好东西,前两种状态下被索引的key是不存在的,直接通过赋值语句加上新的键值对就行了,而第三种也是直接通过赋值语句修改新的值,简单明了,最后通过urlencode方法直接生成URL传给a标签的href属性。
a标签被点击效果
a标签应该有个被选中的效果,当我们选中了一个filter之后这个a标签是应该变色的
所以我在for循环里添加了一个if判断 ,可以在生成标签的时候通过request.GET.get(field)获得当前的数据current_id,在for循环的过程中一旦数据的id和current_id一致就说明这个数据对应的标签是被点击的,通过CSS加了个效果。
ALL标签的实现
注意一下admin标签里,每个filter的字段都是有个ALL底选项的,这个ALL的思路就是把这个param字典里filter的字段对应的键值对删除掉。但是有两点要注意:
- 添加ALL按钮一定要在添加其余数据前面
- 要先判断param字典里是否包含需要ALL的字段
第一条其实好理解,本身就是按照显示的顺序添加的,我说这个点是因为在生成ALL的时候删除了字典里的键值对,需要后面的赋值语句重新添上。
第二条也简单,因为在对字典删除键值对的时候如果不存在这个键值对,按程序就报错了,所以要先判定一下这个键值对是否存在,如果不存在其实也说明现在的状态就是全部显示,没经过filger。
在前端的效果已经完成以后,我们就要看看怎么对数据进行filter了。其实整个过程跟search有些像,都是通过requset.GET获得一个字典,唯一一点区别就是search中的键值对里的key是固定的(直接在URL里写死的q)。而filter的键值对是不定的,就需要我们队整个键值对进行遍历。和search一样,我们把整个获取搜索条件的方法封装到一个函数里
1 def get_filter_condition(self,request): 2 filter_words = request.GET 3 search_connection = Q() 4 5 if filter_words: 6 search_connection.connector= 'or' 7 for field,value in filter_words.items(): 8 search_connection.children.append((field,value)) 9 10 return search_connection
也是通过一个for循环拿到字典里的键值对,然后放到Q查询对象中。在视图中调用这个函数的过程这里就不写了,和search是一样的,但是filter的过程要注意。
all_data = self.model.objects.filter(filter_conn).filter(search_conn)
注意两次filter的写法,不分先后。
但是现在这样是有个BUG的,我们可以试一下:
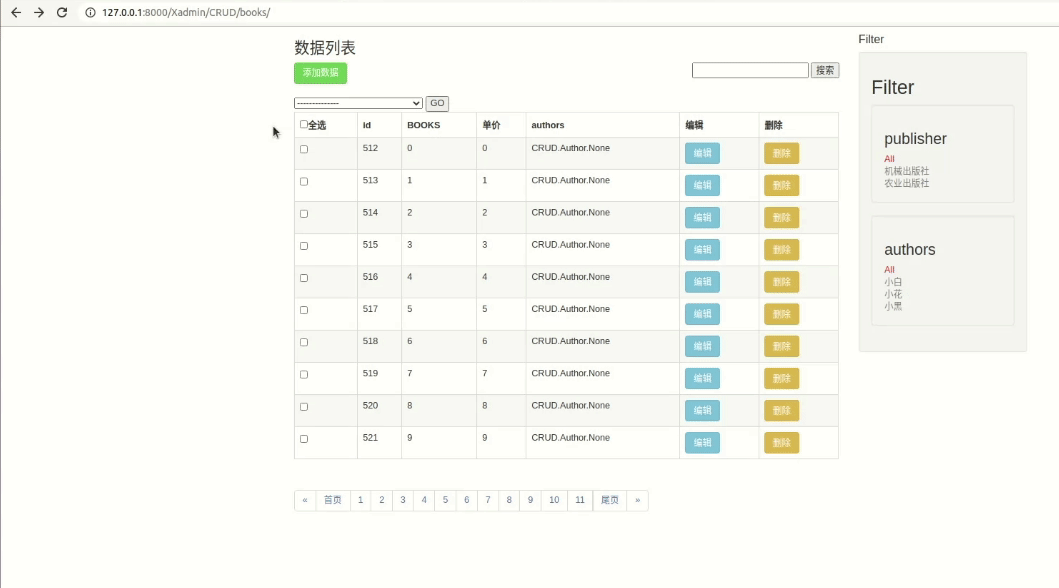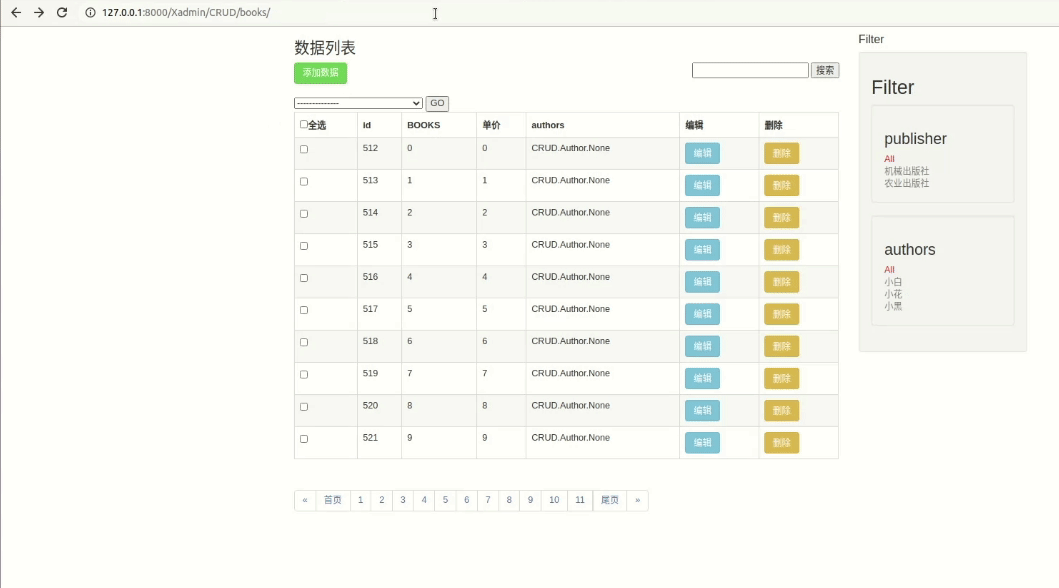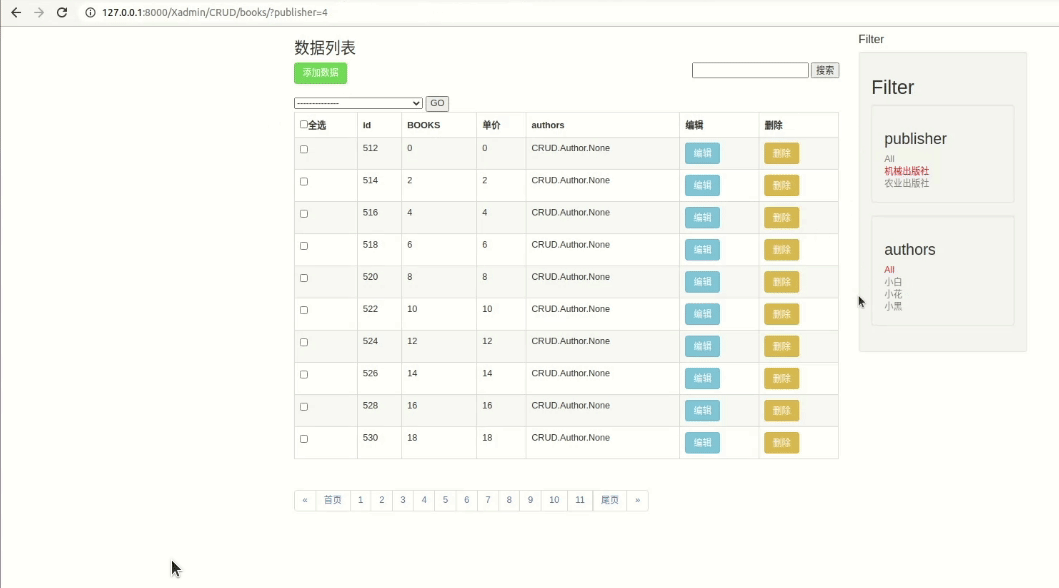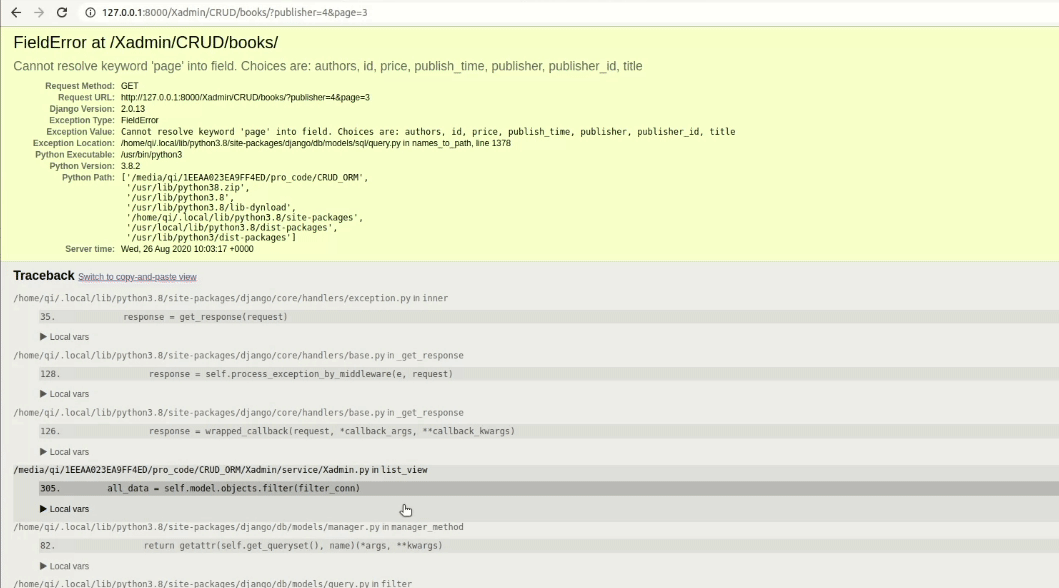
是不是报错了,
BUG解决
引发这BUG点原因注意看一下函数的流程和URL就可以了,我们在进行filter的时候是没问题的,但是由于在resquest.GET里的键值对包含一个page的健,在for循环中因为没有对应的字段就报错了,所以就要在数据索引前加上一个判断
1 def get_filter_condition(self,request): 2 filter_words = request.GET 3 search_connection = Q() 4 5 if filter_words: 6 search_connection.connector= 'or' 7 for field,value in filter_words.items(): 8 if field in self.list_filter: 9 search_connection.children.append((field,value)) 10 11 return search_connection
就是在第8行的判断,如果field是包含在list_filter里的就i执行索引,否则跳过。
admin组件中默认情况是不支持对多对多字段进行filter功能的,我们这里看看怎么可以实现多对多字段的filter。
可能在上面的动图里能看到,我们设置表格显示字段中定义了authors,而这个作者的字段在models里是按照多对多的关系设置的。所以在表格里是无法正常显示的。
这时候就需要我们队List_View类里的get_body修改一下了。先看看改过以后的代码
1 def get_data(self): 2 show_data_list = [] 3 4 #分页 5 page = int(self.request.GET.get('page',1)) 6 7 data_totle = self.data_list.count() 8 page_cut = Page_Cut(page=page, 9 url_prefix=self.conf_obj.get_list_url(), 10 param=self.request.GET, 11 data_totle=data_totle) 12 13 cut_html = page_cut.page_html 14 15 16 cut_data = self.data_list[page_cut.ID_start:page_cut.ID_end] 17 18 for model_obj in cut_data: 19 temp = [] 20 21 for field in self.conf_obj.get_display_field(): 22 if callable(field): 23 val = field(self.conf_obj,model_obj) 24 else: 25 from django.db.models.fields.related import ManyToManyField 26 get_field = self.conf_obj.model._meta.get_field(field) 27 if isinstance(get_field,ManyToManyField): 28 ret = getattr(model_obj,field).all() 29 t = [] 30 for i in ret: 31 t.append(str(i)) 32 val = ','.join(t) 33 else: 34 val = getattr(model_obj,field) 35 temp.append(val) 36 37 show_data_list.append(temp) 38 39 return show_data_list,cut_html
主要就是在嵌套的两层for循环中的第二个for循环改了以下,先回顾一下整个函数的思路,前面的一部分是用来实现分页功能的(16行以前),就不说了。这里着重介绍一下怎么处理manytomanyfield的对象
第一层for循环就是拿到我们list_display里的元素
这里要改一下注册的地方
1 class BookConf(ConfXadmin): 2 #原方法 3 # list_display = deepcopy(ConfXadmin.list_display) 4 # list_display.append('price') 5 # list_display.append('authors') 6 # list_display.append('publisher') 7 #修改以后的方法 8 list_display = ['price','publisher','authors']
当初在调试的时候这里卡了很久,因为原先打算的是在原ConfXadmin里的list_display继承一下,但是因为父类里的list_display里有个__str__方法,在后面的程序中会报错。就要通过赋值语句删掉这个元素了。
流程分析
list_display里面的元素除了在ConfXadmin里通过get_display_field函数添加的以外就是我们在注册时候声明的里,在这里我们就以publisher字段和authors字段为例来看下流程
publisher字段
第一层for循环先拿到了publisher,field='publisher',通过if判断,返现publisher不是可调用的,就走else,然后通过26行的语句拿到一个get_field,我们可以通过type()方法看一下这个get_field是个什么类
<class 'django.db.models.fields.related.ForeignKey'>
再通过下面isinstance判断这个get_field是不是一个多对多的键,明显不是,走了第33行的else,model_obj就是每一行对象,可以通过映射拿到的val就是model_obj对应的field字段的值,我们在第34行下面加上一个打印val的过程
print(field,val) ##########输出########## id 512 price 0 publisher 机械出版社 id 513 price 1 publisher 农业出版社 id 514 price 2 publisher 机械出版社
。
。
。
由于第一层的for循环里有十组model_obj,要打印的对象就比较多,所以这里就接了3组。最后添到列表temp里就行了。
authors字段
而authors字段就稍微复杂了,在进行isinstance判定他是不是manytomanyfield的时候就会走Ture的情况, 然后下面的方法
1 ret = getattr(model_obj,field).all() 2 t = [] 3 for i in ret: 4 t.append(str(i)) 5 val = ','.join(t)
注意ret的代码和前面第34行的val,其实就是多了个all(),那么就能拿到整个多对多字段里的querryset对象。然后用下面的for循环生成一个列表,我挑了两组ret和val打印了一下,看看他们的关系
ret <QuerySet [<Author: 小花>, <Author: 小黑>]>
val 小花,小黑
ret <QuerySet [<Author: 小黑>]>
val 小黑
ret <QuerySet [<Author: 小白>, <Author: 小花>, <Author: 小黑>]>
val 小白,小花,小黑
这样就可以放在前端的table里去渲染了,但是要注意点一点,我们这里写死了分隔符是逗号,就是在第5行里拼接字符串的时候。看看最后显示的效果

最后作者这一列就显示了实际的内容
BUG的处理
这里还存在一个小BUG,book表是我们做了一个自定义的配置类,但是其他的表呢?我们注册完了访问一下publisher
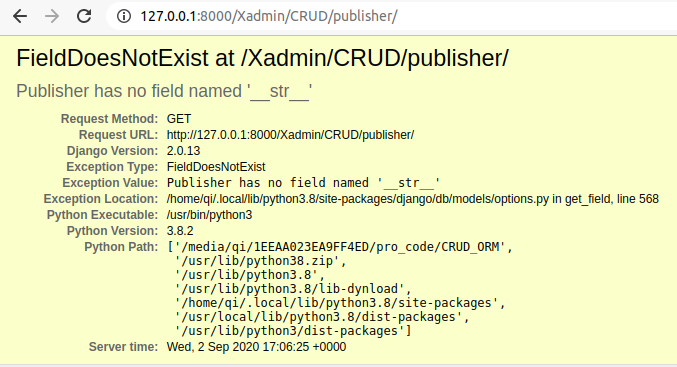
报错了,注意看错误提示,说Publisher表里没有一个叫__str__的字段,那是怎么回事呢?
首先要知道这个__str__是哪来的?没错,就是我们默认ConfXadmin类里定义的list_display列表,book表在自定义配置类的时候前面已经提出来了要改一下,直接赋值而不用追加的方式。如果列表里有__str__元素,在内部的for循环中第一个if判定他不是一个callable多对象,所以走了else的路径,但是在下面26行的代码中
get_field = self.conf_obj.model._meta.get_field(field)
field值就是__str__,而get_field是通过一个字符串拿到一个model点字段对象,显然没有字段名字是__str__,所以程序就报错了,解决方法月很简单,加一个try就行了,下面就把第二个for循环开始的代码放出来。保持了源程序的缩进,可以直接替换前面的那段代码中的for循环后面的代码
for field in self.conf_obj.get_display_field(): if callable(field): val = field(self.conf_obj,model_obj) else: try: from django.db.models.fields.related import ManyToManyField get_field = self.conf_obj.model._meta.get_field(field) if isinstance(get_field,ManyToManyField): ret = getattr(model_obj,field).all() print('ret',ret) t = [] for i in ret: t.append(str(i)) val = ','.join(t) print('val',val) else: val = getattr(model_obj,field) except Exception as e: val = getattr(model_obj,field) temp.append(val) show_data_list.append(temp) return show_data_list,cut_html
这样就解决了问题!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号