
MySQL学习笔记——〇四
今天我们继续对MySQL内容进行一些补充,但是今天所讲的内容已经不是平时常用的了。
先穿插一条指令贯穿了今天所讲的所有知识点:
结束符delimiter其实就是告诉mysql解释器,该段命令是否已经结束了,mysql是否可以执行了。默认情况下,delimiter是分号;。在命令行客户端中,如果有一行命令以分号结束,那么回车后,mysql将会执行该命令。
但是在今天的知识点中我们经常需要用到begin...end这种结构体,那么在结构体中的sql语句后的分号就不能作为结束符了,我们需要随便设置一个结束符,在结构体结束后再换回分号。
如果我们在日常进行数据库维护过程中需要一个重复的虚拟表,这个虚拟表的构建过程我们要敲很多次,MySQL给我们提供了一个对齐进行优化的方法_视图(View)。
视图的创建
比方我们今天需要对一个用户表中id>10的用户进行操作,这个操作要重复好多好多次,那么我们就要写好多次这样的代码
select *from (select * from table where id>10) as t;
这个时候,为了提高效率,我们就可以创建一个视图
create view v1 as select * from table where id>10;
这个时候我们只需要调用v1就可以了。
注意:视图是一个虚拟的表,是动态的。会随着被映射的表的变化而变化。但是物理表的内容不能通过视图来做增删改操作。
视图的查、删、改
视图是归于表管理的,创建的视图可以通过show tables;来显示。
视图的删除
drop view 视图名称;
视图的修改
视图的修改也是通过官架子alter来执行的。
alter view 视图名 as
sql语句
在执行某个sql语句的时候,可以用触发器来实现某段代码的执行,有些类似Python中的装饰器的效果。
触发行为有事件前触发(before)和时间后触发(after),能引发触发的行为有增(insert)删(delete)改(update),但是查询不可以。每次事件都会引发触发器。
静态触发
静态触发是触发器最基础的用法,也就是触发器里的sql语句是固定的。貌似正常的使用没有用过这种方法的。就用这种方法看看触发器的使用方式
比方我们有两个表

我们想实现在t1插入一条新数据的时候(插入之后)同时想t2插入一条数据
delimiter // create TRIGGER tg1_ti before insert on t1 for each row begin insert into t2(id,name) values('3','111'); end// delimiter ;
这里就用到了本章一开始讲的结束符的修改。在这段代码结束以后,每次想t1插入数据后,t2就会插入新的数据id=3name=111,(注意t2在建表的时候id列不要设成主键或者唯一了)。
动态触发
相比上面的静态触发,动态触发反而是我们用的相对多一些的方法(也是相对来说,其实触发器平时也不大常用。)
关键字
- NEW——新数据,新插入的数据,用于insert和update
- OLD——老数据,删除或更新前的数据,用于delete和update
还是上面那个例子,比方我们想要在t1插入数据后向t2内插入一个和t1相同的数据,就要这么做
delimiter // create TRIGGER tg1 before insert on t1 for each row begin insert into t2(id_b,name_b) values(NEW.id,NEW.name); end// delimiter ;
在上面的例子中我们就用NEW来表示新添加的数据。
触发器的删除
触发器的删除也是用的关键字drop
drop trigger 触发器名;
同常用的语言一样MySQL也是支持内置函数和自定义函数的使用
内置函数
先看看MySQL里有哪些常用的内置函数


CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5); -> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4); -> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6); -> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3); -> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3); -> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2); -> 'ki' TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(' bar '); -> 'bar' mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx'); -> 'barxxx' mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx'); -> 'bar' mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz'); -> 'barx' 部分内置函数
然后还可以点击官网查看(MySQL8.0版)
内置函数的调用
调用函数就用select+函数名的方式就可以,就像我们前面用的聚合函数一样
select sum()
时间格式化
内置函数里有个要强调一下的是时间格式化,以后会经常用到,先看看时间格式化的格式字符
Specifier Description %a Abbreviated weekday name (Sun..Sat) %b Abbreviated month name (Jan..Dec) %c Month, numeric (0..12) %D Day of the month with English suffix (0th, 1st, 2nd, 3rd, …) %d Day of the month, numeric (00..31) %e Day of the month, numeric (0..31) %f Microseconds (000000..999999) %H Hour (00..23) %h Hour (01..12) %I Hour (01..12) %i Minutes, numeric (00..59) %j Day of year (001..366) %k Hour (0..23) %l Hour (1..12) %M Month name (January..December) %m Month, numeric (00..12) %p AM or PM %r Time, 12-hour (hh:mm:ss followed by AM or PM) %S Seconds (00..59) %s Seconds (00..59) %T Time, 24-hour (hh:mm:ss) %U Week (00..53), where Sunday is the first day of the week; WEEK() mode 0 %u Week (00..53), where Monday is the first day of the week; WEEK() mode 1 %V Week (01..53), where Sunday is the first day of the week; WEEK() mode 2; used with %X %v Week (01..53), where Monday is the first day of the week; WEEK() mode 3; used with %x %W Weekday name (Sunday..Saturday) %w Day of the week (0=Sunday..6=Saturday) %X Year for the week where Sunday is the first day of the week, numeric, four digits; used with %V %x Year for the week, where Monday is the first day of the week, numeric, four digits; used with %v %Y Year, numeric, four digits %y Year, numeric (two digits) %% A literal % character %x x, for any “x” not listed above
就像博客园一样,博客园的页面上有个依据时间划分的随笔档案

我们每次写一个博客以后都会按照月份索引出来。我们简化一下博客的数据库模型
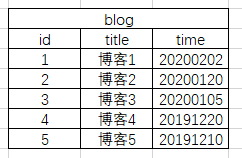
然后我们用下面的方法就能获取每个月份的博客数量
select DATE_FORMAT(time,'%Y-%m'),count(1) from blog group by DATE_FORMAT(time,'%Y-%m');
自定义函数
自定义函数的调用方法和内置函数是一样的。同样,使用前要先声明。
自定义函数的声明
MySQL里的自定义函数是强制类型的函数,也就是说函数的参数、输出的数据类型要在声明函数是确定好。声明的方法如下
delimiter // CREATE FUNCTION f1( i1 int, i2 int) RETURNS int BEGIN DECLARE num int; set num = i1+i2; RETURN num; END // delimiter ;
注意在声明返回值类型的时候,一定是returns,不是return,否则会报错,也就是说
用户定义函数中,用RETURNS 子句指定该函数返回值的数据类型,而return用来返回具体的值或变量。
还有一点,在自定义函数中不能有select *from这种的语句。
还有一点要注意:
- MySQL中如果加入函数会降低其性能,如果对性能要求高的话不建议使用函数。需要函数实现性能的话建议把函数放在程序级别或架构级别。
- 索引是用来提高速度的,如果对索引列使用了函数就丧失了索引的优势了。
这一章里最重要的可能也就是这个存储过程了。
什么事存储过程?
MySQL 5.0 版本开始支持存储过程。
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
存储过程的优缺点
优点
- 存储过程可以封装,并且隐藏复杂的商业逻辑
- 存储过程可以回传值,可以接受参数
- 存储过程无法用select来调用,因为他是个子程序,也查表或自定义函数不同
- 存储过程可以用在数据检验,强制实行商业逻辑等
缺点
- 存储过程,往往定制化于特定的数据库上,因为支持的编程语言不同,在切换到其他的数据库系统时需要重写原有的存储过程
- 存储过程的性能调教与撰写,首先与各种数据库系统
一般情况下,软件开发有下面几种模式
- dba写存储过程,程序员调用存储过程名称
- 常用模式:程序员员把sql语句写在代码中,dba利用MySQL的满日志记录查询效率低或耗时久的sql语句,提交开发修改。
- 程序员写类和对象,但是在程序级别还是转化成sql语句。dba不需要做什么了就。
存储过程的创建和调用
不带参数的存储过程
这种的是最简单的
delimiter // create PROCEDURE p1() begin select * from student; insert into teacher(tname) values(); end// delimiter ;
这种的是最简单的,直接定义就好了。然后可以通过call来调用
call p1();
带有参数的存储过程(无out参数)
delimiter // create procedure p2( in n1,int, in n2,int) begin select * from student where id>n1; end// delimiter ;
注意,我们在定义的时候声明了两个参数n1和n2,但是在使用结构体里只用了一个,那么调用的时候也要给n2传一个想用数据类型的参数.
call p2(10,1);
带有"返回值"的存储过程
注意到这里的返回值是加了引号的么?其实这里的返回值是不对的,存储过程是没有返回值的,这个返回值相当于把一个变量传递给存储过程然后把他的值改变。看看是怎么用的
delimiter // create procedure p2( in n1,int, out n2,int) begin set n2=123123 select * from student where id>n1; end// delimiter ;
在上面的代码中,n2就是个out的值,我们在调用这个过程时必须传递一个变量,然后通过这个存储过程给这个变量赋一个值(12313)。在调用这个过程以后
set @v=0; call p4(10,@v); select @v;
这样就可以拿到id>10的结果集和@v经过过程改变的值
也就是说:out就是传递了一个引用,所以在调用的时候一定要传递一个变量。
还有一点,参数除了in、out还有一个inout。
事务
我们在前面点到过事务操作,存储过程也可以支持事务性操作,特别是结合其他代码使用,因为存储过程没有返回值,我们的代码(非sql语句)在执行过程中并不知道sql语句执行结论是否成功。我们就可以结合存储过程的out特性来判定sql语句是否执行成功。
这里放一段代码,就是支持事务的存储过程的构建思路。
delimiter \\ create PROCEDURE p1( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; DELETE from tb1; insert into tb2(name)values('seven'); COMMIT; -- SUCCESS set p_return_code = 0; END\\ delimiter ; 支持事务的存储过程
游标
游标主要是实现了sql语句的循环操作
比方我们有个这样的操作

还是这样两个表,要把t1里的数据填到t2里,t2.name=t1.id+t1.name
这就类似一个循环的操作。
大概的架构是这样的
create procedure p() begin declare my_cursor declare 标志位 open my_cursor; x:LOOP 循环体 end loop x; close my_cursor end
有个很重要的一点,这个循环体里是不会自动跳出的。我们需要自己判定是否满足要求。看看上面那个要求的代码是怎么样的
delimiter // create procedure p6() begin declare row_id int; declare row_num int; declare done int default false; declare temp int; declare my_cursor CURSOR FOR select id,num from table1; declare CONTINUE HANDLER FOR NOT FOUND SET done=TRUE; open my_cursor; xxoo:LOOP fetch my_cursor into row_id,row_num; if done then leave xxoo; end if; set temp = row_id+ row_num; insert into table2 values(temp); end loop xxoo; close my_cursor; end // delimiter ;
动态执行SQL
我们还可以通过存储郭晨过来实现sql的动态执行,在执行的过程还可以进行sql语句合法性的判定,特别是可以用来sql的防止注入。
过程是这样的:
delimiter // create procedure p7( in tpl varchar(255), in arg,int) begin 1.预检测某个东西来判定sql语句的合法性 2.sql = 格式化tpl+arg 3.执行sql语句 set @xx = arg PREPARE prod FROM 'select * from student where sid >?'; prod为一个变量,随便起名字 EXECUTE prod useing @xx; DEALLOCATE prepare prod; end// delimiter ;
也就是做一个了解。不用特别记。
在Python文件中我们常常用pymsql库对MySQL进行访问,这里先强调一下如何在pymsql里拿到带out的存储过程的out值。
首先,pymsql里调用存储过程的方法:
cursor.callproc('p3',[a,b])
但是我们只能通过
cursor.fetchall()
来拿到结果集。
但是要想拿到out的结论要怎么做呢?
cursor.execute('select @_p3_0,@_p3_1')
select @_p3_0,@_p3_1是个固定的写法,表示了p3的第0个参数和第1个参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号