
MySQL中的索引
参考:https://www.cnblogs.com/whgk/p/6179612.html
一、概念
1、什么是索引
- 索引用于快速找出在某个列中有一特定值的行
- 不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多
- 如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间
例如:有一张person表,其中有2W条记录,记录着2W个人的信息。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息。
- 如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止。
- 如果有了索引,那么会将该Phone字段,通过一定的方法进行存储,好让查询该字段上的信息时,能够快速找到对应的数据,而不必在遍历2W条数据了。
其中MySQL中的索引的存储类型有两种:BTREE、HASH。 也就是用树或者Hash值来存储该字段
二、使用索引的优缺点
1、优点
- 所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引
- 大大加快数据的查询速度
2、缺点
- 创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
- 索引也需要占空间,我们知道数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
- 当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度
3、使用原则
并不是每个字段度设置索引就好,也不是索引越多越好,而是需要自己合理的使用。
- 对经常更新的表要避免对其进行过多的索引,对经常用于查询的字段应该创建索引
- 数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果
- 在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可是建立索引
三、索引的分类
注意:索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
- MyISAM和InnoDB存储引擎:只支持BTREE索引, 也就是说默认使用BTREE,不能够更换
- MEMORY/HEAP存储引擎:支持HASH和BTREE索引
1、索引我们分为四类:单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引、
(1)单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引
- 普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值
- 主键索引:是一种特殊的唯一索引,不允许有空值
(2)组合索引:
在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合
(3)全文索引:全文索引,只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引
什么是全文索引:就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行,比如有"你是个大煞笔,二货 ..." 通过大煞笔,可能就可以找到该条记录。这里说的是可能,因为全文索引的使用涉及了很多细节
(4)空间索引:空间索引是对空间数据类型的字段建立的索引
MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。
在创建空间索引时,使用SPATIAL关键字。
要求:引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL
四、索引的操作(创建)
创建表的时候创建索引:格式:CREATE TABLE 表名[字段名 数据类型] [UNIQUE|FULLTEXT|SPATIAL|...] [INDEX|KEY] [索引名字] (字段名[length]) [ASC|DESC]
创建单列索引
1、创建普通索引
mysql> create table book( -> bookid int not null, -> bookname varchar(255) not null, -> authors varchar(255) not null, -> info varchar(255) null, -> comment varchar(255) null, -> year_publication year not null, -> index(year_publication) -> );
mysql> create table book2( -> bookid int not null, -> bookname varchar(255) not null, -> authors varchar(255) not null, -> info varchar(255) null, -> comment varchar(255) null, -> year_publication year not null, -> key(year_publication) -> );
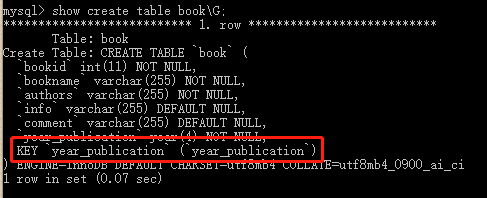
我们在创建索引时没写索引名的话,会自动帮我们用字段名当作索引名
测试:看是否使用了索引进行查询
mysql> explain select * from book2 where year_publication = 1990\G;

2、创建唯一索引
mysql> create table t1( -> id int not null, -> name char(30) not null, -> unique index uniqidx(id) -> ); Query OK, 0 rows affected (0.54 sec)
解释:对id字段使用了索引,并且索引名字为UniqIdx

要查看其中查询时使用的索引,必须先往表中插入数据,然后在查询数据,不然查找一个没有的id值,是不会使用索引的
insert into t1 values(1,"xxx");
mysql> explain select * from t1 where id=1\G;
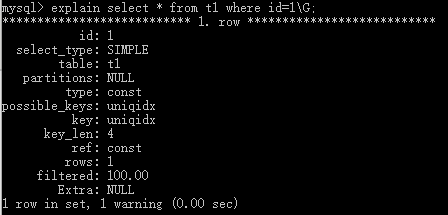
3、创建主键索引
mysql> create table t2( -> id int not null, -> name char(10), -> primary key(id) -> );
insert into t2 values(1,"QQQ");
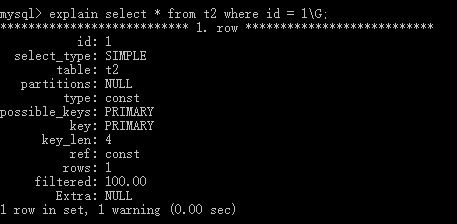
以前声明的主键约束,就是一个主键索引
创建组合索引
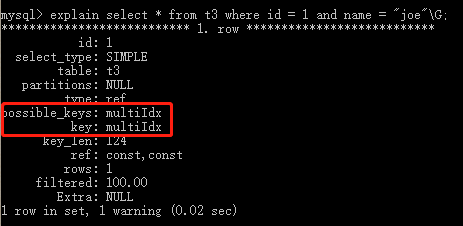
mysql> create table t3( -> id int not null, -> name char(30) not null, -> age int not null, -> info varchar(255), -> index multiIdx(id,name,age) -> );
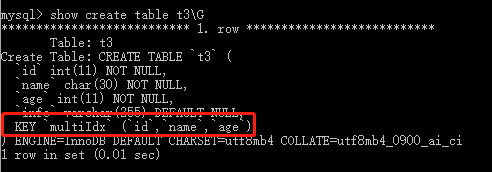
组合索引就是遵从了最左前缀,利用索引中最左边的列集来匹配行,这样的列集称为最左前缀
例如,这里由id、name和age3个字段构成的索引,索引行中就按id/name/age的顺序存放,索引可以索引下面字段组合(id,name,age)、(id,name)或者(id)。
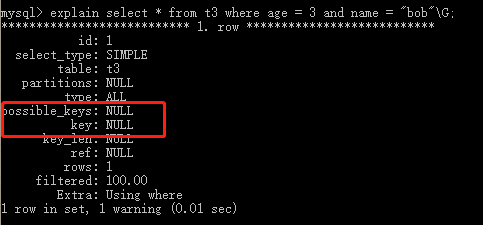
如果要查询的字段不构成索引最左面的前缀,那么就不会是用索引,比如,age或者(name,age)组合就不会使用索引查询
查询(age,name)字段,这样就不会使用索引查询
在已创建的表上添加索引
- ALTER TABLE 表名 ADD[UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [索引名] (索引字段名)[ASC|DESC]
为表添加索引
- ALTER TABLE book ADD INDEX BkNameIdx(bookname(30));
使用CREATE INDEX创建索引
- CREATE INDEX BkBookNameIdx ON book(bookname);
五、索引操作(删除)
格式一:ALTER TABLE 表名 DROP INDEX 索引名
格式二:DROP INDEX 索引名 ON 表名;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号