
ZooKeeper必知
Java后端知识点汇总——Zookeeper专题
全套Java知识点汇总目录,见https://www.cnblogs.com/ying-dong/p/11831922.html
——参考于码农求职小助手公众号
1, 请简述ZooKeeper的选举机制
Zookeeper选举(Paxos算法)
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,如图
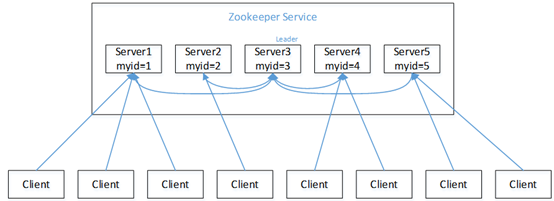
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
(注 : 新启动一个Server时,第一票的投票规律:判断一启动集群中有无比自身myid大的Server,如果有,则第一票投给最大myid的Server,否则投给自己)
⬇
所以➡集群模式的Zookeeper开启时按照myid从大到小开启,会节省选举时间,从而响应速度加快➡因为由大到小第一次投票都投给最大myid的Server,第一轮就可以决定Leader
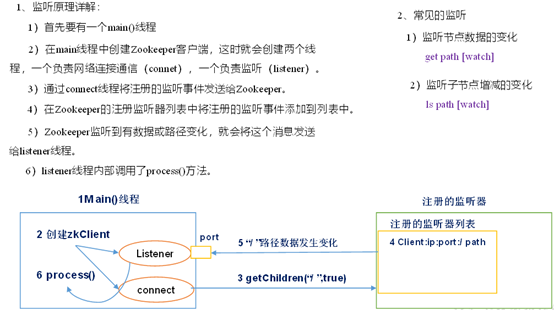
2, ZooKeeper的监听原理是什么?
3, ZooKeeper的部署方式有哪几种?集群中的角色有哪些?集群最少需要几台机器?
(1)部署方式单机模式、集群模式
(2)角色:Leader和Follower
(3)集群最少需要机器数:3
4, ZooKeeper的常用命令
ls create get rmr delete set…
5,以CAP理论分析ZooKeeper
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种
- 一致性(C:Consistency)
- 可用性(A:Available)
- 分区容错性(P:Partition Tolerance)

这三个基本需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。
在ZooKeeper保证的是CP
分析:可用性(A:Available)
不能保证每次服务请求的可用性。任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
进行leader选举时集群都是不可用。在使用ZooKeeper获取服务列表时,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。所以说,ZooKeeper不能保证服务可用性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号