Error: java.io.IOException: Spill failed,Error: java.lang.NullPointerException以及hadoop输出结果为空的可能性。
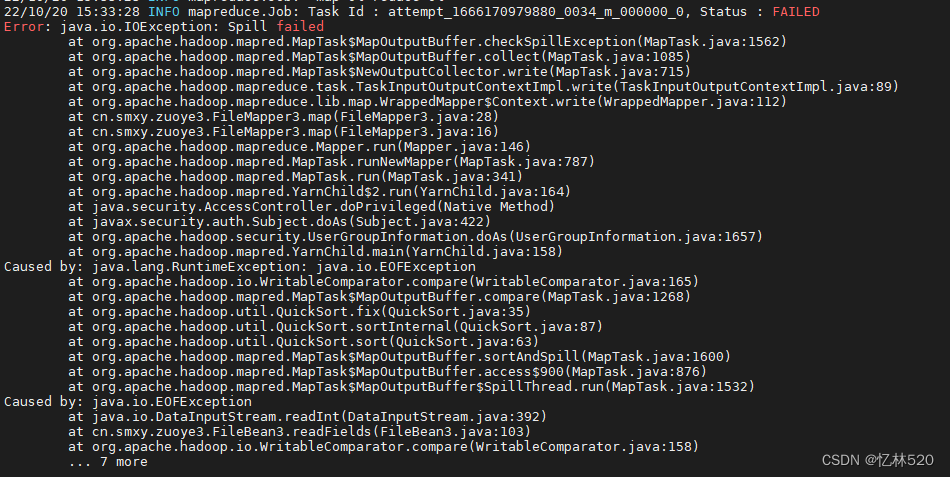
首先先说第一种:Error: java.io.IOException: Spill failed
一般出现这种错误你都可以去看看你的自定义bean类的序列化方法对应是不是写错了,一般来说都是这个问题虽然他看上去很想一个字符串切分的错误。实际上不是,为此我也查了很久。
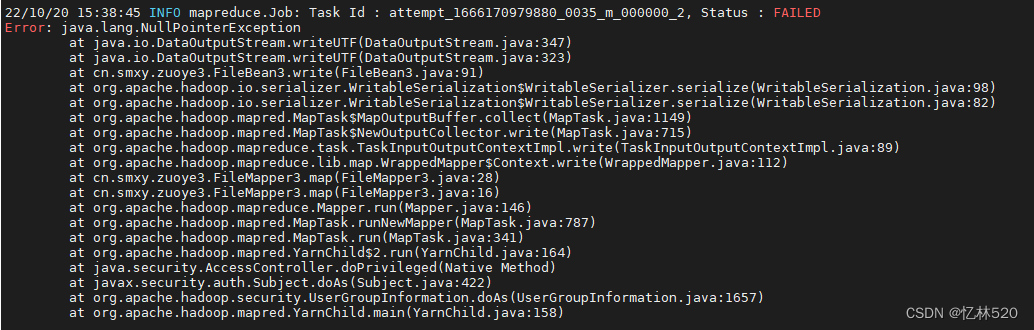
第二个就是这个Error: java.lang.NullPointerException
一般来说报这个错误:我这边做一个猜想:应该是你的bean类在传输到reduce的时候出现了一个报错(空指针异常),应该是序列化的时候,因为是顺序读值得有一个为null得话,他读值得时候就会出毛病。(个人观点!!!)
上面说了我的观点,现在说解决办法,刚刚已经说了是传值的时候出现的问题,那么这个时候你就需要去找这个bean类在map阶段是不是少赋值了,导致里面的一部分数据为空了。
最后我说一下那个hadoop有可能出现的输出为空的错误,可能你的代码在什么地方都是对的,但是传值过去就是空,那这个时候你应该去看看你的bean 类的序列化方法有没有全部实现,也就是说你的全部值有没有都传到reduce 的阶段,如果到了reduce阶段这个时候有值是空的时候,你就应该考虑这个问题了。
我说的序列化方法是这个:
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeUTF(produceid);
dataOutput.writeUTF(categoryid);
dataOutput.writeInt(pronum);
dataOutput.writeInt(catenum);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.name = dataInput.readUTF();
this.produceid = dataInput.readUTF();
this.categoryid = dataInput.readUTF();
this.pronum = dataInput.readInt();
this.catenum = dataInput.readInt();
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号