
rk3588桌面系统qt的qwidget在x11对接opengles 渲染的多路播放器22路测试
播放效果
https://www.bilibili.com/video/BV1eYbdzuE7b/
1080p@30 码率2554kbps
注意 这是远程桌面 会比实际接屏幕效果差一些
性能
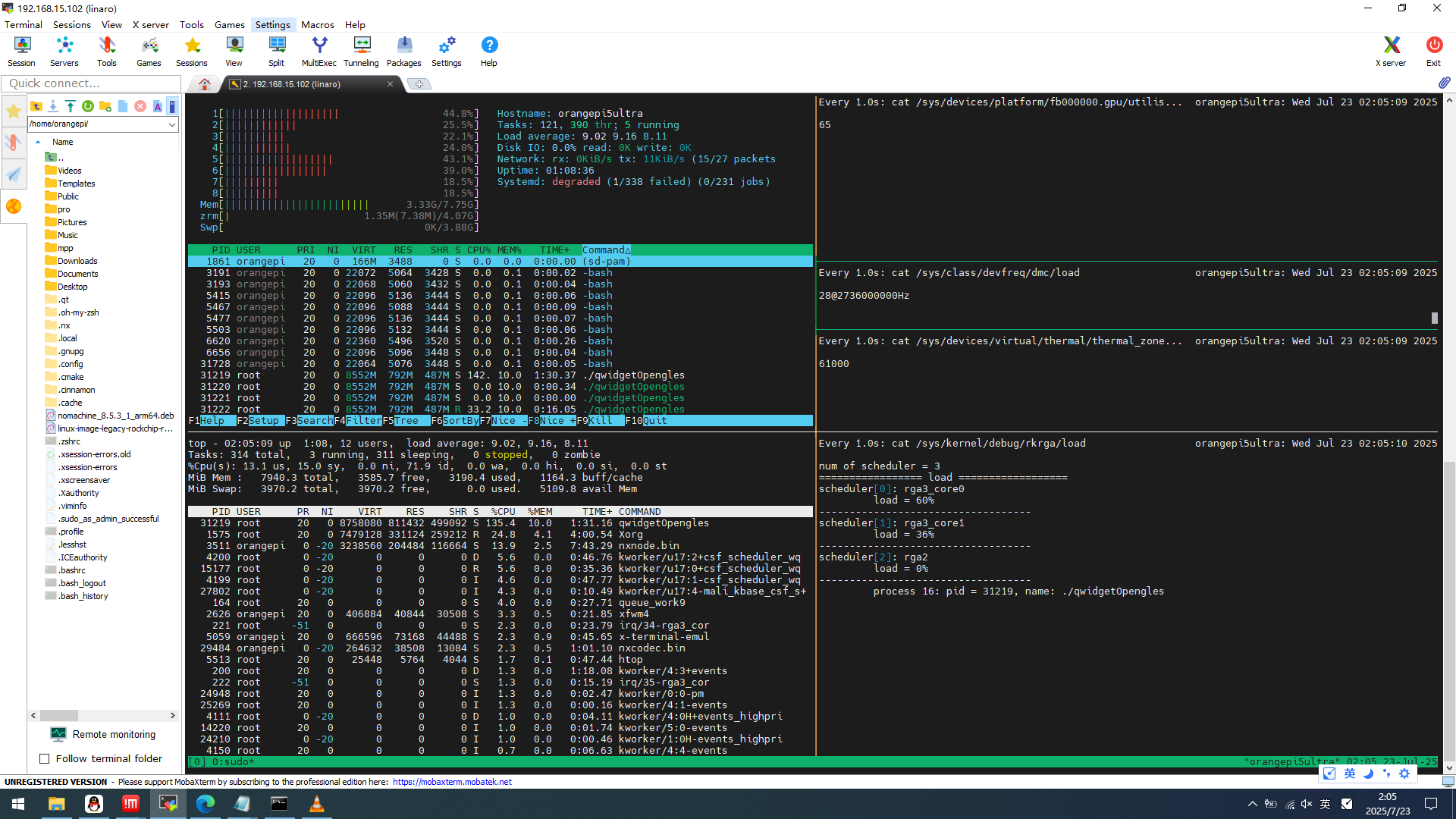
cpu 142%(满载800%)
mem 42% 3.33GB (用户空间才占792MB 但是内核空间可能已经占了几G)
rga rga3_core0:60% rga3_core1:36% rga2:0%
gpu 65%
ddr 带宽占用率28
温度 61度
平台
主控 rk3588
板卡 香橙派5 ultra
系统 ubuntu桌面kernel 5.10
实现方案
- ffmpeg 拉流 rtsp 获得 h265,为了传输稳定配置 rtsp over tcp
- mpp 解码 h265 获得 nv12,注意解码器会有帧长度对齐
- rga 转换 nv12 成 rgb
- gpu 渲染 rgb,用 opengles 对接的 qwidget,把 dmabuf 对接到 EGLImage 上传 2d 纹理
特点
做 qt 界面的经常希望把硬件加速的视频播放器集成到 qwidget,这样方便用 qt 统一处理各控件的布局、样式、事件等。
注意事项
在实现过程中,需要注意配置问题和性能问题:
配置问题
qt 在 x11 上会默认使用 GLX 而不用 opengles,这时就需要配置成使用 opengles,有两种方法:
- 第一种:使用系统环境变量
export QT_OPENGL=es2
export QT_XCB_GL_INTEGRATION=xcb_egl
- 第二种:在 pro 和代码配置
- 在 pro 中增加DEFINES += QT_OPENGL_ES_2
- 在代码开始里写上qputenv("QT_XCB_GL_INTEGRATION", "xcb_egl");
在配置完使用 opengles 后,还需要在创建窗口前用代码配置 Surface Format:
QSurfaceFormat format;
format.setRenderableType(QSurfaceFormat::OpenGLES);
format.setVersion(2, 0); // 或 3.0
format.setSwapBehavior(QSurfaceFormat::DoubleBuffer);
format.setOptions(QSurfaceFormat::DebugContext); // 调试用
QSurfaceFormat::setDefaultFormat(format); // 全局生效
性能问题
在 opengl 中渲染 2d 纹理时,有多种方式可以上传纹理数据到 gpu:
- glTexImage2D/glTexSubImage2D
这是最简单的方式,一般 AI 写代码会提供这种,但性能非常低。在底层会造成至少两次数据拷贝,一次拷贝到窗口服务器,一次拷贝到 gpu 驱动,对 cpu、内存耗时都不理想,适合进行简单的着色器和纹理连接的测试。
- glTexImage2D/glTexSubImage2D + PBO 双缓冲
基于第一种做了优化,增加一个缓冲空间,根据乒乓缓冲原理,把原本拷贝 + 渲染串行做成异步并行,减少了渲染耗时。测试发现在上传纹理时减少耗时明显,下载纹理时几乎没提升。这种方式通过空间换时间增加渲染效率,但 cpu 占用没有改善,适合在第三种不能用时使用。
- EGLImage
这是零拷贝的方式,在底层不会产生拷贝,通过使用共享内存块来避免拷贝。在 linux 下一般是 dmabuf,在 android 下是 graphicsbuffer 或者 ahardwarebuffer。这些共享内存块有 fd 接口,可以搭配 rk 的 rga 做图像处理的接口使用,十分高效。这种方式性能最高,但对平台有要求:linux 下要检查 opengles 是否支持 eglImage 的 dmabuf 扩展;android 下 graphicsbuffer 和 ahardwarebuffer 对 ndk 版本有不同的要求。
注意:EGLImage 对宽高都要求 64 位对齐。
图像读取时机
将图像传给 opengles 对接的 qwidget 时,传递图像一般会用一个图像队列,读队列的图像进行渲染。读取时机一般有两种:
- 触发读取:在图像入列时发送一个信号给 qwidget 执行 update,然后再读取图像出列渲染。
- 定时器轮询读取:直接用定时器每隔一段时间读取图像队列,执行 update 然后再读取图像出列渲染。
一般容易想到为了 cpu 高效选择触发的方式,但容易忽略的是这种方式会造成有时多次 update 被合并成一次刷新执行,每次执行只出一帧,导致偶尔会有几帧在队列里出不来而掉帧,所以建议使用轮询的方式。
多路播放优化
qt 通过 opengles 对接到 qwidget 做多路播放器时,需要注意 qwidget 的底层放缩、拼接、层叠会产生额外的 gpu 性能开销。每路视频单独播放在一个 widget 里非常耗 gpu 资源,在 rk3588 中能做到 22 路 1080p@30;但如果用 rga 完成对每路视频放缩拼接再传入 qwidget 里,能做到 32 路,当然这样做会失去对单独每路视频用 qt 统一管理布局的灵活性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号