
opengles渲染方式glTextImage和eglImage性能对比
在rk系列芯片处理视频中 图像采集、编解码、图像处理和推理等都可以获取到图像的内存块的文件描述符fd处理图像从而实现零拷贝和避免虚拟地址以减少cpu的占用 但是gpu渲染容易被忽略也有这种方式特别是拷打ai的时候只会给你用glTexImage2D的方式
在一些推理的应用中有人会用opencv对接opencl来调用gpu加速一些图像处理 发现很慢后说是处理图像时要把图像从系统内存上传到gpu内存很慢导致的 实际上移动平台的gpu没有独立的显存 就像pc的集成显卡用的是系统内存 而不是独显的专有内存 实际上是底层会有内存拷贝造成的
为了减少内存拷贝 opengles扩展了零拷贝接口 在linux下eglImage+dmabuf可以通过传递fd来避免拷贝 在android下是eglImage+graphicsbuffer(用native windows申请的)或者eglImage+hardwarebuffer
下面对glTexImage2D+PBO和eglImage+dmabuf渲染进行性能测试
平台香橙派rk3588 ubuntu
测试场景
rtsp拉流 mpp解码 rga裁剪 rga图像格式转换 opengles渲染
测试数据
eglImage+dmabuf
系统cpu 193(满载800)
程序cpu 12.5
系统mem 2.04GB
程序mem 137MB
GPU 22
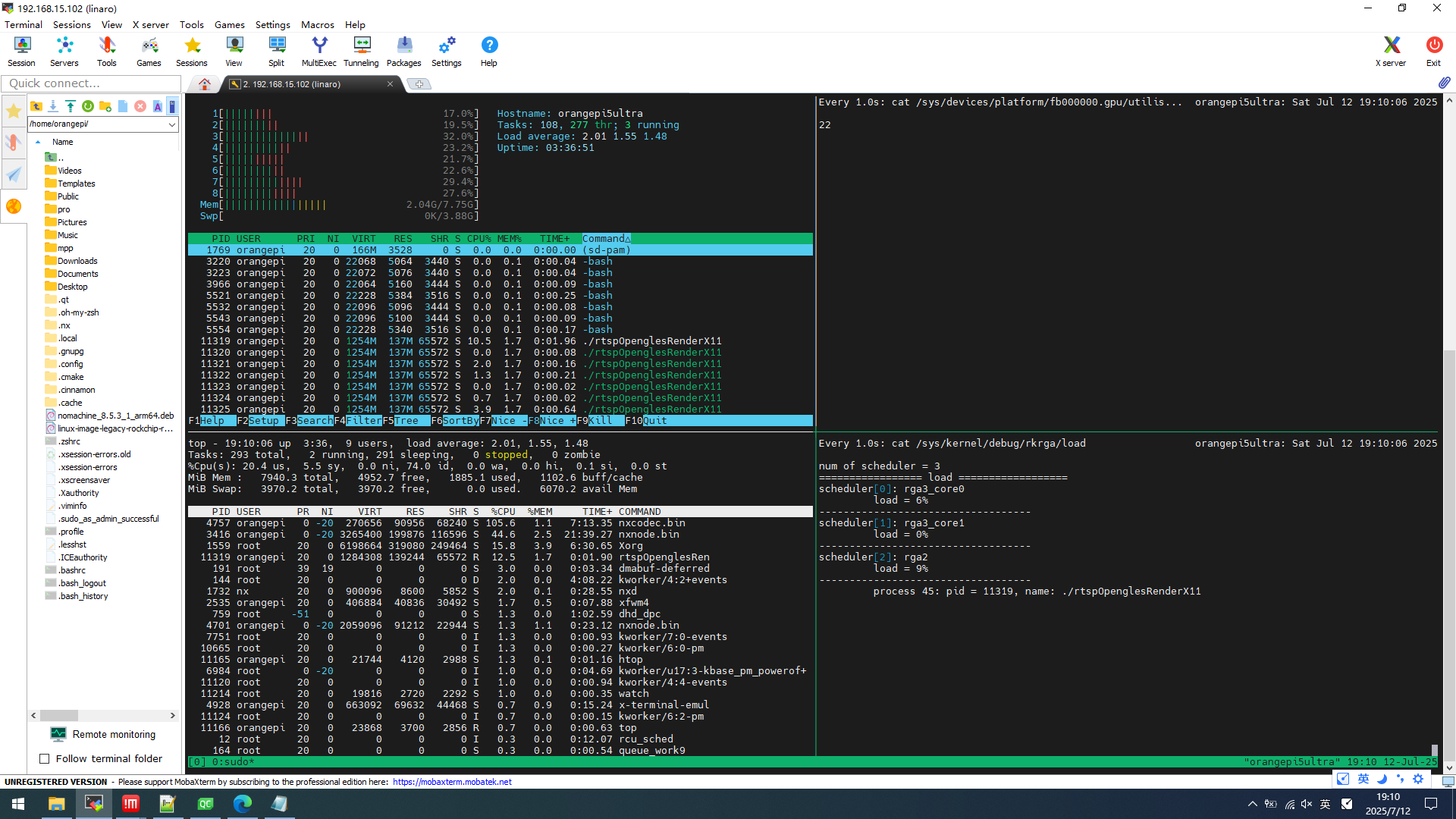
程序耗时统计log单位ms
gl cost 5 100 829 tCostCvt 1 100 379
其中gl cost是图像格式转换nv12转rga的时间+纹理上传+渲染的时间
tCostCvt 是图像格式转换nv12转rga的时间
100后面的数字是累积100帧的时间
glTexImage2D+pbo
系统cpu 265.3(满载800)
程序cpu 36.8
系统mem 2.11GB
程序mem 175MB
GPU 25
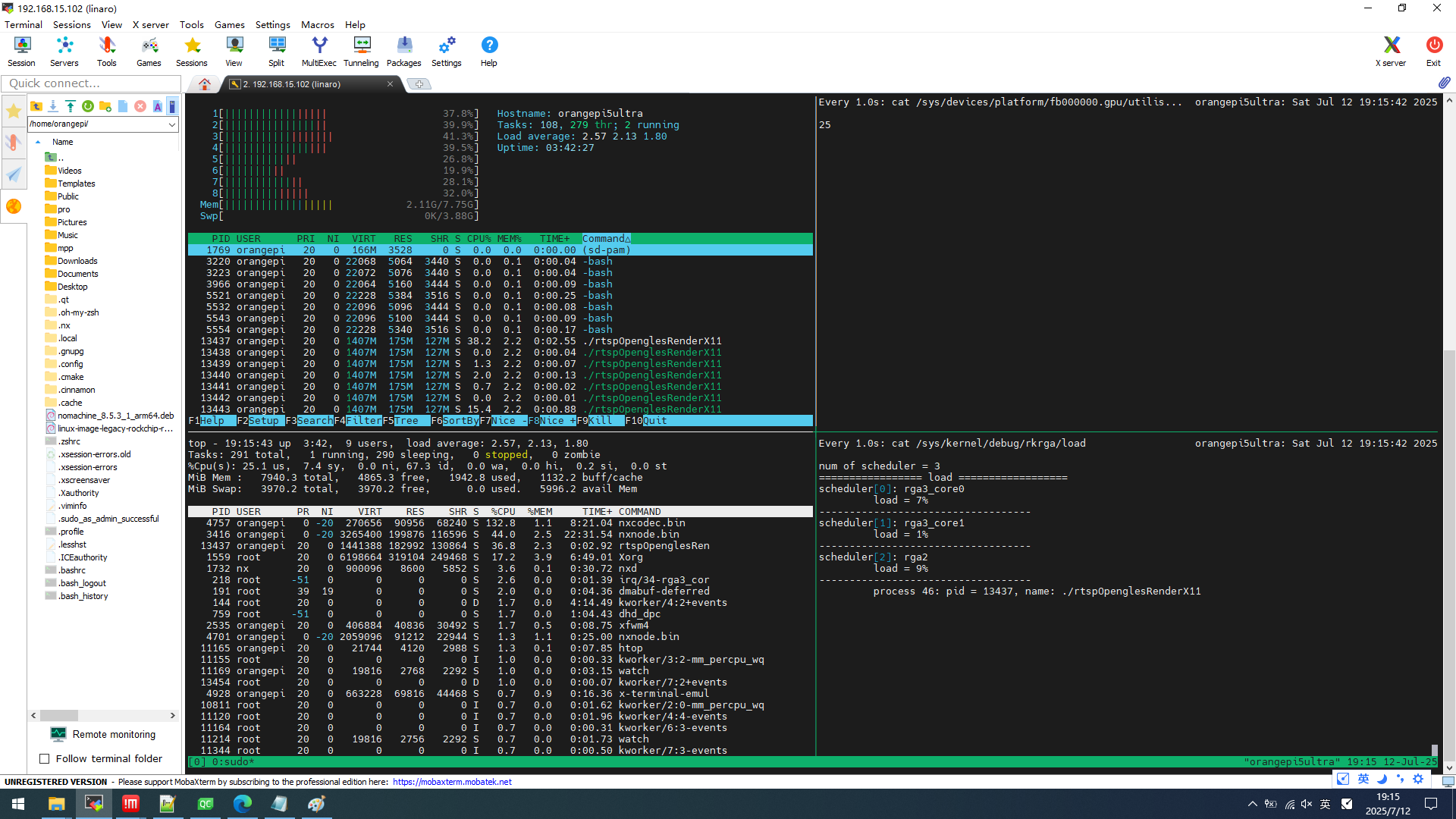
gl cost 17 100 1572 tCostCvt 5 100 685
下面用ai总结
一、核心结论
基于 RGA 图像格式转换(NV12→RGA) + 纹理渲染 场景测试,eglImage + dmabuf 方案在耗时、资源占用上全面优于 glTexImage2D + pbo ,更适合对性能敏感的音视频渲染场景。
二、数据对比表格
|
维度 |
指标 |
eglImage + dmabuf |
glTexImage2D + pbo |
差异分析 |
|
耗时(100 帧,ms) |
tCostCvt(格式转换) |
累计 379,单帧平均 3.79 |
累计 685,单帧平均 6.85 |
dmabuf 基于 fd 零拷贝,减少内存操作耗时 |
|
|
gl cost(全流程) |
累计 829,单帧平均 8.29 |
累计 1572,单帧平均 15.72 |
全流程含格式转换 + 纹理上传 + 渲染,dmabuf 优势显著 |
|
资源占用 |
系统 CPU(满载 800) |
193 |
265.3 |
pbo 虚拟地址操作依赖更多 CPU 调度,开销更高 |
|
|
程序 CPU |
12.5 |
36.8 |
dmabuf 流程更高效,程序自身 CPU 消耗更低 |
|
|
系统内存 |
2.04GB |
2.11GB |
pbo 虚拟地址传递增加内存管理开销 |
|
|
程序内存 |
137MB |
175MB |
dmabuf 零拷贝减少内存占用 |
|
|
GPU 负载 |
22 |
25 |
pbo 纹理上传、渲染更依赖 GPU,负载略高 |
三、关键逻辑解读
耗时差异根源:
- eglImage + dmabuf用 fd 传递图像,实现 “零拷贝” ,跳过虚拟地址到物理地址的映射开销,格式转换(tCostCvt)和全流程(gl cost)耗时大幅降低。
- glTexImage2D + pbo用 虚拟地址传递,需 CPU 参与内存拷贝、地址转换,额外增加耗时与资源占用。
资源占用连锁反应:
- pbo方案因内存操作复杂,CPU 调度压力大(系统 + 程序 CPU 均更高),内存管理开销导致系统 / 程序内存占用上升;
- dmabuf方案通过硬件级数据共享,降低 CPU 参与度,资源占用更优。
场景适配建议:
- 优先选eglImage + dmabuf:对性能敏感的低延迟场景(如实时视频渲染、高帧率图像处理),可减少卡顿、降低功耗。
- glTexImage2D + pbo备用:若场景对兼容性要求高(如旧版 GPU 不支持 dmabuf),或处理简单低帧率任务,可权衡使用,但需接受更高资源开销。
通过数据对比,eglImage + dmabuf 凭借零拷贝机制,在耗时和资源效率上优势明显,是高性能音视频渲染场景的更优解 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号