
香橙派rk3588的16路1080p实时目标检测rknn多线程推理
演示视频
https://www.bilibili.com/video/BV1vTMmzaErC
一、系统架构与功能流程
核心流程:RTSP 拉流→解码→预处理→多线程推理→后处理→画面拼接→编码→RTSP 推流
拉流与解码
- 用 FFmpeg 实现 RTSP 拉流,配置 RTSP over TCP 保证传输稳定,解封装 H.264。
- 基于 MPP 例程解码 H.264,输出 NV12 格式图像。
预处理
- 采用 RGA 替代 OpenCV 以减少 CPU 占用,实现 Letterbox 处理(等比放缩、黑边填充、图像居中),需处理位移填充和坐标计算。
- 注意事项:限定 RGA3 核、使用专用内存分配器,避免 4G 内存报错、图像抖动等问题。
多线程推理
- 为 3 个 NPU 核心各分配 1 个线程,线程轮流输入不同图像至 NPU 推理。
- 直接使用例程中的 YOLOv5s 模型,未做优化以对比部署性能。
后处理与画面拼接
- 后处理:CPU 实现 NMS 过滤与画框,直接在 NV12 图像上操作(避免 NV12→RGB→NV12 转换),实测 CPU 画框(3.39ms / 帧)比 RGA(7.8ms / 帧)更高效,使用bytetrack跟踪目标,根据跟踪id决定画框颜色。
- 拼接:使用 RGA2(需 4G 内存分配器)将 16 路视频图像放缩后拼接,因 RGA3 核已高负载。
编码与推流
- 基于 MPP 例程将 NV12 编码为 H.264,通过开源项目 rtsp_demo 封装为 RTSP 流服务。
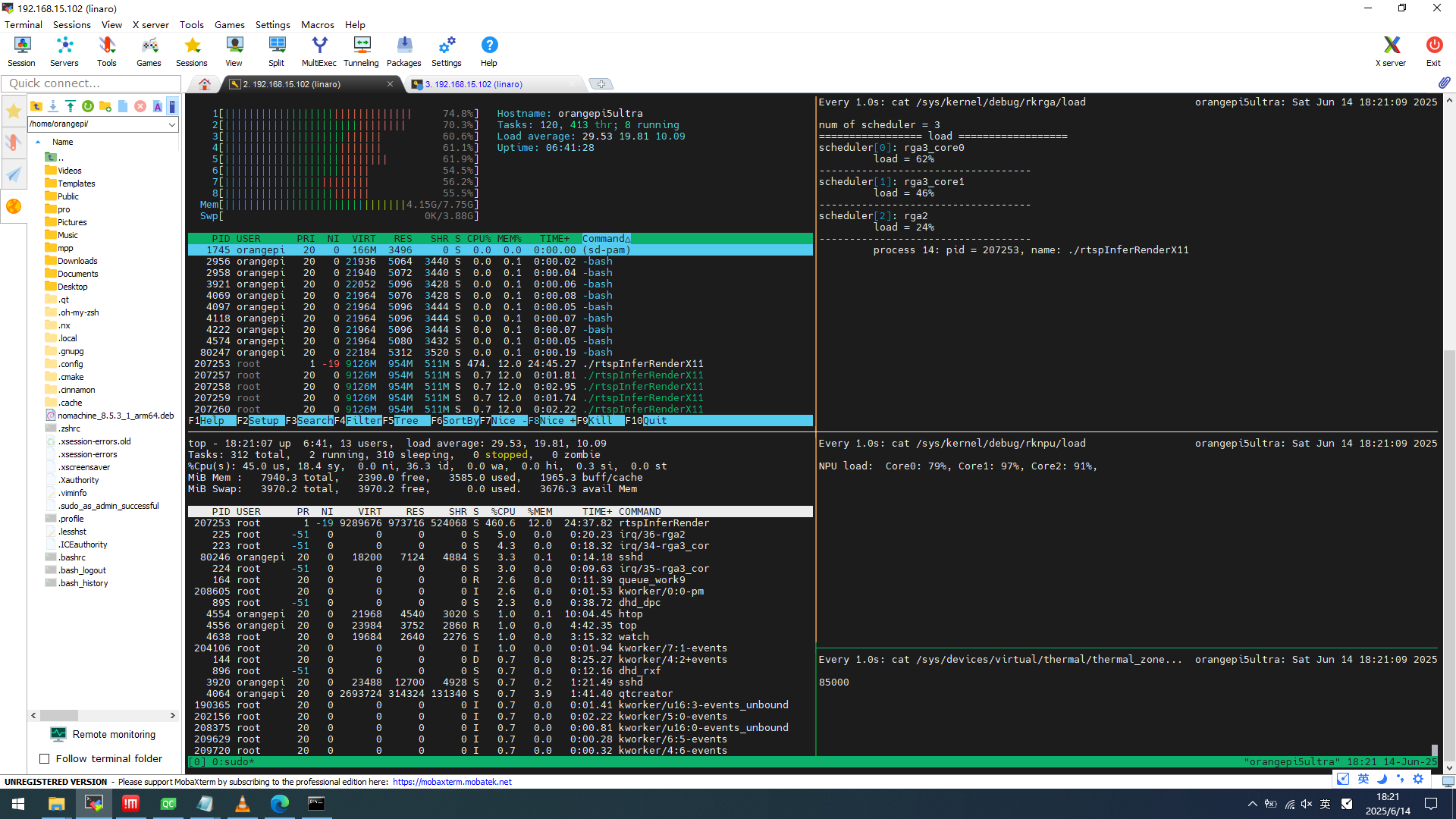
二、测试数据与资源占用
|
指标 |
详情 |
|
输入视频 |
1080P@25fps,码率 2918kbps(B 站视频,PC 推流给RK3588拉流) |
|
CPU 占用 |
应用程序 127%(满载 800%),系统总占用 494.9%(8 核合计) |
|
内存占用 |
应用程序 954MB(占 12%),系统总内存 4.15GB/7.75GB |
|
NPU 占用 |
Core0:79%,Core1:97%,Core2:91% |
|
RGA 占用 |
RGA3_core0:62%,RGA3_core1:46%,RGA2:24% |
|
温度 |
85℃ |
三、关键优化点与结论
性能优化策略
- 预处理与后处理:RGA 替代 OpenCV 降低 CPU 负载,CPU 直接在 NV12 图像画框减少数据转换耗时。
- 多线程与资源分配:NPU 核独立线程并行推理,RGA2/RGA3 分核处理避免资源竞争。
- 内存管理:通过限定 RGA 核数、专用内存分配器解决 4G 内存报错问题。
实测结论
- 成功实现 16路 1080P 视频的端到端实时处理,系统资源占用处于合理范围(CPU 未满载,NPU 接近饱和)。
- 温度 85℃需注意散热优化,避免长期高负载下性能衰减。
后续改进方向
- 探索模型量化或剪枝以降低 NPU 负载,进一步提升帧率。
- 优化 RGA2 内存分配策略,减少拼接耗时。
四、技术要点总结
- RTSP 链路:FFmpeg+rtsp_demo 实现稳定的拉流与推流,TCP 传输保证可靠性。
- 异构计算:NPU 负责推理,RGA 处理图像预处理 / 拼接,CPU 处理后处理,实现资源高效分配。
- 工程实践:RGA 和内存分配器的正确使用是避免性能问题的关键,需参考官方文档配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号