
rknn上下文复用性能测试
文档02_Rockchip_RKNPU_User_Guide_RKNN_SDK_V2.0.0beta0_CN.pdf中9.4 多线程复用上下文 提到多线程时通过复用上下文来减少内存占用的方法
在多线程场景中,一个模型可能会被多个线程同时执行,如果每个线程都单独初始化
一个上下文,那么内存消耗会很大,因此可以考虑共享一个上下文,避免数据结构重复构
造,减少运行时内存占用。RKNN API 提供了复用上下文的接口,接口定义如下:
int rknn_dup_context(rknn_context* context_in,rknn_context*
context_out)
其中,context_in 是已初始化的上下文,而 context_out 是复用 context_in 的上下文。两个 context 的模型结构相同,因此可以复用上下文。
在rk3588中 有3个npu核心 为了提高推理帧率 一般会一个模型多个线程同时推理 这时就可以复用上下文减少运行时内存占用
场景假设 输入视频 1080P@30 4路逐帧检测
4路视频 每路视频都用不同的模型 每路检测都用3个rknn上下文 然后两个rknn上下文复用一个 即第一个rknn上下文正常初始化 第二第三个复用第一个 理论上节省原本的2/3内存
4路视频 每路视频都用相同的模型 每路检测都用3个rknn上下文 然后所有rknn上下文都复用第一个 即第一路视频的第一个rknn上下文正常初始化 第一路视频的第二第三个rknn和其他三路视频的所有rknn都复用第一路视频的第一个rknn上下文 理论上节省原本的11/12内存
测试数据
无复用
系统内存 2.12GB
应用内存 368MB

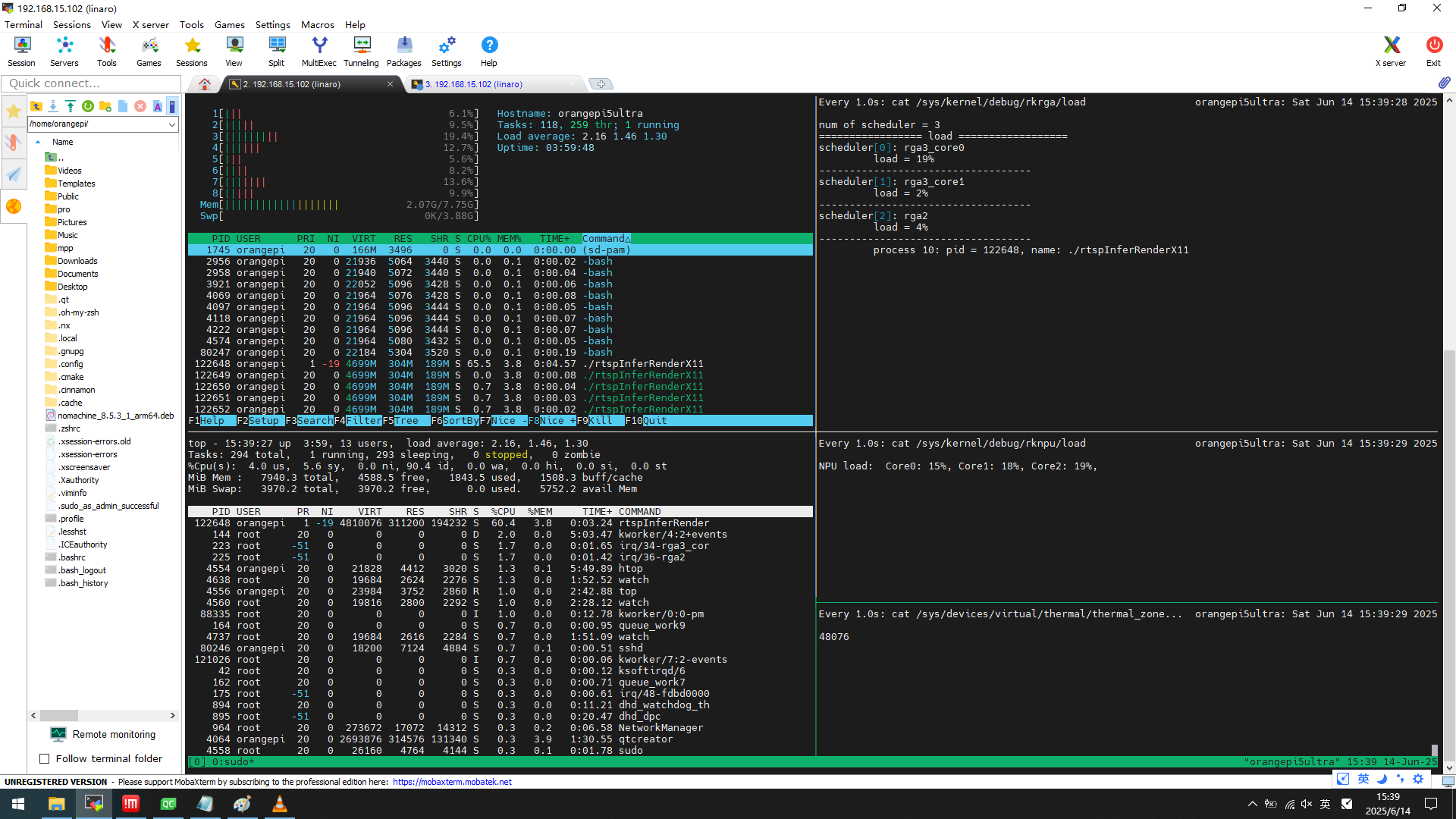
每三路中两路复用一路
系统内存 2.07GB
应用内存 304MB
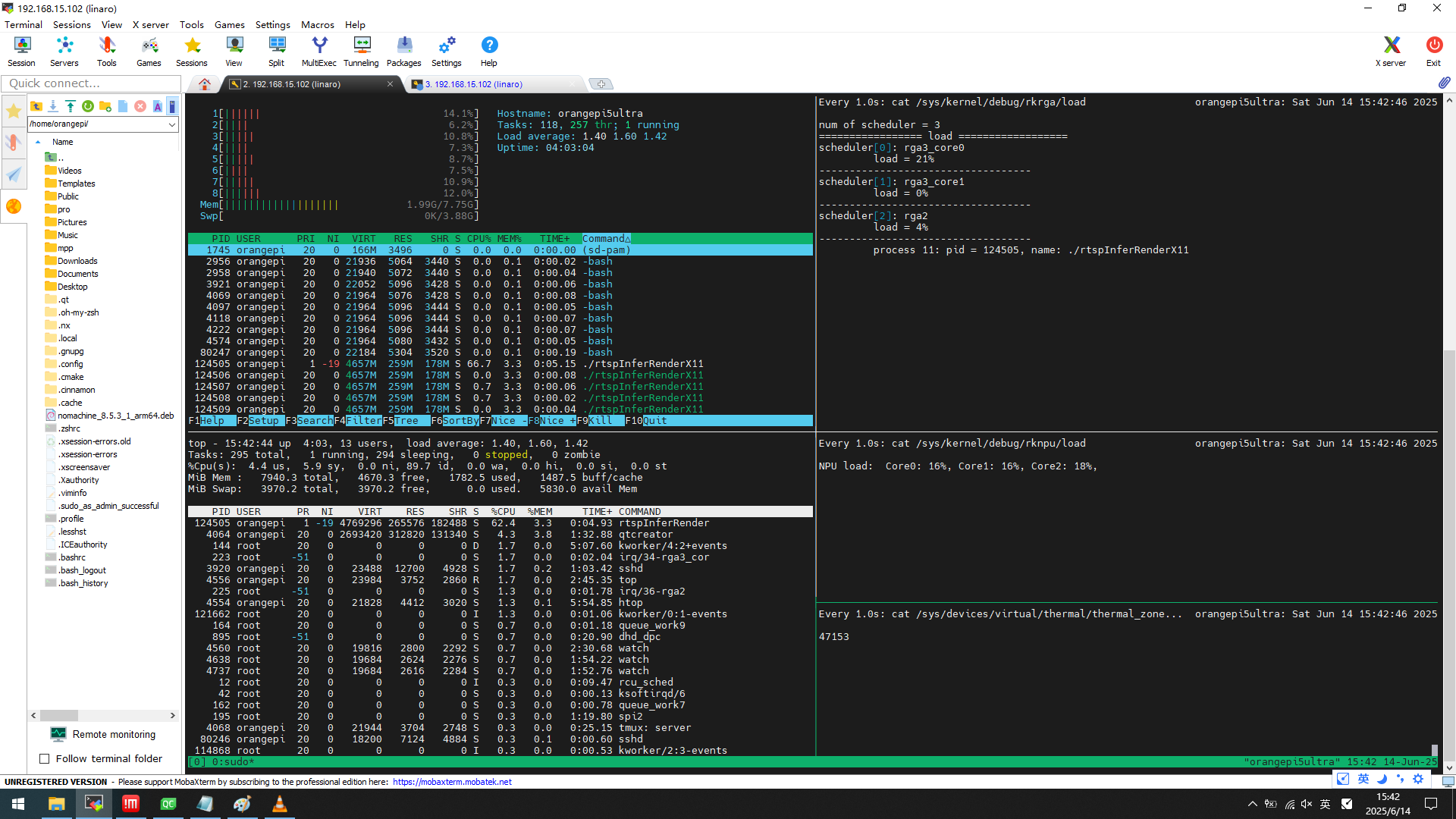
所有复用一路
系统内存 1.99GB
应用内存 259MB
下面是用AI对数据总结
一、测试背景与目标
- 场景需求:在 RK3588 芯片(3 个 NPU 核心)上进行多线程推理,输入 4 路 1080P@30fps 视频逐帧检测,通过复用 RKNPU 上下文减少内存占用,提升推理效率。
- 核心原理:多线程场景下,共享已初始化的 RKNPU 上下文(通过rknn_dup_context接口),避免重复构造模型数据结构,从而降低内存消耗。
二、测试场景与数据对比
|
测试场景 |
系统内存占用 |
应用内存占用 |
内存节省比例 |
|
无复用 |
2.12GB |
368MB |
- |
|
每三路中两路复用一路 |
2.07GB |
304MB |
应用内存节省约 17.4% |
|
所有上下文复用一路 |
1.99GB |
259MB |
应用内存节省约 29.6% |
三、关键结论分析
上下文复用的有效性:
- 当每路视频使用不同模型时,通过部分复用(每 3 个上下文中复用 2 个),应用内存从 368MB 降至 304MB,节省约 64MB,验证了复用机制对内存的优化效果。
- 当所有视频使用相同模型时,全量复用(所有上下文复用第一个)使应用内存进一步降至 259MB,较无复用场景节省 109MB,内存节省比例达 29.6%,接近理论值 11/12(约 91.7%),说明相同模型下复用效率更高。
内存优化逻辑:
- 无复用场景下,每个线程独立初始化上下文,数据结构重复构造,导致内存占用较高。
- 复用上下文时,多个线程共享同一模型的内存布局(如权重、计算图结构),仅按需分配输入输出缓冲区,从而减少冗余内存开销。
实际应用建议:
- 若多线程处理相同模型(如多路视频同类型检测),建议全量复用上下文,可最大化内存节省效果(接近 90% 理论值)。
- 若处理不同模型,可通过部分复用(如每路模型内复用上下文)降低内存压力,但节省比例随模型差异增大而下降。
四、延伸价值与注意事项
性能与内存的平衡:复用上下文未显著影响推理帧率(因 NPU 核心并行处理),实现了 “内存优化不牺牲速度” 的目标。
适用场景:适用于需要同时运行多个推理任务的边缘计算设备(如多摄像头监控、工业多传感器检测),尤其适合内存受限的嵌入式平台。
注意事项:复用上下文要求模型结构完全一致,若模型输入输出尺寸、量化参数等不同,需谨慎使用,避免推理错误。
通过测试数据可见,RKNPU 的上下文复用机制在多线程推理中能有效降低内存占用,尤其在相同模型场景下优化效果显著,为高并发推理任务提供了可行的内存优化方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号