

三、支持向量机
1. 间隔与支持向量
数据集$D = \{ ({{\bf{x}}_1},{y_1}),({{\bf{x}}_2},{y_2}),...,({{\bf{x}}_m},{y_m})\} $,其中${{\bf{x}}_i} = \{ {x_{i1}},{x_{i2}},...,{x_{id}}\} $,包含d维特征,${y_i} \in \{ - 1, + 1\} $。
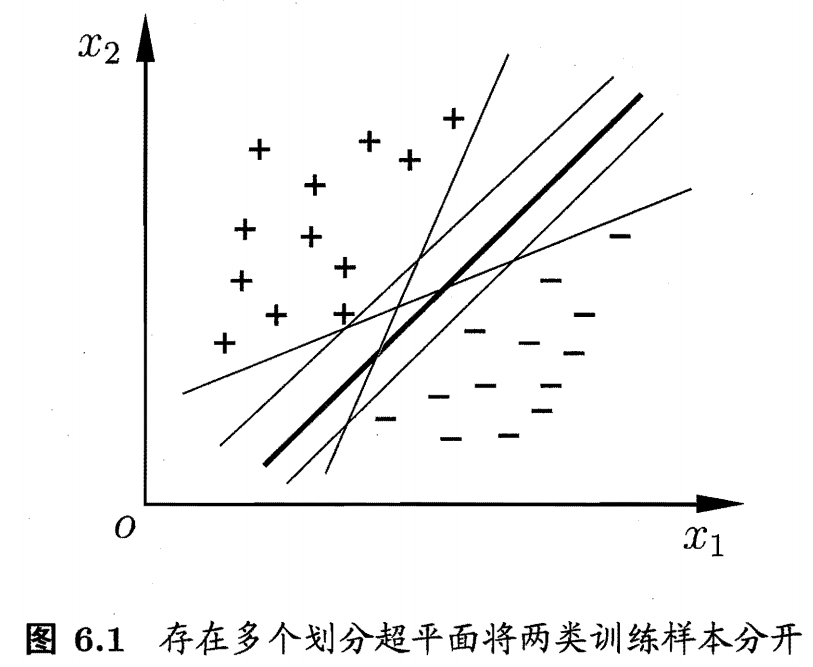
分类学习就是在样本空间里找到一个超平面,能够分离开“+”、“-”两类。如下图所示,在二维特征的样本空间里,找到一条线能够分离开两类。但是针对该数据集D,这样的线可能有很多,我们应该用哪一个呢?直观上看,应该是正中间加粗的那条线是“最合适”的线,对训练集D局部扰动的“容忍”性最好。换言之,这个划分超平面所产生的分类结果是最鲁棒的,对未见示例的泛化能力最强.
该超平面可通过线性方程来描述,${{\bf{\omega }}^T}{\bf{x}} + b = 0$,该超平面记为$({\bf{\omega }},b)$。
假设超平面$({\bf{\omega }},b)$能将训练样本正确分类,即对于$({{\bf{x}}_i},y_i) \in D$,若$y_i = +1$,则有${{{\bf{\omega }}^T}{{\bf{x}}_i} + b}>0$,若$y_i = -1$,则有${{{\bf{\omega }}^T}{{\bf{x}}_i} + b}<0$。令,
$\left\{ {\begin{array}{*{20}{c}}
{{{\bf{\omega }}^T}{{\bf{x}}_i} + b \ge + 1,{y_i} = + 1}\\
{{{\bf{\omega }}^T}{{\bf{x}}_i} + b \le - 1,{y_i} = - 1}
\end{array}} \right.$

距离超平面最近的这几个训练样本点(如上图中被圈出来的三个样本点)等号成立,被称为"支持向量" (support vector),两个异类支持向量到超平面的距离之和为 $\gamma = \frac{2}{{\left\| {\bf{\omega }} \right\|}}$,称为“间隔”。
我们希望在满足样本约束${y_i}({{\bf{\omega }}^T}{{\bf{x}}_i} + b) \ge 1$的条件下,找到具有最大间隔的划分超平面$\mathop {\max }\limits_{{\bf{\omega }},b} \frac{2}{{\left\| {\bf{\omega }} \right\|}}$。
支持向量机的基本型如下,
$\begin{array}{l}
\mathop {\min }\limits_{{\bf{\omega }},b} \frac{1}{2}{\left\| {\bf{\omega }} \right\|^2}\\
{\rm{s}}{\rm{.t}}{\rm{. }}{y_i}({{\bf{\omega }}^T}{{\bf{x}}_i} + b) \ge 1,i = 1,2,...,m
\end{array}$
2. 对偶问题
我们希望求解支持向量机基本型的最小化问题,来得到大间隔划分超平面所对应的{+1,-1}二分类模型
$f({\bf{x}}) = {{\bf{\omega }}^T}{\bf{x}} + b$
怎么求这个凸优化问题,求得最优模型参数$\bf{\omega }, b$呢?
我们对每条约束引入拉格朗日乘子$\alpha_i \ge 0$,则该问题的拉格朗日函数可写为,
$L({\bf{\omega }},b,{\bf{\alpha }}) = \frac{1}{2}{\left\| {\bf{\omega }} \right\|^2} + \sum\limits_{i = 1}^m {{\alpha _i}\left( {1 - {y_i}\left( {{{\bf{\omega }}^T}{{\bf{x}}_i} + b} \right)} \right)} $
该凸优化问题为,
$\mathop {{\rm{min}}}\limits_{{\rm{w,b}}} \mathop {\max }\limits_{{\alpha _i} \ge 0} L(w,b,\alpha )$
转化为对偶问题,
$\mathop {\max }\limits_{{\alpha _i} \ge 0} \mathop {{\rm{min}}}\limits_{{\rm{w,b}}} L(w,b,\alpha )$
求$L({\bf{\omega }},b,{\bf{\alpha }})$对$\bf{\omega }$和$b$的偏导为零
$\begin{array}{l}
{\bf{\omega }} = \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} {{\bf{x}}_i},\\
0 = \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} .
\end{array}$
则拉格朗日对偶问题表示为
$\begin{array}{*{20}{l}}
{\mathop {\max }\limits_{\bf{\alpha }} \sum\limits_{i = 1}^m {{\alpha _i} - } \frac{1}{2}\sum\limits_{i = 1}^m {\sum\limits_{j = 1}^m {{\alpha _i}{\alpha _j}} } {y_i}{y_j}{\bf{x}}_i^T{{\bf{x}}_j}}\\
{s.t.\sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0,}\\
{{\alpha _i} \ge 0,i = 1,2,...,m.}
\end{array}$
那么如何求解${\bf{\alpha }} = ({\alpha _1};{\alpha _2},...,{\alpha _m})$呢,这里介绍一个高效算法,SMO。
SMO 的基本思路是先固定$\alpha _i$之外的所有参数,然后求$\alpha _i$上的极值。由于存在约束$\sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0$,若固定$\alpha _i$之外的其他变量,则 $\alpha _i$可由其他变量导出,所以SMO每次选择两个变量$\alpha _i$和$\alpha _j$,并固定其他参数。这样,在参数初始化后, SMO 不断执行如下两个步骤直至收敛:
- 选取一对需要更新的变量$\alpha _i$和$\alpha _j$,
- 固定除$\alpha _i$和$\alpha _j$以外的参数,求解对偶优化问题,获得更新后的$\alpha _i$和$\alpha _j$
SMO 算法之所以高效,恰由于在固定其他参数后,仅优化两个参数的过程能做到非常高效。具体来说, 仅考虑$\alpha _i$和$\alpha _j$两个变量,约束$\sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0$可重写为,
$\begin{array}{l}
{\alpha _i}{y_i} + {\alpha _j}{y_j} = c,{\alpha _i} \ge 0,{\alpha _i} \ge 0\\
c = - \sum\limits_{k \ne i,j}^m {{\alpha _k}{y_k}}
\end{array}$ c是常数
这样可以利用该等式,消去对偶问题目标函数的$\alpha _j$,得到一个关于$\alpha _i$的单变量二次规划问题,不必调用数值优化算法即可高效地计算出更新后的$\alpha _i$和$\alpha _j$。
解得${\bf{\alpha }}$后,求出$\bf{\omega }$和$b$,
${\bf{\omega }} = \sum\limits_{i = 1}^m {{\alpha _i}{y_i}{{\bf{x}}_i}} $
${y_s}(\sum\limits_{i \in S}^m {{\alpha _i}{y_i}{\bf{x}}_i^T{{\bf{x}}_s}} + b) = 1$
其中$S = \{ i|{\alpha _i} > 0,i = 1,2,...,m\} $为所有支持向量的下标集。理论上,可选取任意支持向量并通过求解上式 获得 b, 但现实任务中常采用一种更鲁棒的做法,使用所有支持向量求解的平均值,
$b = \frac{1}{{\left| S \right|}}\sum\limits_{s \in S} {({y_s} - \sum\limits_{i \in S}^m {{\alpha _i}{y_i}{\bf{x}}_i^T{{\bf{x}}_s}} )} $
求完$\bf{\omega }$和$b$后,即可得到分类模型$f({\bf{x}}) = {{\bf{\omega }}^T}{\bf{x}} + b$。
从对偶问题解出$\alpha_i$,对应着每一个样本$({{\bf{x}}_i},y_i)$,和它满足的约束。满足KKT条件,
$\left\{ {\begin{array}{*{20}{c}}
{{\alpha _i} \ge 0;}\\
{{y_i}f({{\bf{x}}_i}) - 1 \ge 0;}\\
{{\alpha _i}({y_i}f({{\bf{x}}_i}) - 1) = 0.}
\end{array}} \right.$
所以,对于任意训练样本$({{\bf{x}}_i},y_i)$,总有$\alpha _i=0$或${y_i}f({{\bf{x}}_i})=1$。若$\alpha _i=0$,则该样本不会在$\bf{\omega }$求和模型中出现,不会对$f({\bf{x}})$有任何影响; 若$\alpha _i>0$,则必有${y_i}f({{\bf{x}}_i})=1$,所对应的样本点位于最大间隔边界上,是一个支持向量。这显示出支持向量机的一个重要性质:训练完成后?大部分的训练样本都不需保留,最终模型仅与支持向量有关 。
3. 核函数
在前面的学习中,我们都是假设用线性超平面去分离样本,如果线性不可分的话,我们可以将样本从原始空间映射到更高维的特征空间,使得样本在这个特征空间内线性可分。如下图所示,若将原始的二维空间 映射
到一个合适的三维空间 ,就能找到一个合适的划分超平面。幸运的是,如果原始空间是有限维 ,即属性数有限,那么一定存在一个高维特征空间使样本可分。

令$\phi ({\bf{x}})$表示将$\bf{x}$映射后的高维特征向量,于是在高维特征空间中划分超平面所对应的模型可表示为
$f({\bf{x}}) = {{\bf{\omega }}^T}\phi ({\bf{x}}) + b$
类似有支持向量机的基本型,
$\begin{array}{*{20}{l}}
{\mathop {\min }\limits_{{\bf{\omega }},b} \frac{1}{2}{{\left\| {\bf{\omega }} \right\|}^2}}\\
{{\rm{s}}.{\rm{t}}.{y_i}({{\bf{\omega }}^T}\phi ({{\bf{x}}_i}) + b) \ge 1,i = 1,2,...,m}
\end{array}$
拉格朗日对偶问题表示为
$\begin{array}{*{20}{l}}
{\mathop {\max }\limits_{\bf{\alpha }} \sum\limits_{i = 1}^m {{\alpha _i} - } \frac{1}{2}\sum\limits_{i = 1}^m {\sum\limits_{j = 1}^m {{\alpha _i}{\alpha _j}} } {y_i}{y_j}\phi {{({{\bf{x}}_i})}^T}\phi ({{\bf{x}}_j})}\\
{s.t.\sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0,}\\
{{\alpha _i} \ge 0,i = 1,2,...,m.}
\end{array}$
其中${\phi {{({{\bf{x}}_i})}^T}\phi ({{\bf{x}}_j})}$表示的是高维空间的特征内积,计算较困难,我们设计一个函数,该函数称之为核函数,
$k({{\bf{x}}_i},{{\bf{x}}_j}) = \phi {({{\bf{x}}_i})^T}\phi ({{\bf{x}}_j})$
不必去费心找合适的映射$\phi ()$函数,并计算样本的高维特征内积,我们可以直接利用函数来表示。且一般来说,利用如下常用的几种核函数(或许函数组合),能够将线性不可分的样本映射到高维特征空间从而使样本可分(前人已有证明,我们可以直接用这个结论)。

4. 软间隔与正则化
在前面的讨论中 ,我们一直假定训练样本在样本空间或特征空间中是线性可分的,即存在一个超平面能将不同类的样本完全划分开。然而,在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分;退一步说,即使恰好找到了 某个核函数使训练集在特征空间中线性可分?也很难断定这个貌似线性可分的结果不是由于过拟合所造成的。缓解该问题的一个办法是允许支持向量机在一些样本上出错。为此,要引入"软间隔" (soft margin)的概念,如图所示,

当然,在最大化间隔的同时,不满足约束的样本应尽可能少。于是,优化目标可写为
$\mathop {\min }\limits_{{\bf{\omega }},b} \frac{1}{2}{\left\| {\bf{\omega }} \right\|^2} + C\sum\limits_{i = 1}^m {{l_{0/1}}({y_i}({{\bf{\omega }}^T}\phi ({{\bf{x}}_i}) + b) - 1)} $
其中C>0,是惩罚系数。显然,当C为无穷大时,迫使所有样本均满足约束,;当C取有限值时,允许一些样本不满足约束。
$l_{0/1}$是损失函数。当样本不满足约束时,取值为1,会带来一些惩罚;当样本满足约束时,取值为0,不会带来惩罚。这样理想的损失函数非凸非连续,数学性质不太好,于是通常用一些其他函数来替代。如,
$\begin{array}{l}
{l_{hinge}}(z) = \max (0,1 - z)\\
{l_{\exp }}(z) = \exp ( - z)\\
{l_{\log }}(z) = \log (1 + \exp ( - z))
\end{array}$。
引入松弛变量$\xi_i $,定量衡量样本不满足约束的程度,则支持向量机的基本型可表示为,
$\begin{array}{l}
\mathop {\min }\limits_{{\bf{\omega }},b} \frac{1}{2}{\left\| {\bf{\omega }} \right\|^2} + C\sum\limits_{i = 1}^m {{\xi _i}} \\
{\rm{s}}.{\rm{t}}.\;\;{y_i}({{\bf{\omega }}^T}{{\bf{x}}_i} + b) \ge 1 - {\xi _i};\\
\;\;\;\;\;{\xi _i} \ge 0,\;\;\;\;i = 1,2,\;...,\;m.
\end{array}$
拉格朗日对偶问题表示为
$\begin{array}{*{20}{l}}
{\mathop {\max }\limits_{\bf{\alpha }} \sum\limits_{i = 1}^m {{\alpha _i} - } \frac{1}{2}\sum\limits_{i = 1}^m {\sum\limits_{j = 1}^m {{\alpha _i}{\alpha _j}} } {y_i}{y_j}\phi {{({{\bf{x}}_i})}^T}\phi ({{\bf{x}}_j})}\\
{s.t.\sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0,}\\
{0 \le {\alpha _i} \le C,i = 1,2,...,m.}
\end{array}$
类似利用KKT条件,求解。软间隔支持向量机的最终模型仅与支持向量有关。
接下来我们继续扩展损失函数,写成更一般的形式,
$\mathop {\min \;\;}\limits_{f\;\;\;} \Omega \left( f \right) + C\sum\limits_{i = 1}^m {\ell \left( {f\left( {{{\bf{x}}_i}} \right),{y_i}} \right)} $
其中$\Omega(f)$称为“结构风险”(structural risk) ,用于描述模型的某些性质;第二项称为“经验风险”(empirical risk) ,用于描述模型与训练数据的契合程度;C 用于对二者进行折中。从经验风险最小化的角度来看,$\Omega(f)$表述了我们希望获得具有何种性质的模型(例如希望获得复杂度较小的模型), 这为引入领域知识和用户意图提供了途径;另一方面,该信息有助于削减假设空间,从而降低了最小化训练误差的过拟合风险。从这个角度来说,上式称 为"正则化" (regularization) 问题 ,$\Omega(f)$称为正则化项, C 则称为正则化常数.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号