

随机采样方法(接受-拒绝采样,MCMC蒙特卡洛采样、Gibbs采样)
如果我们要求$f(x)$的积分,可化成,
\[\int {\frac{{f(x)}}{{p(x)}}p(x)dx} \]
$p(x)$是x的概率分布,假设${g(x) = \frac{{f(x)}}{{p(x)}}}$,然后在$p(x)$的分布下,抽取x个样本,当n足够大时,可以采用均值来近似$f(x)$的积分,
\[\int {f(x)dx} \approx \frac{{g({x_1}) + g({x_2}) + ... + g({x_n})}}{n}\]
1. 接受-拒绝采样
就算我们已知$p(x)$的分布,也很难得到一堆符合$p(x)$分布的样本$\{ {x_1},{x_2},...,{x_n}\} $来带入$g(x)$。
既然$p(x)$太复杂在程序中没法直接采样,那么我们设定一个程序可抽样的分布$q(x)$比如高斯分布,然后按照一定的方法拒绝某些样本,达到接近$p(x)$分布的目的,这就是接受拒绝采样。
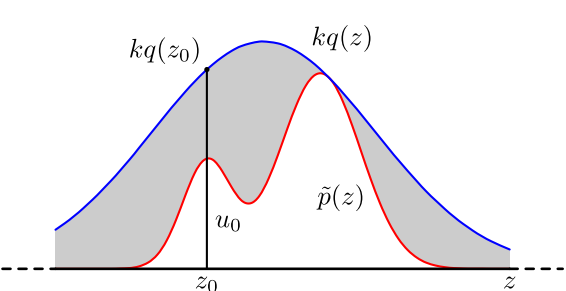
接受拒绝采样具体操作如下,设定一个方便抽样的函数$q(x)$,以及一个常量k,使得已知的分布$p(x)$(红线)总在$kq(x)$(蓝线)的下方,
从方便抽样的$q(x)$分布抽样得到$z_0$
从均匀分布$\left( {0,kq\left( {{z_0}} \right)} \right)$抽样得到$u_0$
如果$u_0$刚好落到灰色区域,拒绝这次采样,否则接受这次采样$x_t=z_0$
重复以上过程,得到接近$p(x)$分布的样本$\{ {x_1},{x_2},...,{x_n}\} $
在高维的情况下,接受-拒绝采样会出现两个问题,第一是合适的$q(x)$分布比较难以找到,第二是很难确定一个合理的 k 值。这两个问题会导致拒绝率很高,无用计算增加。
2. MCMC蒙特卡洛采样
这里我们需要引入马尔科夫链来帮忙,后面的几种采样方法都是基于马尔科夫链的,如果不想明白原理的话,这边一段都可以跳过。
可以参照马尔科夫细致平稳条件
我们的马尔科夫链模型的状态转移矩阵收敛到的稳定概率分布与我们的初始状态概率分布无关。这是一个非常好的性质,也就是说,如果我们得到了这个稳定概率分布$p(x)$对应的马尔科夫链模型的状态转移矩阵$P$,则我们可以用任意的概率分布样本$q_{0}(x)$开始,带入马尔科夫链模型的状态转移矩阵$P$,这样经过一些序列的转换,${q_0}\mathop \to \limits^P {q_1}\mathop \to \limits^P {q_2}...\mathop \to \limits^P {q_z}$,最终就可以得到符合对应稳定概率分布的样本${q_z} = \{ {x_1},{x_2},...,{x_n}\} $。
马尔科夫链采样具体过程总结如下,输入马尔科夫状态转移矩阵P,需要样本个数n,
从任意简单概率分布得到样本${q_0} = \{ {x_1},{x_2},...,{x_n}\}$开始
对样本$q_t$中的每一个样本$x_i$,利用状态转移矩阵P,${x_i} \times P$,求得转移后的$q_{t+1}$
达到终止条件(转移次数阈值或者q稳定)后的${q_z} = \{ {x_1},{x_2},...,{x_n}\} $即为我们需要的平稳分布对应的样本集。
针对目标平稳分布$p(x)$,如何得到它所对应的马尔科夫链状态转移矩阵P呢?
从任意一个马尔科夫状态转移矩阵Q开始,一般情况,$p(x)$和Q不满足细致平稳条件,
$\pi (i)Q(i,j) \ne \pi (j)Q(j,i)$
为了使等式成立,引入一个接受率$\alpha (i,j)$,
$\pi (i)Q(i,j)\alpha (i,j) = \pi (j)Q(j,i)\alpha (j,i)$
只要接受率$\alpha (i,j)$满足下面两个式子,就可以使细致平稳条件成立,
$\begin{array}{l}
\alpha (i,j) = \pi (j)Q(j,i)\\
\alpha (j,i) = \pi (i)Q(i,j)
\end{array}$
类似与接受-拒接采样思想,我们的目标转移矩阵P可以通过一个任意的马尔科夫转移矩阵Q乘以某个接受率值得到。取值在[0,1]之间,可以理解为一个概率值。接受-拒接采样是以一个方便抽样的分布通过一定的接受-拒绝概率得到一个不方便抽样的分布$p(x)$样本,MCMC采样是以一个常见的马尔科夫链状态转移矩阵Q通过一定的接受-拒绝概率得到目标转移矩阵P。
目标是生成$p(x)$分布的样本$\{ {X_1},{X_2},...,{X_n}\}$,需要样本的个数为n,MCMC采样具体操作如下,输入任意选定的马尔科夫状态转移矩阵Q,从任意初始值$x_0$开始,
从均匀分布采样u∼uniform[0,1]采样样本u,
利用转移矩阵Q中针对$x_{t}$元素的转移概率,也就是条件概率分布$Q(x|x_t)$,将$x_{t}$转移到$x_*$,
如果$u < \alpha (x_{t},x_*) = p({x_*})Q({x_*},{x_{t}})$,则接受这次转移${x_t} \to {x_*}$,即$x_{t+1}=x_{*}$,否则不接受转移,
重复上述步骤直至达到转移次数阈值后,再采样n次,得到接近$p(x)$分布的n个样本$\{ {X_1},{X_2},...,{X_n}\}$。
这个过程基本上就是MCMC采样的完整采样理论了,但是这个采样算法还是比较难在实际中应用,为什么呢?问题在于$p({x_t})Q({x_t}|{x_{t - 1}})$可能非常的小,比如0.1,导致我们大部分的采样值都被拒绝转移,采样效率很低。有可能我们采样了上百万次马尔可夫链还没有收敛,这让人难以接受,怎么办呢?
3. M-H采样
针对细致平稳条件,
$\pi (i)Q(i,j)\alpha (i,j) = \pi (j)Q(j,i)\alpha (j,i)$
接受率$\alpha (i,j)$太小怎么办,我们等式左右两边同时扩大使\alpha (j,i)$达到1
$\begin{array}{l}
\alpha (i,j) = min\{ \frac{{\pi (j)Q(j,i)}}{{\pi (i)Q(i,j)}},1\} \\
\alpha (j,i) = 1
\end{array}$
M-H采样具体操作如下,输入任意选定的马尔科夫状态转移矩阵Q,从任意初始值$x_0$开始,
从均匀分布采样u∼uniform[0,1]采样样本u,
利用转移矩阵Q中针对$x_{t}$元素的转移概率,也就是条件概率分布$Q(x|x_t)$,将$x_{t}$转移到$x_*$,
如果$u < \min \left\{ {\frac{{p({x_*})Q({x_*},{x_t})}}{{p({x_t})Q({x_t},{x_*})}},1} \right\}$,则接受这次转移${x_t} \to {x_*}$,即$x_{t+1}=x_{*}$,否则不接受转移,
重复上述步骤直至达到转移次数阈值后,再采样n次,得到接近$p(x)$分布的n个样本$\{ {X_1},{X_2},...,{X_n}\}$。
import numpy as np import pandas as pd def normal(x, u, sigma): p = np.exp(-(x - u) ** 2 / (2*sigma ** 2))/(np.sqrt(2*np.pi)*sigma) return p #选择的马尔可夫链状态转移矩阵Q(i,j)的条件转移概率是以i为均值,方差1的正态分布在位置j的值 #FUNCTION(x)就是我们已知函数形式,想生成该概率分布样本的分布p(x),可用normal(x, 0, 2)正态分布为例, # %% #从任意初始值开始,所有的样本都存在x_t里 x_t = [0] for t in range(5000): # 从均匀分布采样u∼uniform[0,1]采样样本u, u = np.random.uniform(0, 1) #利用转移矩阵Q,将上一个时候的xt,转移到x*(x_) x_ = np.random.normal(x_t[-1], 1) alpha = min(1, FUNCTION(x_)*normal(x_t[-1], x_, 1)) #判断是否接受转移 if u < alpha: x_t.append(x_) # %% # 后n个采样样本 即为我们需要的接近p(x)分布的n个样本 # 查看采样样本的概率密度函数是否符合FUNCTION(x) pd.Series(x_t[-200:]).plot(kind='kde')
"
M-H采样完整解决了使用蒙特卡罗方法需要的任意概率分布样本集的问题,因此在实际生产环境得到了广泛的应用。
但是在大数据时代,M-H采样面临着两大难题:
1) 我们的数据特征非常的多,M-H采样由于接受率计算式π(j)Q(j,i)π(i)Q(i,j)π(j)Q(j,i)π(i)Q(i,j)的存在,在高维时需要的计算时间非常的可观,算法效率很低。同时α(i,j)α(i,j)一般小于1,有时候辛苦计算出来却被拒绝了。能不能做到不拒绝转移呢?
2) 由于特征维度大,很多时候我们甚至很难求出目标的各特征维度联合分布,但是可以方便求出各个特征之间的条件概率分布。这时候我们能不能只有各维度之间条件概率分布的情况下方便的采样呢?
Gibbs采样解决了上面两个问题,因此在大数据时代,MCMC采样基本是Gibbs采样的天下,下一篇我们就来讨论Gibbs采样。
"
4. Gibbs采样
针对二维数据分布,
。。。。。。
由于Gibbs采样在高维特征时的优势,目前我们通常意义上的MCMC采样都是用的Gibbs采样。当然Gibbs采样是从M-H采样的基础上的进化而来的,同时Gibbs采样要求数据至少有两个维度,一维概率分布的采样是没法用Gibbs采样的,这时M-H采样仍然成立。
有了Gibbs采样来获取概率分布的样本集,有了蒙特卡罗方法来用样本集模拟求和,他们一起就奠定了MCMC算法在大数据时代高维数据模拟求和时的作用。MCMC系列就在这里结束吧。
感恩刘建平Pinard 撒花~
http://www.cnblogs.com/pinard/p/6645766.html
论文:
可用于参数估计,
“采用马尔科夫链蒙特卡洛仿真的方法对参数进行样本抽样,在对所抽样的样本进行分布拟合,即可获得模型参数的点估计、区间估计和近似的概率分布。具体参数估计过程可以通过软件Open BUGS 来实现。”
参考:
https://www.cnblogs.com/xbinworld/p/4266146.html
http://www.cnblogs.com/pinard/p/6625739.html
http://www.cnblogs.com/pinard/p/6645766.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号