MCMC(三)MCMC采样和M-H采样
MCMC(三)MCMC采样和M-H采样
在MCMC(二)马尔科夫链中我们讲到给定一个概率平稳分布$\pi$, 很难直接找到对应的马尔科夫链状态转移矩阵$P$。而只要解决这个问题,我们就可以找到一种通用的概率分布采样方法,进而用于蒙特卡罗模拟。本篇我们就讨论解决这个问题的办法:MCMC采样和它的易用版M-H采样。
1. 马尔科夫链的细致平稳条件
在解决从平稳分布$\pi$, 找到对应的马尔科夫链状态转移矩阵$P$之前,我们还需要先看看马尔科夫链的细致平稳条件。定义如下:
如果非周期马尔科夫链的状态转移矩阵$P$和概率分布$\pi(x)$对于所有的$i,j$满足:$$\pi(i)P(i,j) = \pi(j)P(j,i)$$
则称概率分布$\pi(x)$是状态转移矩阵$P$的平稳分布。
证明很简单,由细致平稳条件有:$$\sum\limits_{i=1}^{\infty}\pi(i)P(i,j) = \sum\limits_{i=1}^{\infty} \pi(j)P(j,i) = \pi(j)\sum\limits_{i=1}^{\infty} P(j,i) = \pi(j)$$
将上式用矩阵表示即为:$$\pi P = \pi$$
即满足马尔可夫链的收敛性质。也就是说,只要我们找到了可以使概率分布$\pi(x)$满足细致平稳分布的矩阵$P$即可。这给了我们寻找从平稳分布$\pi$, 找到对应的马尔科夫链状态转移矩阵$P$的新思路。
不过不幸的是,仅仅从细致平稳条件还是很难找到合适的矩阵$P$。比如我们的目标平稳分布是$\pi(x)$,随机找一个马尔科夫链状态转移矩阵$Q$,它是很难满足细致平稳条件的,即:$$\pi(i)Q(i,j) \neq \pi(j)Q(j,i)$$
那么如何使这个等式满足呢?下面我们来看MCMC采样如何解决这个问题。
2. MCMC采样
由于一般情况下,目标平稳分布$\pi(x)$和某一个马尔科夫链状态转移矩阵$Q$不满足细致平稳条件,即$$\pi(i)Q(i,j) \neq \pi(j)Q(j,i)$$
我们可以对上式做一个改造,使细致平稳条件成立。方法是引入一个$\alpha(i,j)$,使上式可以取等号,即:$$\pi(i)Q(i,j)\alpha(i,j) = \pi(j)Q(j,i)\alpha(j,i)$$
问题是什么样的$\alpha(i,j)$可以使等式成立呢?其实很简单,只要满足下两式即可:$$\alpha(i,j) = \pi(j)Q(j,i)$$$$\alpha(j,i) = \pi(i)Q(i,j)$$
这样,我们就得到了我们的分布$\pi(x)$对应的马尔科夫链状态转移矩阵$P$,满足:$$P(i,j) = Q(i,j)\alpha(i,j)$$
也就是说,我们的目标矩阵$P$可以通过任意一个马尔科夫链状态转移矩阵$Q$乘以$\alpha(i,j)$得到。$\alpha(i,j)$我们有一般称之为接受率。取值在[0,1]之间,可以理解为一个概率值。即目标矩阵$P$可以通过任意一个马尔科夫链状态转移矩阵$Q$以一定的接受率获得。这个很像我们在MCMC(一)蒙特卡罗方法第4节讲到的接受-拒绝采样,那里是以一个常用分布通过一定的接受-拒绝概率得到一个非常见分布,这里是以一个常见的马尔科夫链状态转移矩阵$Q$通过一定的接受-拒绝概率得到目标转移矩阵$P$,两者的解决问题思路是类似的。
好了,现在我们来总结下MCMC的采样过程。
1)输入我们任意选定的马尔科夫链状态转移矩阵$Q$,平稳分布$\pi(x)$,设定状态转移次数阈值$n_1$,需要的样本个数$n_2$
2)从任意简单概率分布采样得到初始状态值$x_0$
3)for $t = 0$ to $n_1 +n_2-1$:
a) 从条件概率分布$Q(x|x_t)$中采样得到样本$x_{*}$
b) 从均匀分布采样$u \sim uniform[0,1] $
c) 如果$u < \alpha(x_t,x_{*}) = \pi(x_{*})Q(x_{*},x_t) $, 则接受转移$x_t \to x_{*}$,即$x_{t+1}= x_{*}$
d) 否则不接受转移,即$x_{t+1}= x_{t}$
样本集$(x_{n_1}, x_{n_1+1},..., x_{n_1+n_2-1})$即为我们需要的平稳分布对应的样本集。
上面这个过程基本上就是MCMC采样的完整采样理论了,但是这个采样算法还是比较难在实际中应用,为什么呢?问题在上面第三步的c步骤,接受率这儿。由于$\alpha(x_t,x_{*}) $可能非常的小,比如0.1,导致我们大部分的采样值都被拒绝转移,采样效率很低。有可能我们采样了上百万次马尔可夫链还没有收敛,也就是上面这个$n_1$要非常非常的大,这让人难以接受,怎么办呢?这时就轮到我们的M-H采样出场了。
3. M-H采样
M-H采样是Metropolis-Hastings采样的简称,这个算法首先由Metropolis提出,被Hastings改进,因此被称之为Metropolis-Hastings采样或M-H采样
M-H采样解决了我们上一节MCMC采样接受率过低的问题。
我们回到MCMC采样的细致平稳条件:$$\pi(i)Q(i,j)\alpha(i,j) = \pi(j)Q(j,i)\alpha(j,i)$$
我们采样效率低的原因是$\alpha(i,j)$太小了,比如为0.1,而$\alpha(j,i)$为0.2。即:$$\pi(i)Q(i,j)\times 0.1 = \pi(j)Q(j,i)\times 0.2$$
这时我们可以看到,如果两边同时扩大五倍,接受率提高到了0.5,但是细致平稳条件却仍然是满足的,即:$$\pi(i)Q(i,j)\times 0.5 = \pi(j)Q(j,i)\times 1$$
这样我们的接受率可以做如下改进,即:$$\alpha(i,j) = min\{ \frac{\pi(j)Q(j,i)}{\pi(i)Q(i,j)},1\}$$
通过这个微小的改造,我们就得到了可以在实际应用中使用的M-H采样算法过程如下:
1)输入我们任意选定的马尔科夫链状态转移矩阵$Q$,平稳分布$\pi(x)$,设定状态转移次数阈值$n_1$,需要的样本个数$n_2$
2)从任意简单概率分布采样得到初始状态值$x_0$
3)for $t = 0$ to $n_1 +n_2-1$:
a) 从条件概率分布$Q(x|x_t)$中采样得到样本$x_{*}$
b) 从均匀分布采样$u \sim uniform[0,1] $
c) 如果$u < \alpha(x_t,x_{*}) = min\{ \frac{\pi(j)Q(j,i)}{\pi(i)Q(i,j)},1\}$, 则接受转移$x_t \to x_{*}$,即$x_{t+1}= x_{*}$
d) 否则不接受转移,即$x_{t+1}= x_{t}$
样本集$(x_{n_1}, x_{n_1+1},..., x_{n_1+n_2-1})$即为我们需要的平稳分布对应的样本集。
很多时候,我们选择的马尔科夫链状态转移矩阵$Q$如果是对称的,即满足$Q(i,j) = Q(j,i)$,这时我们的接受率可以进一步简化为:$$\alpha(i,j) = min\{ \frac{\pi(j)}{\pi(i)},1\}$$
4. M-H采样实例
为了更容易理解,这里给出一个M-H采样的实例。
完整代码参见我的github: https://github.com/ljpzzz/machinelearning/blob/master/mathematics/mcmc_3_4.ipynb
在例子里,我们的目标平稳分布是一个均值3,标准差2的正态分布,而选择的马尔可夫链状态转移矩阵$Q(i,j)$的条件转移概率是以$i$为均值,方差1的正态分布在位置$j$的值。这个例子仅仅用来让大家加深对M-H采样过程的理解。毕竟一个普通的一维正态分布用不着去用M-H采样来获得样本。
代码如下:
import random import math from scipy.stats import norm import matplotlib.pyplot as plt %matplotlib inline def norm_dist_prob(theta): y = norm.pdf(theta, loc=3, scale=2) return y T = 5000 pi = [0 for i in range(T)] sigma = 1 t = 0 while t < T-1: t = t + 1 pi_star = norm.rvs(loc=pi[t - 1], scale=sigma, size=1, random_state=None) alpha = min(1, (norm_dist_prob(pi_star[0]) / norm_dist_prob(pi[t - 1]))) u = random.uniform(0, 1) if u < alpha: pi[t] = pi_star[0] else: pi[t] = pi[t - 1] plt.scatter(pi, norm.pdf(pi, loc=3, scale=2)) num_bins = 50 plt.hist(pi, num_bins, normed=1, facecolor='red', alpha=0.7) plt.show()
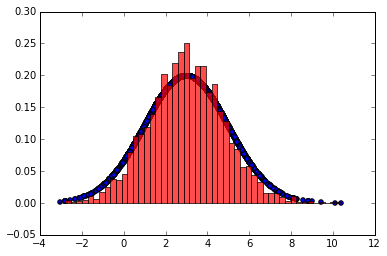
输出的图中可以看到采样值的分布与真实的分布之间的关系如下,采样集还是比较拟合对应分布的。
5. M-H采样总结
M-H采样完整解决了使用蒙特卡罗方法需要的任意概率分布样本集的问题,因此在实际生产环境得到了广泛的应用。
但是在大数据时代,M-H采样面临着两大难题:
1) 我们的数据特征非常的多,M-H采样由于接受率计算式$ \frac{\pi(j)Q(j,i)}{\pi(i)Q(i,j)}$的存在,在高维时需要的计算时间非常的可观,算法效率很低。同时$\alpha(i,j)$一般小于1,有时候辛苦计算出来却被拒绝了。能不能做到不拒绝转移呢?
2) 由于特征维度大,很多时候我们甚至很难求出目标的各特征维度联合分布,但是可以方便求出各个特征之间的条件概率分布。这时候我们能不能只有各维度之间条件概率分布的情况下方便的采样呢?
Gibbs采样解决了上面两个问题,因此在大数据时代,MCMC采样基本是Gibbs采样的天下,下一篇我们就来讨论Gibbs采样。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号