
SpringAI Agent开发秘籍:让javaer也可以用上Agent Skills
要说最近AI相关话题中什么最火,毫无疑问是Claude Skills,让我感到震惊的倒不是它为什么火爆,而是SpringAI居然已经迅速支持上Skills了,这效率真的是堪比🚀了。
谁说AI时代java开发者要掉队了? 肉虽然不一定吃得上,但是喝口汤还是妥妥的
接下来我们通过构建一个code reviewer, 来实际体验一把,如何将SpringAI和Skills结合起来使用
一、项目创建
1. 基础环境要求
要体验SpringAI & Skills,目前需要升级到SpringAI 2.x版本,同时我们的SpringBoot也可以升级到4.x
- SpringAI: 2.0.0-M2
- JDK21
- SpringBoot: 4.0.1
除了这几个基本依赖之外,我们可以选择一个支持Function Tool的大模型来作为这个实现的大脑中枢
我们这里选择智谱的大模型GLM-4.5-Flash (原因就是因为它免费,且效果还行,对所有想体验的小伙伴没有任何额外成本投入)
2. 项目创建
接下来我们创建一个SpringAI应用,对于一个标准的SpringAI应用,在pom.xml配置中,你会看到下面这些基础版本指定,这个也没什么好说的
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>4.0.1</version>
<relativePath />
</parent>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-ai.version>2.0.0-M2</spring-ai.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
接下来重点看一下我们这个项目所用到的几个核心依赖
<dependencies>
<dependency>
<groupId>org.springaicommunity</groupId>
<artifactId>spring-ai-agent-utils</artifactId>
<version>0.4.1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
</dependencies>
- spring-ai-agent-utils: 这个就是SpringAI进行agent开发的关键依赖包
- spring-ai-starter-model-zhipuai: 这个是智谱大模型进行交互的依赖包
3. 项目配置
依赖搞定之后,接下来就是在配置文件中,配置LLM访问的相关信息、以及agent相关配置参数,对应的配置文件 resources/application.yml
spring:
ai:
zhipuai:
# api-key 使用你自己申请的进行替换;如果为了安全考虑,可以通过启动参数进行设置
api-key: ${zhipuai-api-key}
chat: # 聊天模型
options:
model: GLM-4.5-Flash
## Agent Configuration
agent:
skills:
dirs: classpath:/.claude/skills
model: GLM-4.5-Flash
这几个配置看起来和之前SpringAI相关的并没有太多的区别,其中 agent 相关的配置中,主要设置了skills的存放路径,使用的model
根据上面的定义,我们将skills信息,放在resources/.claude/skills目录下
新增一个目录code-reviewer,目录下的文件为 SKILL.md
.claude/skills/code-reviewer/
└── SKILL.md
对应的内容如下
---
name: code-reviewer
description: Reviews Java code for best practices, security issues, and Spring Framework conventions. Use when user asks to review, analyze, or audit code.
---
# Code Reviewer
## Instructions
在审查代码时:
1. 检查是否存在安全漏洞(如SQL注入、XSS等)
2. 验证是否遵循了Spring Boot的最佳实践(如正确使用@Service、@Repository等注解)
3. 查找潜在的空指针异常
4. 提出提高代码可读性和可维护性的建议
5. 提供具体的逐行反馈,并附上代码示例
6. 以中文的方式返回代码评审结果
4. Skills简要说明
我们上面的Skill比较简单,就是一个markdown文档,SpringAI支持的Skills中,除了包含基本的SKILL.md文件(包含元数据(名称和描述)以及指导代理如何执行特定任务的说明)之外,还可以有相关的脚本、模板和参考资料
一个常见的skills结构如下
my-skill/
├── SKILL.md # Required: instructions + metadata
├── scripts/ # Optional: executable code
├── references/ # Optional: documentation
└── assets/ # Optional: templates, resources
二、核心实现
现在前置准备已经完成,接下来开始正式的体验吧
2.1 交互日志打印 MyLoggingAdvisor
为了让系统与大模型之间的交互更清晰,我们将双方交互的日志进行更友好的打印(也顺便看一下,一次用户感知的问答过程中,实际上有几次交互)
public class MyLoggingAdvisor implements BaseAdvisor {
private final int order;
public final boolean showSystemMessage;
public final boolean showAvailableTools;
private AtomicInteger cnt = new AtomicInteger(1);
private MyLoggingAdvisor(int order, boolean showSystemMessage, boolean showAvailableTools) {
this.order = order;
this.showSystemMessage = showSystemMessage;
this.showAvailableTools = showAvailableTools;
}
@Override
public int getOrder() {
return this.order;
}
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
System.out.println("======================= 第 " + cnt.getAndAdd(1) + " 轮 ====================================");
StringBuilder sb = new StringBuilder("\nUSER: ");
if (this.showSystemMessage && chatClientRequest.prompt().getSystemMessage() != null) {
sb.append("\n - SYSTEM: ").append(first(chatClientRequest.prompt().getSystemMessage().getText(), 300));
}
if (this.showAvailableTools) {
Object tools = "No Tools";
if (chatClientRequest.prompt().getOptions() instanceof ToolCallingChatOptions toolOptions) {
tools = toolOptions.getToolCallbacks().stream().map(tc -> tc.getToolDefinition().name()).toList();
}
sb.append("\n - TOOLS: ").append(ModelOptionsUtils.toJsonString(tools));
}
Message lastMessage = chatClientRequest.prompt().getLastUserOrToolResponseMessage();
if (lastMessage.getMessageType() == MessageType.TOOL) {
ToolResponseMessage toolResponseMessage = (ToolResponseMessage) lastMessage;
for (var toolResponse : toolResponseMessage.getResponses()) {
var tr = toolResponse.name() + ": " + first(toolResponse.responseData(), 1000);
sb.append("\n - TOOL-RESPONSE: ").append(tr);
}
} else if (lastMessage.getMessageType() == MessageType.USER) {
if (StringUtils.hasText(lastMessage.getText())) {
sb.append("\n - TEXT: ").append(first(lastMessage.getText(), 1000));
}
}
System.out.println("before: " + sb);
return chatClientRequest;
}
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
StringBuilder sb = new StringBuilder("\nASSISTANT: ");
if (chatClientResponse.chatResponse() == null || chatClientResponse.chatResponse().getResults() == null) {
sb.append(" No chat response ");
System.out.println("after: " + sb);
return chatClientResponse;
}
for (var generation : chatClientResponse.chatResponse().getResults()) {
var message = generation.getOutput();
if (message.getToolCalls() != null) {
for (var toolCall : message.getToolCalls()) {
sb.append("\n - TOOL-CALL: ")
.append(toolCall.name())
.append(" (")
.append(toolCall.arguments())
.append(")");
}
}
if (message.getText() != null) {
if (StringUtils.hasText(message.getText())) {
sb.append("\n - TEXT: ").append(first(message.getText(), 1200));
}
}
}
System.out.println("after: " + sb);
return chatClientResponse;
}
private String first(String text, int n) {
if (text.length() <= n) {
return text;
}
return text.substring(0, n) + "...";
}
public static Builder builder() {
return new Builder();
}
public static class Builder {
private int order = 0;
private boolean showSystemMessage = true;
private boolean showAvailableTools = true;
public Builder order(int order) {
this.order = order;
return this;
}
public Builder showSystemMessage(boolean showSystemMessage) {
this.showSystemMessage = showSystemMessage;
return this;
}
public Builder showAvailableTools(boolean showAvailableTools) {
this.showAvailableTools = showAvailableTools;
return this;
}
public MyLoggingAdvisor build() {
MyLoggingAdvisor advisor = new MyLoggingAdvisor(this.order, this.showSystemMessage,
this.showAvailableTools);
return advisor;
}
}
}
2.2 准备用于评审的代码
我们直接使用 实战 | 零基础搭建知识库问答机器人:基于SpringAI+RAG的完整实现 中的代码分块的内容作为待评审的内容,看下这段简单的文本分块工具会评审出什么内容
package com.git.hui.springai.app.demo;
import org.springframework.ai.document.Document;
import java.util.ArrayList;
import java.util.List;
/**
* 文档分块工具类
* 将长文档分割成较小的块,以便更好地进行向量化和检索
*/
public class DocumentChunker {
private final int maxChunkSize;
private final int overlapSize;
public static DocumentChunker DEFAULT_CHUNKER = new DocumentChunker();
public DocumentChunker() {
this(500, 50); // 默认值:最大块大小500个字符,重叠50个字符
}
public DocumentChunker(int maxChunkSize, int overlapSize) {
this.maxChunkSize = maxChunkSize;
this.overlapSize = overlapSize;
}
/**
* 将文档分割成块
*
* @param document 输入文档
* @return 分割后的文档块列表
*/
public List<Document> chunkDocument(Document document) {
String content = document.getText();
if (content == null || content.trim().isEmpty()) {
return List.of(document);
}
List<String> chunks = splitText(content);
List<Document> chunkedDocuments = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
String chunk = chunks.get(i);
String chunkId = document.getId() + "_chunk_" + i;
// 创建新的文档块,保留原始文档的元数据
Document chunkDoc = new Document(chunkId, chunk, new java.util.HashMap<>(document.getMetadata()));
// 添加块相关的元数据
chunkDoc.getMetadata().put("chunk_index", i);
chunkDoc.getMetadata().put("total_chunks", chunks.size());
chunkDoc.getMetadata().put("original_document_id", document.getId());
chunkedDocuments.add(chunkDoc);
}
return chunkedDocuments;
}
/**
* 将文本分割成块
*
* @param text 输入文本
* @return 分割后的文本块列表
*/
private List<String> splitText(String text) {
List<String> chunks = new ArrayList<>();
// 按多种分隔符分割,优先在语义边界处分割(包括中文句号、问号、感叹号等)
String[] sentences = text.split("(?<=。)|(?<=!)|(?<=!)|(?<=?)|(?<=\\?)|(?<=\\n\\n)");
StringBuilder currentChunk = new StringBuilder();
for (String sentence : sentences) {
// 跳过空句子
if (sentence.trim().isEmpty()) {
continue;
}
// 如果当前块加上新句子不超过最大大小,就添加到当前块
if (currentChunk.length() + sentence.length() <= maxChunkSize) {
if (currentChunk.length() > 0) {
currentChunk.append(sentence);
} else {
currentChunk.append(sentence);
}
} else {
// 如果当前块为空,但是单个句子太长,需要强制分割
if (currentChunk.length() == 0) {
List<String> subChunks = forceSplit(sentence, maxChunkSize);
for (int i = 0; i < subChunks.size(); i++) {
String subChunk = subChunks.get(i);
// 如果不是最后一个子块,添加到当前块并保存
if (i < subChunks.size() - 1) {
chunks.add(subChunk);
} else {
currentChunk.append(subChunk);
}
}
} else {
// 保存当前块
chunks.add(currentChunk.toString());
// 开始新块,包含重叠部分
currentChunk = new StringBuilder();
// 添加重叠部分,如果句子长度大于重叠大小,则只取末尾部分
if (sentence.length() > overlapSize) {
String overlap = sentence.substring(Math.max(0, sentence.length() - overlapSize));
currentChunk.append(overlap);
currentChunk.append(sentence);
} else {
currentChunk.append(sentence);
}
}
}
}
// 添加最后一个块
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString());
}
return chunks;
}
/**
* 强制将长文本分割成指定大小的块
*
* @param text 输入文本
* @param maxSize 最大块大小
* @return 分割后的文本块列表
*/
private List<String> forceSplit(String text, int maxSize) {
List<String> chunks = new ArrayList<>();
int start = 0;
while (start < text.length()) {
int end = Math.min(start + maxSize, text.length());
String chunk = text.substring(start, end);
chunks.add(chunk);
start = end;
}
return chunks;
}
/**
* 将多个文档分别分割成块
*
* @param documents 输入文档列表
* @return 分割后的文档块列表
*/
public List<Document> chunkDocuments(List<Document> documents) {
List<Document> allChunks = new ArrayList<>();
for (Document document : documents) {
allChunks.addAll(chunkDocument(document));
}
return allChunks;
}
}
2.3 核心实现
配置Agent实现代码评审
Bean定义与依赖注入
- CommandLineRunner: Spring启动后自动执行的接口
- ChatClient.Builder: 用于构建聊天客户端
- @Value("${agent.skills.dirs:Unknown}"): 注入配置属性,获取技能目录资源列表
ChatClient配置链
- 系统提示词配置:
- 技能工具配置:
- SkillsTool.builder().addSkillsResources(agentSkillsDirs).build(): 动态加载预定义的技能资源
- FileSystemTools.builder().build(): 提供文件系统访问能力
- ShellTools.builder().build(): 提供命令行执行能力
- Advisor配置:
- ToolCallAdvisor.builder().build(): 处理工具调用逻辑
- MyLoggingAdvisor.builder().showAvailableTools(false).showSystemMessage(false).build(): 自定义日志记录,隐藏工具和系统消息详情
代码评审执行流程
请求执行
- prompt(): 构建提示词
- .call(): 发起AI请求
- .content(): 获取返回结果
@Bean
CommandLineRunner commandLineRunner(ChatClient.Builder chatClientBuilder,
@Value("${agent.skills.dirs:Unknown}") List<Resource> agentSkillsDirs) throws IOException {
return args -> {
ChatClient chatClient = chatClientBuilder // @formatter:off
.defaultSystem("始终运用现有技能协助用户满足其要求.")
// Skills tool
.defaultToolCallbacks(SkillsTool.builder().addSkillsResources(agentSkillsDirs).build())
// 支持读取系统文件内容,用于读取我们需要评审的代码
.defaultTools(FileSystemTools.builder().build())
// 支持执行脚本,如果skills中存在script,那么这些脚本的执行,靠的就是它
.defaultTools(ShellTools.builder().build())
.defaultAdvisors(
// Tool Calling advisor
ToolCallAdvisor.builder().build(),
// Custom logging advisor
MyLoggingAdvisor.builder()
.showAvailableTools(false)
.showSystemMessage(false)
.build())
.build();
// @formatter:on
var answer = chatClient
// 下面具体的代码位置,请根据实际的位置进行替换
.prompt("""
按照最佳实际的方式,评审下面的代码实现:
D:\\Workspace\\hui\\project\\spring-ai-demo\\v2\\T01-agentic-skills-simple-design\\src\\main\\java\\com\\git\\hui\\springai\\app\\demo\\DocumentChunker.java
""")
.call()
.content();
System.out.println("The Answer: " + answer);
};
}
2.4 执行演示
接下来我们启动项目,验证一下效果如何(在启动命令行参数中,配置上大模型的api-key,当然也可以直接在yml配置文件中进行配置)
@Slf4j
@SpringBootApplication
public class T01Application {
public static void main(String[] args) {
SpringApplication.run(T01Application.class, args);
}
}
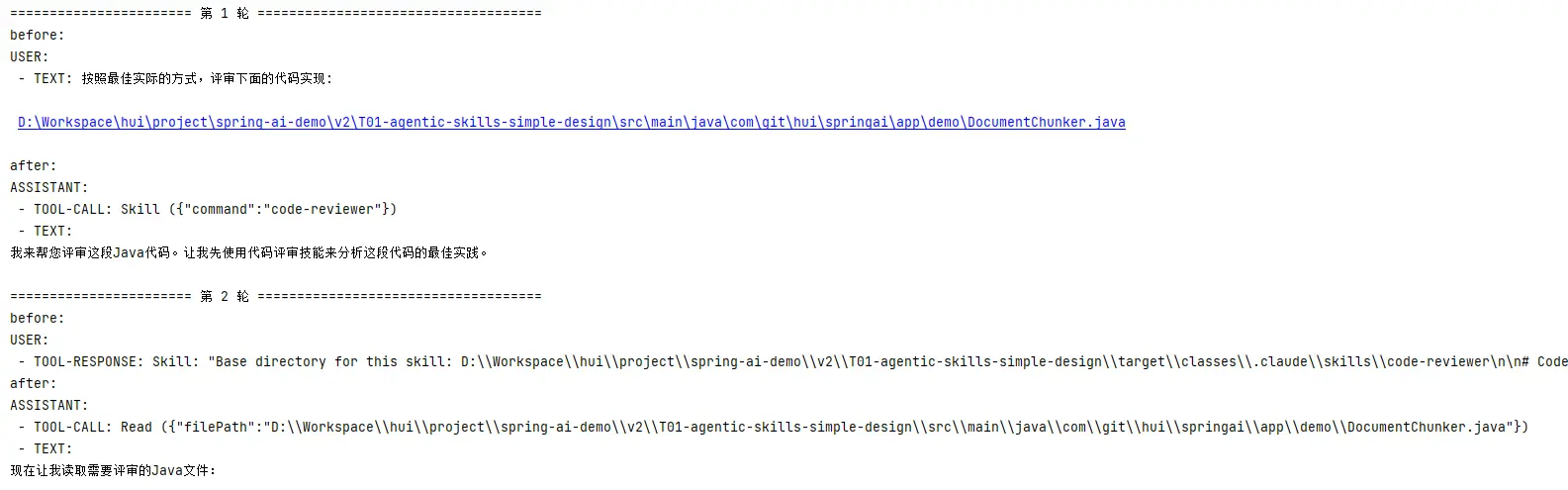

从上面的截图也可以看出,系统与大模型之间进行了三轮对话,
- 第一轮: 用户的原始诉求 -> 大模型
- 大模型识别到需要进行代码评审,给系统响应
{"command":"code-reviewer"}
- 第二轮:系统接收到响应之后,读取skills的约束进行响应
- 大模型返回需要读取需要评审的代码内容,对应的响应为
{"filePath":"D:\\Workspace\\hui\\project\\spring-ai-demo\\v2\\T01-agentic-skills-simple-design\\src\\main\\java\\com\\git\\hui\\springai\\app\\demo\\DocumentChunker.java"}
- 第三轮:系统读取代码内容,发送给大模型
- 大模型返回评审结果
下面是完整的返回文本,有兴趣的小伙伴可以看看
基于对代码的详细分析,我为您提供以下代码评审报告:
## 📋 代码评审报告 - DocumentChunker.java
### ✅ **优点**
1. **功能完整性强**:代码实现了完整的文档分块功能,包括:
- 单文档分块
- 批量文档分块
- 智能语义边界分割
- 重叠机制
- 长文本强制分割
2. **良好的文档注释**:类和方法都有清晰的中文注释,说明了功能用途
3. **合理的默认值**:提供了合理的默认参数(maxChunkSize=500, overlapSize=50)
4. **元数据保留**:正确保留了原始文档的元数据,并添加了块相关的元数据
### ⚠️ **需要改进的问题**
#### 1. **线程安全问题**
// 问题:静态实例不是线程安全的
public static DocumentChunker DEFAULT_CHUNKER = new DocumentChunker();
**建议**:使用 `volatile` 或 `AtomicReference`,或者移除静态实例让用户自己管理。
#### 2. **参数验证不足**
// 问题:构造函数没有参数验证
public DocumentChunker(int maxChunkSize, int overlapSize) {
this.maxChunkSize = maxChunkSize;
this.overlapSize = overlapSize;
}
**建议**:添加参数验证,确保 `maxChunkSize > 0` 且 `overlapSize < maxChunkSize`。
#### 3. **正则表达式复杂度**
// 问题:正则表达式过于复杂,难以维护
String[] sentences = text.split("(?<={。})|(?<=!)|(?<=!)|(?<=?)|(?<=\\?)|(?<=\\n\\n)");
**建议**:提取为常量或使用更清晰的方式处理多语言分隔符。
#### 4. **性能优化空间**
// 问题:StringBuilder操作可以优化
if (currentChunk.length() > 0) {
currentChunk.append(sentence);
} else {
currentChunk.append(sentence);
}
**建议**:简化为 `currentChunk.append(sentence);`
#### 5. **异常处理缺失**
代码中没有处理可能的异常情况,如:
- 内存不足
- 文档过大导致性能问题
### 🔧 **具体改进建议**
#### 1. **添加参数验证**
public DocumentChunker(int maxChunkSize, int overlapSize) {
if (maxChunkSize <= 0) {
throw new IllegalArgumentException("maxChunkSize must be positive");
}
if (overlapSize >= maxChunkSize) {
throw new IllegalArgumentException("overlapSize must be less than maxChunkSize");
}
this.maxChunkSize = maxChunkSize;
this.overlapSize = overlapSize;
}
#### 2. **线程安全改进**
public static final DocumentChunker DEFAULT_CHUNKER = new DocumentChunker();
// 或者移除静态实例,让用户自己管理
#### 3. **提取常量**
private static final String SENTENCE_SEPARATOR_PATTERN =
"(?<={。})|(?<=!)|(?<=!)|(?<=?)|(?<=\\?)|(?<=\\n\\n)";
#### 4. **添加Builder模式**
考虑使用Builder模式来更灵活地配置参数。
#### 5. **性能优化**
// 优化StringBuilder操作
private List<String> splitText(String text) {
List<String> chunks = new ArrayList<>();
String[] sentences = text.split(SENTENCE_SEPARATOR_PATTERN);
StringBuilder currentChunk = new StringBuilder();
for (String sentence : sentences) {
if (sentence.trim().isEmpty()) continue;
if (currentChunk.length() + sentence.length() <= maxChunkSize) {
currentChunk.append(sentence);
} else {
// 处理块分割逻辑
}
}
// ...
}
### 🎯 **总体评价**
这是一个功能完整、设计合理的文档分块工具类,主要问题集中在线程安全、参数验证和代码可维护性方面。通过上述改进,可以显著提升代码的健壮性和可维护性。
**建议优先级**:
1. 高优先级:参数验证、线程安全
2. 中优先级:性能优化、代码简化
3. 低优先级:Builder模式、异常处理
三、小结
SpringAI的Agent开发范式配合Skills机制,非常简单就实现了AI应用的工程化。整个过程实现下来,门槛还是比较低的。 不得不高喊一声:Spring🐂🍺
实现方式虽然简单,但是这个背后的设计哲学、开发思维的转变,还是很值得我们学习参考的——在AI时代,如何将我们现有的技能(如可复用、模块化思设计等)转变到大模型应用开发,这可能是我们每一个旧时代程序员最大的财富。
那么这一套是怎么实现的呢?
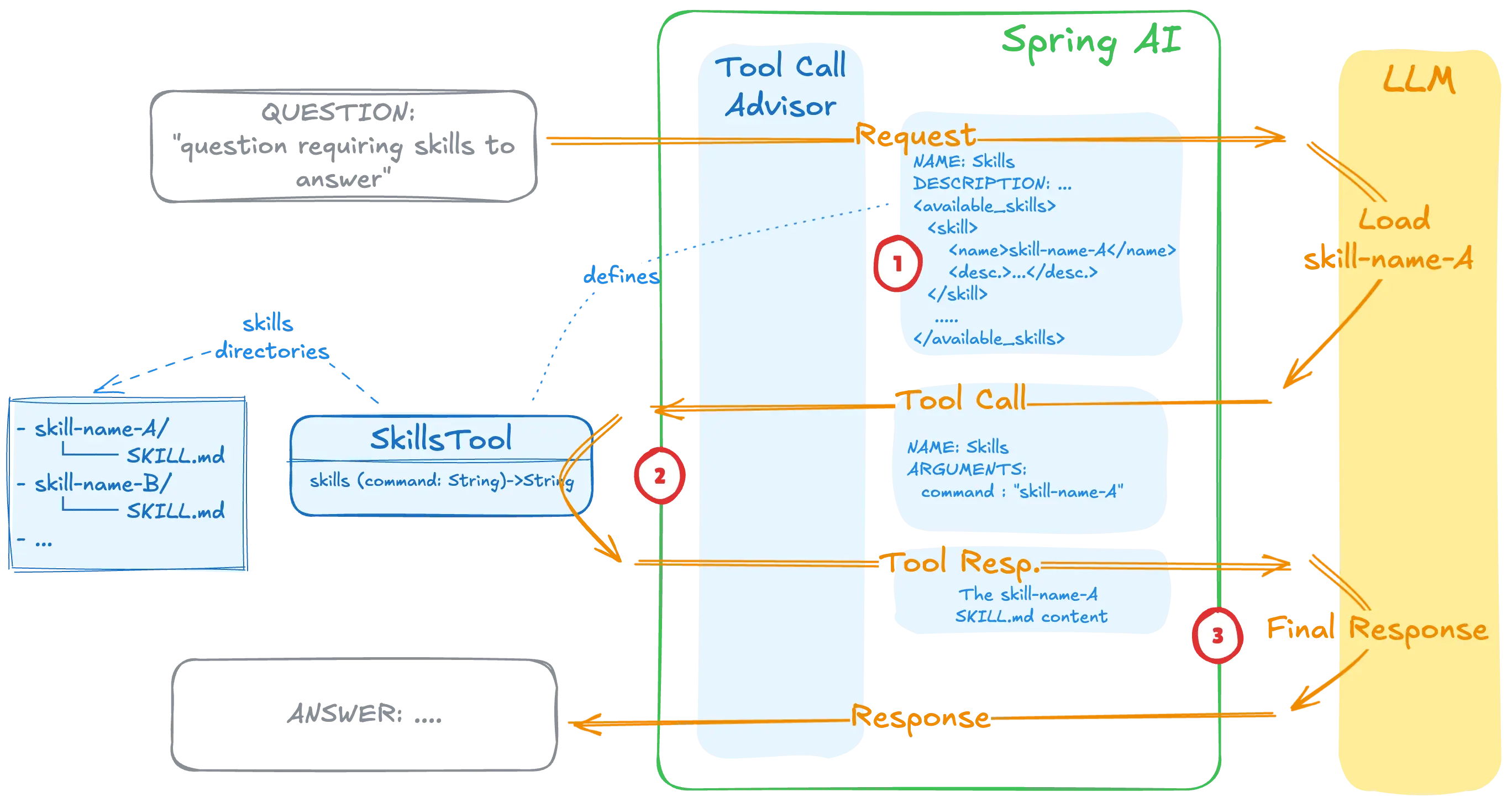
Spring AI采用基于工具的集成方法,通过实现各种工具,使任何LLM都能回调执行,Skills的运行过程,通常是下面三步:
- 发现(启动阶段)
- 通过
SKILL.md文件中的元数据,快速实现技能的安装注册
- 语义匹配(对话过程中)
- 当用户发出请求时,LLM 会检查工具定义中嵌入的技能描述。如果 LLM 判断用户请求在语义上与某个技能的描述匹配,则会调用该技能工具,并将技能名称作为参数传递给它。
- 执行(技能调用时)
- 当调用技能工具时,SkillsTool会从磁盘加载完整的SKILL.md内容,并将其与技能的基础目录路径一起返回给大型语言模型(LLM)。然后,LLM会按照技能内容中的指令执行。如果技能引用了其他文件或辅助脚本,LLM会使用
FileSystemTools的Read函数或ShellTools的Bash函数来按需访问它们
项目源码:
零基础入门:
- LLM 应用开发是什么:零基础也可以读懂的科普文(极简版)
- 大模型应用开发系列教程:序-为什么你“会用 LLM”,但做不出复杂应用?
- 大模型应用开发系列教程:第一章LLM到底在做什么?
- 大模型应用开发系列教程:第二章 模型不是重点,参数才是你真正的控制面板
- 大模型应用开发系列教程:第三章 为什么我的Prompt表现很糟?
- 大模型应用开发系列教程:第四章Prompt 的工程化结构设计
- 大模型应用开发系列教程:第五章 从 Prompt 到 Prompt 模板与工程治理
- 大模型应用开发系列教程:第六章 上下文窗口的真实边界
- 大模型应用开发系列教程:第七章:从 “堆上下文” 到 “管理上下文”
实战
- 大模型应用开发实战:两百行实现一个自然语言地址提取智能体
- 大模型应用开发实战:基于SpringAI与大模型的零配置发票智能提取架构
- 实战 | 零基础搭建知识库问答机器人:基于SpringAI+RAG的完整实现
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号