

线上故障实录-一大早服务就不可用了?
线上故障实录-一大早服务就不可用了?
难得一个周末,一大早还没有睡醒就接到另外一个团队的电话,app 打不开了,所有的数据都没有了,睡意全无,赶紧起来看能不能紧急抢救一下,最终发现是一个关键链路的 nginx 配置错误,导致 nginx 无法启动,接下来完整的记录下愉快的周末中,这个不愉快的早晨
1. 项目环境
首先说一下背景,出问题的这个项目是我之前参与的,现在由另外的小伙伴负责。这个项目使用 nginx 作为反向代理,因为某些业务上的原因,搞了一个香港和大陆之间的专线,下面又有一层的 nginx 进行不同业务的请求转发
后端服务基于 SpringCloud 微服务搭建,通过统一网关对外提供基本的业务服务; 也有部分服务不是通过网关,直接 nginx 转发过去的(比如内部使用的控制台就没有走网关)

大致的结构如上图,实际有一些区别,至于为什么选择这种架构设计,与实际的业务场景以及之前遭遇过的一次 ddos 有关,这个与本文主题关系不大,就不详细展开
2. 问题描述
接下来我们先看一下出现的状况,运营的小伙伴最早接到反馈,app 上所有的数据都没了,并提供了一个上次出现这种场景的原因是域名的证书过期
注意,这里有两个关键信息点
- 数据没有 -> 直观反映是不是业务服务跪了导致的
- 证书过期 -> 我们的域名采用的是 let's encrypt 进行证书颁发,只有三个月的有效期,所以也不是不存在这种可能
3. 问题追踪
前面是背景介绍,然后要开始进入正题,起床第一件事,呃并不是打开电脑,而是先打开 appp 看一下是个什么状况,毕竟不能完全凭运营一说,就开始找问题
app 表现与运营同学描述一致,所有数据也空白,直观的表现就是服务端 gg 了
尝试解决思路
下面的文字相对冗长,基本思路可以参考下面这个图

先从运营同学提供的思路来看一下证书是否过期,直接浏览器输入 app 接口对应的一级域名xxx.com,结果发现被 302 到另外一个域名,还真的是证书过期,关键是这个也不是刚刚过期,而是过期了五十多天,这个时间对不上
既然一级域名没法直接查看,那就选择 app 直接请求接口的域名,来看一下是不是过期了,结果尴尬的事情是我不知道这个二级域名的前缀是啥(为了避免 ddos,我们之前做的一个方案是随机生成了很多二级域名前缀,然后根据用户的地域进行二级域名的选取),所以只能通过抓包了
找到域名之后(假设为 xxx.a.com),直接浏览器访问,毫无意外提示"无法访问此网络",那这个域名证书是否过期就不好确定了
出现上面这个表现,自然而然的就是ping xxx.a.com,可以 ping 通,证明这个域名解析没有问题
简单的从域名上没有找到明显的突破口,接着去确认一下服务是否还在线,登录服务器,jps -l查看一下当前进程,结果居然发现居然没有zuul网关进程,难道是网关跪了导致的么,貌似有眉目了,在准备重启之前,看了一下日志,居然发现有正常的心跳日志,这特么的就鬼畜了啊,进程都没有,日志还在打;然后谨慎的用top看了一下服务器进程,zuul进程还在,不过坑爹的是它居然是 root 权限启动的;所以我用普通账号执行jps -l没有展示。针对这种状况,强烈建议所有的小伙伴,不要用 root 用户在服务器上搞事情
确定服务还在之后,使用curl http://127.0.0.1:8080/xxx来发出请求,正常响应,ok,服务没挂,那么问题就出现在上层
然后登录上层的几个 nginx 服务器,查看对应的 nginx 访问日志tail -f /var/log/nginx/access.log,以及异常日志tail -f /var/log/nginx/error.log,里面有几个之前的 ssl 验证失败的日志,好像也不是导致这个问题的原因
从日志文件上,看不出太多的信息,接着从最上层的 nginx 出发,ping 域名,层层下推,结果发现到了某一台机器之后,ping 了没反应,然后查看nginx.conf配置,起初是怀疑这里是不是被人动过了(虽然说可能性比较小),这个时候走了弯路,配置上看不出任何问题,然后下意思的查看了一下 nginx 进程ps aux | grep nginx,结果发现进程不在,原因找到
nginx 进程为什么会突然没了,这个后面在说
4. 问题 fix
既然发现是因为 nginx 进程不再导致的原因,那就简单了,启动 nginx 就好了,结果发现 nginx 进程死活都起不来,一直提示 80 端口被占用, nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use) but no 80 process can find
遇到上面这个问题,要解决还不简单,找到占用 80 端口的进程,干掉它
netstat -ntulp | grep 80
让人诧异的是,没有找到任何占用 80 端口的进程
网上搜索了一下,有不少小伙伴是通过下面这个命令解决的 NGINX BIND() TO 0.0.0.0:80 FAILED (98: ADDRESS ALREADY IN USE)
# use fuser to kill process using port 80!
fuser -k 80/tcp
很遗憾的是,使用上面这个命令依然没有能解决问题;这就很尴尬了啊,这个时候只能祭出我的大杀器了--重启服务器
reboot
经过短暂的重启之后,再次启动 nginx,嗯,依然没有解决问题;nginx 居然死活起不来,这个问题就有点大发了,先解决线上问题让服务可用吧,临时调整了一下转发规则,把这台机器摘掉,操作完毕之后服务恢复
接下来我们的问题就是这个 nginx 为啥起不来
这里有一篇文章带来了一些思路 Fix nginx: [emerg] bind() to [::]:80 failed (98: Address already in use)
这个文章里面主要说的是在配置中,使用如下这种姿势导致端口占用
server {
listen :80;
listen [::]:80;
}
对应提请的解决方案是只保留一个,或者在后面加一个 ipv6 的限定
server {
listen 80;
listen [::]:80 ipv6only=on;
}
# or
server {
listen [::]:80;
}
但是我的 nginx 配置中本来就只有一个listen 80,没有上面两个,讲道理不应该会冲突才对
注意到nginx.conf配置文件中有下面这一行
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
难道是 conf.d 目录下的配置中,某个配置文件和最外面的冲突了导致的么,正好这个目录下只有一个配置文件,先干掉它
cd conf.d
mv xxx.conf xxx.conf.bk
nginx
然后发现 nginx 顺利的起来了,通过再次查看,果然是上面这个原因导致的 80 端口冲突,调整一下即可;然后就剩下一个疑问,就这个配置,之前是怎么起来的(可能只有最开始部署这个的同学才知道了...)
最后揭晓一下,为啥这个 nginx 进程会挂掉,对于这个原因我也是很忧桑
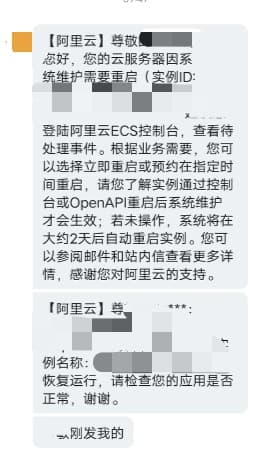
5. 小结
其实这个问题最后看来还是比较简单的,根本原因在于某个单点的 nginx 跪了,导致整个服务不可用,这也暴露了几个比较严重的缺陷
- 单点问题
- 监控缺失(核心链路的进程监控还是比较重要的,在整个问题的排查中,真没有想到会是 nginx 进程没有的情况)
- 短信要及时看,并提醒给相应的小伙伴(阿里云已经提醒了,可惜这条短信是在最后问题修复之后才告诉到负责这一块内容的小伙伴,这种事后,也就给我们排查为啥 nginx 跪了有点帮助了 🐩)
II. 其他
1. 一灰灰 Blog: https://liuyueyi.github.io/hexblog
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
2. 声明
尽信书则不如,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现 bug 或者有更好的建议,欢迎批评指正,不吝感激
- 微博地址: 小灰灰 Blog
- QQ: 一灰灰/3302797840
3. 扫描关注
一灰灰 blog


 浙公网安备 33010602011771号
浙公网安备 33010602011771号