1.Oracle数据库安装
1.1.整合PL/SQL Developer软件
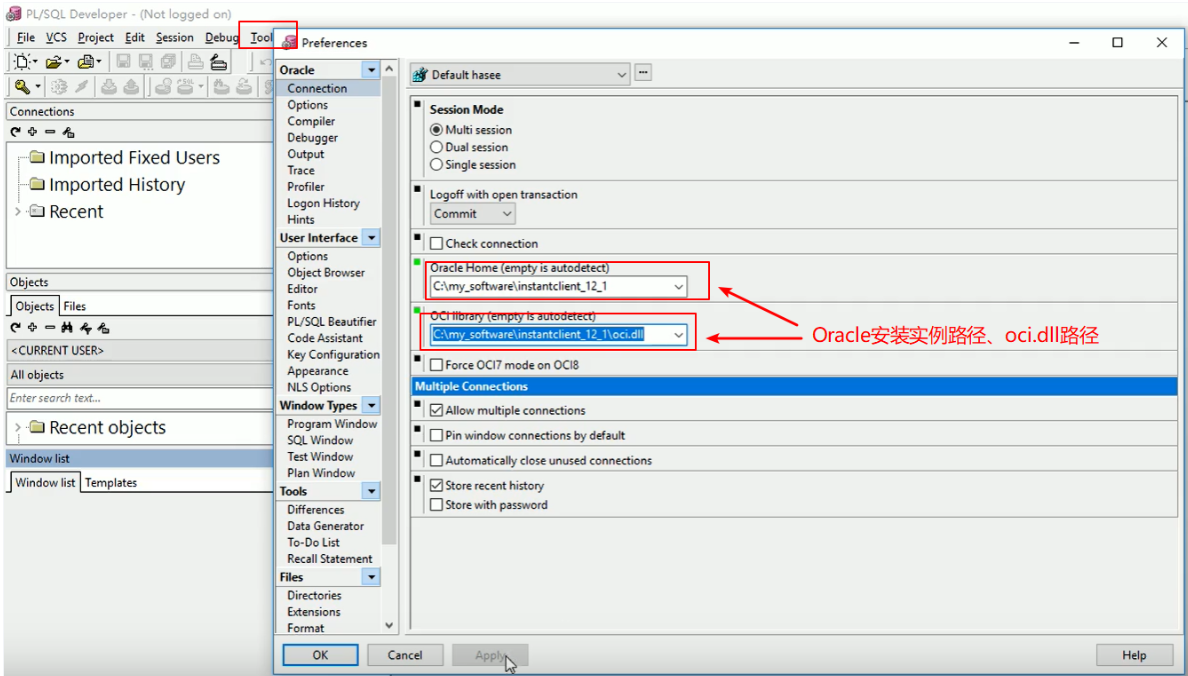
1.点击Tools—>Preferences—>Connection连接,填写连接信息:
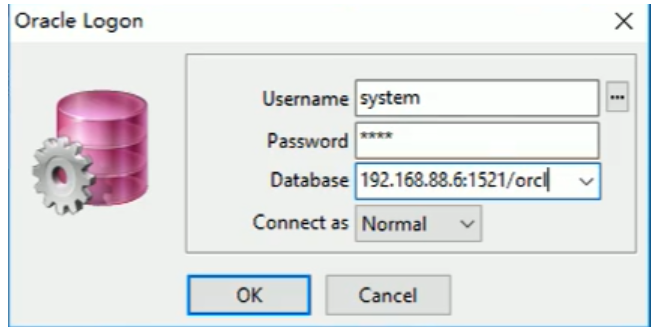
2.连接Oracle数据库,默认连接方式:
192.168.88.6:表示安装Oracle数据库的服务器地址;
1521:默认端口号
orcl:默认Oracle安装数据库名称
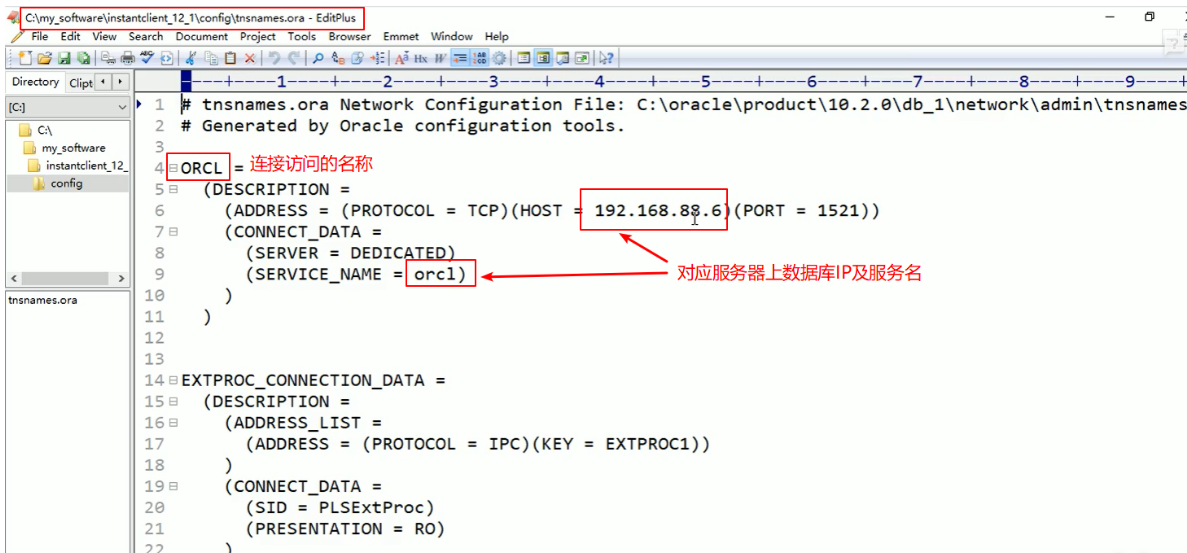
3.使用修改tnsnames.ora文件配置方式连接:
①复制远程服务器Oracle安装目录中的tnsnames.ora到本地的instantclient_12_1软件目录下:

②修改本地复制的tnsnames.ora配置如下:
③设置本地tnsnames.ora到本地的环境变量配置中:
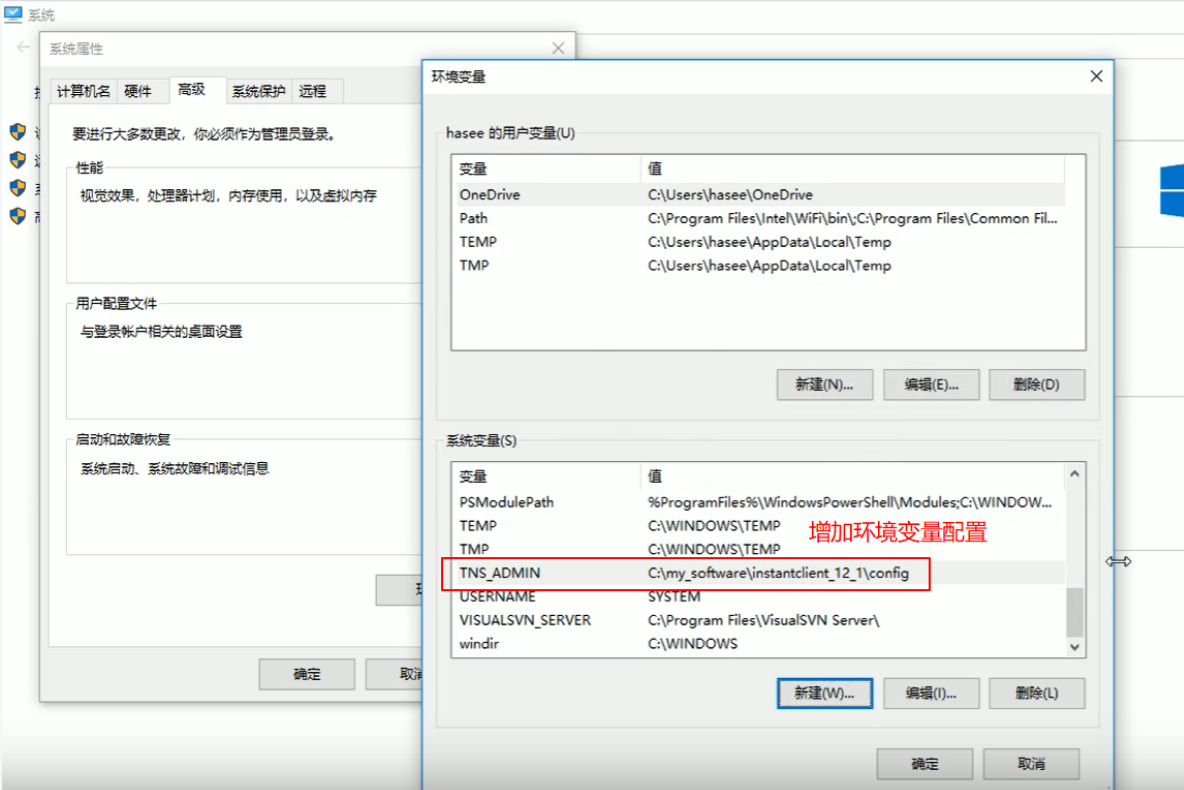
配置完环境变量之后在继续登录PL/SQL去连接Oracle数据库就可以使用ORCL去连接数据库了。
2.Oracle体系结构
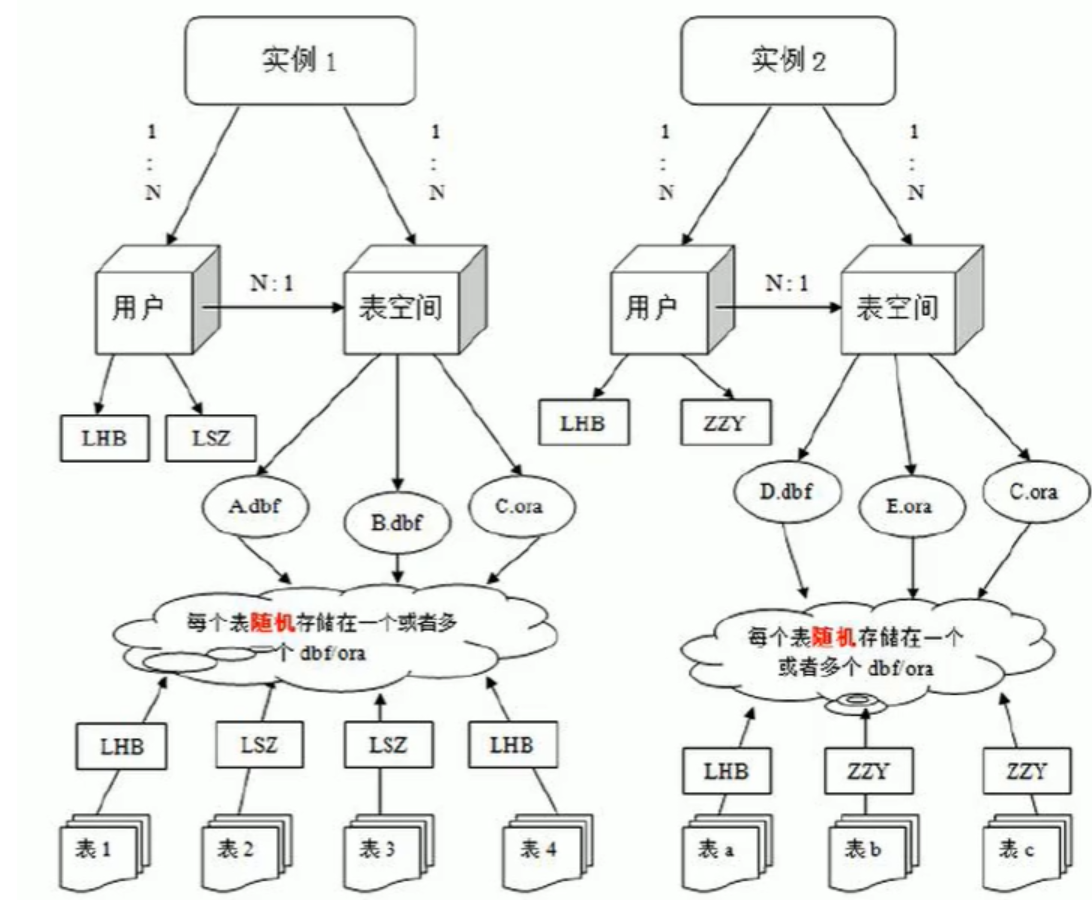
2.1.数据库
Oracle数据库是数据的物理存储。这就包括(数据文件ORA或者DBF、控制文件、联机日志、参数文件)。其实Oracle数据库的概念和其它数据库不一样,这里的数据库是一个操作系统只有一个库。可以看作是Oracle就只有一个大数据库。
2.2.实例
一个Oracle实例(Oracle Instance)有一系列的后台进程(Background Processes)和内存结构(Memory Structures)组成。一个数据库可以有n个实例。
2.3.用户
用户是在实例下建立的。不同实例可以建相同名字的用户。
2.4.表空间
表空间是Oracle对物理数据库上相关数据文件(ORA或者DBF文件)的逻辑映射。一个数据库在逻辑上被划分成一到若干个表空间。每个表空间包含了在逻辑上相关的一组结构。每个数据库至少有一个表空间(称之为system表空间)。
每个表空间由同一磁盘上的一个或多个文件组成。这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。
2.5.数据文件(dbf、ora)
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个或者多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于一个表空间。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除所属于的表空间才行。
注意:表的数据,是有用户放入某一个表空间的,而这个表空间会随机把这些表数据放到一个或者多个数据文件中。
由于oracle的数据库不是普通的概念,oracle是有用户和表空间对数据进行管理和存放的。但是表不是有表空间去查询的,而是由用户去查的。因为不同用户可以在同一个表空间建立同一个名字的表!这里区分就是用户了。
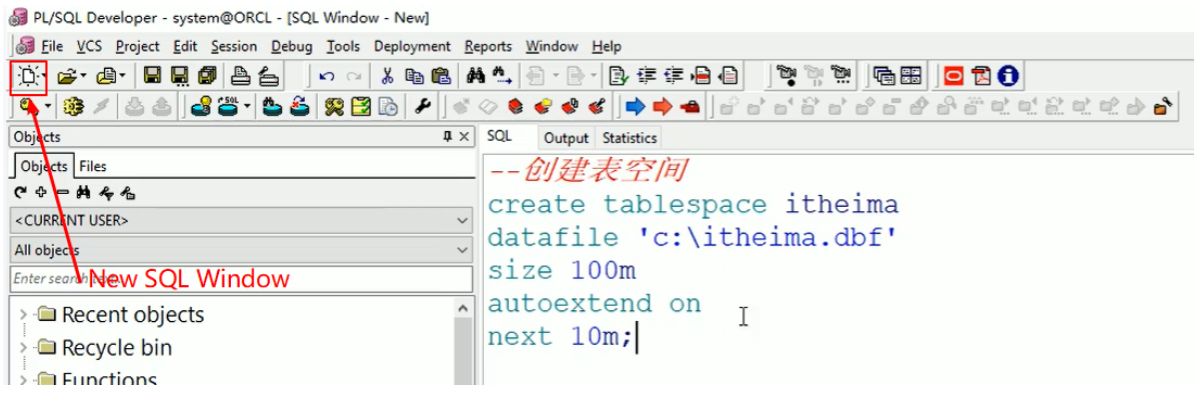
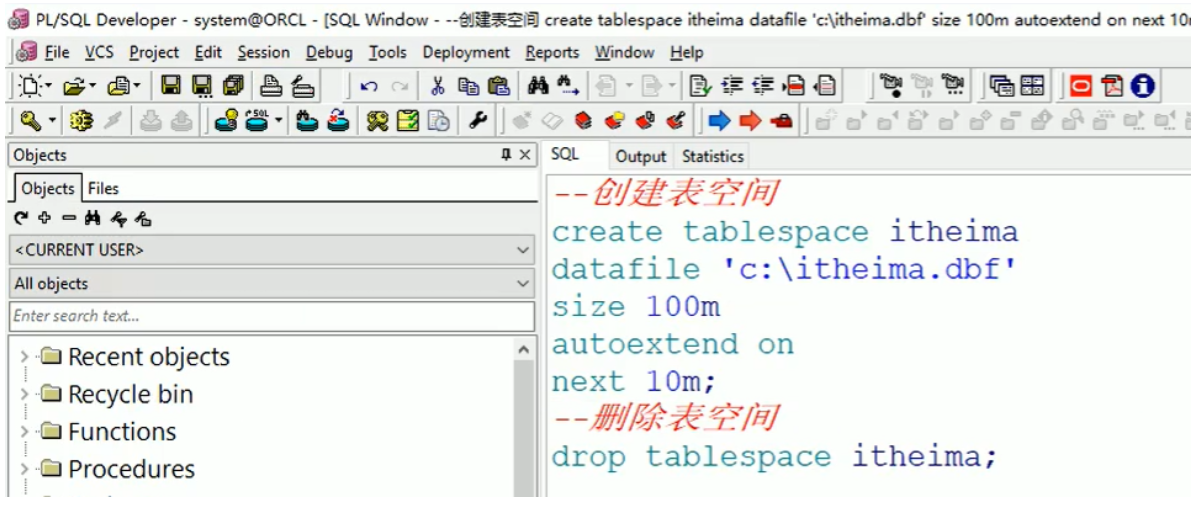
3.创建表空间
表空间是Oracle数据库的逻辑单元。数据库--表空间,一个表空间可以与多个数据文件(物理结构)关联。
一个数据库下可以建立多个表空间,一个表空间可以建立多个用户、一个用户下可以建立多个表。
create tablespace mytable datafile 'c:\mytable.dbf' size 100m autoextend on next 10m
其中
mytable:为表空间名称
datafile:指定表空间对应的数据文件
size:后定义的是表空间的初始大小
autoextend on:自动增长,当表空间存储都占满时,自动增长
next:后指定的是一次自动增长的大小
编写好sql语句之后,点击小齿轮按钮,Excute执行即可。
如下语句是创建表空间语句:
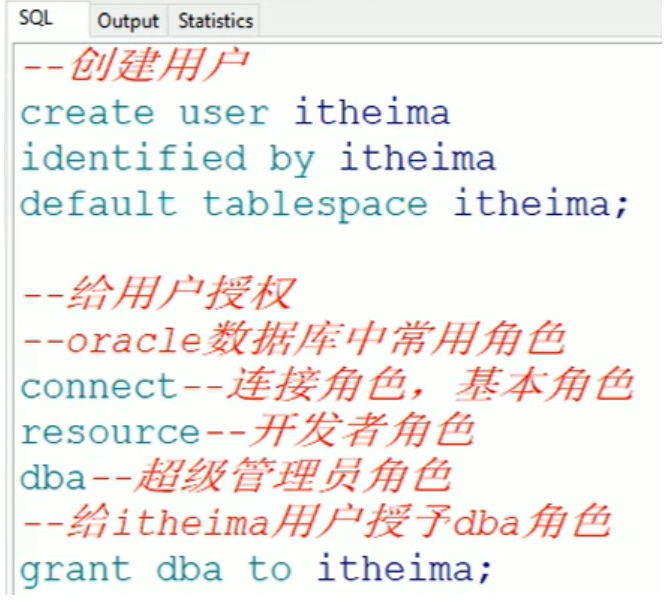
4.用户
创建用户并给用户授权:
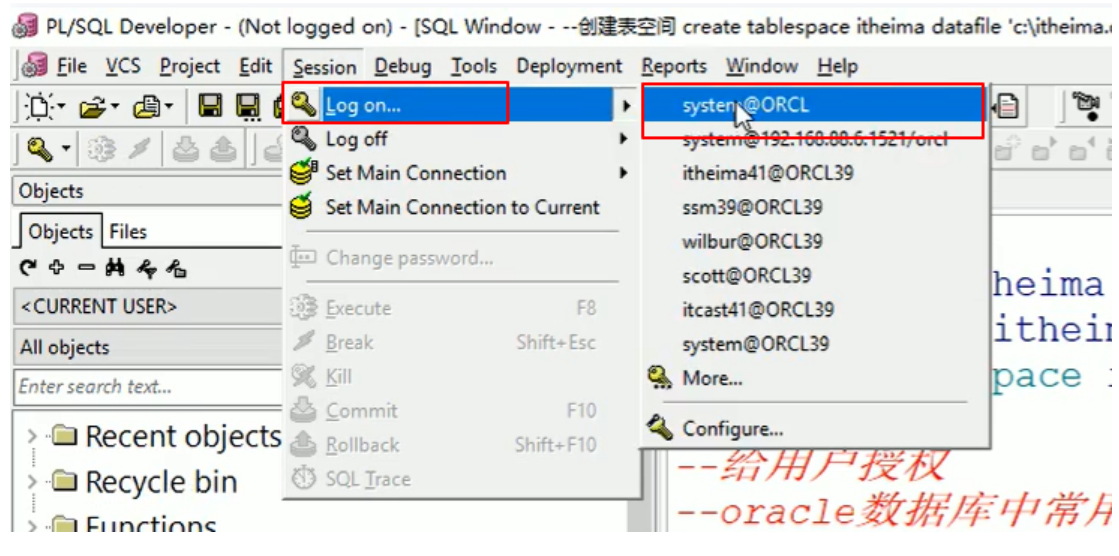
切换登录用户:
先选择Log off进行退出当前用户,再选择Log on进行登录;修改登录用户名与密码进行登录即可;
| No | 数据类型 | 描述 |
|---|---|---|
| 1 | varchar,varchar2 | 表示一个字符串,可变长度,常用的类型是varchar2 |
| 2 | NUMBER | NUMBER(n)表示一个整数,长度是n |
| 3 | NUMBER | NUMBER(m, n)表示一个小数,总长度是m,小数是n,整数是m-n |
| 4 | DATA |
表示日期类型 |
| 5 | CLOB | 大对象,表示大文本数据类型,可存4G |
| 6 | BLOB | 大对象,表示二进制数据,可存4G |
6.表的管理
6.1.建表
语法:
create table 表名(
字段1 数据类型 [default 默认值],
字段2 数据类型 [default 默认值],
...
)
示例:

6.2.修改表结构
添加一列数据,如果多列数据使用(n1, n2):
--- 修改表结构 --- 添加一列 alter table person add (gender number(1));
添加之后查看表结构:
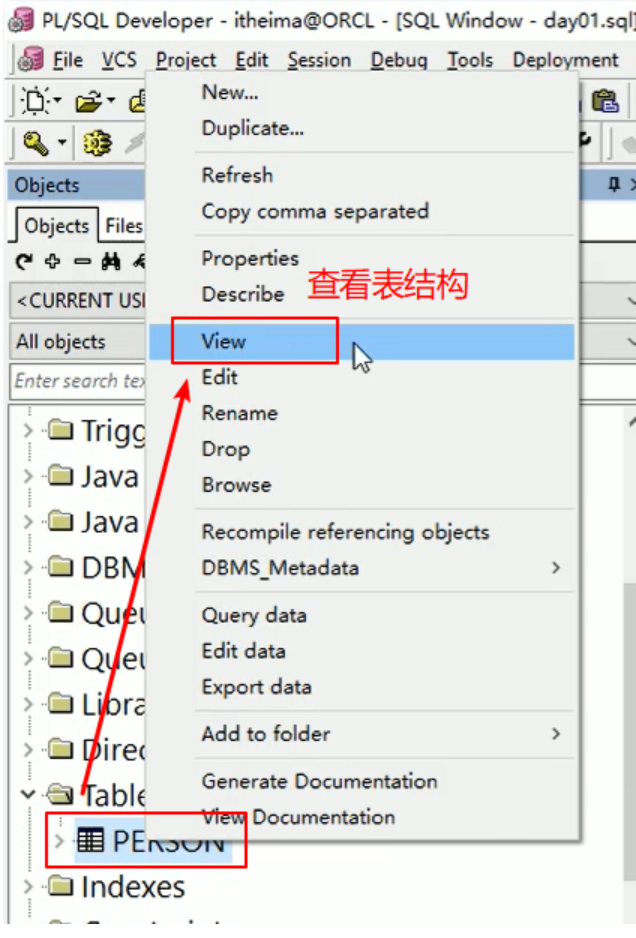
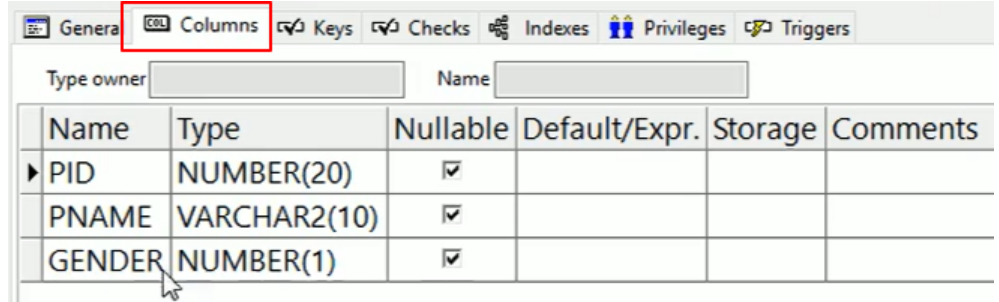
修改列类型:
---修改列类型 alter table person modify gender char(1);
修改列名称:
---修改列名称 alter table person rename column gender to sex;
删除一列:
---删除一列 alter table person drop column sex;
6.3.数据的增删改
添加数据insert:
---添加一条记录 insert into person(pid, pname) values (1, '小明'); commit
修改数据update:
---修改一条记录 update person set pname = '小马' where pid = 1; commit;
删除表数据delete/truncate/drop:
---三个删除 ---删除表中全部记录 delete from person; ---删除表结构 drop table person; ---先删除表,再次创建表。效果等同于删除表中全部记录 ---在数据量大的情况下,尤其在表中带有索引的情况下,该操作效率高。 ---索引可以提供查询效率,但是会影响增删改效率 truncate table person;
---序列不真的属于任何一张表,但是可以逻辑和表做绑定 ---序列:默认从1开始,依次递增,主要用来给主键赋值使用 ---dual:虚表,只是为了补全语法,没有任何意义 create sequence s_person; select s person.currval from dual; ---添加一条记录 insert into person (pid, pname) values (s_person.nextval, '小明'); commit; select * from person;
6.5.Scott用户介绍
scott是给初学者学习的用户,学习者可以用Scott登录系统,注意scott用户登录后,就可以使用Oracle提供的数据库和数据表,这些都是oracle提供的,学习者不需要自己创建数据库和数据表,直接使用这些数据库和数据表练习SQL。
---scott用户,密码是tiger ---解锁scott用户 alter user scott account unlock; ---解锁scott用户的密码【此句也可以用来重置密码】 alter user scott identified by tiger;
7.Oracle查询
7.1.单行/多行函数
单行函数:作用于一行,返回一个值。
多行函数:作用于多行,返回一个值。
字符函数
select upper('yes') from dual; -- YES select lower('YES') from dual; -- yes
数值函数
select round(26.16, 1) from dual; -- 四舍五入,后面的参数表示保留的位数,结果26.2 select round(26.16, -1) from dual; -- 往前保留一位小数,结果30 select trunc(56.16, 1) from dual; -- 直接截取,不再看后边位数的数字是否大于5。56.1 select mod(10, 3) from dual; -- 求余数
日期函数
---查询出emp表中所有员工入职距离现在几天 select sysdate-e.hiredate from emp e; ---算出明天此刻 select sysdate+1 from dual; ---查询出emp表中所有员工入职距离现在几月 select months_between(sysdate, e.hiredate) from emp e; ---查询出emp表中所有员工入职距离现在几年 select months_between(sysdate, e.hiredate)/12 from emp e; ---查询出emp表中所有员工入职距离现在几周 select round((sysdate-e.hiredate)/7) from emp e;
转换函数
日期转换成字符串
注意:fm表示如果是"04"格式前面会自动省略0,展示为"4";
---转换函数 select to_char(sysdate, 'fm yyyy-mm-dd hh24:mi:ss') from dual;

字符串转日期
---字符串转日期 select to_date('2018-6-7 16:39:50', 'fm yyyy-mm-dd hh24:mi:ss') from dual;
多行函数(聚合函数)
---多行函数【聚合函数】:作用于多行,返回一个值。 select count(1) from emp; ---查询总数量 select sum(sal) from emp; ---工资总和 select max(sal) from emp; ---最大工资 select min(sal) from emp; ---最低工资 select avg(sal) from emp; ---平均工资
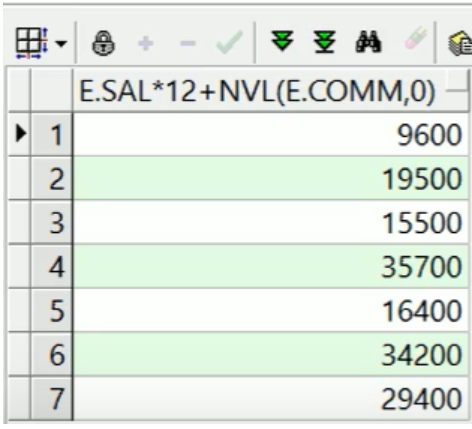
--- 通用函数 --- 算出emp表中所有员工的年薪 --- 奖金里面有null值,如果null值和任意数字做算术运算,结果都是null select e.sal*12+nvl(e.comm, 0) from emp e;
计算结果:
7.3.条件表达式
以下两种表达式为mysql、oracle通用表达式:
第一种:
---条件表达式 ---给emp表中员工起中文名 select e.ename, case e.ename when 'SMITH' then '曹贼' when 'ALLEN' then '大耳贼' when 'WARD' then '诸葛小儿' else '无名' --- 注意:如果else不写则为null end from emp e;
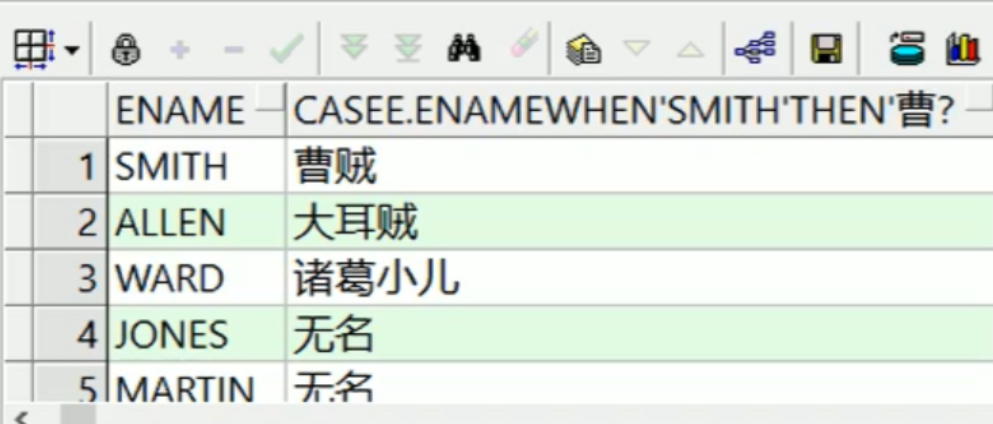
第二种:
---判断emp表中员工工资,如果高于3000显示高收入;如果高于1500低于3000显示中等收入;其余显示低收入 select e.sal, case when e.sal>3000 then '高收入' when e.sal>1500 then '中等收入' else '低收入' end from emp e;
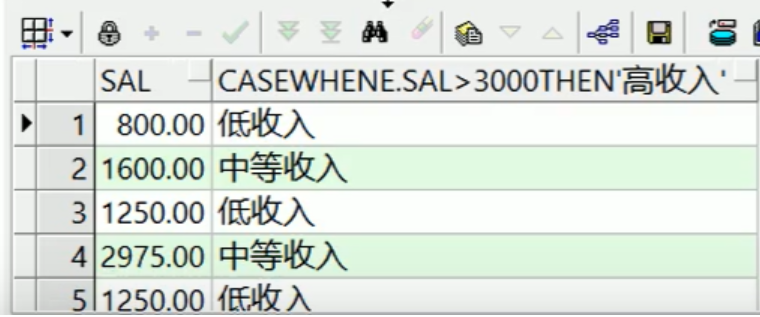
其中"中文名"为别名,别名使用双引号,其余都用单引号。
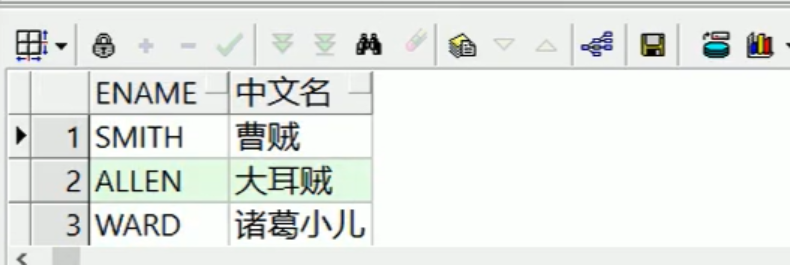
---oracle专用条件表达式 select e.ename, decode(e.ename, 'SMITH', '曹贼', 'ALLEN', '大耳贼', 'WARD', '诸葛小儿', '无名') 中文名 from emp e;
---分组查询 ---查询出每个部门的平均工资 ---分组查询中,出现在group by 后面的原始列,才能出现在select后面 ---没有出现在group by后面的列,想在select后面,必须加上聚合函数 ---聚合函数有一个特性,可以把多行记录变成一个值 select e.deptno, avg(e.sal) from emp e group by e.deptno;
别名问题:
---查询出平均工资高于2000的部门信息 select e.deptno, avg(e.sal) asal from emp e group by e.deptno having avg(e.sal)>2000; ---所有条件都不能使用别名来判断 ---比如下面的条件语句也不能使用别名当条件 select ename, sal s from emp where sal>1500;
分组group by与having问题:
---where是过滤分组前的数据,having是过滤分组后的数据 ---表现形式:where必须在group by之前,having是在group by之后 ---查询出每个部门工资高于800的员工的平均工资 ---然后再查询出平均工资高于2000的部门 select e.deptno, avg(e.sal) asal from emp e where e.sal>800 group by e.deptno having avg(e.sal)>2000;
7.5.多表连接查询
left join、right join、inner join
oracle中特有的连接方式,(+)在的地方表示right join等同
---oracle中专用外连接 select * from emp e, dept d where e.deptno(+) = d.deptno;
---查询出员工姓名,员工领导姓名 ---自连接:自连接其实就是站在不同的角度把一张表看成多张表 select e1.ename, e2.ename from emp e1, emp e2 where e1.mgr = e2.empno;
---rownum行号:当我们做select操作的时候, ---没查询出一行记录,就会在该行上加上一个行号, ---行号从1开始,依次递增,不能跳着走 ---emp表工资倒叙排列后,每页五条记录,查询第二页 ---排序操作会影响rownum的顺序 select rownum, e.* from emp e order by e.sal desc ---如果涉及到排序,但是还要使用rownum的话,我们可以再次嵌套查询 select rownum, t.* from( select rownum, e.* from emp e order by e.sal desc) t;

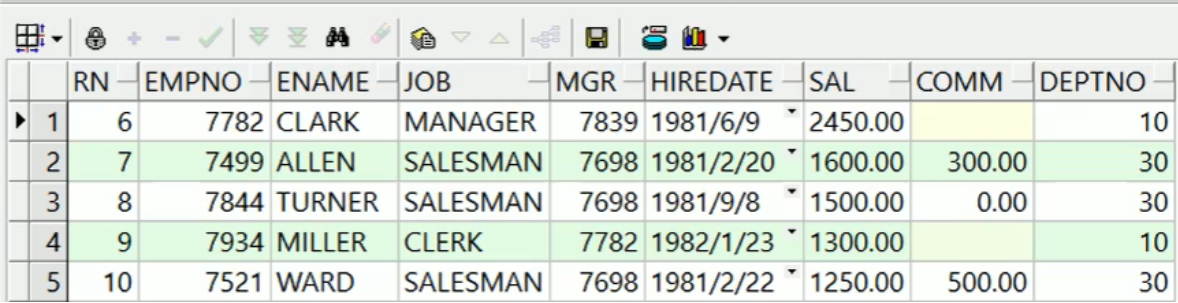
分页查询固定格式:
---emp表工资倒叙排列后,每页五条记录,查询第二页 ---rownum行号不能写上大于一个正数 select * from( select rownum rn, tt.* from( select * from emp order by sal desc ---这里可以写需要进行分页的数据 ) tt where rownum < 11 ) where rn > 5;
8.Oracle视图
视图:视图就是提供一个查询的窗口,所有数据来自于原表。
-- 查询语句创建表 create table emp as select * from scott.emp; select * from emp; -- 创建视图【必须有dba权限】 create view v_emp as select ename, job from emp; -- 查询视图 select * from v_emp; -- 修改视图[不推荐] update v_emp set job ='CLERK' where ename = 'ALLEN'; commit; -- 创建只读视图 create view v_emp as select ename, job from emp with read only;
视图的作用:
第一:视图可以屏蔽掉一些敏感字段;
第二:保证总部和分部数据及时统一;
9.Oracle索引
索引:索引就是在表的列上构建一个二叉树,达到大幅度提高查询效率的目的,但是索引会影响增删改的效率。
索引分为:单列索引与复合索引。
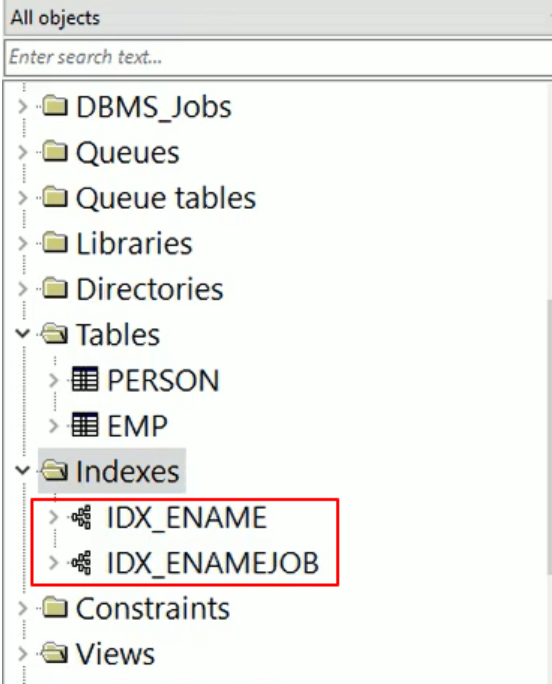
-- 创建单列索引 create index idx_ename on emp(ename); -- 单列索引触发规则,条件必须是索引列中的原始值 -- 单行函数,模糊查询,都会影响索引的触发 select * from emp where ename = "SOCTT"; -- 复合索引 -- 创建复合索引 create index idx_enamejob on emp(ename, job); -- 复合索引中第一列为优先检索列 -- 如果要触发复合索引,必须包含有优先检索列中的原始值 select * from emp where ename = 'SCOTT' and job = 'XX'; -- 触发复合索引 select * from emp where ename = 'SCOTT' or job = 'XX'; -- 不触发索引 select * from emp where ename = 'SCOTT'; -- 触发单列索引
创建结果如下:
10.PL/SQL编程语言
pl/sql编程语言是对sql语言的扩展,使得sql语言具有过程化编程的特性。
pl/sql编程语言比一般的过程化编程语言,更加灵活高效。
pl/sql编程语言主要用来编写存储过程和存储函数等。
10.1.pl/sql编程基础语法
--- 声明方法 --- 赋值操作可以使用:=也可以使用into查询语句赋值 declare i number(2) := 10; s varchar2(10) := '小明'; ena emp.ename%type; ---引用型变量 emprow emp%rowtype; ---记录型变量 begin dbms_output.put_line(i); dbms_output.put_line(s); select ename into ena from emp where empno = 7788; dbms_output.put_line(ena); select * into emprow from emp where empno = 7788; dbms_output.put_line(emprow.ename || '的工作为:' || emprow.job) end;
--- 输入小于18的数字,输出未成年 --- 输入大于18小于40的数字,输出中年人 --- 输入大于40的数字,输出老年人 declare i number(3) := ⅈ begin if i<18 then dbms_output.put_line('未成年'); elsif i<40 then dbms_output.put_line('中年人'); else dbms_output.put_line('老年人'); end if; end;
--- pl/sql中的loop循环 --- 用三种方式输出1到10是个数字 --- while循环 declare i number(2) := 1; --- 定义变量并赋值 begin while i<11 loop dbms_output.put_line(i); i := i+1; end loop end; --- exit循环 declare i number(2) := 1; begin loop exit when i > 10; dbms_output.put_line(i); i := i+1; end loop; end; --- for循环 declare begin for i in 1..10 loop dbms_output.put_line(i); end loop; end;
10.4.pl/sql游标
--- 输出emp表中所有员工的姓名 declare cursor c1 is select * from emp; emprow emp%rowtype; begin open c1; loop fetch c1 into emprow; exit when c1%notfound; dbms_output.put_line(emprow.ename); end loop; close c1; end; --- 给指定部门员工涨工资 declare cursor c2(eno emp.deptno%type) is select empno from emp where deptno = eno; en emp.empno%type; begin open c2(10); loop fetch c2 into en; exit when c2%notfound; update emp set sal=sal+100 where empno = en; commit; end loop; close c2; end;
10.5.存储过程
存储过程:存储过程就是提前已经编译好的一段pl/sql语言,放置在数据库中。
--- 给指定员工涨100块钱 --- 使用or replace create or replace procedure p1(eno emp.empno%type) is begin update emp set sal=sal+100 where empno = eno; commit; end; --- 测试p1 declare begin p1(7788); end;
--- 通过存储函数实现计算指定员工的年薪 --- 存储过程和存储函数的参数都不能带长度 --- 存储函数的返回值类型不能带长度 create or replace function f_yearsal(eno emp.empno%type) return number is s number(10); begin select sal*12+nvl(comm, 0) into s from emp where empno = eno; return s; end; ---测试f_yearsql ---存储函数在调用的时候,返回值需要接收 declare s number(10); begin s:= f_yearsal(7788); dbms_output.put_line(s); end; ---out类型参数如何使用 out类型参数使用: ---使用存储过程来算年薪 create or replace procedure p_yearsal(eno emp.empno%type, yearsal out number) is s number(10); c emp.comm%type; begin select sal*12, nvl(comm, 0) into s, c from emp where empno = eno; yearsal := s+c; end; ---测试p_yearsal declare yearsal number(10); begin p_yearsal(7788, yearsal); dbms_output.put_line(yearsal); end; ---in和out类型参数的区别是什么? ---凡是涉及到into查询语句赋值或者:=赋值操作的参数,都必须使用out来修饰
语法区别:关键字不一样;存储函数比存储过程多了两个return
本质区别:存储函数有返回值,而存储过程没有返回值。
如果存储过程想实现有返回值的业务,我们就必须使用out类型的参数。即便是存储过程使用了out类型的参数,其本质也不是真的有了返回值。而是在存储过程内部给out类型参数赋值,在执行完毕后,我们直接拿到输出类型参数的值。
我们可以使用存储函数有返回值的特性,来自定义函数。
而存储过程不能用来自定义函数。
--- 案例需求:查询出员工姓名,员工所在部门名称 --- 案例准备工作:把scott用户下的dept表复制到当前用户下 create table dept as select * from scott.dept; --- 使用传统方式来实现案例需求 select e.ename, d.dname from emp e, dept d where e.deptno = d.deptno; ---使用存储函数来实现提供一个部门编号,输出一个部门名称 create or replace function fdna(dno dept.deptno%type) return dept.dname%type is dna dept.dname%type; begin select dname into dna from dept where deptno = dno; return dna; end; --使用fdna存储函数来实现案例需求:查询出员工姓名,员工所在部门名称 select e.ename, fdna(e.deptno) from emp e;
10.6.触发器
触发器:就是指定一个规则,在我们做增删改操作的时候,主要满足该规则,自动触发,无需调用。
触发器分为:语句级触发器、行级触发器
语句级触发器:不包含有for each row的触发器。
行级触发器:包含有for each row的行级触发器。
--- 语句级触发器 --- 插入一条记录,输出一个新员工入职 create or replace trigger t1 after insert on person declare begin dbms_output.put_line('一个新员工入职'); end; ---触发t1 insert into person values (1, '小红'); commit; select * from person;
--- 行级触发器 --- 不能给员工降薪 --- raise_application_error(-20001~20999之间, '错误提示信息'); create or replace trigger t2 before update on emp for each row declare begin if :old.sal > :new.sal then raise_application_error(-20001, '不能给员工降薪'); end if; end; ---触发t2 select * from emp where empno = 7788; update emp set sal=sal-1 where empno = 7788; commit;
触发器实现主键自增:
用到的是行级触发器
--- 分析:在用户做插入操作之前,拿到即将插入的数据。给该数据中的主键列赋值 create or replace trigger auid before insert on person for each row declare begin select s_person.nextval into :new.pid from dual; end; ---查询person表数据 select * from person; ---使用auid实现主键自增 insert into person (pname) values ('a'); commit;
11.Java调用存储过程
11.1.Java调用Oracle存储过程环境准备
oracle10g使用ojdbc14.jar包;
1.创建Maven工程,导入以下依赖jar包:
<dependencies> <dependency> <groupId>com.oralce</groupId> <artifactId>ojdbc14</artifactId> <version>10.2.0.4.0</version> <scope>runtime</scope> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> <scope>test</scope> </dependency> </dependencies>
11.2.调用存储过程代码实现
String driverName = "oracle.jdbc.driver.OracleDriver";
String url = "jdbc:oracle:thin:@192.168.79.10:1521:orcl";
String username = "scott";
String password = "tiger";
1.执行查询操作:
@Test public void javaCallOracle() throws Exception { //加载数据库驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //得到Connection连接 Connection connection = DriverManager.getConnection("jdbc:oracle:thin:@192.168.88.6:1521:orcl", "scott", "tiger"); //得到预编译的Statement对象 PreparedStatement pstm = connection.prepareStatement("select * from emp where empno = ?"); //给参数赋值 pstm.setObject(1, 7788); //执行数据库查询操作 ResultSet rs = pstm.executeQuery(); //输出结果 while(rs.next()){ System.out.println(rs.getString("ename")); } //释放资源 rs.close(); pstm.close(); connection.close(); }
2.java调用存储过程:
/** * java调用存储过程 * {?= call <procedure-name>[(<arg1>,<arg2>, ...)]} 调用存储函数使用 * {call <procedure-name>[(<arg1>,<arg2>, ...)]} 调用存储过程使用 * @throws Exception */ @Test public void javaCallProcedure() throws Exception { //加载数据库驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //得到Connection连接 Connection connection = DriverManager.getConnection("jdbc:oracle:thin:@192.168.88.6:1521:orcl", "scott", "tiger"); //得到预编译的Statement对象 CallableStatement pstm = connection.prepareCall("{call p_yearsal(?, ?)}"); //给参数赋值 pstm.setObject(1, 7788); pstm.registerOutParameter(2, OracleTypes.NUMBER); //执行数据库查询操作 pstm.execute(); //输出结果[第二个参数] System.out.println(pstm.getObject(2)); //释放资源 pstm.close(); connection.close(); }
3.java调用存储函数
/** * java调用存储函数 * {?= call <procedure-name>[(<arg1>,<arg2>, ...)]} 调用存储函数使用 * {call <procedure-name>[(<arg1>,<arg2>, ...)]} 调用存储过程使用 * @throws Exception */ @Test public void javaCallFunction() throws Exception { //加载数据库驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //得到Connection连接 Connection connection = DriverManager.getConnection("jdbc:oracle:thin:@192.168.88.6:1521:orcl", "scott", "tiger"); //得到预编译的Statement对象 CallableStatement pstm = connection.prepareCall("{?= call f_yearsal(?)}"); //给参数赋值 pstm.setObject(2, 7788); pstm.registerOutParameter(1, OracleTypes.NUMBER); //执行数据库查询操作 pstm.execute(); //输出结果[第一个参数] System.out.println(pstm.getObject(1)); //释放资源 pstm.close(); connection.close(); }
本博客相关文档笔记均已上传至GitHub地址:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号