3.分布式一致性hash算法
1.分布式一致性Hash算法发展来源
-
一致性Hash算法常见使用场景
- 缓存
- ES
- Hadoop
- 分布式数据库
- Nginx(用一致性hash做负载均衡策略)
- Dubbo
- 客户端的负载均衡,可能选择一致性hash算法做负载均衡
-
分布式数据存储的场景下,为什么需要使用一致性hash算法?
- 以缓存为例,以空间换取时间,来提高数据访问的性能,环节数据库的压力
-
互联网公司分布式高并发系统有什么特点?
- 高并发
- 海量数据
- 特别是针对
2C的系统
-
高并发问题如何处理
- 应用集群
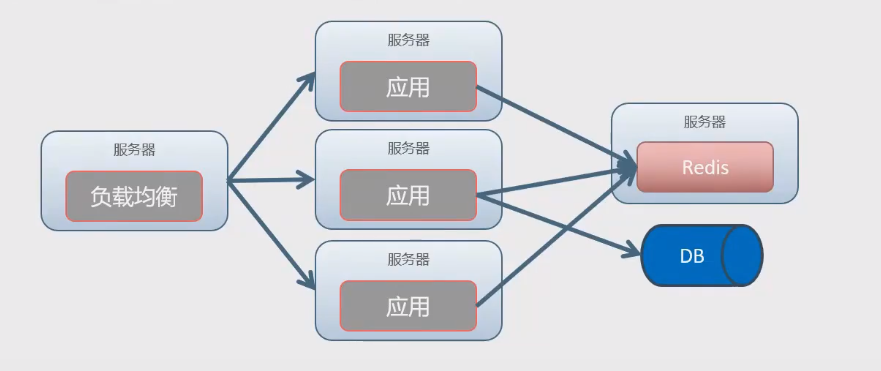
- 应用集群
像上图,应用服务虽然用到了集群,但是数据层反而是一个单机模型
- 单机缓存能扛起并发吗?
- Redis,Memcache的并发处理能力有多强?
- 很强:10W并发,因为他使用的是内存
- Redis,Memcache的并发处理能力有多强?
- 如果并发量达到30万怎么办?
- 缓存集群
- 海量数据对缓存有什么影响?会超出单机的存储上线,怎么办?
- 分布式缓存集群
- 数据如何均衡分布到缓存集群节点上?
均衡分布方式一:hash求余
- hash求余
- hash(key)%集群节点数

- hash(key)%集群节点数
- 缺点:不方便扩展集群,会导致原来存储的数据获取不到,因为算法被影响了,所以之前存储的数据也会被影响
- 增加一个节点后,有多大比例的数据缓存命不中
- 假如有3台集群,加一台,变成4台.将会有3/4的数据获取不到
- 假如有99台,加一台,变成100台,将会有99/100的数据获取不到
- 集群扩展的对系统会有什么影响
- 大量缓存命不中,就会访问数据库
- 瞬间失去了缓存的分压,数据库不堪重负,崩溃
- 缓存雪崩
2.均衡分布方式一:一致性hash算法
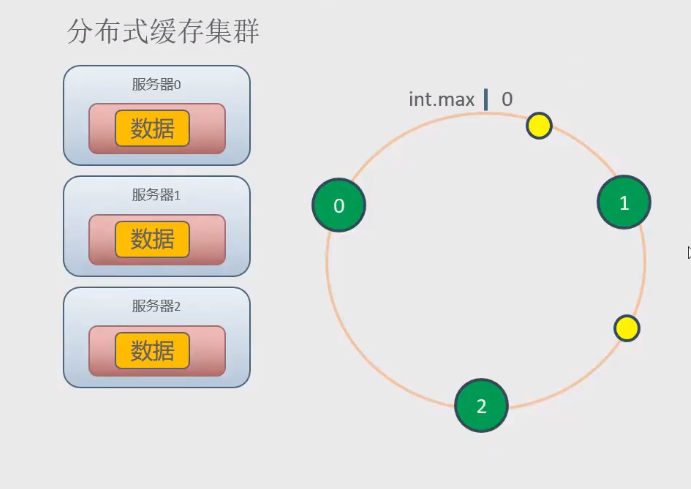
环为0-int的最大值,是一个值空间
- 1.hash值一个非负整数,把非负整数的值做成一个圆环
- 2.对集群的节点的某个属性求hash值(如节点名称),根据hash值把节点放到环上
- 3.对数据的key求hash,一样的把数据也放到环山,按顺时针方向,找离他最近的节点,就存储到这个节点上
增加一个节点影响如何?
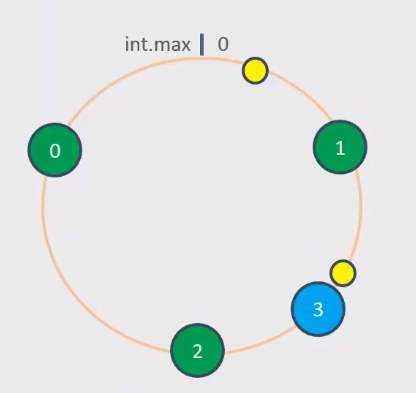
假如有三个节点,增加一个,影响的范围是 0-1/3,去一个中值,就是1/6
新增节点能够均衡缓解原有节点的压力吗?
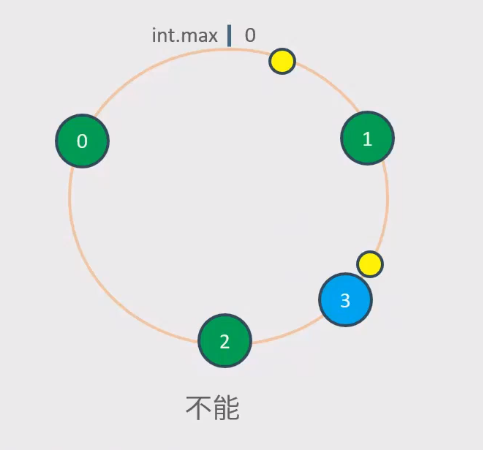
不能,假如类似上图,他只能缓解二号节点的压力
集群的节点一定会均衡的分布在环上吗?
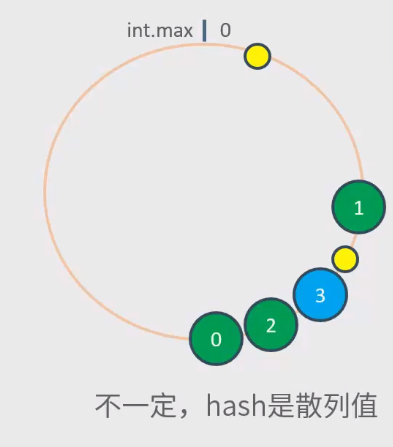
如何均衡分布,缓解压力?
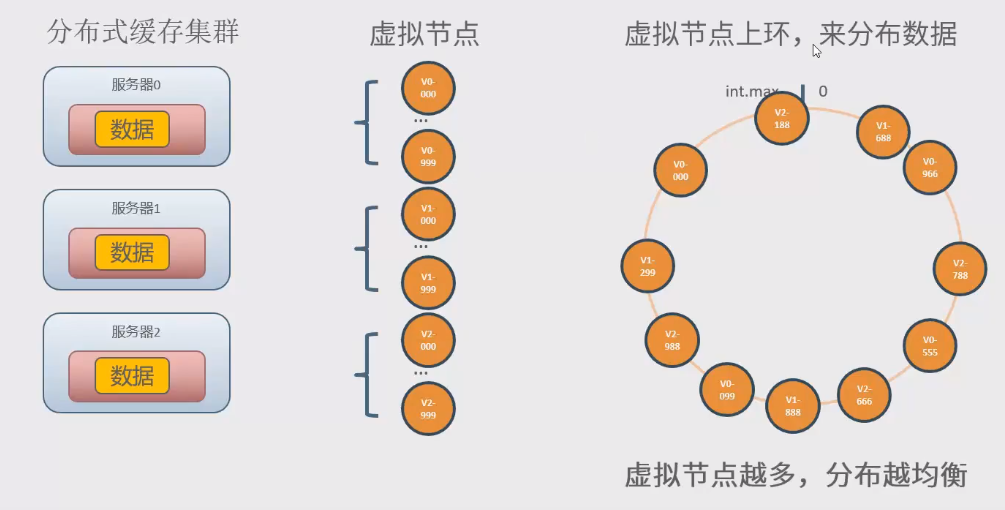
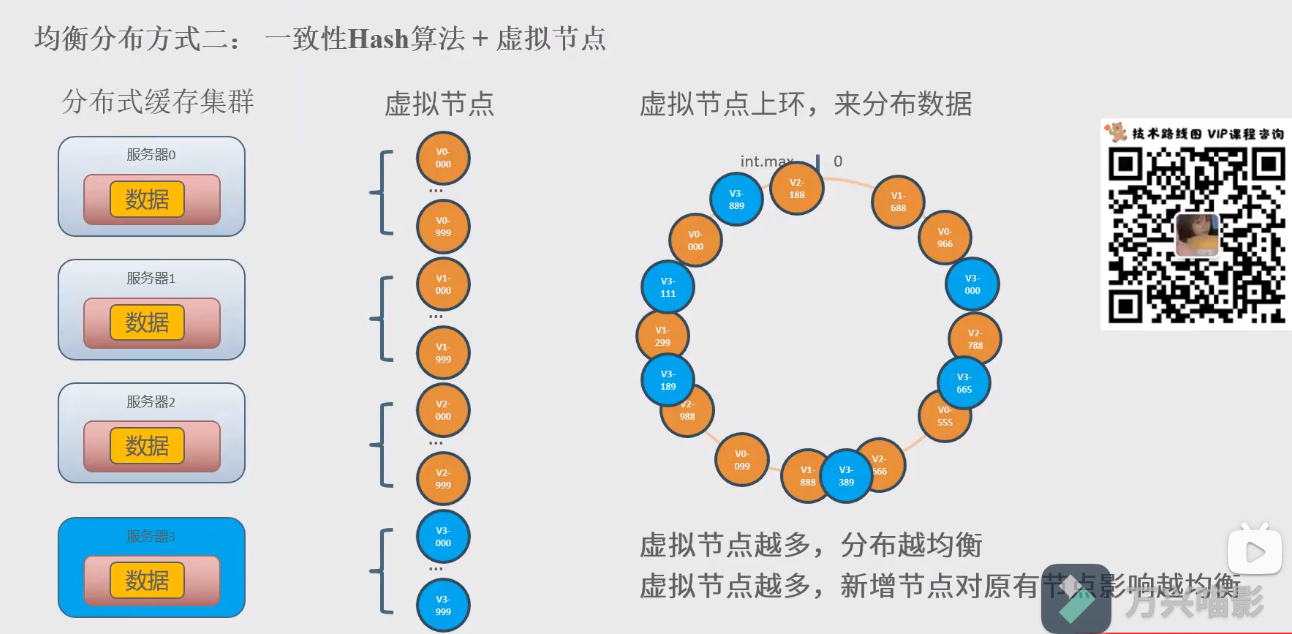
3.均衡分布方式二:一致性hash算法+虚拟节点
为每一个物理节点虚拟很多个虚拟节点,然后把虚拟节点放到换上,来分布数据,虚拟节点越多,就越均衡
增加一台服务器,对原有数据的影响
在dubbo框架中,也讲到了一致性hash算法,也使用到了一致性hash算法,虚拟节点的个数为150
由三个节点变为四个节点,将有1/4的缓存失效,所以从n个节点新增m个节点,将会有m/m+n个节点失效
在redis里,有一个槽的概念,共16384个,他这就是已经划分好了的虚拟节点
4.手写实现一致性Hash算法
- 要有物理节点
- 要有虚拟节点
- Hash算法
- 将虚拟节点放到环上
- 数据找到对应的虚拟节点
public class ConsistenceHash {
//物理节点{id,name,ip....}
private List<String> realNodes = new ArrayList<String>();
//虚拟节点的数量
private int virutalNums = 100;
//保存物理节点与虚拟节点的关系
private Map<String,List<Integer>> real2VirtualMap = new HashMap<String, List<Integer>>();
// Integer为hash值,String为物理节点,这里就是建立他们的对应关系,SortedMap排序存储结构-->环,用key做排序,并建立对应关系
private SortedMap<Integer,String> sorteMap = new TreeMap<Integer, String>();
public ConsistenceHash(int virutalNums) {
this.virutalNums = virutalNums;
}
//新增节点
public void addServer(String node){
this.realNodes.add(node);
//虚拟出指定数量的节点
int count = 0,i=0;
String vnode = null;
List<Integer> virutalNodes = new ArrayList<Integer>(this.virutalNums);
this.real2VirtualMap.put(node,virutalNodes);
while(count < this.virutalNums){
i++;
vnode = node + "--" + i;
//计算hash值
/**
* 这里直接使用java里面的hashCode(),他不够散列,会有负值,当然负值很好解决,主要就是不够散列
* 其他hash算法:CRC32_HASH,FNV1_32_HASH,KETAMA_HASH等,其中KETAMA_HASH是默认的memCache推荐的一致性Hash算法
*/
int hashvalue = FVN1_32_HASN.getHash(vnode);
//hash值会冲突,值相同,会被覆盖,所以如果集合中有,就会重新在做一次计算
if(sorteMap.containsKey(hashvalue)){
//保存物理节点与虚拟节点的对应关系
virutalNodes.add(hashvalue);
//虚拟节点放到换环上去 环在哪里???? 数据结构:红黑树
sorteMap.put(hashvalue,node);
count++;
}
}
}
//移除节点
public void removeServe(String node){
}
//取数据
public String getServer(String key){
int hash = FVN1_32_HASN.getHash(key);
//顺时针方向找,离她最近的
/**
* tailMap会拿到这个值后面的所有制,返回一个SortedMap,我们根据返回的结果取第一个值即可
*/
SortedMap<Integer, String> subMap = sorteMap.tailMap(hash);
if(subMap.isEmpty()){
return sorteMap.get(sorteMap.firstKey());
}else {
return subMap.get(subMap.firstKey());
}
}
public static void main(String[] args) {
ConsistenceHash consistenceHash = new ConsistenceHash(100);
consistenceHash.addServer("192.168.10.10");
consistenceHash.addServer("192.168.10.11");
consistenceHash.addServer("192.168.10.12");
for(int i = 0;i<10;i++){
System.out.println(i + "对应的服务器:" + consistenceHash.getServer("cdl"+i));
}
}
}
呀,是丹龙呀!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号