6. Redis
1.NoSQL的引言
RDBMS:关系型数据库
NoSql:非关系型数据库
由C语言编写
NoSQL(Not Only SQL ),意即不仅仅是SQL, 泛指非关系型的数据库。Nosql这个技术门类,早期就有人提出,发展至2009年趋势越发高涨。
2. 为什么是NoSQL
随着互联网网站的兴起,传统的关系数据库在应付动态网站,特别是超大规模和高并发的纯动态网站已经显得力不从心,暴露了很多难以克服的问题。如商城网站中对商品数据频繁查询、对热搜商品的排行统计、订单超时问题、以及微信朋友圈(音频,视频)存储等相关使用传统的关系型数据库实现就显得非常复杂,虽然能实现相应功能但是在性能上却不是那么乐观。nosql这个技术门类的出现,更好的解决了这些问题,它告诉了世界不仅仅是sql。
3. NoSQL的四大分类
3.1 键值(Key-Value)存储数据库
# 1.说明:
- 这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。
# 2.特点
- Key/value模型对于IT系统来说的优势在于简单、易部署。
- 但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。
# 3.相关产品
- Tokyo Cabinet/Tyrant,
- Redis ---> key value 内存
- SSDB ---> key value 硬盘
- Voldemort
- Oracle BDB
3.2 列存储数据库
# 1.说明
- 这部分数据库通常是用来应对分布式存储的海量数据。
# 2.特点
- 键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。
# 3.相关产品
- Cassandra、HBase、Riak.
3.3 文档型数据库
# 1.说明
- 文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高
# 2.特点
- 以文档形式存储
# 3.相关产品
- MongoDB、CouchDB、 MongoDb(4.x). 国内也有文档型数据库SequoiaDB,已经开源。
3.4 图形(Graph)数据库
# 1.说明
- 图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。
- NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。
# 2.特点
# 3.相关产品
- Neo4J、InfoGrid、 Infinite Graph、
4. NoSQL应用场景
- 数据模型比较简单
- 需要灵活性更强的IT系统
- 对数据库性能要求较高
- 不需要高度的数据一致性(Nosql对事务的支持都不是特别良好)
5. 什么是Redis
- 官方网站:https://redis.io/
- Redis 开源 遵循BSD 基于内存数据存储 被用于作为 数据库 缓存 消息中间件
- Redis 数据存在内存中,读写快,但是也有缺点,即断电即消失,所以就出现了持久化机制,将内存的数据,定期写入磁盘
- 总结: redis是一个内存型的数据库,缓存,消息中间件等
6.Redis特点
- Redis是一个高性能key/value内存型数据库
- Redis支持丰富的数据类型 (String,List,Set,ZSet,Hash)
- Redis支持持久化 内存数据持久化到硬盘中
- Redis单进程,单线程+异步(所以不会存在线程安全问题,并发问题),Redis实现分布式锁
分布式锁:当服务器做了集群之后,每一个应用都是一个独立的虚拟机,Synchronized关键字只能控制一个JAVA虚拟机里面的东西,当跨虚拟机之后,Synchronized关键字就解决不了线程安全的问题了,所以就需要一个独立于虚拟机以外的产品去解决
7.Redis安装
# 0.准备环境
- vmware15.x+
- centos7.x+
# 1.下载redis源码包
- https://redis.io/

# 2.下载完整源码包
- redis-4.0.10.tar.gz
# 3.将下载redis资料包上传到Linux中
# 4.解压缩文件
[root@localhost ~]# tar -zxvf redis-4.0.10.tar.gz
[root@localhost ~]# ll
# 5.安装gcc
- yum install -y gcc
# 6.进入解压缩目录执行如下命令
- make MALLOC=libc
# 7.编译完成后执行如下命令
- make install PREFIX=/usr/redis
# 8.进入/usr/redis目录启动redis服务
- ./redis-server
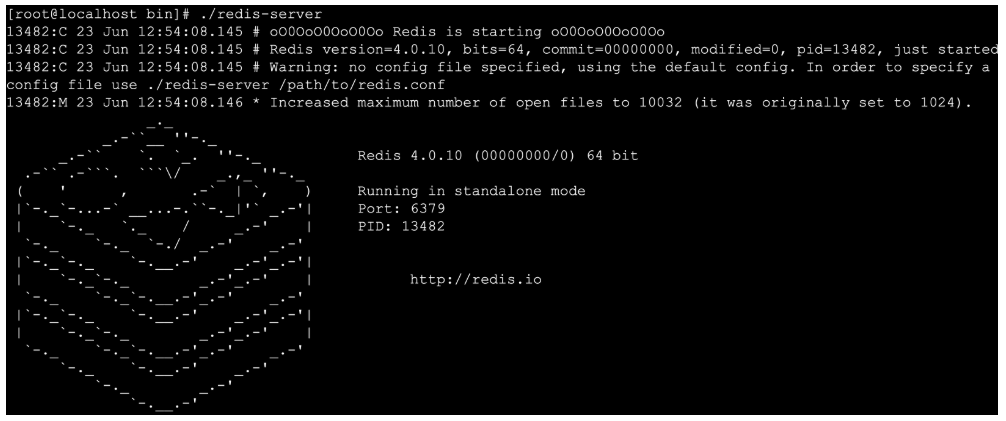
# 9.Redis服务端口默认是 6379
# 10.在新的窗口打开,进入redis的bin目录执行客户端连接操作
- ./redis-cli -h localhost –p 6379
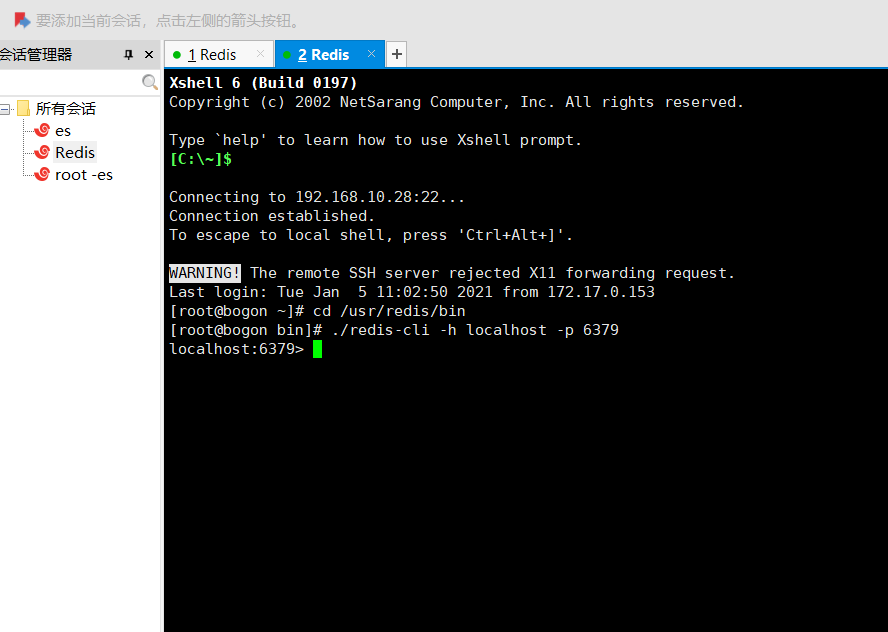
# 11.连接成功出现上面界面连接成功
8. Redis数据库相关指令
8.1 数据库操作指令
1.redis启动服务的细节
注意:直接使用./redis-server方式启动使用的是redis-server这个shell脚本中默认设置
2.如何在启动redis时指定配置文件启动
注意:默认在redis在安装完成之后,在安装目录没有配置文件,需要在源码目录中复制配置文件(redis.conf)到安装目录
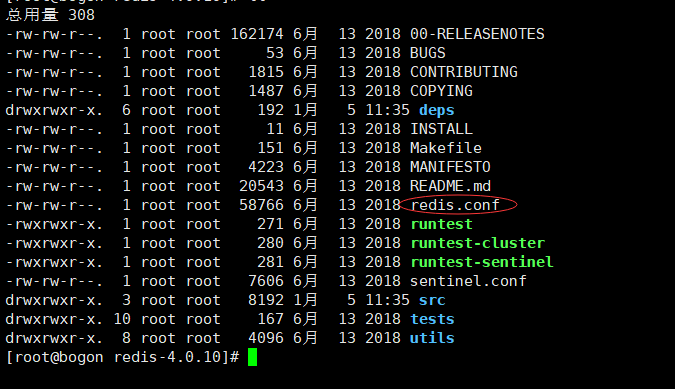
a.进入源码目录
cp redis.conf /usr/redis/
b.进入usr/redis安装目录查看配置文件
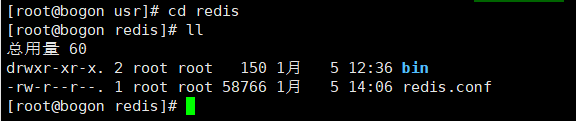
c.进入bin目录,加载配置启动(若配置文件没有做任何更改,直接使用./redis-server即可,若修改之后,则启动的时候需要使用自己的配置文件)
./redis-server ../redis.conf
3.例如:修改配置文件,修改默认端口号
vim redis.conf
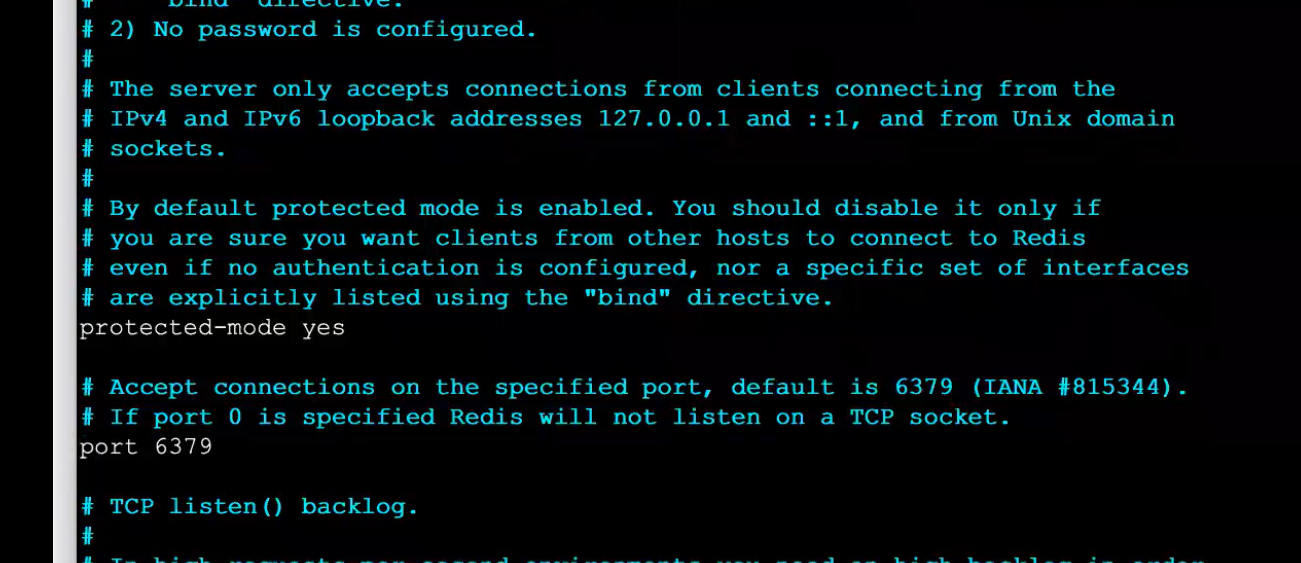
4.redis中库的概念
库:database 用来存放数据的基本单元 redis中每一个库都有一个唯一的名称(或编号,从0开始)
默认库的个数:16个库(0-15) 默认使用的是0号库(若果要修改redis中库的个数,直接修改redis.conf配置文件的database参数即可)
切换库命令:select + 库的编号
5.redis中清楚库的指令
- 清空当前的库 FLUSHDB
- 清空全部的库 FLUSHALL
8.2 操作key相关指令
# 1.DEL指令
- 语法 : DEL key [key ...]
- 作用 : 删除给定的一个或多个key 。不存在的key 会被忽略。
- 可用版本: >= 1.0.0
- 返回值: 被删除key 的数量。
# 2.EXISTS指令
- 语法: EXISTS key
- 作用: 检查给定key 是否存在。
- 可用版本: >= 1.0.0
- 返回值: 若key 存在,返回1 ,否则返回0。
# 3.EXPIRE
- 语法: EXPIRE key seconds
- 作用: 为给定key 设置生存时间,当key 过期时(生存时间为0 ),它会被自动删除。
- 可用版本: >= 1.0.0
- 时间复杂度: O(1)
- 返回值:设置成功返回1 。
# 4.KEYS
- 语法 : KEYS pattern
- 作用 : 查找所有符合给定模式pattern 的key 。
- 语法:
KEYS * 匹配数据库中所有key 。
KEYS h?llo 匹配hello ,hallo 和hxllo 等。
KEYS h*llo 匹配hllo 和heeeeello 等。
KEYS h[ae]llo 匹配hello 和hallo ,但不匹配hillo 。特殊符号用 "\" 隔开
- 可用版本: >= 1.0.0
- 返回值: 符合给定模式的key 列表。
# 5.MOVE
- 语法 : MOVE key db
- 作用 : 将当前数据库的key 移动到给定的数据库db 当中。
- 可用版本: >= 1.0.0
- 返回值: 移动成功返回1 ,失败则返回0 。
# 6.PEXPIRE
- 语法 : PEXPIRE key milliseconds
- 作用 : 这个命令和EXPIRE 命令的作用类似,但是它以毫秒为单位设置key 的生存时间,而不像EXPIRE 命令那样,以秒为单位。
- 可用版本: >= 2.6.0
- 时间复杂度: O(1)
- 返回值:设置成功,返回1 key 不存在或设置失败,返回0
# 7.PEXPIREAT
- 语法 : PEXPIREAT key milliseconds-timestamp
- 作用 : 这个命令和EXPIREAT 命令类似,但它以毫秒为单位设置key 的过期unix 时间戳,而不是像EXPIREAT那样,以秒为单位。
- 可用版本: >= 2.6.0
- 返回值:如果生存时间设置成功,返回1 。当key 不存在或没办法设置生存时间时,返回0 。(查看EXPIRE 命令获取更多信息)
# 8.TTL
- 语法 : TTL key
- 作用 : 以秒为单位,返回给定key 的剩余生存时间(TTL, time to live)。
- 可用版本: >= 1.0.0
- 返回值:
当key 不存在时,返回-2 。
当key 存在但没有设置剩余生存时间时,返回-1 。
否则,以秒为单位,返回key 的剩余生存时间。
- Note : 在Redis 2.8 以前,当key 不存在,或者key 没有设置剩余生存时间时,命令都返回-1 。
# 9.PTTL
- 语法 : PTTL key
- 作用 : 这个命令类似于TTL 命令,但它以毫秒为单位返回key 的剩余生存时间,而不是像TTL 命令那样,以秒为单位。
- 可用版本: >= 2.6.0
- 返回值: 当key 不存在时,返回-2 。当key 存在但没有设置剩余生存时间时,返回-1 。
- 否则,以毫秒为单位,返回key 的剩余生存时间。
- 注意 : 在Redis 2.8 以前,当key 不存在,或者key 没有设置剩余生存时间时,命令都返回-1 。
# 10.RANDOMKEY
- 语法 : RANDOMKEY
- 作用 : 从当前数据库中随机返回(不删除) 一个key 。
- 可用版本: >= 1.0.0
- 返回值:当数据库不为空时,返回一个key 。当数据库为空时,返回nil 。
# 11.RENAME
- 语法 : RENAME key newkey
- 作用 : 将key 改名为newkey 。当key 和newkey 相同,或者key 不存在时,返回一个错误。当newkey 已经存在时,RENAME 命令将覆盖旧值。
- 可用版本: >= 1.0.0
- 返回值: 改名成功时提示OK ,失败时候返回一个错误。
# 12.TYPE
- 语法 : TYPE key
- 作用 : 返回key 所储存的值的类型。
- 可用版本: >= 1.0.0
- 返回值:
none (key 不存在)
string (字符串)
list (列表)
set (集合)
zset (有序集)
hash (哈希表)
8.3 String类型
1. 内存存储模型
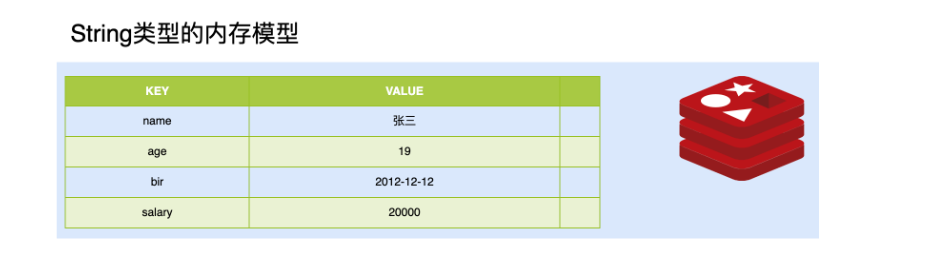
2. 常用操作命令
| 命令 | 说明 |
| ---- | ---- | ---- |
| set | 设置一个key/value |
| get | 根据key获得对应的value |
| mset | 一次设置多个key value |
| mget | 一次获得多个key的value |
| getset | 获得原始key的值,同时设置新值 |
| strlen | 获得对应key存储value的长度 |
| append | 为对应key的value追加内容 |
| getrange 索引0开始 | 截取value的内容 |
| setex | 设置一个key存活的有效期(秒) |
| psetex | 设置一个key存活的有效期(毫秒) |
| setnx | 存在不做任何操作,不存在添加 |
| msetnx原子操作(只要有一个存在不做任何操作)| 可以同时设置多个key,只有有一个存在都不保存|
| decr | 进行数值类型的-1操作 |
| decrby | 根据提供的数据进行减法操作 |
| Incr | 进行数值类型的+1操作 |
| incrby | 根据提供的数据进行加法操作 |
| Incrbyfloat | 根据提供的数据加入浮点数 |
8.4 List类型
list 列表 相当于java中list 集合 特点 元素有序 且 可以重复
1.内存存储模型
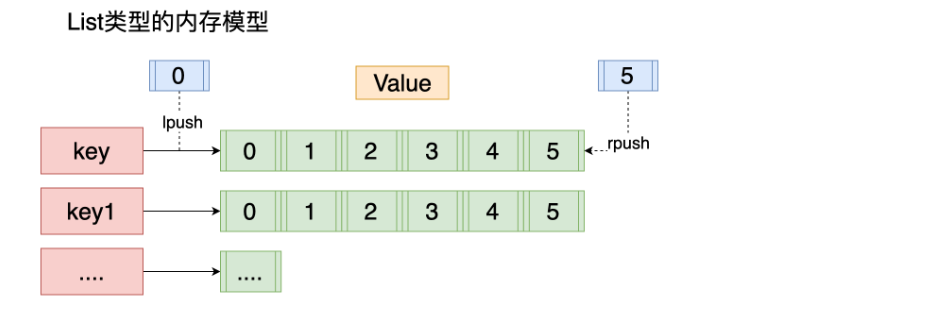
2.常用操作指令
| 命令 | 说明 |
| ---- | ---- | ---- |
| lpush | 将某个值加入到一个key列表头部 |
| lpushx | 同lpush,但是必须要保证这个key存在|
| rpush | 将某个值加入到一个key列表末尾 |
| rpushx |同rpush,但是必须要保证这个key存在|
| lpop |返回和移除列表左边的第一个元素 |
| rpop |返回和移除列表右边的第一个元素 |
| lrange |获取某一个下标区间内的元素 |
| llen |获取列表元素个数 |
| lset |设置某一个指定索引的值(索引必须存在) |
| lindex |获取某一个指定索引位置的元素 |
| lrem |删除重复元素 |
| ltrim | 保留列表中特定区间内的元素 |
| linsert |在某一个元素之前,之后插入新元素 |
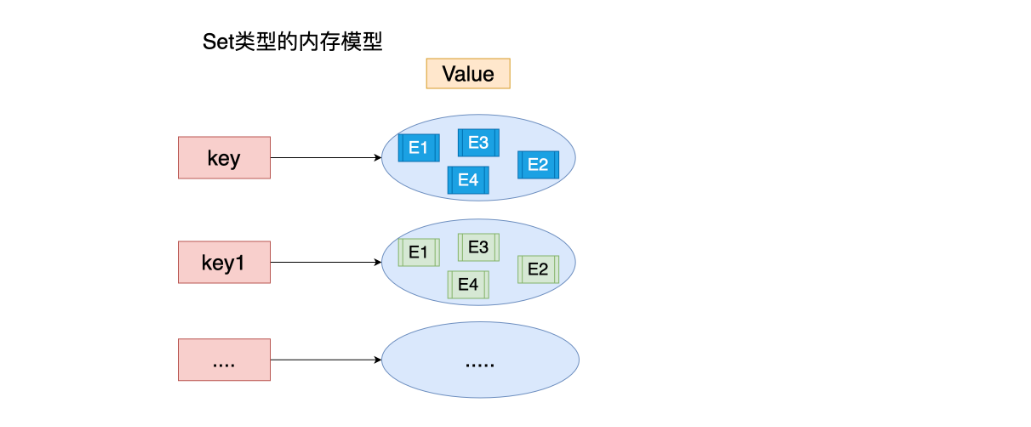
8.5 Set类型
特点: Set类型 Set集合 元素无序 不可以重复
1.内存存储模型
2.常用命令
| 命令 | 说明 |
| ---- | ---- | ---- |
| sadd |为集合添加元素 |
| smembers |显示集合中所有元素 无序 |
| scard |返回集合中元素的个数 |
| spop | 随机返回一个元素 并将元素在集合中删除 |
| smove | 从一个集合中向另一个集合移动元素 必须是同一种类型|
| srem | 从集合中删除一个元素 |
| sismember | 判断一个集合中是否含有这个元素 |
| srandmember| 随机返回元素 |
| sdiff | 去掉第一个集合中其它集合含有的相同元素 |
|sinter | 求交集 |
| sunion | 求和集 |
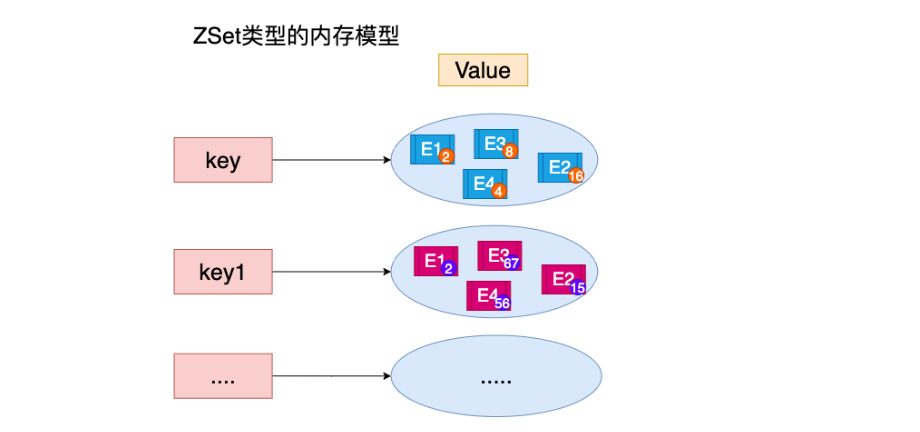
8.6 ZSet类型
特点: 可排序的set集合 排序 不可重复
ZSET 官方 可排序SET sortSet
1.内存模型
2.常用命令
| 命令 | 说明 |
| ---- | ---- | ---- |
| zadd | 添加一个有序集合元素 |
| zcard | 返回集合的元素个数 |
| zrange 升序 zrevrange 降序| 返回一个范围内的元素 |
| zrangebyscore | 按照分数查找一个范围内的元素|
| zrank | 返回排名 |
| zrevrank | 倒序排名 |
| zscore | 显示某一个元素的分数 |
|zrem | 移除某一个元素 |
| zincrby | 给某个特定元素加分 |
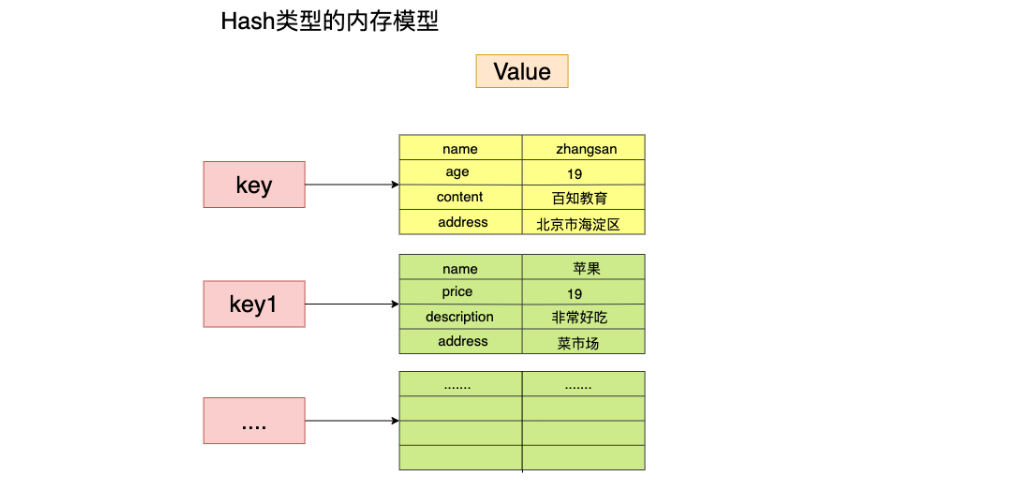
8.7 hash类型
特点: value 是一个map结构 存在key value key 无序的
1.内存模型
2.常用命令
|命令 | 说明 |
| ---- | ---- | ---- |
| hset | 设置一个key/value对 |
| hget | 获得一个key对应的value|
| hgetall | 获得所有的key/value对|
| hdel | 删除某一个key/value对|
| hexists | 判断一个key是否存在|
| hkeys | 获得所有的key |
| hvals | 获得所有的value |
| hmset | 设置多个key/value |
| hmget | 获得多个key的value |
| hsetnx | 设置一个不存在的key的值 |
| hincrby | 为value进行加法运算 |
| hincrbyfloat |为value加入浮点值 |
8.8.可视化工具使用
1.连接Redis
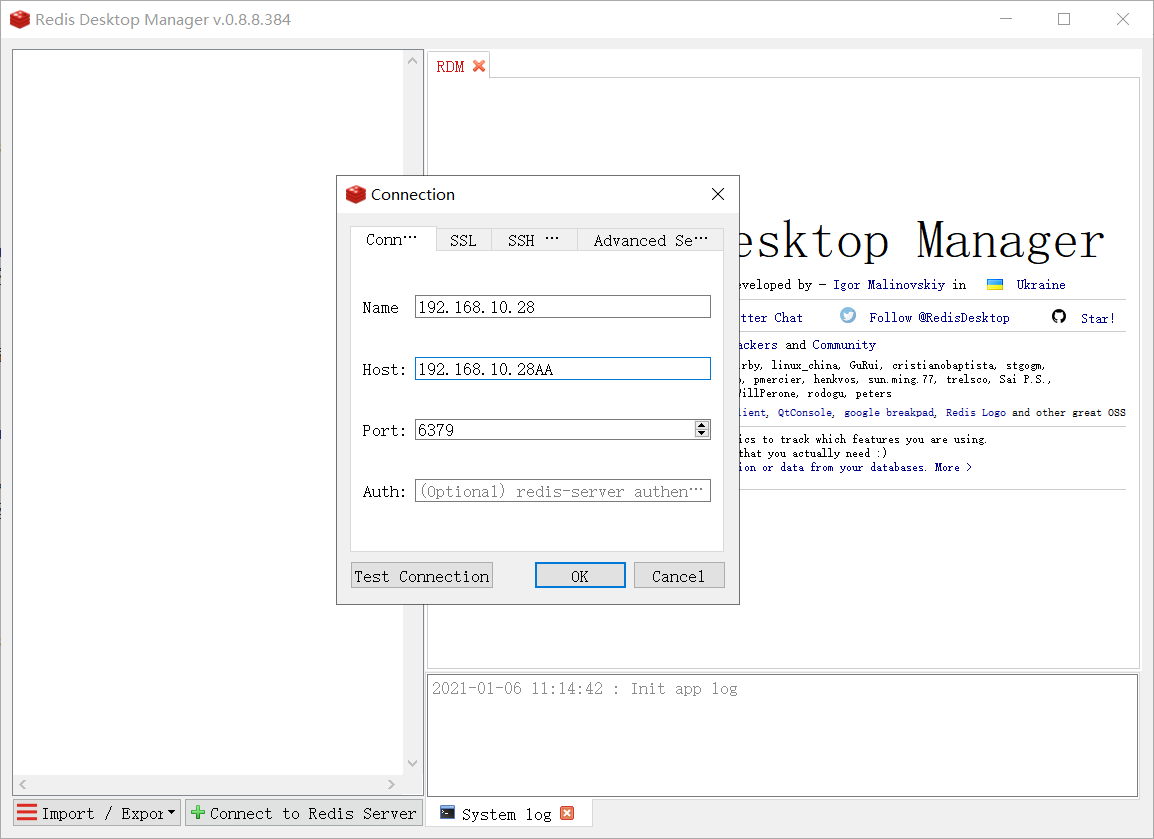
连接失败
2.开启redis远程连接
a.redis默认不允许远程连接,也就是拒绝所有的远程客户端连接(日后使用java操作redis也需要开启远程连接)
b.修改配置开启远程连接
vim redis.conf
将bind参数修改为0.0.0.0(允许所有的客户端连接)
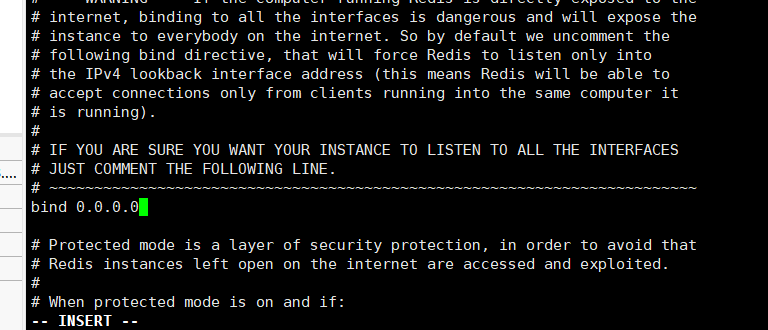
c.重启redis服务并需要再加配置文件启动
./redis-server ../redis.conf
3.连接成功(一定记住关闭防火墙)
9. 持久化机制
client redis[内存] -----> 内存数据- 数据持久化-->磁盘
Redis官方提供了两种不同的持久化方法来将数据存储到硬盘里面分别是:
- 快照(Snapshot)
- AOF (Append Only File) 只追加日志文件
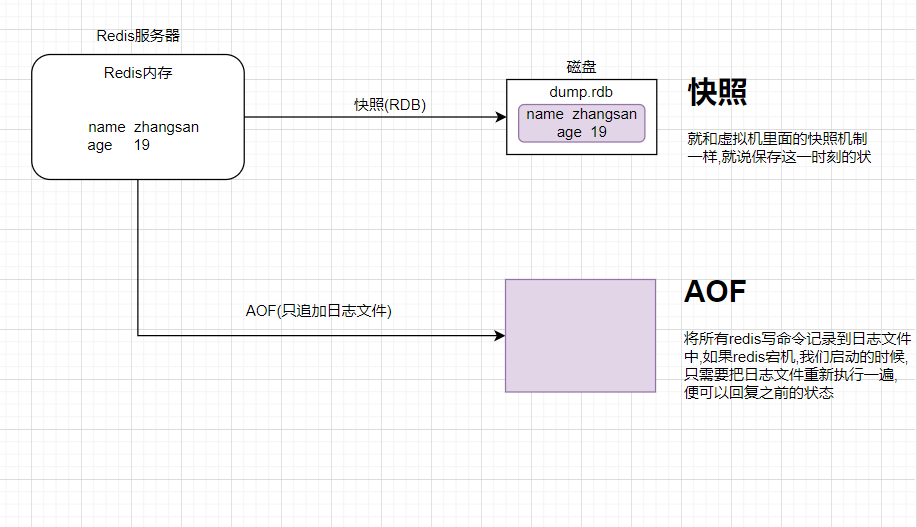
9.1 快照
1. 特点
这种方式可以将某一时刻的所有数据都写入硬盘中,当然这也是redis的默认开启持久化方式,保存的文件是以.rdb形式结尾的文件因此这种方式也称之为RDB方式。
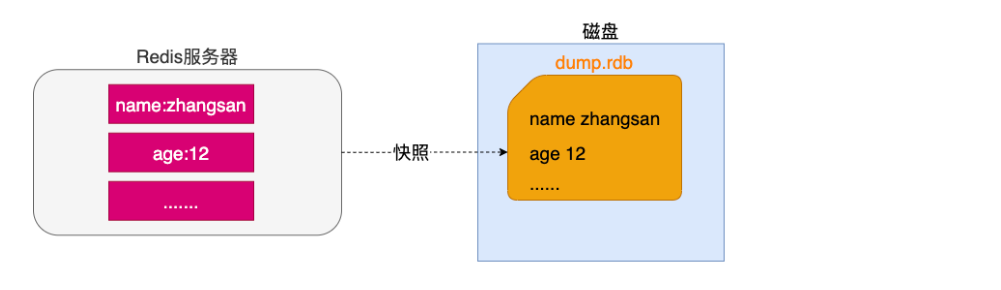
2.快照生成方式
- 方式一:通过客户端命令的方式,明确告诉他需要持久化操作: BGSAVE 和 SAVE指令
# 1.客户端方式之BGSAVE
- a.客户端可以使用BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork¹来创建一个子进程,然后子进程负责将快照写入磁盘中,而父进程则继续处理命令请求。
`名词解释: fork当一个进程创建子进程的时候,底层的操作系统会创建该进程的一个副本,在类unix系统中创建子进程的操作会进行优化:在刚开始的时候,父子进程共享相同内存,直到父进程或子进程对内存进行了写之后,对被写入的内存的共享才会结束服务`
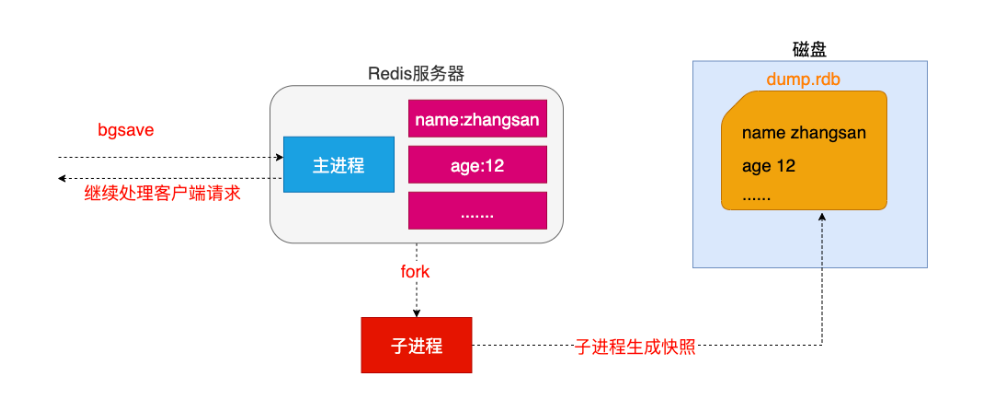
# 2.客户端方式之SAVE
- b.客户端还可以使用SAVE命令来创建一个快照,接收到SAVE命令的redis服务器在快照创建完毕之前将不再响应任何其他的命令
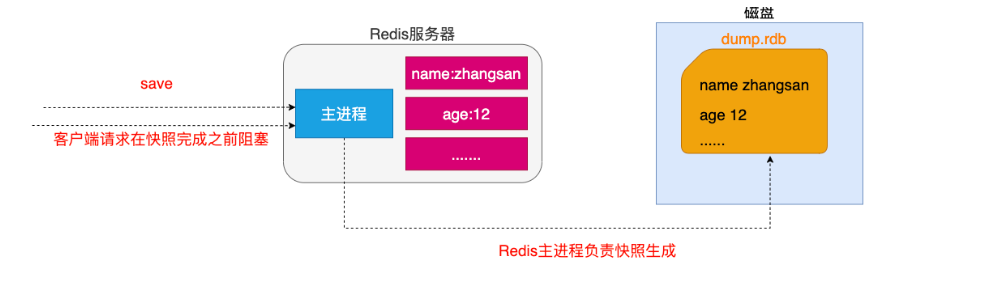
注意: SAVE命令并不常用,使用SAVE命令在快照创建完毕之前,redis处于阻塞状态,无法对外服务
- 方式二:服务端配置自动触发的方式
# 1.服务器配置方式之满足配置自动触发
- 如果用户在redis.conf中设置了save配置选项,redis会在save选项条件满足之后自动触发一次BGSAVE命令,如果设置多个save配置选项,当任意一个save配置选项条件满足,redis也会触发一次BGSAVE命令
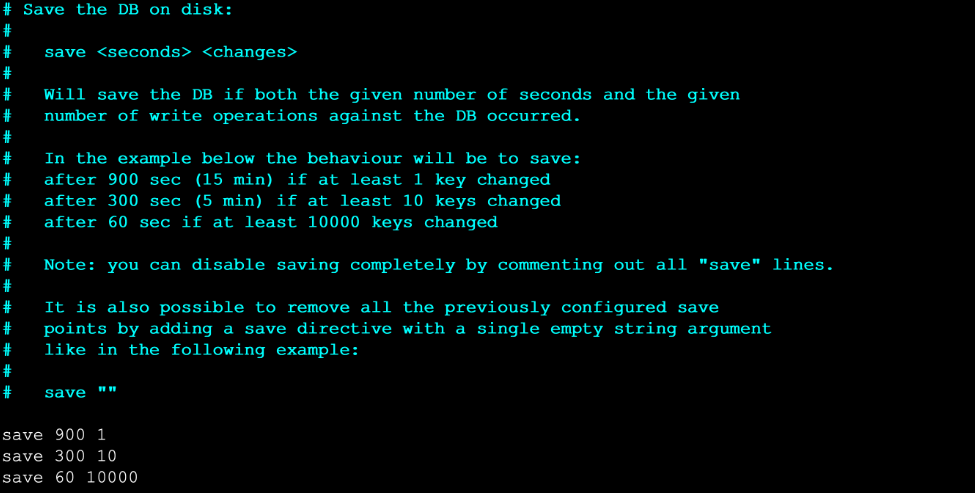
- 方式三
# 1.服务器接收客户端shutdown指令
- 当redis通过shutdown指令接收到关闭服务器的请求时,会执行一个save命令,阻塞所有的客户端,不再执行客户端执行发送的任何命令,并且在save命令执行完毕之后关闭服务器
3.配置生成快照名称和位置
#1.修改生成快照名称
- dbfilename dump.rdb 必须以rdb结尾
# 2.修改生成位置
- dir ./
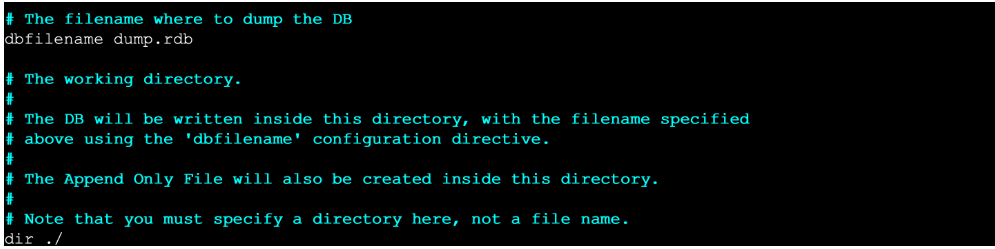
结论:当我们刚刚进行一次快照,然后客户端又进行了两次写入,但是并没有触发快照,这个时候断电/宕机,就会出现数据丢失
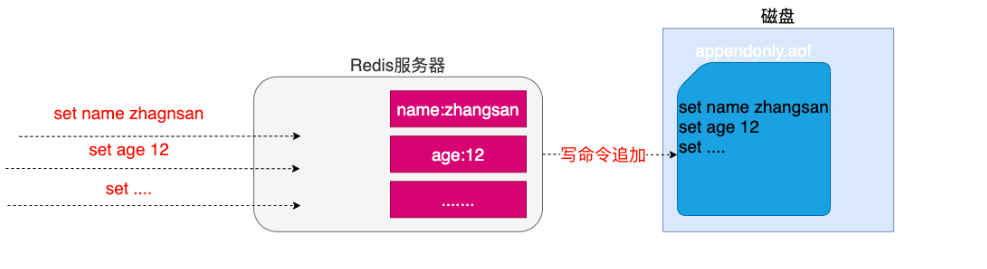
9.2 AOF 只追加日志文件
1.特点
这种方式可以将所有客户端执行的写命令记录到日志文件中,AOF持久化会将被执行的写命令写到AOF的文件末尾,以此来记录数据发生的变化,因此只要redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集.
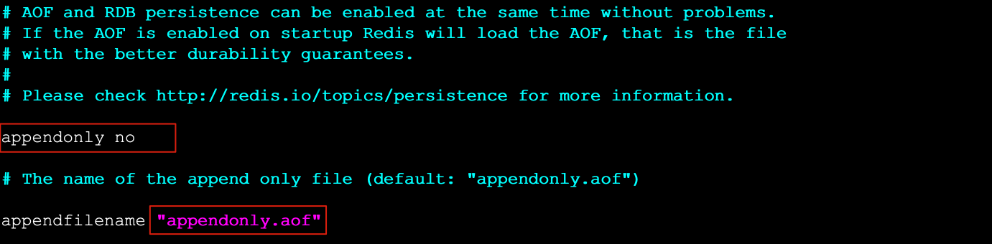
2.开启AOF持久化
在redis的默认配置中AOF持久化机制是没有开启的,需要在配置中开启
# 1.开启AOF持久化
- a.修改 appendonly yes 开启持久化
- b.修改 appendfilename "appendonly.aof" 指定生成文件名称(文件放置位置与放置快照的位置一样)
3.日志追加频率
# 1.always 【谨慎使用】
- 说明: 每个redis写命令都要同步写入硬盘,严重降低redis速度
- 解释: 如果用户使用了always选项,那么每个redis写命令都会被写入硬盘,从而将发生系统崩溃时出现的数据丢失减到最少;遗憾的是,因为这种同步策略需要对硬盘进行大量的写入操作,所以redis处理命令的速度会受到硬盘性能的限制;
- 注意: 转盘式硬盘在这种频率下200左右个命令/s ; 固态硬盘(SSD) 几百万个命令/s;
- 警告: 使用SSD用户请谨慎使用always选项,这种模式不断写入少量数据的做法有可能会引发严重的写入放大问题,导致将固态硬盘的寿命从原来的几年降低为几个月。
# 2.everysec 【推荐】
- 说明: 每秒执行一次同步显式的将多个写命令同步到磁盘
- 解释: 为了兼顾数据安全和写入性能,用户可以考虑使用everysec选项,让redis每秒一次的频率对AOF文件进行同步;redis每秒同步一次AOF文件时性能和不使用任何持久化特性时的性能相差无几,而通过每秒同步一次AOF文件,redis可以保证,即使系统崩溃,用户最多丢失一秒之内产生的数据。
# 3.no 【不推荐】
- 说明: 由操作系统决定何时同步
- 解释:最后使用no选项,将完全有操作系统决定什么时候同步AOF日志文件,这个选项不会对redis性能带来影响但是系统崩溃时,会丢失不定数量的数据,另外如果用户硬盘处理写入操作不够快的话,当缓冲区被等待写入硬盘数据填满时,redis会处于阻塞状态,并导致redis的处理命令请求的速度变慢。
4.修改同步频率
# 1.修改日志同步频率
- 修改appendfsync everysec|always|no 指定

9.3 AOF文件的重写
1. AOF带来的问题
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件Redis提供了AOF重写(ReWriter)机制。
2. AOF重写
用来在一定程度上减小AOF文件的体积
3. 触发重写方式
# 方式一:客户端方式触发重写
- 执行BGREWRITEAOF命令 不会阻塞redis的服务
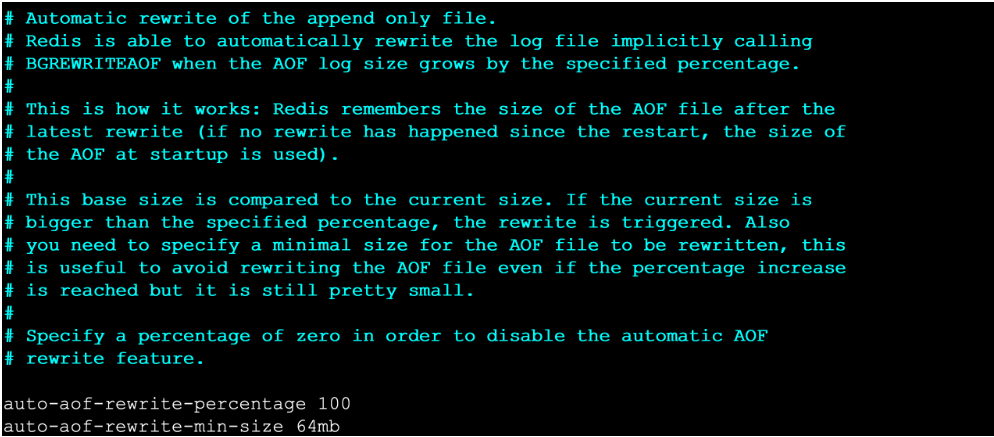
# 方式二:服务器配置方式自动触发
- 配置redis.conf中的auto-aof-rewrite-percentage选项 参加下图↓↓↓
- 如果设置auto-aof-rewrite-percentage值为100和auto-aof-rewrite-min-size 64mb,并且启用的AOF持久化时,那么当AOF文件体积大于64M,
并且AOF文件的体积比上一次重写之后体积大了至少一倍(100%)时,会自动触发,如果重写过于频繁,用户可以考虑将auto-aof-rewrite-percentage设置为更大(意思是我们第一次重写,如果大小到达64M时就会触发一次,
第二次重写,会根据auto-aof-rewrite-percentage值为100(1倍)去判断,如果体积大于第一次重写之后的一倍,就发生第二次重写,这样依次类推)
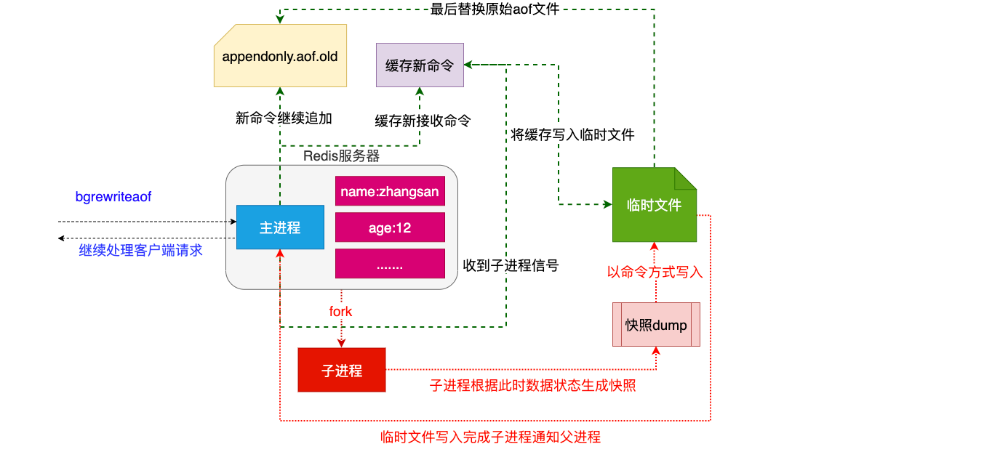
4. 重写原理
注意:重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,替换原有的文件这点和快照有点类似。
# 重写流程
- 1. redis调用fork ,现在有父子两个进程 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
- 2. 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
- 3. 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
- 4. 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
9.4 持久化总结
- 两种持久化方案既可以同时使用(aof),又可以单独使用,在某种情况下也可以都不使用,具体使用那种持久化方案取决于用户的数据和应用决定。
- 无论使用AOF还是快照机制持久化,将数据持久化到硬盘都是有必要的,除了持久化外,用户还应该对持久化的文件进行备份(最好备份在多个不同地方)。
10.java操作Redis
10.1 环境准备
1. 引入依赖
<!--引入jedis连接依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
2.创建jedis对象
public static void main(String[] args) {
//1.创建jedis对象
Jedis jedis = new Jedis("192.168.40.4", 6379);//1.redis服务必须关闭防火墙 2.redis服务必须开启远程连接
jedis.select(0);//选择操作的库默认0号库
//2.执行相关操作
//....
//3.释放资源
jedis.close();
}
jedis的API和redis的命令都一样
10.2 操作key相关API
public class KeyTest {
private Jedis jedis;
@Before
public void before(){
this.jedis = new Jedis("192.168.10.28",6379);
}
@After
public void after(){
jedis.close();
}
//测试key相关命令
@Test
public void testKeys(){
//删除一个key
jedis.del("sign");
//删除多个key
jedis.del("name","age");
//判断一个key是否存在
Boolean name = jedis.exists("name");
System.out.println(name);
//设置一个key的超时时间
Long name1 = jedis.expire("name", 90);//秒
// Long name2 = jedis.pexpire("name", 900);//毫秒为单位
System.out.println(name1);
// System.out.println(name2);
//查看一个key的超时时间
Long name3 = jedis.ttl("name");
System.out.println(name3);
//随机获取一个key
String s = jedis.randomKey();
//修改key的名称
String rename = jedis.rename("name", "newName");
//查看key对应的值的类型
String name2 = jedis.type("name");
}
}
10.3 操作String相关API
public class StringTest {
private Jedis jedis;
@Before
public void before(){
this.jedis = new Jedis("192.168.10.28",6379);
}
@After
public void after(){
jedis.close();
}
//测试String类型相关命令
@Test
public void testString(){
//set
jedis.set("name","小陈");
//get
String name = jedis.get("name");
System.out.println(name);
//mset
jedis.mset("content","好人","address","渝北");
//mget
List<String> mget = jedis.mget("name", "content", "address");
mget.forEach(v-> System.out.println(v));
//getset
String set = jedis.getSet("name", "小明");
System.out.println(set);
}
}
10.4操作List相关API
public class ListTest {
private Jedis jedis;
@Before
public void before(){
this.jedis = new Jedis("192.168.10.28",6379);
}
@After
public void after(){
jedis.close();
}
//测试List类型相关命令
@Test
public void testString(){
jedis.lpush("names1","zhnagsan","wangwu","lisi");
jedis.rpush("names","xiaoming","chen","li");
List<String> names1 = jedis.lrange("names1", 0, -1);
names1.forEach(name-> System.out.println("name = " + name));
//lpop rpop
String names11 = jedis.lpop("names1");
System.out.println(names11);
//llen
jedis.linsert("lists", BinaryClient.LIST_POSITION.BEFORE,"xiaohei","xiaobai");
}
}
10.5操作Set的相关API
//测试SET相关
@Test
public void testSet(){
//sadd
jedis.sadd("names","zhangsan","lisi");
//smembers
jedis.smembers("names");
//sismember
jedis.sismember("names","xiaochen");
//...
}
10.6 操作ZSet相关API
//测试ZSET相关
@Test
public void testZset(){
//zadd
jedis.zadd("names",10,"张三");
//zrange
jedis.zrange("names",0,-1);
//zcard
jedis.zcard("names");
//zrangeByScore
jedis.zrangeByScore("names","0","100",0,5);
//..
}
10.7 操作Hash相关API
//测试HASH相关
@Test
public void testHash(){
//hset
jedis.hset("maps","name","zhangsan");
//hget
jedis.hget("maps","name");
//hgetall
jedis.hgetAll("mps");
//hkeys
jedis.hkeys("maps");
//hvals
jedis.hvals("maps");
//....
}
11.SpringBoot整合Redis
Spring Boot Data(数据) Redis 中提供了RedisTemplate和StringRedisTemplate,其中StringRedisTemplate是RedisTemplate的子类,两个方法基本一致,不同之处主要体现在操作的数据类型不同,RedisTemplate中的两个泛型都是Object,意味着存储的key和value都可以是一个对象,而StringRedisTemplate的两个泛型都是String,意味着StringRedisTemplate的key和value都只能是字符串。
注意: 使用RedisTemplate默认是将对象序列化到Redis中,所以放入的对象必须实现对象序列化接口
11.1 环境准备
1.引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.配置application.propertie
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.database=0
11.2 使用StringRedisTemplate和RedisTemplate
@SpringBootTest(classes = SpringbootRedisApplication.class)
public class TestStringRedisTemplate {
@Autowired
private StringRedisTemplate stringRedisTemplate; //操作的key和value都是字符串
//操作redis中key相关
@Test
public void testKey(){
stringRedisTemplate.delete("name");//删除一个key
Boolean name = stringRedisTemplate.hasKey("name");//判断某个key是否存在
System.out.println(name);
DataType name1 = stringRedisTemplate.type("name");//判断key所对应值的类型
System.out.println(name1);
Set<String> keys = stringRedisTemplate.keys("*");//获取所有的key
keys.forEach(key-> System.out.println(key));
stringRedisTemplate.randomKey();//随机获取一个key
stringRedisTemplate.rename("age","age1");//这个可以必须存在,不存在就报错
stringRedisTemplate.move("name",1);//移动key到指定库
//...................
}
//操作redis中的字符串 opsForValue
@Test
public void testString(){
stringRedisTemplate.opsForValue().set("name","xiaochen"); //opsForValue操作String
String name = stringRedisTemplate.opsForValue().get("name");
System.out.println(name);
stringRedisTemplate.opsForValue().set("code","7989",120, TimeUnit.MINUTES);//设置key的超时时间
stringRedisTemplate.opsForValue().append("name","cdl");//追加
//.........................
}
//操作redis中list类型 opsForList 实际操作就是redis中list类型
@Test
public void testList(){
//stringRedisTemplate.opsForList().leftPush("names","小陈");//创建一个列表 并放入一个元素
//stringRedisTemplate.opsForList().leftPushAll("names","小陈","小张","小王");//创建一个列表 放入多个元素
List<String> names = new ArrayList<>();
names.add("xiaoming");
names.add("xiaosan");
//stringRedisTemplate.opsForList().leftPushAll("names",names);//创建一个列表 放入多个元素
List<String> stringList = stringRedisTemplate.opsForList().range("names", 0, -1); //遍历list
stringList.forEach(value-> System.out.println("value = " + value));
stringRedisTemplate.opsForList().trim("names",1,3); //截取指定区间的list
}
//操作redis中set类型 opsForSet 实际操作就是redis中set类型
@Test
public void testSet(){
stringRedisTemplate.opsForSet().add("sets","张三","张三","小陈","xiaoming");//创建set 并放入多个元素
Set<String> sets = stringRedisTemplate.opsForSet().members("sets");//查看set中成员
sets.forEach(value-> System.out.println("value = " + value));
Long size = stringRedisTemplate.opsForSet().size("sets");//获取set集合元素个数
System.out.println("size = " + size);
}
//操作redis中Zset类型 opsForZSet 实际操作就是redis中Zset类型
@Test
public void testZset(){
stringRedisTemplate.opsForZSet().add("zsets","小黑",20);//创建并放入元素
Set<String> zsets = stringRedisTemplate.opsForZSet().range("zsets", 0, -1);//指定范围查询
zsets.forEach(value-> System.out.println(value));
System.out.println("=====================================");
Set<ZSetOperations.TypedTuple<String>> zsets1 = stringRedisTemplate.opsForZSet().rangeByScoreWithScores("zsets", 0, 1000);//获取指定元素以及分数
zsets1.forEach(typedTuple ->{
System.out.println(typedTuple.getValue());
System.out.println(typedTuple.getScore());
});
}
//操作redis中Hash类型 opsForHash 实际操作就是redis中Hash类型
@Test
public void testHash(){
stringRedisTemplate.opsForHash().put("maps","name","张三");//创建一个hash类型 并放入key value
Map<String,String> map = new HashMap<String,String>();
map.put("age","12");
map.put("bir","2012-12-12");
stringRedisTemplate.opsForHash().putAll("maps",map); //放入多个key value
List<Object> values = stringRedisTemplate.opsForHash().multiGet("maps", Arrays.asList("name", "age"));//获取多个key的value
values.forEach(value-> System.out.println(value));
String value = (String) stringRedisTemplate.opsForHash().get("maps", "name");//获取hash中某个key的值
List<Object> vals = stringRedisTemplate.opsForHash().values("maps");//获取所有values
Set<Object> keys = stringRedisTemplate.opsForHash().keys("maps");//获取所有keys
}
}
redisTemplate序列化 存对象时需要把对象序列化
@SpringBootTest(classes = SpringbootRedisApplication.class)
public class TestRedisTemplate {
@Autowired
private RedisTemplate redisTemplate;//里面可以放对象
//opsforxxx
//必须对象序列化才可以存对象
//redisTemplate 不管做什么操作,默认是将key和value序列化之后的结果
@Test
public void testRedisTemplate(){
User v = new User();
/**
* redisTemplate对象中 key 和 value都序列化了
* 所以我们想key:string 依然保持字符串,就需要修改默认的序列化方案
*/
//修改string key的序列化方案 value的序列化默认使用jdk的序列化,不需要修改
redisTemplate.setKeySerializer(new StringRedisSerializer());
//修改hash key的序列化方案
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
v.setId(UUID.randomUUID().toString());
v.setName("小陈");
v.setAge(23);
redisTemplate.opsForValue().set("user", v);//redis进行设置值,对象需要序列化
User user = (User) redisTemplate.opsForValue().get("user");
System.out.println(user);
}
}
绑定key
@SpringBootTest(classes = SpringbootRedisApplication.class)
public class TestBoundApi {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
//spring data 为了方便我们对redis更友好的操作,因此又提供了bound api简化操作
@Test
public void testBound(){
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
//无论是 redisTemplate 还是 stringRedisTemplate
// stringRedisTemplate.opsForValue().set("name","zhangsan");
// stringRedisTemplate.opsForValue().append("name","是一个好人");
// String name = stringRedisTemplate.opsForValue().get("name");
// System.out.println(name);
//像上面这种,如果要对一个key进行N多次操作,那么可以对这个key进行绑定处理,日后如果拿这个绑定对象进行操作时,都是对这个key的操作
//对字符串类型的key进行绑定,操作name1对象,就是对key 为 name的值的操作
BoundValueOperations<String, String> name1 = stringRedisTemplate.boundValueOps("name");
name1.set("zhangsan");
name1.append("是一个好人");
name1.get();
//对list/set/zset/hash都可以进行绑定,redisTemplate/stringRedisTemplate也都可以绑定
/**
* 总结:
* 1.针对以后key/value都是string,使用stringRedisTemplate
* 2.针对以后key/value存在对象,使用redisTemplate
* 3.针对以后对同一个key进行多次操作,可以使用绑定操作
*/
}
}
11.3 Redis的应用场景
- 1.项目中利用redis的字符串类型,完成手机验证码的实现
- 2.利用redis中字符串类型完成具有一定失效性的业务功能 订单超时
- 3.利用redis完成分布式系统中或集群系统中的 Session共享
- 4.利用redis中的Zset类型,可排序的set类型,完成排行榜之类的功能
- 5.利用redis实现分布式缓存
- 6.利用redis存储认证之后的信息
- 7.利用redis解决分布式集群系统中分布式锁的问题
12 Redis分布式缓存的实现
1.什么是缓存(Cache)
定义:计算机内存中的一段数据
2.内存中数据的特点
- 读写快
- 断电立即丢失
3.缓存解决了什么问题?
- 提高网站的吞吐量,提高了网站的运行效率
- 缓存核心解决的问题:缓存的存在是用来减轻数据库的压力
4.既然缓存能提高效率,那项目中所有数据加入缓存岂不是更好?
注意:使用缓存时,一定是数据库中的数据极少发生修改,更多用于查询的情况,如果数据发生修改的及其频繁,则不建议去添加缓存
5.什么是本地缓存?什么是分布式缓存?
- 本地缓存:存在应用服务器内存中数据称为本地缓存(local cache)
- 分布式缓存:存储在当前应用服务器内存之外数据称为分布式缓存(distribute cache)
- 集群:将同一种服务的多个节点放在一起共同对系统提供服务的过程称为集群
- 分布式:有多个不同服务集群共同对系统提供服务,这个系统称为分布式系统(distribute system)
6.利用mybatis的自身本地缓存结合redis实现分布式缓存
- a.mybatis中应用级缓存 SqlSessionFactory级别缓存 所有会话共享
- b.如何开启(二级缓存)
在mapper.xml中加入即可--->本地缓存
7.使用mybatis实现本地缓存
配置文件
server:
port: 8989
## redis 配置
spring:
redis:
host: 192.168.10.28
port: 6379
database: 0
# mysql配置
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/2001?useUnicode=true&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: root
# mybatis
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.cdl.entity
# 日志打印
logging:
level:
com.cdl.dao: debug
DAO
@Repository
public interface UserDao {
List<User> findAll();
}
mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.cdl.dao.UserDao">
<cache></cache>
<select id="findAll" resultType="com.cdl.entity.User">
select * from t_user
</select>
</mapper>
测试类
@SpringBootTest(classes = SpringbootRedisApplication.class)
public class TestUserService {
@Resource
private UserServiceImpl userService;
@Test
public void findAll(){
List<User> all = userService.findAll();
all.forEach(user -> System.out.println(user));
System.out.println("----------------------------");
List<User> all1 = userService.findAll();
all1.forEach(user2 -> System.out.println(user2));
}
}
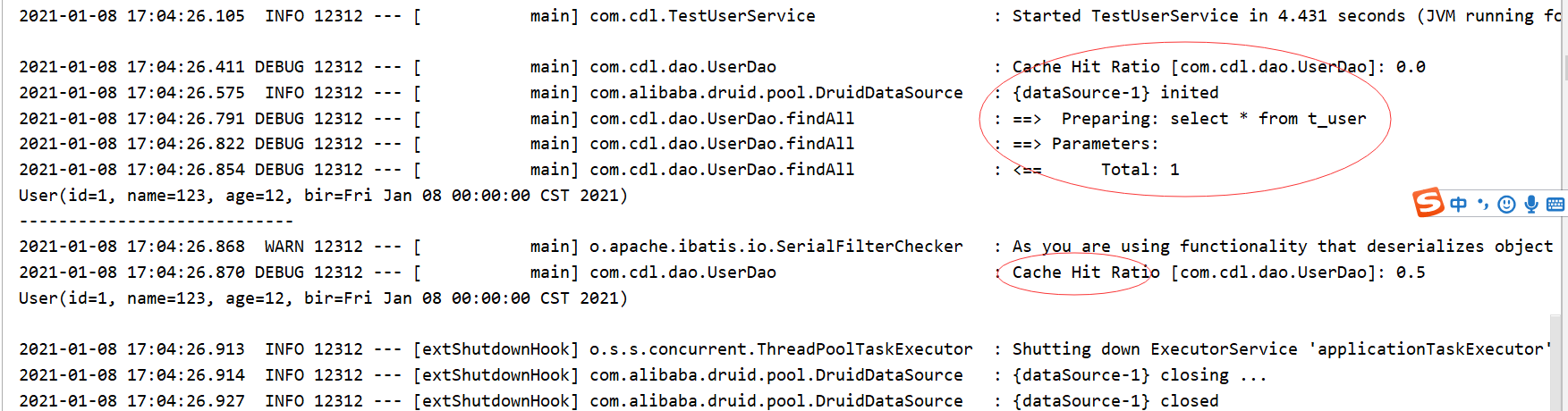
会发现第二次查询,并没有请求数据库,而是直接调用了mybatis的本地缓存,但是本地缓存还是需要消耗我们的虚拟机的内存,同时,他也会随着我们jvm进程的结束或断电,而丢失,如果在集群分布式系统下,也不能做到缓存共享,所以我们需要将改缓存修改为分布式缓存
8.分布式缓存的实现
- a.查看cache标签缓存的实现
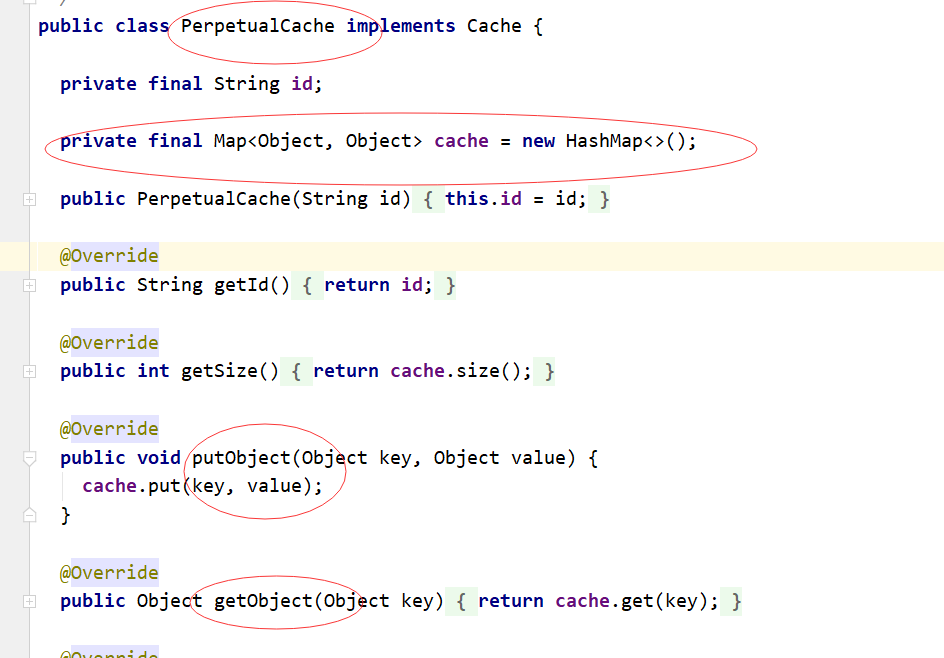
结论:mybatis底层默认使用的是 org.apache.ibatis.cache.cache.impl.PerpetualCache 实现,PerpetualCache底层维护了一个map集合,去完成缓存的实现! - b.自定义redis的cache实现
- 1.通过mybatis默认cache的源码,我们可以得知,可以使用自定义的cache类实现实现接口,并对里面的方法进行实现
- 1.通过mybatis默认cache的源码,我们可以得知,可以使用自定义的cache类实现实现接口,并对里面的方法进行实现
package com.cdl.cache;
import com.cdl.util.ApplicationContextUtil;
import org.apache.ibatis.cache.Cache;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
-
@Author CDL
-
@Date 2021/1/8 17:46
-
@Desc
-
@Version 1.0.
*/
//自定义redis缓存的实现
public class RedisCache implements Cache {//当前放入缓存的mapper的namespace
private final String id;//必须存在构造方法,否则会报错
public RedisCache(String id){
System.out.println("id:"+id);
this.id = id;
}//表示返回cache的唯一标识
@Override
public String getId() {
return this.id;
}//向缓存中放入值 redis -->redisTemplate stringRedisTemplate
@Override
public void putObject(Object key, Object value) {
System.out.println("key:"+key.toString());
System.out.println("value:"+value);
//通过工具类获取redisTemplate对象
RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtil.getBean("redisTemplate");
redisTemplate.setStringSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());//通过redis中的hash类型作为缓存模型 id key value redisTemplate.opsForHash().put(id.toString(),key.toString(),value);}
//缓存中获取数据
@Override
public Object getObject(Object key) {
System.out.println("key:"+key.toString());
RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtil.getBean("redisTemplate");
redisTemplate.setStringSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
return redisTemplate.opsForHash().get(id.toString(),key.toString());
}//根据指定的key删除缓存 为mybatis的保留方法,默认没有实现
@Override
public Object removeObject(Object key) {
return null;
}//清空缓存 只要发生增删改,mybatis会默认调用清除缓存
@Override
public void clear() {
RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtil.getBean("redisTemplate");
redisTemplate.setStringSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.delete(id.toString());
}//用来计算缓存的数量
@Override
public int getSize() {
RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtil.getBean("redisTemplate");
redisTemplate.setStringSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
//获取hash中的key value的数量
return redisTemplate.opsForHash().size(id.toString()).intValue();
}
}
```
//用来获取springboot创建好的工厂
@Configuration
public class ApplicationContextUtil implements ApplicationContextAware {
//保留下来工厂
private static ApplicationContext applicationContext;
//将创建好工厂以参数形式传递给这个类
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
//提供在工厂中获取对象的方法 //RedisTemplate redisTemplate
public static Object getBean(String beanName){
return applicationContext.getBean(beanName);
}
}
- 2.使用RedisCache实现
<cache type="com.cdl.cache.RedisCache"></cache>
结论:当我们执行增删改操作的时候,会清空redis中的缓存,同时,他只会清空自己namespace下的缓存,不会清空其他的namespace下的缓存
9.Redis分布式缓存的实现(二)
1.缓存在项目中的应用
- 如果项目中查询之间表没有任何关联查询,使用现在的查询方式没有任何问题
- 现有的方式在表连接的查询过程中一定存在问题!
2.在mybatis的缓存中,如果要解决关联关系时更新缓存时的问题?
使用标签,将两个表之间关联起来,当无论哪个表发生跟新时,都会去清空缓存,namespace里面指向哪个对象,缓存的key就会使用该对象的全路径,然后有多个关联关系的缓存都放在一起
10.Redis分布式缓存的实现(三)
1.缓存的优化策略
- 将key设计的简洁一些,不像原来那么长
算法: MD5处理- 一切文件字符串等经过md5处理之后,都会生成32位16进制字符串
- 不同内容文件经过md5加密,加密结果一定不一致
- 相同内容的文件,多次经过MD5,生成结构始终一致
推荐:在redis整合mybatis过程中,建议将key进行MD5优化处理
2.面试相关概念:
- 1.什么是缓存穿透?
- 定义:客户端查询了一个数据库中没有的数据记录,导致缓存在这种情况选无法利用,称为缓存穿透,或者是缓存击穿
- mybatsi本身是已经解决了缓存穿透的,mybatis解决思路:无论你查询的结果数据库有没有,他都会放到redis,如果数据库的查询结果为null,则redis中的value也为null,这样就在一定程度上保护了我们的数据库
- 2.什么是缓存雪崩?
- 定义:在系统运行的某一个时刻,突然,系统中的缓存全部失效(比如大量缓存过期),恰好在这一时刻,涌入了大量的客户端请求,导致所有的模块缓存无法利用,大量的请求涌入数据库,导致极端情况,数据库阻塞或挂机
- 解决方案:
- 1.缓存永久存储(不推荐)
- 2.针对于不同的业务数据,一定要设置不同的超时时间
13.Redis主从复制
13.1 主从复制
主从复制架构仅仅用来解决数据的冗余备份,从节点仅仅用来同步数据
注意:当redis主节点宕机的时候,从节点不会去替代主节点提供服务,无法解决故障转移的功能,所以就需要使用哨兵服务
13.2主从复制架构图
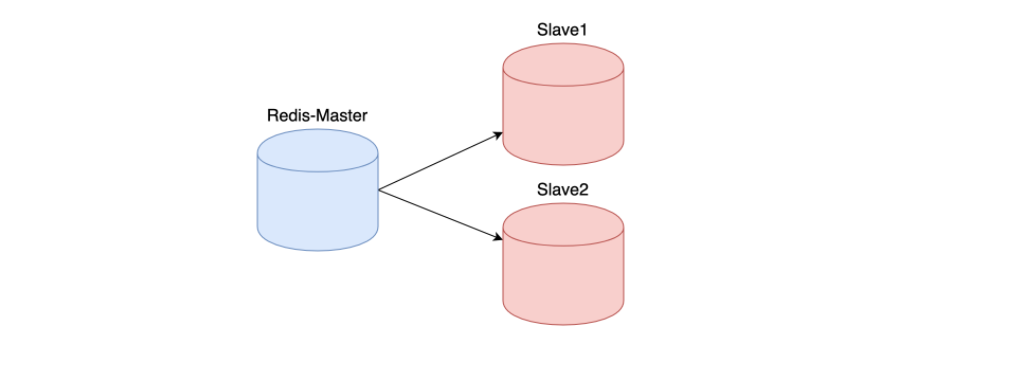
13.3 搭建主从复制
1.准备三个文件夹,模拟三台机器,
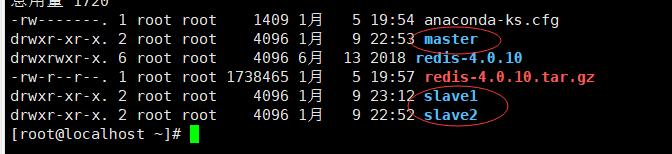
2.将redis.conf分别复制到三个文件夹中,

3.修改配置文件
- master 主
port 6379
bind 0.0.0.0
- slave1 从
port 6380
bind 0.0.0.0
slaveof masterip masterport
- slave2 从
port 6381
bind 0.0.0.0
slaveof masterip masterport

4.启动三台机器进行测试
- cd /usr/redis/bin
- ./redis-server /root/master/redis.conf
- ./redis-server /root/slave1/redis.conf
- ./redis-server /root/slave2/redis.conf
结论:从库不接受任何指令,从库只负责同步主库的数据,完成数据的冗余备份,不进行自动故障转移(自动故障转移:当主节点宕机的时候,从节点顶替主节点进行工作)
5.也可以让从库可以接收指定(但是一般是不建议这个操作的)
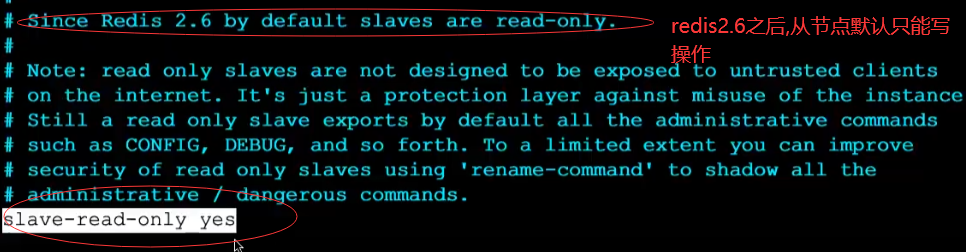
将改操作改为NO即可
14.哨兵机制
14.1 哨兵Sentinel机制
Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。简单的说哨兵就是带有自动故障转移功能的主从架构。
14.2 哨兵架构原理
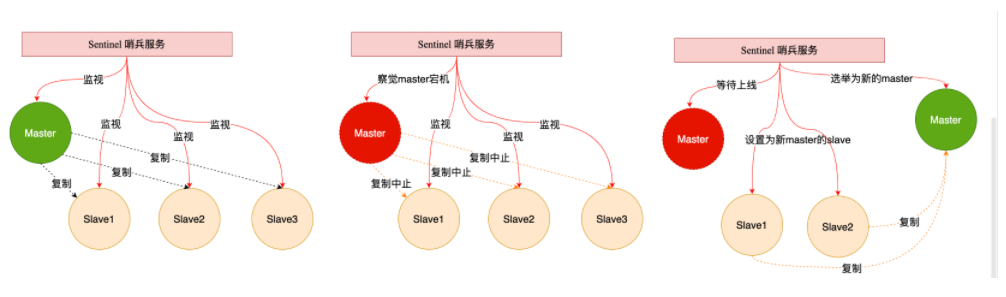
注意:当原始master启动之后,原始的master将不再充当master了,而是充当新的master的从节点
14.3 搭建哨兵架构
# 1.在主节点上创建哨兵配置
- 在Master对应redis.conf同目录下新建sentinel.conf文件,名字绝对不能错;
# 2.配置哨兵,在sentinel.conf文件中填入内容:
- sentinel monitor 被监控数据库名字(自己起名字) 主机ip 端口号 1(说明:这个后面的数字5,是指当有2.5个及以上的哨兵服务检测到master宕机,才会去执行主机切换的功能,建议哨兵机制单间个数为奇数个,当节点宕机的时候,会进行一个投票,有半数及以上的投票说宕机了,那就证明真正宕机,如果是偶数个,当投票数相同的时候,就会产生一个歧义)
# 3.到原redis解压目录中的src目录下,复制redis-sentinel启动脚本到redis的bin目录下
# 4.启动哨兵模式进行测试
- ./redis-sentinel /root/sentinel/sentinel.conf
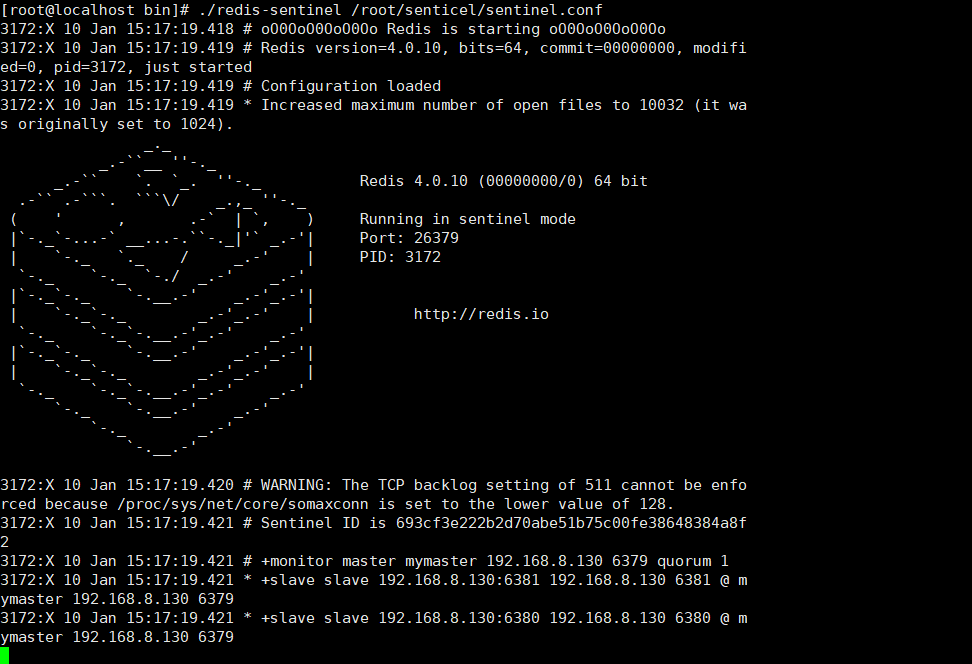
在我们启动哨兵的时候,哨兵会把我们的配置信息自动补全
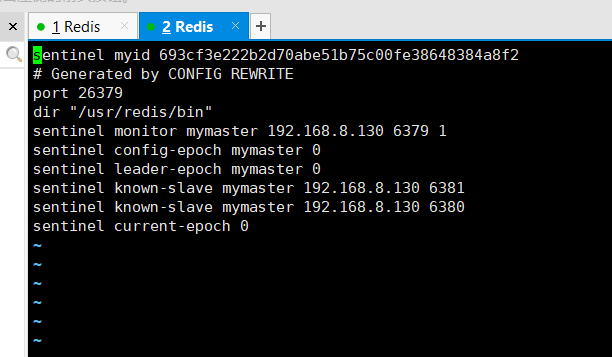
- 结论:会发现,当我们主节点宕机的时候,哨兵会默认的把一个从节点变为主节点,然后原来的主节点变为从节点
- 发现问题
- 当我们所有的请求全部到主节点的时候,就会出现问题,主节点压力过大,master的内存也会不够,造成溢出
无法解决: 1.单节点并发压力问题 2.单节点内存和磁盘物理上限
解决方法:redis集群
- 当我们所有的请求全部到主节点的时候,就会出现问题,主节点压力过大,master的内存也会不够,造成溢出
14.4 SpringBoot操作哨兵
# 1.开启哨兵的远程连接,在配置文件中添加bind 0.0.0.0 配置
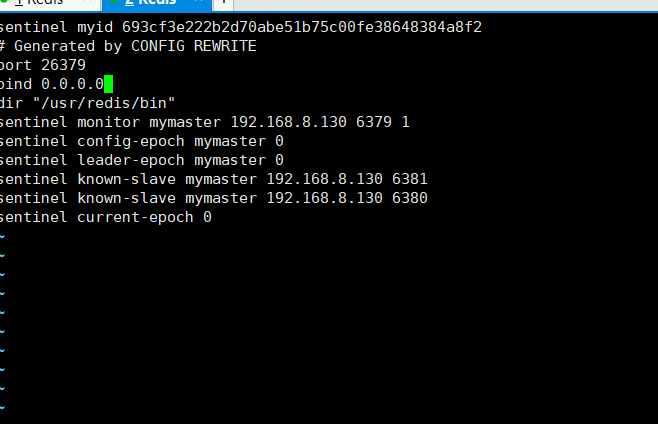
# 2.书写springboot的哨兵配置
注意:这个时候,spingboot中并不知道那个节点才是我的主节点,只有哨兵服务才知道
spring:
# redis的哨兵架构配置(我们这个时候是不知道那个节点上我们的主节点的)
redis:
sentinel:
master: mymaster # master书写的是哨兵监听的那个名称
# 连接的不再是一个具体的redis主机,而是多个哨兵节点,如有多个哨兵,使用逗号隔开
nodes: 192.168.8.130:26379
# 3.启动测试:成功
15.Redis集群
15.1 集群
Redis在3.0后开始支持Cluster(集群)模式,目前redis的集群支持节点的自动发现(以后往redis添加一个节点,可以融入这个集群),支持slave-master选举和容错,支持在线分片(sharding shard )等特性。
15.2 集群架构图
redis节点之间检测心跳:ping-->pang机制
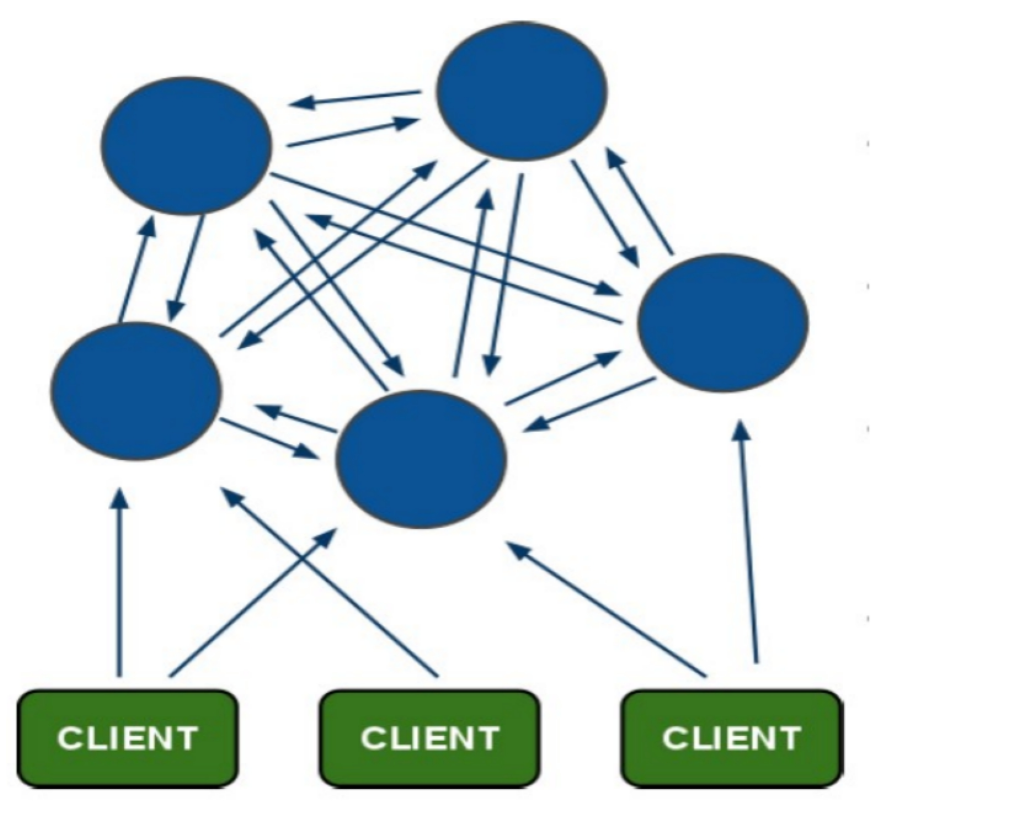
15.3 集群细节
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
- 节点的fail是通过集群中超过半数的节点检测失效时才生效. (集群节点个数建议奇数个,偶数个可能会产生歧义)
- 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster(集群)负责维护node(节点)<->slot(hash槽)<->value
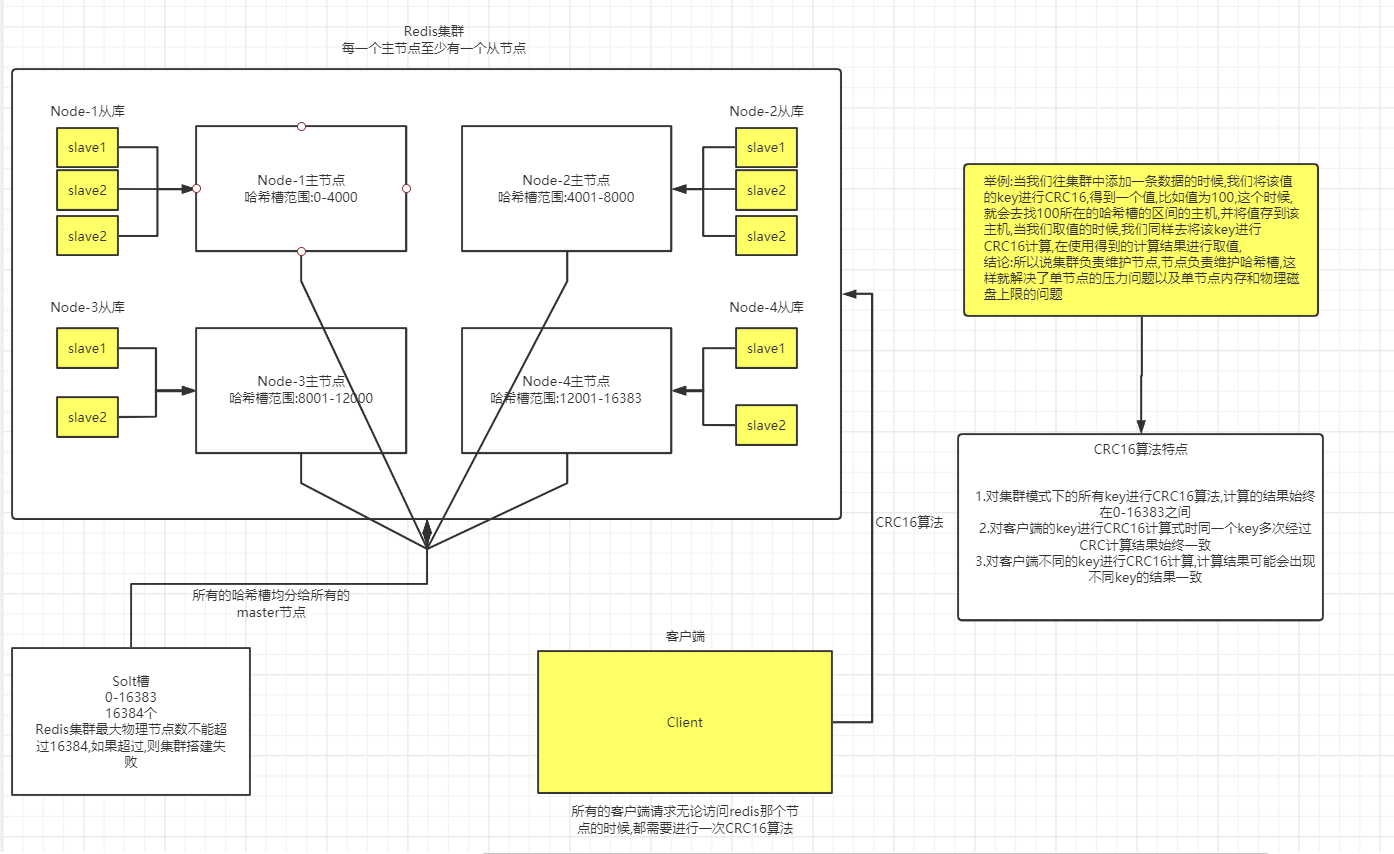
关于槽的重新分配:
- 当发生故障转移的时候,槽不会重新分配,直接复制上一个主节点的就可以
- 当再往集群中添加节点的时候,才回去重新分配槽,注意:当分配过去槽的时候,对应的值也应该复制过去
15.4 集群搭建
判断一个是集群中的节点是否可用,是集群中的所用主节点选举过程,如果半数以上的节点认为当前节点挂掉,那么当前节点就是挂掉了,所以搭建redis集群时建议节点数最好为奇数,搭建集群至少需要三个主节点,三个从节点,至少需要6个节点。
# 1.准备环境安装ruby以及redis集群依赖
- yum install -y ruby rubygems
- gem install redis-xxx.gem(需要安装包)
# 2.在一台机器创建7个目录
# 3.每个目录复制一份配置文件
# 4.修改不同目录配置文件
- bind 0.0.0.0 //开启远程连接
- port 6379 ..... //修改端口
- daemonize yes //守护进程启动(可改可不改)
- cluster-enabled yes //开启集群模式
- cluster-config-file nodes-port.conf //集群节点配置文件
- cluster-node-timeout 5000 //集群节点超时时间
- appendonly yes //开启AOF持久化
# 5.指定不同目录配置文件启动七个节点
- [root@localhost bin]# ./redis-server /root/7000/redis.conf
- [root@localhost bin]# ./redis-server /root/7001/redis.conf
- [root@localhost bin]# ./redis-server /root/7002/redis.conf
- [root@localhost bin]# ./redis-server /root/7003/redis.conf
- [root@localhost bin]# ./redis-server /root/7004/redis.conf
- [root@localhost bin]# ./redis-server /root/7005/redis.conf
- [root@localhost bin]# ./redis-server /root/7006/redis.conf
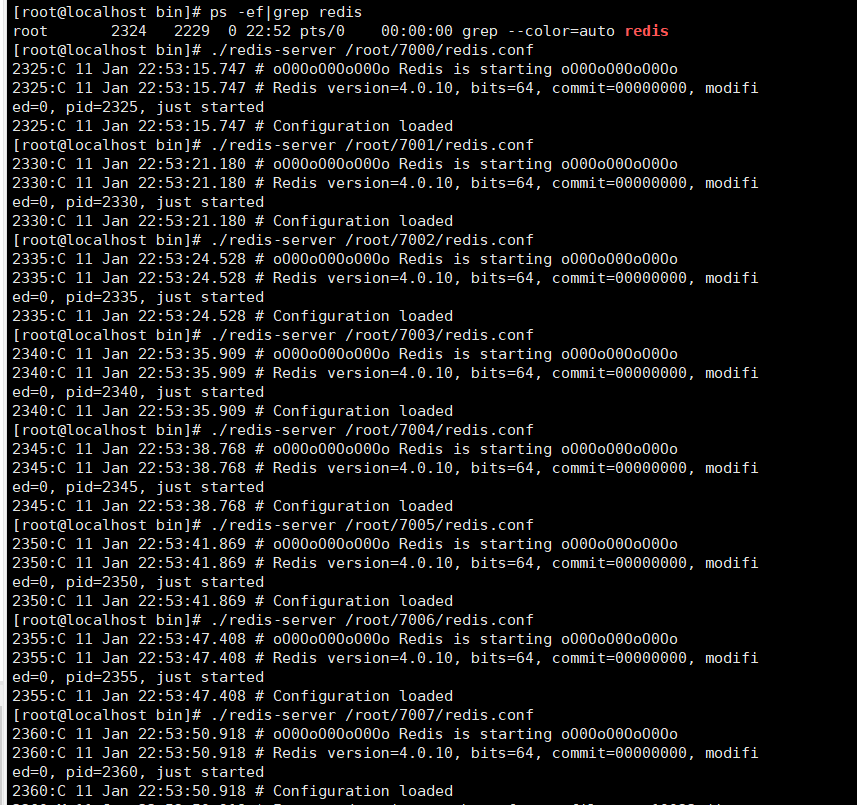
# 6.查看进程
- [root@localhost bin]# ps aux|grep redis
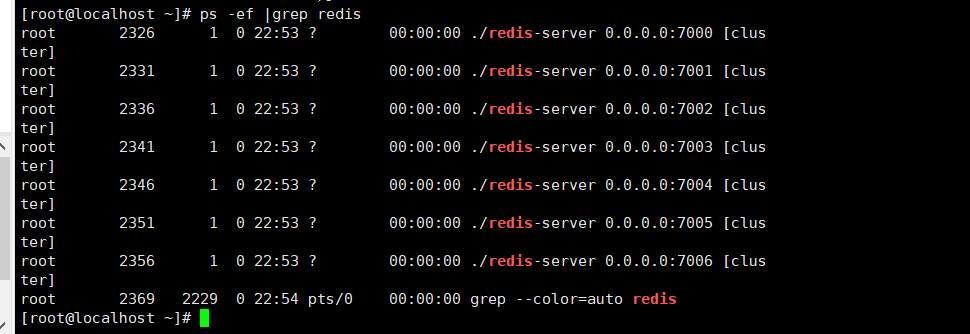
15.5 创建集群
17.Redis扩展
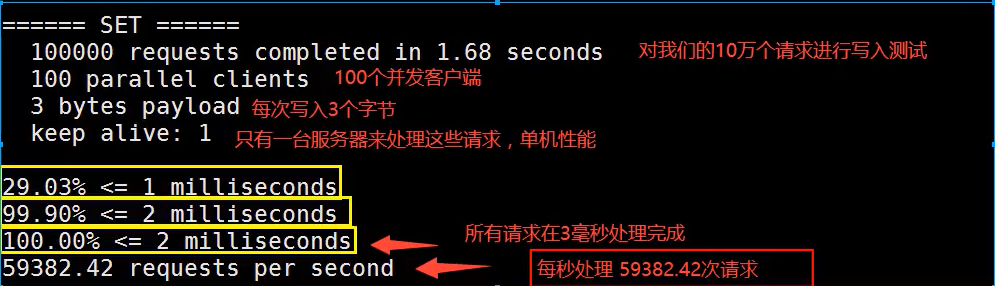
17.1 redis-benchmark性能测试
redis-benchmark是一个redis的压力测试工具
官方自带的性能测试工具
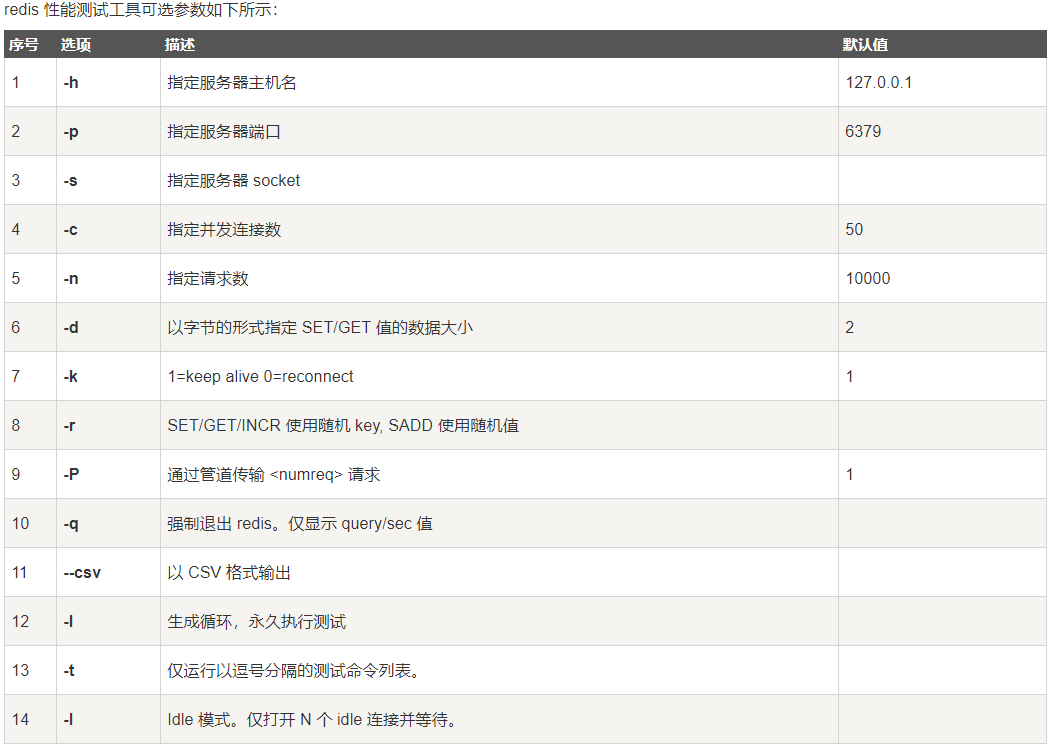
# 测试100个并发连接 每一个并发10万个请求
./redis-benchmark -h localhost -p 6379 -c 100 -n 100000
测试结果
17.2 三种特殊数据类型
1.geospatial 地理位置
朋友的定位,附近的人,打车距离计算都可以使用redis的Geo(redis的3.2版本就已经推出,这个功能可以推算地位位置信息,两地之间的距离,方圆几里的人)
# getadd 添加地理位置
- 添加城市数据
- 规则:
- 两级无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入
- 有效的经度从-180度到180度。有效的纬度从-85.05112878度到85.05112878度.当坐标位置超出上述指定范围时,该命令将会返回一个错误。
- 参数:key 值(纬度,经度,名称)
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.10 29.53 chongqin
(integer) 1
127.0.0.1:6379> geoadd china:city 114.05 22.52 shenzhen
(integer) 1
# geopos 获得定位,从key里返回所有给定位置元素的位置
127.0.0.1:6379> geopos china:city beijing
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> geopos china:city chongqin
1) 1) "106.09999984502792358"
2) "29.52999957900659211"
127.0.0.1:6379> geopos china:city shanghai
1) 1) "121.47000163793563843"
2) "31.22999903975783553"
127.0.0.1:6379>
# GEODIST 返回两个给定位置之间的距离
127.0.0.1:6379> geodist china:city shanghai beijing
"1067378.7564"
127.0.0.1:6379> geodist china:city shanghai beijing km
"1067.3788"
127.0.0.1:6379>
# georadius 以给定的经度纬度为中心,找出某一半径内的元素
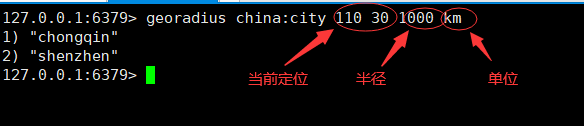
//查询附近的点,并限制查询数量
127.0.0.1:6379> georadius china:city 110 30 1000 km count 1
1) "chongqin"
//显示他人的位置信息
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord
1) 1) "chongqin"
2) 1) "106.09999984502792358"
2) "29.52999957900659211"
2) 1) "shenzhen"
2) 1) "114.04999762773513794"
2) "22.5200000879503861"
//显示到中间距离的位置
127.0.0.1:6379> georadius china:city 110 30 1000 km withdist
1) 1) "chongqin"
2) "380.1448"
2) 1) "shenzhen"
2) "924.6408"
# georadiusbymember 找出位于指定范围内的元素,中心点是有给定元素的位置袁术决定
//找出以北京位于中心店,周围1000km的点
127.0.0.1:6379> georadiusbymember china:city beijing 1000 km
1) "beijing"
//找出以北京位于中心店,周围10000km的点
127.0.0.1:6379> georadiusbymember china:city beijing 10000 km
1) "chongqin"
2) "shenzhen"
3) "shanghai"
4) "beijing"
# geohash 返回一个或多个位置元素的geohash表示,该命令将返回11个字符串的geohash字符串(如果两个字符串越接近,就表示两个位置距离越近)
127.0.0.1:6379> geohash china:city beijing
1) "wx4fbxxfke0"
127.0.0.1:6379> geohash china:city beijing chongqin
1) "wx4fbxxfke0"
2) "wm5ryrg8tn0"
# GEO底层的实现原理其实就是ZSet,所以我们可以使用ZSet的命令来操作geo
127.0.0.1:6379> zrange china:city 0 -1
1) "chongqin"
2) "shenzhen"
3) "shanghai"
4) "beijing"
2.Hyperloglog 基数统计(大概0.81%的错误率)
# 1.什么是基数
A{1,3,5,7,9,1}
B{1,3,5,6,7,3}
不重复的元素的个数--基数(1,3,5,6,7,9)有6个
一个网站的访问数量,重复的人访问,只算一次
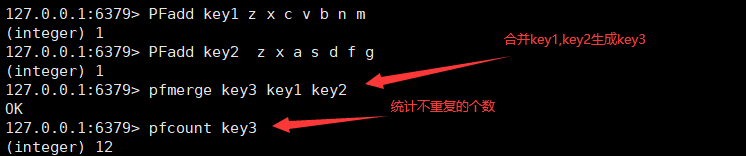
# 如果允许很小范围的容错,可以使用Hyperloglog,若使用其他方法,会占用很大内存,若使用Hyperloglog,他的内存固定,12kb,所以做统计,Hyperloglog首选
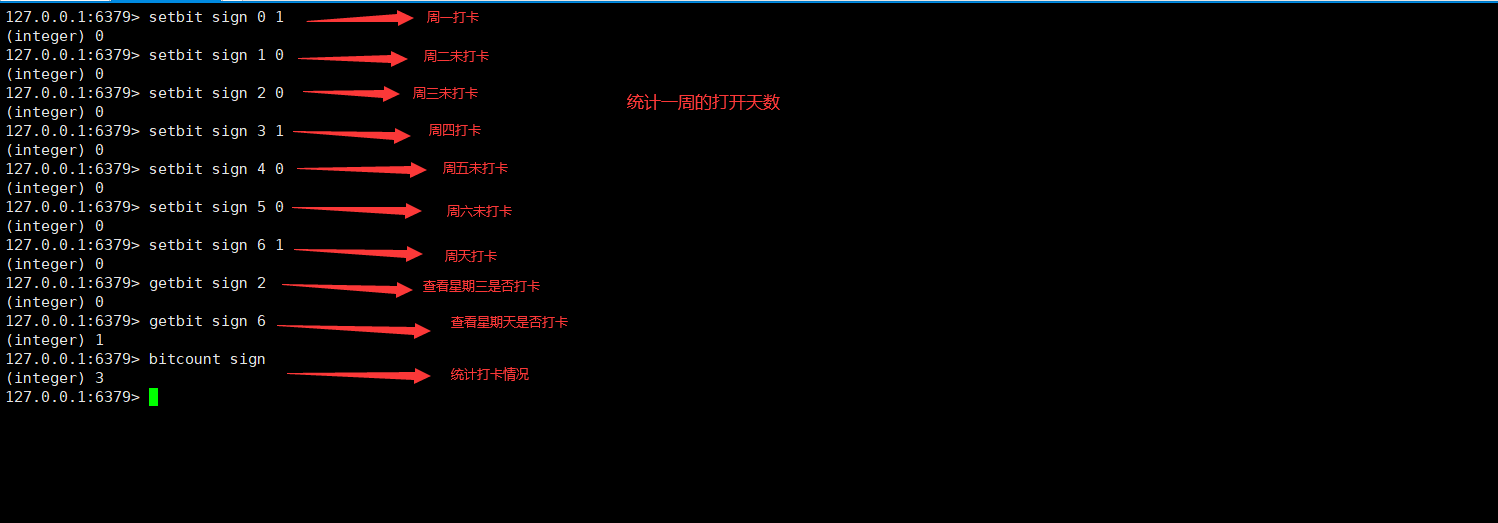
3.Bitmaps 位图场景详解
位存储:
- 例如统计用户信息,打卡信息,登录人数,未登录人数,活跃人数,不活跃人数统计等等两个状态的都可以使用Bitmaps
Bitmaps位图,数据结构,都是操作二进制来进行记录,就只有0和1两个状态
17.3 Redis基本的事务操作
Redis事务本质:一组命令的集合!一个事务的所有命令都会被序列化,在事务执行过程中,会按照顺序执行
一次性,顺序性,排他性!执行一系列的命令
所有的命令在事务中,并没有直接执行,只有发起执行命令的时候才回去执行!Exec
redis事务没有原子性,没有隔离级别的概念
- redis事务:
- 开启事务(multi)
- 命令入队
- 执行事务(exec)
使用jedis也可以直接操作事务
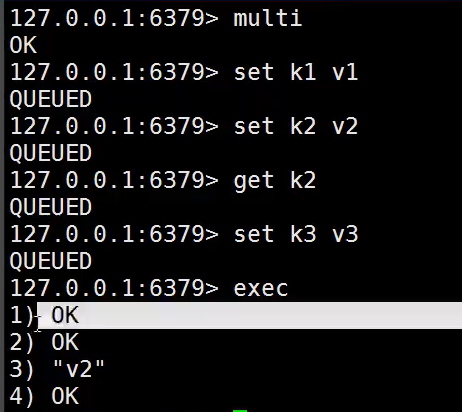
- 放弃事务 discard
- 编译型异常(代码有错!命令有错!),事务中所有的命令都不会被执行
- 运行时异常,如果事务中存在语法性,那么执行命令的时候,其他命令是可以正常执行的,错误命令抛出异常
锁:Redis可以实现乐观锁
悲观锁:
- 很悲观,认为什么时候都会出现问题,无论什么时候都加锁
乐观锁 - 很乐观,认为什么时候都不会出现问题,所以不会上锁,跟新数据的时候去判断一下,在此期间是否有人修改过这个数据
- 获取version
- 更新的时候比较version
redis的监视测试(watch)
使用watch监视key,可以当做乐观锁操作
unwatch 放弃监视
17.4 自定义redisTemplate
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
//固定模板
@Resource
private LettuceConnectionFactory lettuceConnectionFactory;
/**
* RedisTemplate配置
*
* @param lettuceConnectionFactory
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory) {
// 设置序列化
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, Visibility.ANY);
om.enableDefaultTyping(DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置redisTemplate
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<String, Object>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
RedisSerializer<?> stringSerializer = new StringRedisSerializer();
redisTemplate.setKeySerializer(stringSerializer);// key序列化
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);// value序列化
redisTemplate.setHashKeySerializer(stringSerializer);// Hash key序列化
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);// Hash value序列化
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号