Web自动化之元素定位
Web自动化之元素定位
前提:元素或属性必须唯一
八种元素定位方式:id,name,link_text,partial_link_text,xpath,css,class_name,tag_name
1、id定位:
HTML规定id是唯一标识(每个id都是不一样的),这类似公民的身份证号,具有很强的唯一性。

2、name定位:
name属性不是绝对唯一的(一个页面内可能存在多个元素的name属性是相同的)

3、link_text定位:
通过链接元素的文本内容来精确匹配定位元素,不是绝对唯一的(一个页面内可能存在多个链接元素的文本内容是相同的)

4、partial_link_text定位:
通过链接元素的文本内容来模糊匹配定位元素,不是绝对唯一的(一个页面内可能存在多个链接元素的文本内容是相同的)
5、xpath定位:
(1)绝对路径(以/开头,从根目录逐级查找):【一般不会用到绝对路径】
如百度页面的输入框的绝对路径,可右键copy某元素的完整xpath
xpath=/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input

(2)相对路径(以//开头,从网页的任务标签开始查询元素):
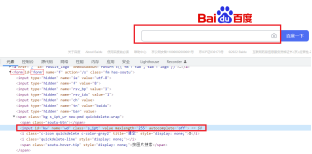
以百度输入框为例子:
① 相对路径+索引定位
xpath=//form//span[1]//input
② 相对路径+属性定位
xpath=//input[@autocomplete="off"]
③ 相对路径+部分属性值定位
以什么开头:xpath=//input[starts-with(@autocomplete,'of')]
以什么结尾:xpath=//input[substring(@autocomplete,2)='ff']
包含:xpath=//input[contains(@autocomplete,'ff')]
④ 相对路径+通配符定位(右键copy复制xpath,但一般不建议使用)
//*[@id=’kw’]
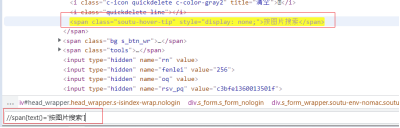
⑤ 相对路径+文本定位(只适用于超链接):
//span[text=’按图片搜索’]
6、css定位:
(1)绝对路径:不会使用
(2)通过id(#)和Class(.)定位
通过id定位:css=input#kw或#kw
通过class定位:css=.s_ipt或imput.s_ipt
(3)相对路径:
通过属性定位:css=input[autocomplete="off"]
通过部分属性值定位:
以什么开头:css=input[autocomplete^='of']
以什么结尾:css=input[autocomplete$='ff']
包含:css=input[autocomplete*='ff']
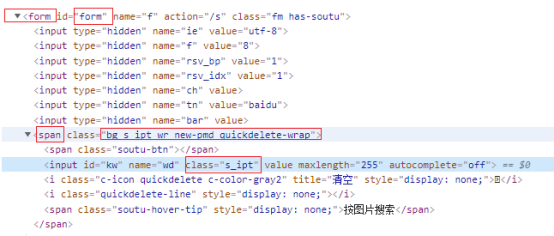
通过子节点定位:
css=form#form>span.bg.s_ipt_wr.new-pmd.quickdelete-wrap>input.s_ipt
或将>替换为空格:css=form#form span.bg.s_ipt_wr.new-pmd.quickdelete-wrap input.s_ipt
css=div#s-top-left>a:nth-child(2)或将>替换为空格:css=div#s-top-left a:nth-child(2)
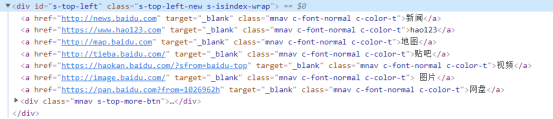
通过兄弟节点:
css=div#s-top-left>a +a
7、class_name定位:
通过元素的class属性来定位元素,class属性不是绝对唯一的(一个页面内可能存在多个元素的class属性是相同的)
8、tag_name定位:
HTML是通过tag来定义功能的,比如input是输入,table是表格等等。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多div,input,a等tag,所以很难通过tag去区分不同的元素。基本上在我们工作中用不到这种定义方法,仅了解就行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号