【Python基础学习记录4】列表和字典
一、列表与字典
1、数据结构
数据结构是指从计算机储存、组织数据的结构。
4种常用的数据结构:
列表(List)
元组(Tuple)
字典(Dictionary)
集合(Set)
2、列表
2.1 定义
列表中的数据按顺序排列
列表有正序与倒序两种索引
列表可存储任意类型数据,且允许重复
|
索引倒序 |
-7 |
-6 |
-5 |
-4 |
-3 |
-2 |
-1 |
|
列表 |
A |
B |
C |
1 |
1 |
3 |
4 |
|
索引正序 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
2.2 列表的创建
(1)列表的创建
语法:
变量名 = [元素1, 元素2, ......]
示例:
list = ["a", "b", "c", 1, 2, 3]
(2)特殊的列表-空列表
list1 = []
2.3 列表的取值
|
索引倒序 |
-7 |
-6 |
-5 |
-4 |
-3 |
-2 |
|
列表 |
张三 |
李四 |
王五 |
赵六 |
钱七 |
孙八 |
|
索引正序 |
0 |
1 |
2 |
3 |
4 |
5 |
(1)取值的语法
变量 = 列表变量[索引值]
(2)范围取值
列表变量 = 原列表变量[起始索引:结束索引],在python中列表范围取值时“左闭右开”
(3)列表的index函数
用于获取指定元素的索引值,只返回第一个符合要求的索引值
a = list.index(某变量):提取某变量在该列表中首次出现的从0开始的索引值
a =len(list):表示这个列表中有几个元素
index()方法语法: str.index(str, beg=0, end=len(string)) 参数 str -- 指定检索的字符串 beg -- 开始索引,默认为0。 end -- 结束索引,默认为字符串的长度。
2.4 列表的遍历(for循环)
for...in语句专门用于遍历列表、元组等数据结构
for 迭代变量 in 可迭代对象
循环体(必须缩进)
for和while:
persons = ['张三','李四','王五','赵六','钱七','孙八']
i = 0 count = len(persons) #获取列表长度 for p in persons: if p == '赵六': ri = count * -1 + i print(p, i, ri) i += 1
i = 0 while i < len(persons): #这里需要注意,不能写成i<= len(persons),否则程序报错 p = persons[i] if p == '赵六': ri = count * -1 + i print(p,i,ri) i += 1
2.5 列表的反转和排序
(1)反转和排序
反转:变量.reverse()
排序:变量.sort() 默认按照升序排列
变量.sort(reverse=True) 降序排列
(2)冒泡排序
def bubbleSort(lyst): n = len(lyst) while n > 1: swaped = False #swaped作为一个标志位,如果在通过某轮循环时没有发生元素交换,这时说明列表已经排序好了,可以直接退出循环 i = 1 while i < n: if lyst[i] < lyst[i - 1]: #如果一个元素比它前面的元素小,则交换两个元素 lyst[i],lyst[i - 1] = lyst[i - 1], lyst[i] swaped = True i += 1 #元素index加一,继续往后 if not swaped: return lyst n -= 1 #完成一轮比较,减一 return lyst if __name__ == "__main__": list = [5, 6, 1, 3, 89, 23, 56, 15, 95] result = bubbleSort(list) print(result)
2.6 列表的新增、修改、删除操作
|
用法 |
描述 |
|
list.append(新元素) |
在列表末端追加新元素,相当于list.insert(len(list),数值) |
|
list.insert(索引,新元素) |
在指定索引插入新元素,原有位置元素向后移一位 |
|
list[索引] = 新值 |
更新指定索引位置数据 |
|
list[起始索引:结束索引] = 新列表 |
更新指定范围数据 |
|
list.remove(元素) |
删除指定元素,只能删除第一个指定元素 |
|
list.pop(索引) |
按索引删除指定元素 |
|
list[起始索引:结束索引]=[] |
特殊用法,删除指定范围元素 |
|
注意:索引范围遵循左闭右开的原则 |
|
2.7 列表其他常用方法
如列表:list = [1, 2, 3, 4, 5, 5, 6, 6]
|
用法 |
描述 |
|
list.count(5) |
统计出现次数,返回2,因为元素5出现了两次 |
|
list.extend([7, 8]) |
extend是将列表中的元素追加到原始列表末端; 区别于list.append([7, 8])是将整个列表追加到列表末端 |
|
1 in list |
in运算符用于判断数据是否在列表中存在,存在:True, 不存在: False
|
|
list1 = list.copy() |
copy 函数用于复制列表,如果改变list列表,list1列表是不受影响的,因为它们俩是完全不同的存储; 区别于list1 = list,list1和 list列表时刻保持一致 |
|
list.clear() |
clear 用于清空列表 |
2.8 多维列表(嵌套列表)
str.split("分隔符号"):split函数将字符串按照分隔符分割成列表
示例:
#[[姓名,年龄,工资],[姓名,年龄,工资],[姓名,年龄,工资],[姓名,年龄,工资]]
#字符串:"姓名,年龄,工资"例如: "张三,30,2000"
emp_list = [ ] while True: info = input("请输入员工信息:") if info == "" print("程序结束") break info_list = info.split(",") if len(info_list) != 3: print("输入格式不正确,请重新输入") continue # continue 用于跳过剩余的语句 emp_list.append(info_list) for emp in emp_list: print("{n},年龄:{a},工资:{s}".format(n=emp[0],a=emp[1],s=emp[2]))
3、字典
3.1 什么是字典
字典(dictionary)时python中的内置数据结构,字典非常适合表达结构化的数据
3.2 字典的特点
字典采用键(key):值(value)形式表达数据
字典中key不允许重复,value允许重复
字典是可修改的,运行时动态调整存储空间
3.3创建字典的两种方式
1)使用 { } 创建字典
例:
dict={'键1':'值','键2':'值','键3':'值','键4':'值'}
1)使用dict函数创建字典,
例:
dict(键1='值',键2='值',键3='值',键4='值',键5='值')
其中,dict4 = dict.fromkeys(["键1","键2","键3"],"N/A")#利用序列来创建key,可以设置默认值,没有设置初始值,默认为None
3.4 字典的取值操作
1)单个取值
a = dict["k1"]
可取到该字典中键k1对应的值;如果k1不存在,则会报错。
a = dict.get("k1")
如果k1存在,输出该键对于的值;如果k1不存在,会输出None。
a=dict.get("k1" , "vn")
如果k1存在,输出该键对于的值;如果k1不存在,会输出后面的值vn。
2)判断键是否存在于字典
k in dict可判断该键k是否存在于字典dict中,返回True或False。注意只判断键,不判断值。
3)遍历字典
#遍历所有的键-值对 -- items() for k,v in {1:'a',2:'b'}.items(): print(k,v) print("-------------------") #遍历字典中的所有键 -- keys() for k in {'a':'b','c':'d'}.keys(): print(k) print("-------------------") for k in {'a':'b','c':'d'}: print(k) print("-------------------") #遍历字典中的所有值 -- values() for v in {'a':'b','c':'d'}.values(): print(v)
4)取最大最小键
表达式 max({2:10,8:4,5:9}) 的结果是8。-----------字典由键值对组成,max(D)输出的是最大的键。
表达式 min({2:10,8:4,5:9}) 的结果是2。-----------字典由键值对组成,min(D)输出的是最小的键。
3.5 字典的更新和删除操作
1)新增和更新
新增和更新均可以使用update函数,秉承有则更新,无则新增的原则。
dict1.update(k1 = "v1" , k2 = "v2") 或者:dict['k'] = "v"
原字典就有的k则更新v,没有的就添加一个。
update内用的是 k = "v",k不需要引号。
2)删除
dict1.pop("k1" , "k2")
删除对应的k所在的键值对。pop里只写k,要加引号。
dict1.popitem()
删除该字典中最后一个键值对,popitem本身有值,为被删掉的键值对转为元组形式,即("k" , "v")。
dict1.clear()
清空字典。
3.6 字典的常用操作
1)为字典设置默认值
setdefault为字典设置默认值,如果某个key存在则忽略,如果不存在则设置。
dict.setdefault('key','默认值')
如:emp.setdefault('grade','c')
2)字典的视图
随着原始数据的变动而变动。
ks = emp.keys() 提取键
vs = emp.values() 提取值
its = emp.items() 提取键对值
3)字典的格式化输出
老版本字典格式化字符串
变量 = “%(键)s”%字典名
str="姓名:%(name)s,评级:%(grade)s,入职时间:%(hiredate)s" %emp
新版本字典格式化字符串
变量 = “{键}”.format_map(字典名)
emp_str = "姓名{name},评级:{grade},入职时间:{hiredae}".format_map(emp)
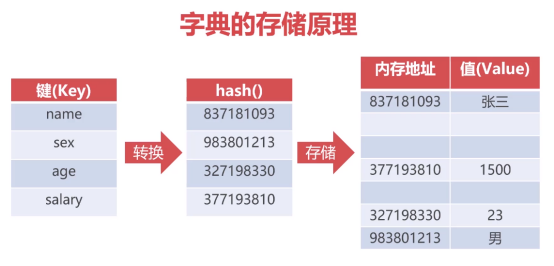
3.7 散列值与字典的存储方式
1)散列值(Hash)
*字典也称为“哈希(Hash)”,对应“散列值”
*散列值是从任何一种数据中创建数字“指纹”
*python中提供了hash()函数生成散列值
2)字典的存储原理
对于字典,通过key所对应的散列值找到对应的数据,数据在内存中不是连续存储(列表、元组则是),也不是按照key的顺序排列。
3.8字典在项目中的运用
#处理员工数据 source = '7782,CLARK,MANAGER,SALES,5000$7934,MILLER,SALESMAN,SALES,3000$369,SMITH,ANALYYST,RESEARCH,2000' employee_list = source.split('$') #对数据进行切割,返回列表 # print(employee_list) #输出结果为3个字符串 #保存所有解析后的员工信息,key是员工编号,value则是包含完整员工信息的字典 all_emp = {} for i in range(0,len(employee_list)): e = employee_list[i].split(',') # print(e) #创建员工字典 employee = {'no':e[0],'name':e[1],'job':e[2],'department':e[3],'salary':e[4]} # print(employee) all_emp[employee['no']] = employee print(all_emp) empno = input('请输入员工编号:') emp = all_emp.get(empno) if empno in all_emp: print('工号:{no},姓名:{name},岗位:{job},部门:{department},工资:{salary}'.format_map(emp)) else: print('员工信息不存在')
#遍历所有的键-值对 -- items()
for k,v in {1:'a',2:'b'}.items():
print(k,v)
print("-------------------")
#遍历字典中的所有键 -- keys()
for k in {'a':'b','c':'d'}.keys():
print(k)
print("-------------------")
for k in {'a':'b','c':'d'}:
print(k)
print("-------------------")
#遍历字典中的所有值 -- values()
for v in {'a':'b','c':'d'}.values():
print(v)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号