
简介
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序
Java 具有坚固、安全、易于使用、易于理解和可从网络上自动下载等特性,是编写数据库应用程序的杰出语言。所需要的只是 Java应用程序与各种不同数据库之间进行对话的方法。
JDBC可以在各种平台上使用Java,如Windows,Mac OS和各种版本的UNIX。
JDBC库包括通常与数据库使用相关的下面提到的每个任务的API:
- 连接数据库。
- 创建SQL或MySQL语句。
- 在数据库中执行SQL或MySQL查询。
- 查看和修改生成的记录。
体系结构
JDBC API支持用于数据库访问的两层和三层处理模型,但通常,JDBC体系结构由两层组成:
- JDBC API:这提供了应用程序到JDBC管理器连接。
- JDBC驱动程序API:这支持JDBC管理器到驱动程序连接。
JDBC API使用驱动程序管理器和特定于数据库的驱动程序来提供与异构数据库的透明连接
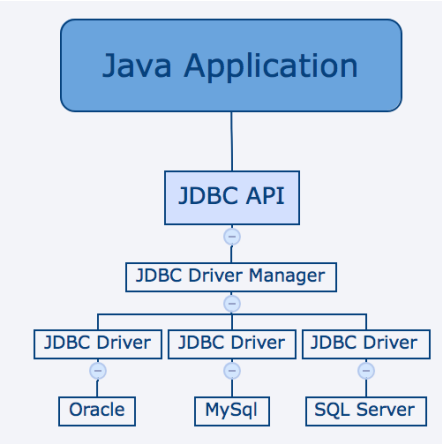
核心组件
DriverManager:
此类管理数据库驱动程序列表。使用通信子协议将来自java应用程序的连接请求 与适当的数据库驱动程序匹配。
Driver:
此接口处理与数据库服务器的通信,我们很少会直接与Driver对象进行交互。而是使用 DriverManager对象来管理这种类型的对象。
Connection:
该界面具有用于联系数据库的所有方法。连接对象表示通信上下文,即,与数据库 的所有通信仅通过连接对象。
Statement:
使用从此接口创建的对象将SQL语句提交到数据库。除了执行存储过程之外,一些派 生接口还接受参数。
ResultSet:
在使用Statement对象执行SQL查询后,这些对象保存从数据库检索的数据。它作为一 个迭代器,允许我们移动其数据。
SQLException:
此类处理数据库应用程序中发生的任何错误
JDBC连接步骤
- 导入包:需要包含包含数据库编程所需的JDBC类的包。大多数情况下,使用import java.sql.*就足够 了。
- 注册JDBC驱动程序:此步骤将使JVM将所需的驱动程序实现加载到内存中,打开与数据库的通信通道
使用Class.forName()方法,将驱动程序的类文件动态加载到内存中,并将其自动注册
使用静态 DriverManager.registerDriver() 方法。
- 创建连接:需要使用DriverManager.getConnection() 方法创建一个Connection对象,该对象表示与数据库的物理连接。
- getConnection(String url)
- getConnection(String url,Properties prop)
- getConnection(String url,String user,String password)
- 执行查询:需要使用类型为Statement的对象来构建和提交SQL语句到数据库。
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
Statement (语句对象)的方法:
- boolean execute(String SQL):如果可以检索到ResultSet对象,则返回一个布尔值true; 否则返 回false。使用此方法执行SQL DDL语句或需要使用真正的动态SQL时。
- int executeUpdate(String SQL):返回受SQL语句执行影响的行数。使用此方法执行预期会影响多个行的SQL语句,例如INSERT,UPDATE或DELETE语句。
- ResultSet executeQuery(String SQL):返回一个ResultSet对象。当您希望获得结果集时,请使用此方法,就像使用SELECT语句一样。
- 从结果集中提取数据:需要使用相应的 ResultSet.getXXX() 方法从结果集中检索数据。(XXX表示数据类型)
判断是否有下一条数据:resultSet .next();
- 释放资源:需要明确地关闭所有数据库资源,而不依赖于JVM的垃圾收集。
始终显示的关闭ResultSet 、Statement 、Connection对象。
数据库URL:
| RDBMS | JDBC驱动程序名称 | 网址格式 |
| MYSQL8 | com.mysql.cj.jdbc.Driver | jdbc:mysql://hostname:3306/databaseName?serverTimezone=UTC(&useUnicode=true&characterEncoding=UTF-8) |
| MySQL | com.mysql.jdbc.Driver | jdbc:mysql://hostname:3306/databaseName |
| ORACLE | oracle.jdbc.driver.OracleDriver | jdbc:oracle:thin:@hostname:port Number:databaseName |
| DB2 | COM.ibm.db2.jdbc.net.DB2Driver | jdbc:db2:hostname:port Number / databaseName |
| SYBASE | com.sybase.jdbc.SybDriver | jdbc:sybase:Tds:hostname:port Number / databaseName |
SQL注入:
即,通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
具体来说,它是利用现有应用程序,将(恶意的)SQL命令注入到后台数据库引擎执行的能力,
它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
比如先前的很多影视网站泄露VIP会员密码大多就是通过 WEB表单递交查询字符暴出的,这类表单特别容易受到SQL注入式攻击。
PreparedStatement(预状态通道)
该PreparedStatement的接口扩展了Statement接口,可以动态地提供参数。
JDBC中的所有参数都由 ?符号标记,这被称为参数标记。
在执行SQL语句之前,必须为每个参数提供值。
所述的setXXX()方法将值绑定到所述参数,其中XXX代表要绑定到输入参数的值的Java数据类型。
如果忘记提供值,将收到一个SQLException。
每个参数标记由其顺序位置引用。第一个标记表示位置1,下一个位置2等等。
PreparedStatement pstmt = null; try { String SQL = "Update Employees SET age = ? WHERE id = ?"; pstmt = conn.preparedStatement(SQL); pstmt.setString(1, 18); . . . }catch (SQLException e) { . . . }finally { pstmt.close(); }
statement和PreparedStatement
1. statement属于状态通道,PreparedStatement属于预状态通道
2. 预状态通道会先编译sql语句,再去执行,比statement执行效率高
3. 预状态通道支持占位符?,给占位符赋值的时候,位置从1开始
4. 预状态通道可以防止sql注入,原因:预状态通道在处理值的时候以字符串的方式处理
ResultSet(结果集)
保存select语句从数据库查询出的数据
ResultSet对象维护指向结果集中当前行的游标。术语“结果集”是指包含在ResultSet对象中的行和列数据。
如果没有指定任何ResultSet类型,您将自动获得一个TYPE_FORWARD_ONLY。
| 类型 | 描述 |
| ResultSet.TYPE_SCROLL_INSENSITIVE | 光标可以向前和向后滚动,结果集对创建结果集后发生的数据库的其他更改不敏感。 |
| ResultSet.TYPE_SCROLL_SENSITIVE。 | 光标可以向前和向后滚动,结果集对创建结果集之后发生的其他数据库所做的更改敏感。 |
| ResultSet.TYPE_FORWARD_ONLY | 光标只能在结果集中向前移动。 |
try { Statement stmt = conn.createStatement( ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); }catch(Exception ex) { .... }finally { .... }
JDBC中事务应用
如果JDBC连接处于自动提交模式,默认情况下,则每个SQL语句在完成后都会提交到数据库。
事务使您能够控制是否和何时更改应用于数据库。
它将单个SQL语句或一组SQL语句视为一个逻辑单 元,如果任何语句失败,则整个事务将失败。
要启用手动事务支持,而不是JDBC驱动程序默认使用的自动提交模式,使用Connection对象的 setAutoCommit()方法。
如果将boolean false传递给setAutoCommit(),则关闭自动提交。我 们可以传递一个布尔值true来重新打开它。
try{ // 关闭自动提交 conn.setAutoCommit(false); Statement stmt = conn.createStatement(); String SQL = "INSERT INTO Employees values (111, 11, 'aaa', 'ccc')"; stmt.executeUpdate(SQL); //Submit a malformed SQL statement that breaks String SQL = "INSERTED IN Employees VALUES (112, 12, 'bbb', 'ddd')"; stmt.executeUpdate(SQL); // 事务提交 conn.commit(); }catch(SQLException se){ // 事务回滚 conn.rollback(); }
Savepoints
新的JDBC 3.0 Savepoint接口提供了额外的事务控制。
设置保存点时,可以在事务中定义逻辑回滚点。
如果通过保存点发生错误,则可以使用回滚方法来撤消 所有更改或仅保存在保存点之后所做的更改。
Connection对象有两种新的方法来帮助您管理保存点
- setSavepoint(String savepointName):定义新的保存点。它还返回一个Savepoint对象。
- releaseSavepoint(Savepoint savepointName):删除保存点。请注意,它需要一个Savepoint 对象作为参数。此对象通常是由setSavepoint()方法生成的保存点。
try{ //Assume a valid connection object conn conn.setAutoCommit(false); Statement stmt = conn.createStatement(); String SQL = "INSERT INTO Employees VALUES (106, 20, 'Rita', 'Tez')"; stmt.executeUpdate(SQL); Savepoint savepoint1 = conn.setSavepoint("Savepoint1"); String SQL = "INSERTED IN Employees VALUES (107, 22, 'Sita', 'Tez')"; stmt.executeUpdate(SQL); conn.commit(); }catch(SQLException se){ // 此时回滚回保存点的位置 conn.rollback(savepoint1); // 此时提交,会将保存点之前的操作提交。 // conn.commit(); }
JDBC批处理
批量处理允许您将相关的SQL语句分组到批处理中,并通过对数据库的一次调用提交它们。
当您一次向数据库发送多个SQL语句时,可以减少连接数据库的开销,从而提高性能。
Statement批处理
以下是使用语句对象的批处理的典型步骤序列
- 使用createStatement()方法创建Statement对象。
- 使用setAutoCommit()将auto-commit设置为false 。
- 使用addBatch()方法在创建的语句对象上添加您喜欢的SQL语句到批处理中。
- 在创建的语句对象上使用executeBatch()方法执行所有SQL语句。
- 最后,使用commit()方法提交所有更改。
Statement stmt = conn.createStatement(); conn.setAutoCommit(false); //sql1 String SQL = "INSERT INTO Employees (id, name, age) VALUES(111,'aaa', 29)"; stmt.addBatch(SQL); //sql2 String SQL = "INSERT INTO Employees (id, name, age) VALUES(112,'ccc', 30)"; stmt.addBatch(SQL); //sql3 String SQL = "UPDATE Employees SET age = 31 WHERE id = 100"; stmt.addBatch(SQL); int[] count = stmt.executeBatch(); conn.commit();
PreparedStatement批处理
1. 使用占位符创建SQL语句。
2. 使用prepareStatement() 方法创建PrepareStatement对象。
3. 使用setAutoCommit()将auto-commit设置为false 。
4. 使用addBatch()方法在创建的语句对象上添加您喜欢的SQL语句到批处理中。
5. 在创建的语句对象上使用executeBatch()方法执行所有SQL语句。
6. 最后,使用commit()方法提交所有更改。
String SQL = "INSERT INTO Employees (id, name, age) VALUES(?, ?, ?)"; PreparedStatement pstmt = conn.prepareStatement(SQL); conn.setAutoCommit(false); // Set the variables pstmt.setInt( 1, 111); pstmt.setString( 2, "aaa" ); pstmt.setInt( 3, 33 ); // Add it to the batch pstmt.addBatch(); // Set the variables pstmt.setInt( 1, 222); pstmt.setString( 2, "bbb" ); pstmt.setInt( 3, 31 ); // Add it to the batch pstmt.addBatch(); //add more batches //Create an int[] to hold returned values int[] count = stmt.executeBatch(); //Explicitly commit statements to apply changes conn.commit();
反射处理结果集
//得到数据库中的所有的列 ResultSetMetaData metaData = rs.getMetaData();//返回数据库中的相关信息 int count=metaData.getColumnCount();//得到列数 String[] columnnames=new String[count]; for (int i = 0; i < count; i++) { // System.out.println(metaData.getColumnName(i+1));//列的位置从1开始 columnnames[i]=metaData.getColumnName(i+1); } //得到实体类中的所有的方法 Method[] methods =cla.getDeclaredMethods(); while(rs.next()){ Object s=cla.newInstance();//调取无参构造创建对象 for (String columnname : columnnames) { String name="set"+columnname;//setstuid for (Method method : methods) { if(method.getName().equalsIgnoreCase(name)){ method.invoke(s,rs.getObject(columnname));//执行了对应的 set方法 break; } } } list.add(s); }
properties文件保存数据库信息
特点:key-value存储方式
// 属性文件:db.properties
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/yhp
user=root
password=123456
// 输入流获取 InputStream inputStream = 当前类名.class.getClassLoader() .getResourceAsStream("db.properties"); Properties properties = new Properties(); properties.load(inputStream); dirverName = properties.getProperty("driver"); url = properties.getProperty("url"); username = properties.getProperty("user"); password = properties.getProperty("password"); // ResourceBundle 获取//参数只写属性文件名即可,不需要写后缀 ResourceBundle bundle = ResourceBundle.getBundle("db");
driver = bundle.getString("driver"); url = bundle.getString("url"); username = bundle.getString("user"); password = bundle.getString("password");
连接池
数据连接池原理
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数 以及每个连接的最大使用次数、最大空闲时间等等,也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
参数
最小连接数: 是数据库一直保持的数据库连接数,所以如果应用程序对数据库连接的使用量不大,将有大量的数据库 资源被浪费。
初始化连接数: 连接池启动时创建的初始化数据库连接数量。
最大连接数: 是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求被加入到等待队 列中。
最大等待时间: 当没有可用连接时,连接池等待连接被归还的最大时间,超过时间则抛出异常,可设置参数为0或者负 数使得无限等待(根据不同连接池配置)。
| DBCP | c3p0 | Druid | |
| 最小连接数 | minldle(0) | minPoolSize(3) | minldle(0) |
| 初始化连接数 | initialSize(0) | initialPoolSize(3) | initialSize(0) |
| 最大连接数 | maxTotal(8) | maxPoolSize(15) | maxActive(8) |
| 最大等待时间 | maxWaitMillis(毫秒) | maxIdleTime(0秒) | maxWait(毫秒) |
注:
在DBCP连接池的配置中,还有一个maxIdle的属性,表示最大空闲连接数,超过的空闲连接将被释 放,默认值为8。
对应的该属性在Druid连接池已不再使用,配置了也没有效果,c3p0连接池则没有对 应的属性。
数据库连接池在初始化的时候会创建initialSize个连接,当有数据库操作时,会从池中取出一个连 接。
如果当前池中正在使用的连接数等于maxActive,则会等待一段时间,等待其他操作释放掉某一个 连接,如果这个等待时间超过了maxWait,则会报错;如果当前正在使用的连接数没有达到 maxActive,则判断当前是否空闲连接,如果有则直接使用空闲连接,如果没有则新建立一个连接。在连接使用完毕后,不是将其物理连接关闭,而是将其放入池中等待其他操作复用。
DBCP连接池
DBCP是一个依赖Jakarta commons-pool对象池机制的数据库连接池.DBCP可以直接的在应用程序中 使用,Tomcat的数据源使用的就是DBCP。
相关jar包:commons-dbcp.jar commons-pool.jar mysql-jdbc.jar
硬编码使用DBCP > 所谓的硬编码方式就是在代码中添加配置
// 硬编码 使用DBCP连接池子 BasicDataSource source = new BasicDataSource();
软编码使用DBCP > 所谓的软编码,就是在项目中添加配置文件,这样就不需要每次代码中添加配合
.properties 文件中配置 #<!-- 初始化连接 --> initialSize=10 #最大连接数量 maxActive=50 #<!-- 最大空闲连接 --> maxIdle=20 #<!-- 最小空闲连接 --> minIdle=5 #<!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 --> maxWait=6000
//1.创建dbcp的工具类对象 static BasicDataSource datasource=new BasicDataSource(); //2.加载驱动 static { try { //加载属性文件 //1.使用工具类 ,参数是属性文件的文件名(不要加后缀) ResourceBundle bundle = ResourceBundle.getBundle("db"); driverClass = bundle.getString("driverclass"); url = bundle.getString("url"); username = bundle.getString("uname"); password = bundle.getString("upass"); init=bundle.getString("initsize"); //2.将驱动地址等信息传递给dbcp datasource.setDriverClassName(driverClass); datasource.setUrl(url); datasource.setUsername(username); datasource.setPassword(password); datasource.setInitialSize(Integer.parseInt(init)); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } //3.获得连接 public static Connection getConn() { try { con= datasource.getConnection(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return con; }
C3P0连接池
c3p0是一个开放源代码的JDBC连接池,它在lib目录中与Hibernate一起发布,包括了实现jdbc3和 jdbc2扩展规范说明的Connection 和Statement 池的DataSources 对象。
c3p0与dbcp区别
1. dbcp没有自动回收空闲连接的功能 c3p0有自动回收空闲连接功能
2. dbcp需要手动设置配置文件 c3p0不需要手动设置
实现方式
1 .手动设置 ComboPooledDataSource
2 .加载配置文件方式
src/c3p0-config.xml(文件名固定) ComboPooledDataSource cpds = new ComboPooledDataSource(); 加载 文件中 <default-config>中的配置 ComboPooledDataSource cpds = new ComboPooledDataSource("aaa"); 加载 <named-config name="aaa"> 中的配置
相关jar包:c3p0-0.9.1.2.jar mysql-connector-java-5.0.8.jar
添加配置文件:
c3p0是在外部添加配置文件,工具直接进行应用,因为直接引用,所以要求固定的命名和文件位置
文件位置: src 文件命名:c3p0-config.xml/c3p0-config.properties
<?xml version="1.0" encoding="utf-8"?> <c3p0-config> <!-- 默认配置,如果没有指定则使用这个配置 --> <default-config> <!-- 基本配置 --> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql://localhost:3306/day2</property> <property name="user">root</property> <property name="password">111</property> <!--扩展配置--> <!-- 连接超过30秒报错--> <property name="checkoutTimeout">30000</property> <!--30秒检查空闲连接 --> <property name="idleConnectionTestPeriod">30</property> <property name="initialPoolSize">10</property> <!-- 30秒不适用丢弃--> <property name="maxIdleTime">30</property> <property name="maxPoolSize">100</property> <property name="minPoolSize">10</property> <property name="maxStatements">200</property> </default-config> <!-- 命名的配置 --> <named-config name="abc"> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql://localhost:3306/day2</property> <property name="user">root</property> <property name="password">111</property> <!-- 如果池中数据连接不够时一次增长多少个 --> <property name="acquireIncrement">5</property> <property name="initialPoolSize">20</property> <property name="minPoolSize">10</property> <property name="maxPoolSize">40</property> <property name="maxStatements">20</property> <property name="maxStatementsPerConnection">5</property> </named-config> </c3p0-config>
注意: c3p0的配置文件内部可以包含命名配置文件和默认配置文件!默认是选择默认配置!如果需要切换 命名配置可以在创建c3p0连接池的时候填入命名即可
使用
Connection con=null; ComboPooledDataSource db = new ComboPooledDataSource("abc"); public Connection getCon(){ try { con=db.getConnection(); System.out.println("初始化的链接数量:"+db.getInitialPoolSize()); } catch (SQLException e) { e.printStackTrace(); } return con; }
Druid(德鲁伊)连接池
阿里出品,淘宝和支付宝专用数据库连接池,但它不仅仅是一个数据库连接池,它还包含一个 ProxyDriver(代理驱动),一系列内置的JDBC组件库,一个SQL Parser(sql解析器)。支持所有JDBC兼 容的数据库,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等等。
Druid针对Oracle和MySql做了特别优化,比如Oracle的PS Cache内存占用优化,MySql的ping检测优化。
Druid提供了MySql、Oracle、Postgresql、SQL-92的SQL的完整支持,这是一个手写的高性能SQL Parser,支持Visitor模式,使得分析SQL的抽象语法树很方便。
简单SQL语句用时10微秒以内,复杂SQL用时30微秒。
通过Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。Druid防 御SQL注入攻击的WallFilter就是通过Druid的SQL Parser分析语义实现的。
Druid 是目前比较流行的高性能的,分布式列存储的OLAP框架(具体来说是MOLAP)。它有如下几个特 点:
一. 亚秒级查询
druid提供了快速的聚合能力以及亚秒级的OLAP查询能力,多租户的设计,是面向用户分析应用的理想方式。
二.实时数据注入
druid支持流数据的注入,并提供了数据的事件驱动,保证在实时和离线环境下事件的实效性和统一性
三.可扩展的PB级存储
druid集群可以很方便的扩容到PB的数据量,每秒百万级别的数据注入。即便在加大数据规模的情况 下,也能保证时其效性
四.多环境部署
druid既可以运行在商业的硬件上,也可以运行在云上。它可以从多种数据系统中注入数据,包括 hadoop,spark,kafka,storm和samza等
五.丰富的社区
使用
/** * Druid * */ public class DruidUtils { //声明连接池对象 private static DruidDataSource ds; static{ //实例化数据库连接池对象 ds=new DruidDataSource(); //实例化配置对象 Properties properties=new Properties(); try { //加载配置文件内容 properties.load(DruidUtils.class.getResourceAsStream("dbcpconfig.properties")); //设置驱动类全称 ds.setDriverClassName(properties.getProperty("driverClassName" )); //设置连接的数据库 ds.setUrl(properties.getProperty("url")); //设置用户名 ds.setUsername(properties.getProperty("username")); //设置密码 ds.setPassword(properties.getProperty("password")); //设置最大连接数量 ds.setMaxActive(Integer.parseInt(properties.getProperty("maxActi ve"))); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } //获取连接对象 public static Connection getConnection() { try { return ds.getConnection(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return null; } }
注:在Druid连接池的配置中,driverClassName可配可不配,如果不配置会根据url自动识别dbType(数 据库类型),然后选择相应的driverClassName。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号